Introducing Hunyuan3D-1.0, a game-changer in the world of 3D asset creation. Imagine generating high-quality 3D models in under 10 seconds—no more long waits or cumbersome processes. This innovative tool combines cutting-edge AI and a two-stage framework to create realistic, multi-view images before transforming them into precise, high-fidelity 3D assets. Whether you’re a game developer, product designer, or digital artist, Hunyuan3D-1.0 empowers you to speed up your workflow without compromising on quality. Explore how this technology can reshape your creative process and take your projects to the next level. The future of 3D asset generation is here, and it’s faster, smarter, and more efficient than ever before.
Learning Objectives
- Learn how Hunyuan3D-1.0 simplifies 3D modeling by generating high-quality assets in under 10 seconds.
- Explore the Two-Stage Approach of Hunyuan3D-1.0.
- Discover how advanced AI-driven processes like adaptive guidance and super-resolution enhance both speed and quality in 3D modeling.
- Uncover the diverse use cases of this technology, including gaming, e-commerce, healthcare, and more.
- Understand how Hunyuan3D-1.0 opens up 3D asset creation to a broader audience, making it faster, cost-effective, and scalable for businesses.
This article was published as a part of the Data Science Blogathon.
Table of contents
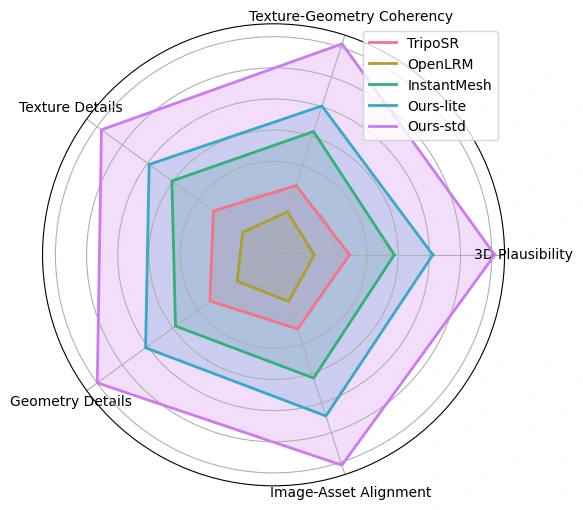
Features of Hunyuan3D-1.0
The uniqueness of Hunyuan3D-1.0 lies in its groundbreaking approach to creating 3D models, combining advanced AI technology with a streamlined, two-stage process. Unlike traditional methods, which require hours of manual work and complex modeling software, this system automates the creation of high-quality 3D assets from scratch in under 10 seconds. It achieves this by first generating multi-view 2D images of a product or object using sophisticated AI algorithms. These images are then seamlessly transformed into detailed, realistic 3D models with an impressive level of fidelity.
What makes this proposal truly innovative is its ability to significantly reduce the time and skill required for 3D modeling, which is typically a labor-intensive and technical process. By simplifying this into an easy-to-use system, it opens up 3D asset creation to a broader audience, including game developers, digital artists, and designers who may not have specialized expertise in 3D modeling. The system’s capacity to generate models quickly, efficiently, and accurately not only accelerates the creative process but also allows businesses to scale their projects and reduce costs.
In addition, it doesn’t just save time—it also ensures high-quality outputs. The AI-driven technology ensures that each 3D model retains important visual and structural details, making them perfect for real-time applications like gaming or virtual simulations. This proposal represents a leap forward in the integration of AI and 3D modeling, providing a solution that’s fast, reliable, and accessible to a wide range of industries.
How Hunyuan3D-1.0 WorksHow Hunyuan3D-1.0 Works
In this section, we discuss two main stages of Hunyuan3D-1.0, which involves a multi-view diffusion model for 2D-to-3D lifting and a sparse-view reconstruction model.

Let’s break down these methods to understand how they work together to create high-quality 3D models from 2D images.
Multi-view Diffusion Model
This method uses the success of diffusion models in generating 2D images and extends it to create multi-view 3D images.

- The multi-view images are generated simultaneously by organizing them in a grid.
- By scaling up the Zero-1-to-3++ model, this approach generates a 3× larger model.
- The model uses a technique called “Reference attention.” This technique guides the diffusion model to produce images with textures similar to a reference image.
- This involves adding an extra condition image during the denoising process to ensure consistency across generated images.
- The model renders the images with specific angles (elevation of 0° and multiple azimuths) and a white background.
Adaptive Classifier-free Guidance (CFG)

- In multi-view generation, a small CFG enhances texture detail but introduces unacceptable artifacts, while a large CFG improves object geometry at the cost of texture quality.
- The performance of CFG scale values varies by view; higher scales preserve more details for front views but may lead to darker back views.
- In this model, adaptive CFG is proposed to adjust the CFG scale for different views and time steps.
- Intuitively, for front views and at early denoising time steps, higher CFG scale is set, which is then decreased as the denoising process progresses and as the view of the generated image diverges from the condition image.
- This dynamic adjustment improves both the texture quality and the geometry of the generated models.
- Thus, a more balanced and high-quality multi-view generation is achieved.
Sparse-view Reconstruction Model
This model helps in turning the generated multi-view images into detailed 3D reconstructions using a transformer-based approach. The key to this method is speed and quality, allowing the reconstruction process to happen in less than 2 seconds.
Hybrid Inputs
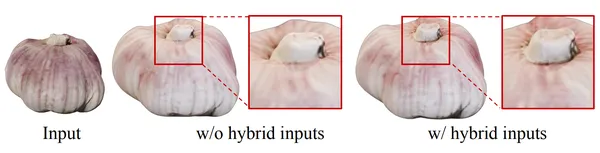
- The reconstruction model uses both calibrated, and uncalibrated (user-provided) images for accurate 3D reconstruction.
- Calibrated images help guide the model’s understanding of the object’s structure, while uncalibrated images fill in gaps, especially for views that are hard to capture with standard camera angles (like top or bottom views).
Super-resolution

- One challenge with 3D reconstruction is that low-resolution images often result in poor-quality models.
- To solve this, the model uses a “Super-resolution module”.
- This module enhances the resolution of triplanes (3D data planes), improving the detail in the final 3D model.
- By avoiding complex self-attention on high-resolution data, the model maintains efficiency while achieving clearer details.
3D Representation

- Instead of relying solely on implicit 3D representations (e.g., NeRF or Gaussian Splatting), this model uses a combination of implicit and explicit representations.
- NeuS uses the Signed Distance Function (SDF) to model the shape and then converts it into explicit meshes with the Marching Cubes algorithm.
- Use these meshes directly for texture mapping, preparing the final 3D outputs for artistic refinements and real-world applications.
Getting Started with Hunyuan3D-1.0
Clone the repository.
git clone https://github.com/tencent/Hunyuan3D-1
cd Hunyuan3D-1Installation Guide for Linux
‘env_install.sh’ script file is used for setting up the environment.
# step 1, create conda env
conda create -n hunyuan3d-1 python=3.9 or 3.10 or 3.11 or 3.12
conda activate hunyuan3d-1
# step 2. install torch realated package
which pip # check pip corresponds to python
# modify the cuda version according to your machine (recommended)
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
# step 3. install other packages
bash env_install.sh
Optionally, ‘xformers’ or ‘flash_attn’ can be installed to acclerate computation.
pip install xformers --index-url https://download.pytorch.org/whl/cu121pip install flash_attnMost environment errors are caused by a mismatch between machine and packages. The version can be manually specified, as shown in the following successful cases:
# python3.9
pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118when install pytorch3d, the gcc version is preferably greater than 9, and the gpu driver should not be too old.
Download Pretrained Models
The models are available at https://huggingface.co/tencent/Hunyuan3D-1:
- Hunyuan3D-1/lite: lite model for multi-view generation.
- Hunyuan3D-1/std: standard model for multi-view generation.
- Hunyuan3D-1/svrm: sparse-view reconstruction model.
To download the model, first install the ‘huggingface-cli’. (Detailed instructions are available here.)
python3 -m pip install "huggingface_hub[cli]"Then download the model using the following commands:
mkdir weights
huggingface-cli download tencent/Hunyuan3D-1 --local-dir ./weights
mkdir weights/hunyuanDiT
huggingface-cli download Tencent-Hunyuan/HunyuanDiT-v1.1-Diffusers-Distilled --local-dir ./weights/hunyuanDiTInference
For text to 3d generation, it supports bilingual Chinese and English:
python3 main.py \
--text_prompt "a lovely rabbit" \
--save_folder ./outputs/test/ \
--max_faces_num 90000 \
--do_texture_mapping \
--do_renderFor image to 3d generation:
python3 main.py \
--image_prompt "/path/to/your/image" \
--save_folder ./outputs/test/ \
--max_faces_num 90000 \
--do_texture_mapping \
--do_renderUsing Gradio
The two versions of multi-view generation, std and lite can be inferenced as follows:
# std
python3 app.py
python3 app.py --save_memory
# lite
python3 app.py --use_lite
python3 app.py --use_lite --save_memory
Then the demo can be accessed through http://0.0.0.0:8080. It should be noted that the 0.0.0.0 here needs to be X.X.X.X with your server IP.
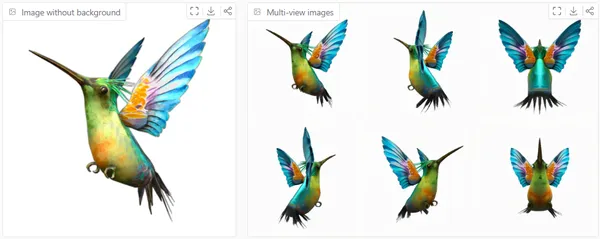
Examples of Generated Models
Generated using Hugging Face Space: https://huggingface.co/spaces/tencent/Hunyuan3D-1
Example1: Humming Bird
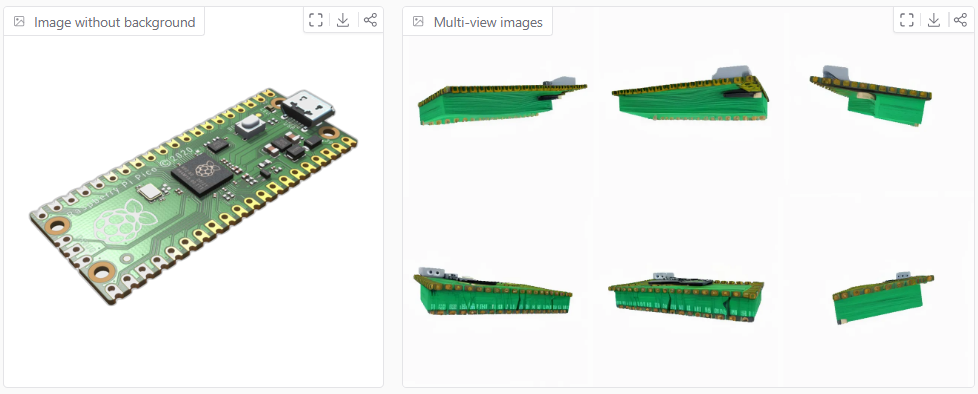
Example2:
Raspberry Pi Pico
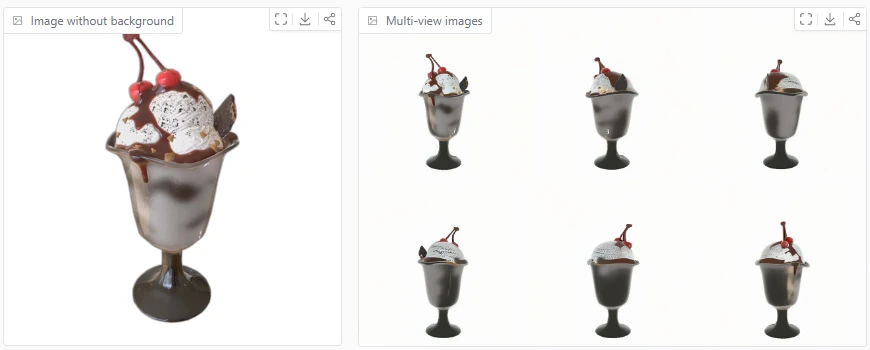
Example3: Sundae
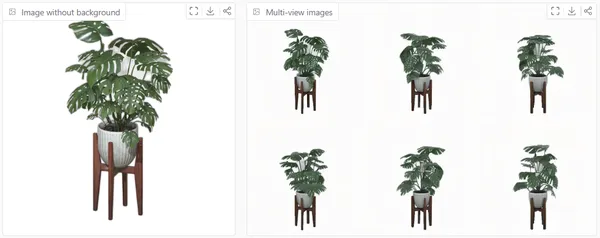
Example4: Monstera deliciosa
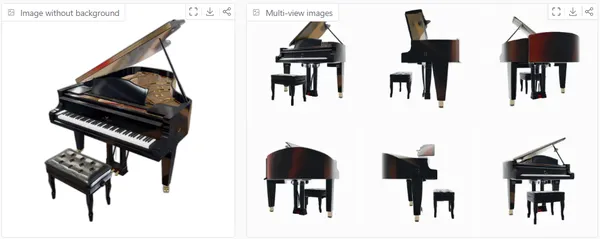
Example5: Grand Piano
Pros and Challenges of Hunyuan3D-1.0
- High-quality 3D Outputs: Generates detailed and accurate 3D models from minimal inputs.
- Speed: Delivers instant reconstructions.
- Versatility: Adapts to both calibrated and uncalibrated data for diverse applications.
Challenges
- Sparse-view Limitations: Struggles with uncertainties in the top and bottom views due to restricted input perspectives.
- Complexity in Resolution Scaling: Increasing triplane resolution adds computational challenges despite optimizations.
- Dependence on Large Datasets: Requires extensive data and training resources for high-quality outputs.
Real-World Applications
- Game Development: Create detailed 3D assets for immersive gaming environments.
- E-Commerce: Generate realistic 3D product previews for online shopping.
- Virtual Reality: Build accurate 3D scenes for VR experiences.
- Healthcare: Visualize 3D anatomical models for medical training and diagnostics.
- Architectural Design: Render lifelike 3D layouts for planning and presentations.
- Film and Animation: Generating hyper-realistic visuals and CGI for movies and animated productions.
- Personalized Avatars: Developing custom, lifelike avatars for social media, virtual meetings, or the metaverse.
- Industrial Prototyping: Streamlining product design and testing with accurate 3D prototypes.
- Education and Training: Providing immersive 3D learning experiences for subjects like biology, engineering, or geography.
- Virtual Home Tours: Enhancing real estate with interactive 3D property walkthroughs for potential buyers.
Conclusion
Hunyuan3D-1.0 represents a significant leap forward in the realm of 3D reconstruction, offering a fast, efficient, and highly accurate solution for generating detailed 3D models from sparse inputs. By combining the power of multi-view diffusion, adaptive guidance, and sparse-view reconstruction, this innovative approach pushes the boundaries of what’s possible in real-time 3D generation. The ability to seamlessly integrate both calibrated and uncalibrated images, coupled with the super-resolution and explicit 3D representations, opens up exciting possibilities for a wide range of applications, from gaming and design to virtual reality. Hunyuan3D-1.0 balances geometric accuracy and texture detail, revolutionizing industries reliant on 3D modeling and enhancing user experiences across various domains.
Moreover, it allows for continuous improvement and customization, adapting to new trends in design and user needs. This level of flexibility ensures that it stays at the forefront of 3D modeling technology, offering businesses a competitive edge in an ever-evolving digital landscape. It’s more than just a tool—it’s a catalyst for innovation.
Key Takeaways
- The Hunyuan3D-1.0 method efficiently generates 3D models in under 10 seconds using multi-view images and sparse-view reconstruction, making it ideal for practical applications.
- The adaptive CFG scale improves both the geometry and texture of generated 3D models, ensuring high-quality results for different views.
- The combination of calibrated and uncalibrated inputs, along with a super-resolution approach, ensures more accurate and detailed 3D shapes, addressing challenges faced by previous methods.
- By converting implicit shapes into explicit meshes, the model delivers 3D models that are ready for real-world use, allowing for further artistic refinement.
- This two-stage process of Hunyuan3D-1.0 ensures that complex 3D model creation is not only faster but also more accessible, making it a powerful tool for industries that rely on high-quality 3D assets.
References
- https://arxiv.org/pdf/2411.02293
- https://github.com/Tencent/Hunyuan3D-1
- https://huggingface.co/tencent/Hunyuan3D-1
Frequently Asked Questions
Q1. Can Hunyuan3D-1.0 completely eliminate human intervention in the creation of 3D model?
A. No, it cannot completely eliminate human intervention. However, it can significantly boost the development workflow by drastically reducing the time required to generate 3D models, providing nearly complete outputs. Users may still need to make final refinements or adjustments to ensure the models meet specific requirements, but the process is much faster and more efficient than traditional methods.
Q2. Does Hunyuan3D-1.0 require advanced 3D modeling skills?
A. No, Hunyuan3D-1.0 simplifies the 3D modeling process, making it accessible even to those without specialized skills in 3D design. The system automates the creation of 3D models with minimal input, allowing anyone to generate high-quality assets quickly.
Q3. How fast can Hunyuan3D-1.0 generate 3D models?
A. The lite model generates 3D mesh from a single image in about 10 seconds on an NVIDIA A100 GPU, while the standard model takes ~25 seconds. These times exclude the UV map unwrapping and texture baking processes, which add 15 seconds.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Over a year of working experience as an AI ML Engineer, I have developed state-of-the-art models for human body posture recognition, hand and mouth gesture recognition systems with +90% accuracies. I look forward to continue my work on data-driven machine learning.



