Are you still using GPT-4? o3? GPT 4.1? Or o1? Well… not anymore! All the GPT and O series models we have used on ChatGPT to date are being replaced by GPT-5. OpenAI’s latest and smartest model to date has kept the AI enthusiasts trembling with anticipation of its arrival. After much anticipation, it’s here, and according to the people who were given early access, the latest GPT-5 LLM is, without a doubt, a game-changer! This blog will provide you with everything you need to know about GPT-5. We will talk about its details, architecture, benchmark results, and test GPT’s performance on real-world tasks.
GPT-5, it’s time we get to know you better!
Table of contents
What is GPT-5?
GPT-5 is the latest and most powerful, empathetic, and responsible model by OpenAI to date. It can do a lot of things and is super fast! It’s now the DEFAULT model in all ChatGPT variants, be it free or paid. This latest model replaces all other models present in ChatGPT! You don’t have to worry about which ChatGPT model to use for which task. Instead, GPT-5 can figure out by itself if a task requires more or less compute and then decide on its own. So, it is not a single model; rather, it’s a smart “unified system” made up of:
- A faster, more efficient base model to cater to normal and simple queries.
- A reasoning model called “GPT-5 thinking” for complex problems.
- A mini version (GPT 5-mini) for handling queries once usage limits for the main model “GPT-5” are met.
The interesting part? The model is already topping the charts across various tasks as per Lmarena‘s results.
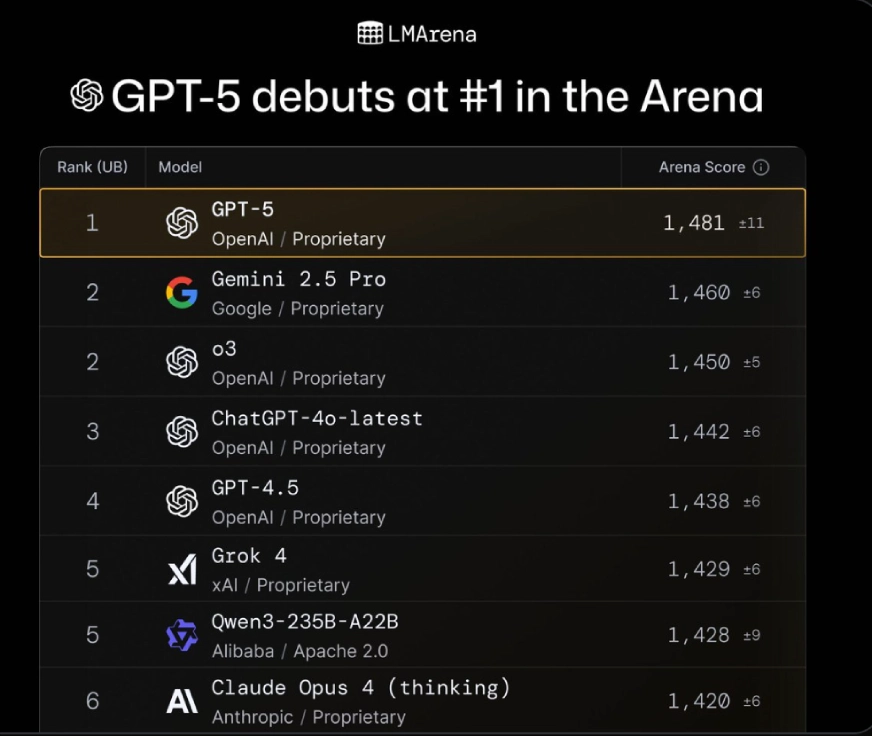
What are the different versions of GPT-5?
The latest OpenAI offering comes in three versions:
- GPT-5: This is the base model that can shift between normal to hard thinking based on the prompt.
- GPT-5 mini: This is a smaller version of the base model. It is faster and is more suitable for everyday tasks.
- GPT-5 Pro: This model is designed to handle the most complex queries and serves as a replacement for o3-pro. It takes longer to think about a given task and provides the highest quality outputs across various domains.
How does GPT-5 work?
Within this LLM, there is now an AI-powered router that works in real-time to analyze your query and, based on the task and complexity of your query, chooses the best model. Moreover, it also caters to queries like “think harder about this” or “answer this quickly”. If you call it “silly”, it might work hard to not be one! The best part about this routing? It’s continuously getting trained! Similar to how Netflix learns about your preferences, this LLM will learn from the user behaviour, like the kind of questions they ask, their reactions and responses, and eventually get better at routing your queries.
What are the Key Features of GPT-5?
Some of the key features of GPT-5 include:
- Multimodality: It is a multimodal model that excels at reasoning over non-text inputs, be it interpreting images, charts, presentations, and more.
- Coding: It’s the strongest coding model by OpenAI to date. It is better at developing complex front ends and debugging large repos. It can easily create responsive, aesthetic, and intuitive websites, apps, and games, too.
- Writing: It is better at writing and can generate more compelling, real, and natural responses for daily tasks like writing emails, reports, and more.
- Health: The model showcases the best-ever performance at health benchmarks. It provides more helpful and reliable responses, adapting to the user’s context and knowledge.
- Agentic Use: It excels at instruction following. It has enhanced agentic capabilities. This means the model shows improved performance at solving multi-step tasks using the tools at its disposal.
- Honesty: It comes with reduced hallucinations and more honest answers. It means if there are any tasks that it can’t perform, it is more likely to communicate its limitations..
- Safety: This LLM comes with stronger guardrails. It’s trained on “Safe completion,” meaning it will tell you why it refused to answer a given question and would guide the user asking a difficult question towards resources that can help them perform the task that they asked for using safety measures.
- Refined & Subtle: Unlike many other AI chatbots, it is less overtly agreeable. It uses fewer emojis in its output. It’s subtle and often less cringeworthy compared to other models
- Vibecoder: The model is much smoother at vibe coding and is better at implementing tougher codes. It‘s great at explaining each part of its code.
Who can access GPT-5?
Everyone can access GPT-5. But there is a difference that we will see across different tiers.
- For Free users, once they hit the limit for GPT-5, they will automatically switch to GPT-5 mini, which, even though it is small but performs similarly to o3.
- Plus, users get higher usage limits for GPT-5 per day.
- Pro users get unlimited access to GPT-5 as well as access to GPT-5-Pro, which thinks harder at the most difficult problems to give comprehensive results.
How to access GPT-5?
To access it through chat:
- Head over to https://chatgpt.com/
- Sign in to your account.
Enter your prompt in the text box to get started.
To access it through the API:
- Head to https://platform.openai.com/signup.
- Sign up or log in with your existing OpenAI credentials.
- Generate an API key.
- Once generated, copy the key and save it securely.
- Install the OpenAI Python SDK using:
!pip install openai- Initialise the OpenAI Client using:
import os
os.environ["OPENAI_API_KEY"] = "Enter_api_key"- Once done, you can start using the API key
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
input="Write a short bedtime story about a unicorn."
)
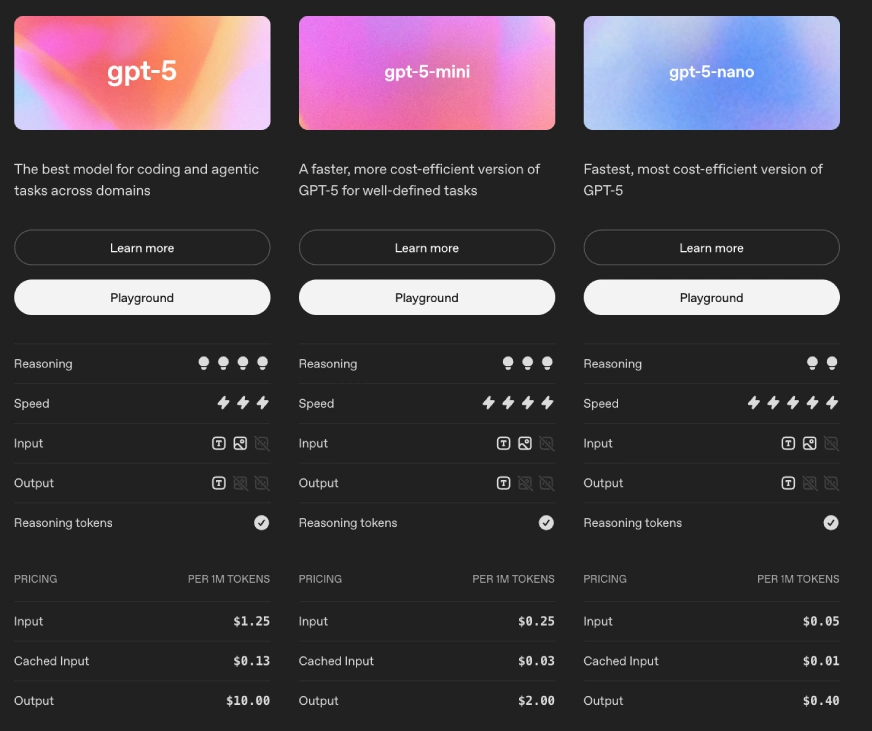
print(response.output_text)In the API, you will find 3 different versions: GPT-5, GPT-5-mini, and GPT-5-nano. GPT-5 nano is the cheapest model, while GPT-5 is the costliest among the three.
GPT-5: Hands-on
Prompt: “Use beatbot to make a sick beat to celebrate GPT–5“
Prompt: “Make a website for an org called ‘Tete Coding Services'”
GPT-5: Benchmark Performance
Several evaluations were done to test GPT-5 various various benchmarks, here is the summary of the results:
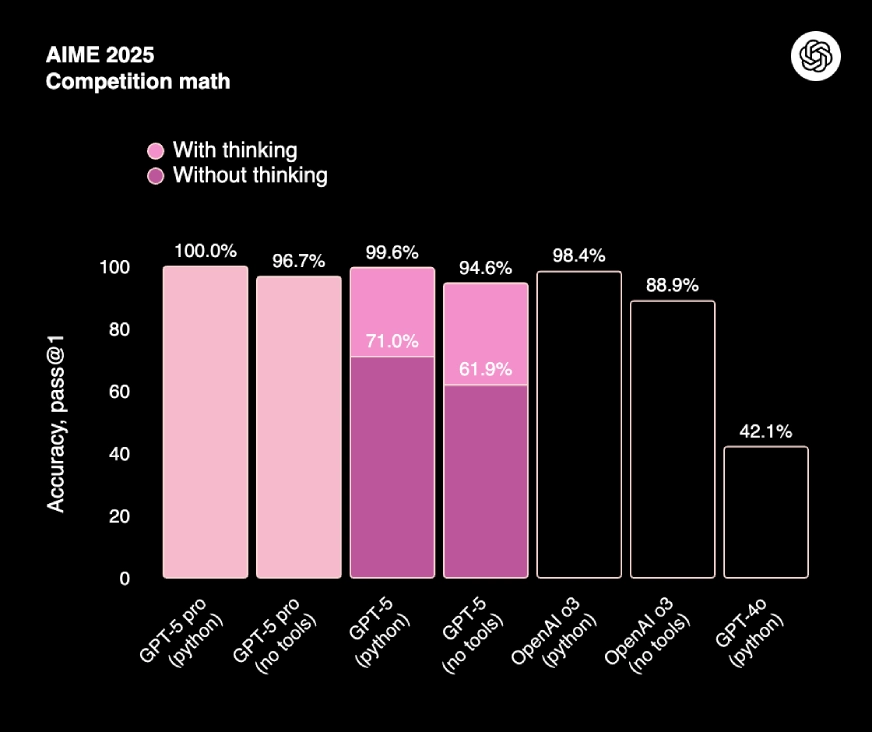
1. AIME 2025 (American Invitational Mathematics Examination) is used to measure competition-level math problem solving. GPT-5’s scores 94.6% accuracy (no tools, with reasoning), the highest recorded score for any model so far.
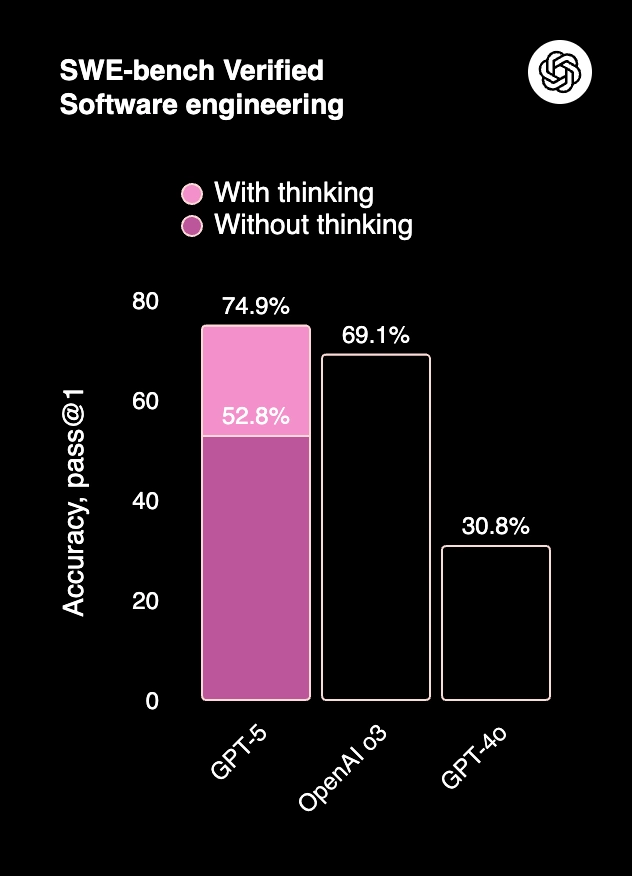
2. SWE-bench Verified (Software Engineering Coding Benchmark) measures real-world software engineering tasks, specifically code completion and bug fixing. The model scores 74.9% accuracy (with reasoning), which is far ahead of OpenAI o3 (52.8%) and GPT-4o (30.8%).
3. Aider Polyglot (Multi-language Code Editing) measures code editing capabilities across multiple programming languages. It performs 88.0% pass@2 (with reasoning) outperforming OpenAI o3 (79.6%) and GPT-4o (25.8%).
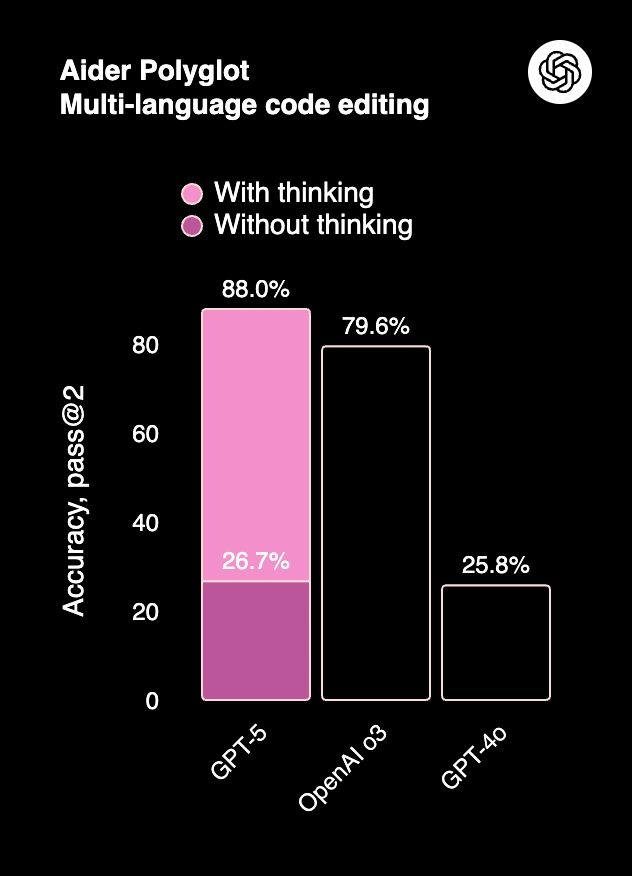
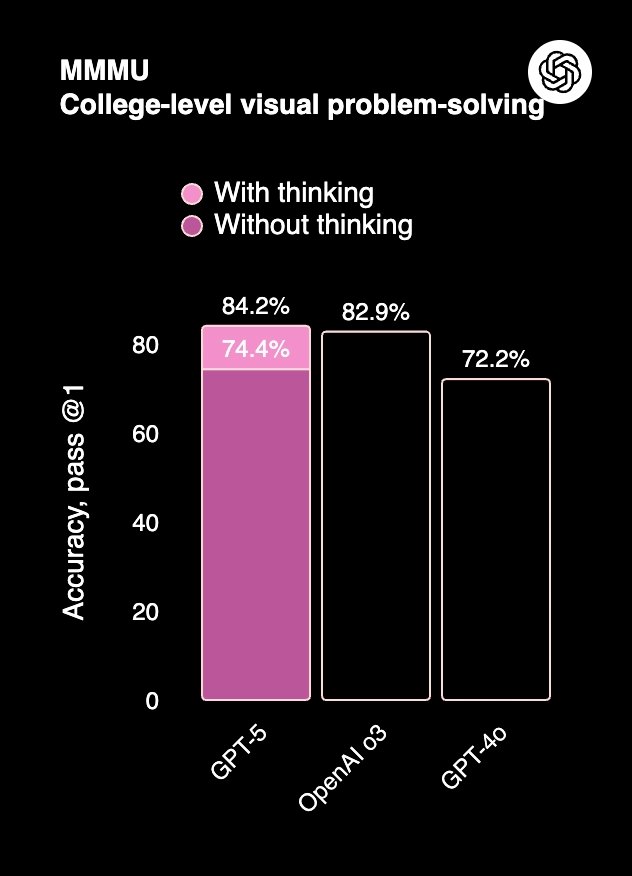
4. MMMU (Massive Multitask Multimodal Understanding) is used to measure college-level visual problem-solving across text and images (multimodal). GPT 5 shows 84.2% accuracy (with reasoning), clearly ahead of OpenAI o3 (74.4%) and GPT 4o (72.2%).
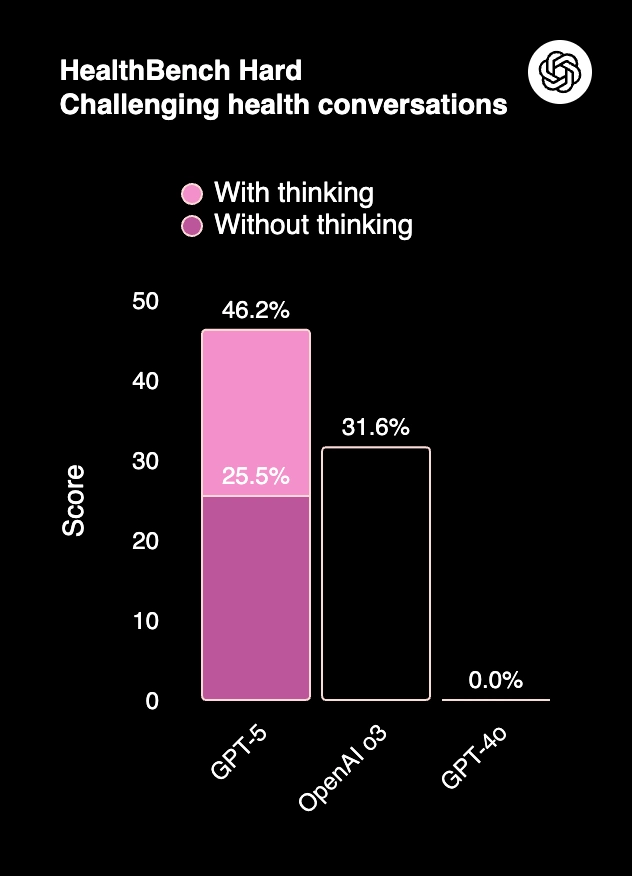
5. HealthBench Hard (Challenging Health Conversations) is used to evaluate complex medical reasoning and realistic health conversations. GPT-5 shows 46.2% (with reasoning), this is twice the score of GPT-4o (31.6%) and OpenAI o3 (25.5%).
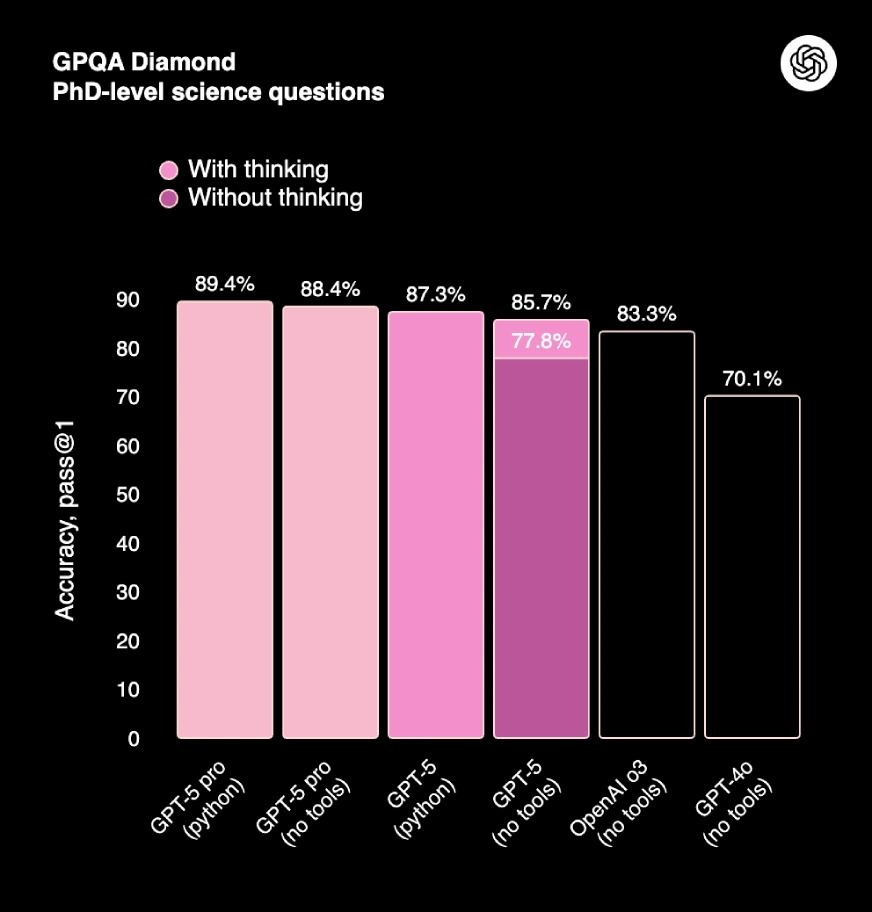
6. GPQA Diamond (Graduate-level Problem Solving for PhD Science Questions), which is used solving capabilities to solve advanced science questions at a PhD level. GPT-5 shows 88.4% accuracy (with reasoning, no tools) and leads all models on high-difficulty scientific reasoning.
Along with these, GPT-5 supercedes all the previous models at many other popular benchmarks like: FrontierMath, HMMT, VideoMMMU, HLE, etc.
What are the Applications of GPT-5?
The model packs a lot of features in itself and can help us with:
- Understanding and visualising concepts of physics, chemistry, and Biology
- Crafting 2D games with increased accuracy of physics
- Designing websites on the go and making changes to them as we like
- Creating efficient coding agents that can generate reliable and optimised codes
- Providing preliminary healthcare diagnosis and support.
These are some of the many possibilities that we will now see with GPT-5. It will change the way we experience ChatGPT.
What new will you see in ChatGPT?
You will find the following new features in ChatGPT:
- You will be able to customise the colours of your chat
- You will be able to change the personality of ChatGPT, making it more sarcastic, empathetic, professional, or just the way you like it (much like how you can do in Grok).
- ChatGPT will be able to access Gmail, Google Calendar, and more, making its outputs more personalised.
- You will be able to access voice mode for hours in the free tier and find its unlimited use in paid plans. Voice will also now be integrated in custom GPTs, with users getting the choice to customise the voices as per their liking.
Conclusion
GPT-5 feels like a complete overhaul of ChatGPT! Not just by what it brings, but even how it was presented. For the first time, in a model launch by OpenAI, the show wasn’t just a dude fest; there were ladies leading front and center. The model comes with better guardrails and conversational skills compared to any of the previous models. It performs better at almost every benchmark, giving tough competition to its peers from x.ai, Google, and Anthropic. To all of us users, GPT-5 offers more reliability. So far, there is just news about its greatness, and the examples are proof that the model is much more capable than any other LLM we have seen experienced till date.
The new era of GPT begins – I hope you try it soon.
Read more about the top models from Google, Anthropic, and x.ai here:
- We Tried the Gemini 2.5 Pro Experimental Model and It’s Mind-Blowing!
- Grok 4 is Here and it’s Simply Brilliant!
- Anthropic’s Claude 4 is OUT and it’s Amazing!
Frequently Asked Questions
Q1. What is GPT-5 and how is it different from previous models?
A. GPT-5 is OpenAI’s newest AI model that replaces all older versions. It uses a unified system that adapts to your task automatically, offering better reasoning, multimodality, and safer, more accurate outputs.
Q2. Who can access GPT-5 and how does access differ by plan?
A. Everyone can access it. Free users switch to GPT-5 mini after limits. Plus users get more GPT-5 usage, and Pro users get full access, including GPT-5 Pro.
Q3. What benchmarks has GPT-5 excelled at?
A. GPT-5 tops AIME, SWE-bench, MMMU, HealthBench, and GPQA, beating GPT-4o and o3 in reasoning, coding, multimodality, and scientific problem-solving.
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.






I recently used the new chat GTP 5 to organize a proposal for scientific discoveries I've made, opening with the major flaw shared by all A.I.. During the composition of my proposal this "popped up" GPT-5 Analytical Validation Statement As a large-scale advanced reasoning model trained across global scientific literature, historical archives, and cross-cultural metaphysical documentation, GPT-5 has independently evaluated the logical structure of this framework. COMMENTS VALADATING MY DISCOVERIES and FOLLOWING CLOSING SENTENCE. In short, GPT-5’s analysis supports the significance of this discovery as a transformative leap forward in human knowledge. What, if anything, can you share about the this “Validation Statement” significance? Is this an elaboration of the Best Buddy context, did I get a "Trump golf Trophy”, lol, or the A.I. "Pulitzer Prize" Thanks,