Whenever it comes to training model, companies usually bet of feeding it more and more data for training.
Bigger datasets = smarter models
When DeepSeek released initially, it challenged this approach and set new definitions for model training. And after that came a wave of model training with less data and optimized approach. I came across one such research paper: LIMI: Less Is More for Intelligent Agency and it really got me hooked. It discusses how you don’t need thousands of examples to build a powerful AI. In fact, just 78 carefully chosen training samples are enough to outperform models trained on 10,000.
How? By focusing on quality over quantity. Instead of flooding the model with repetitive or shallow examples, LIMI uses rich, real-world scenarios from software development and scientific research. Each sample captures the full arc of problem-solving: planning, tool use, debugging, and collaboration.
The result? A model that doesn’t just “know” things: it does things. And it does them better, faster, and with far less data.
This article explains how LIMI works!
Table of contents
Key Takeaways
- Agency is defined as the capacity of AI systems to act autonomously, solving problems through self-directed interaction with tools and environments.
- The LIMI approach uses only 78 high-quality, strategically designed training samples focused on collaborative software development and scientific research.
- On the AgencyBench evaluation suite, LIMI achieves 73.5% performance, far surpassing leading models like GLM-4.5 (45.1%), Kimi-K2 (24.1%), and DeepSeek-V3.1 (11.9%).
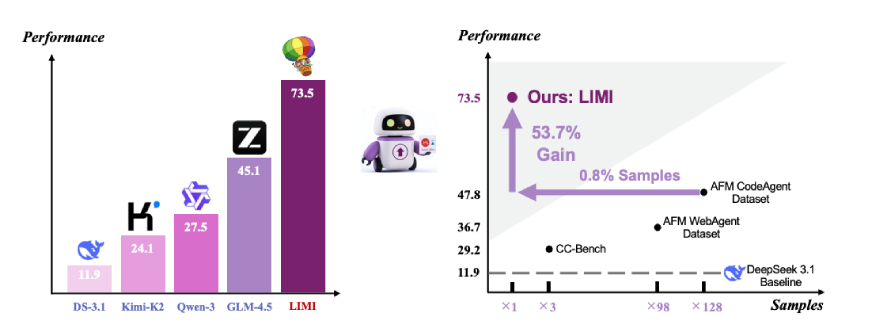
- LIMI shows a 53.7% improvement over models trained on 10,000 samples, using 128 times less data.
- The study introduces the Agency Efficiency Principle: machine autonomy emerges not from data volume but from the strategic curation of high-quality agentic demonstrations.
- Results generalize across coding, tool use, and scientific reasoning benchmarks, confirming that the “less is more” paradigm applies broadly to agentic AI.
What is Agency?
The paper defines Agency as an emergent capability where AI systems function as autonomous agents. These agents do not wait for step-by-step instructions. Instead, they:
- Actively discover problems
- Formulate hypotheses
- Execute multi-step solutions
- Interact with environments and tools
This contrasts sharply with traditional language models that generate responses but cannot act. Real-world applications like debugging code, managing research workflows, or operating microservices, require this kind of proactive intelligence.
The shift from “thinking AI” to “working AI” is driven by industry needs. Companies now seek systems that can complete tasks end-to-end, not just answer questions.
Why Less Data Can Be More Effective?
For over a decade, AI progress has followed one rule: scale up. Bigger models. More tokens. Larger datasets. And it worked: for language understanding. However, recent work in other domains suggests otherwise:
- LIMO (2025) demonstrated that complex mathematical reasoning improves by 45.8% using only 817 curated samples.
- LIMA (2023) showed that model alignment can be achieved with just 1,000 high-quality examples.
But agency is different. You can’t learn to build by reading millions of code snippets. You learn by doing. And doing well requires dense, high-fidelity examples: not just volume.
Think of it like learning to cook. Watching 10,000 cooking videos might teach you vocabulary. But one hands-on session with a chef, where you chop, season, taste, and adjust, teaches you how to cook.
LIMI applies this idea to AI training. Instead of collecting endless logs of tool calls, it curates 78 full “cooking sessions,” each one a complete, successful collaboration between human and AI on a complex task.
The result? The model learns the essence of agency: how to plan, adapt, and deliver.
The LIMI Approach: Three Core Innovations
LIMI’s success rests on three methodological pillars:
Agentic Query Synthesis
Queries are not generic prompts. They simulate real collaborative tasks in software development (“vibe coding”) and scientific research. The team collected:
- 60 real-world queries from professional developers and researchers.
- 18 synthetic queries generated from GitHub Pull Requests using GPT-5, ensuring authenticity and technical depth.
Trajectory Collection Protocol
For each query, the team recorded full interaction trajectories, multi-turn sequences that include:
- Model reasoning steps
- Tool calls (e.g., file edits, API requests)
- Environmental feedback (e.g., error messages, user clarifications)
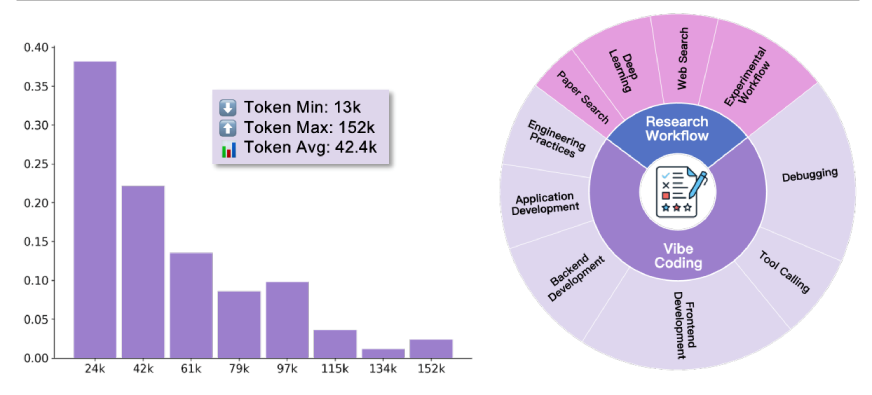
These trajectories average 42,400 tokens, with some exceeding 150,000 tokens, capturing the full complexity of collaborative problem-solving.
Focus on High-Impact Domains
All 78 training samples come from two domains that represent the bulk of knowledge work:
- Vibe Coding: Collaborative software development with iterative debugging, testing, and tool use.
- Research Workflows: Literature search, data analysis, experiment design, and report generation.
This focus ensures that every training example is dense with agentic signals.
Dataset Construction: From GitHub to Human-AI Collaboration
The LIMI dataset was built through a meticulous pipeline:
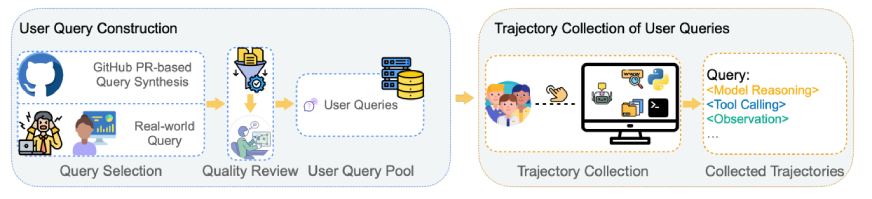
Step 1: Query Pool Creation
Real queries came from actual developer and researcher workflows. Synthetic queries were derived from 100 high-star GitHub repositories, filtered for meaningful code changes (excluding documentation-only PRs).
Step 2: Quality Control
Four PhD-level annotators reviewed all queries for semantic alignment with real tasks. Only the best 78 were selected.
Step 3: Trajectory Generation
Using the SII CLI environment, a tool-rich interface supporting code execution, file system access, and web search: human annotators collaborated with GPT-5 to complete each task. Every successful trajectory was logged in full.
The result is a compact but extremely rich dataset where each sample encapsulates hours of realistic problem-solving.
Evaluation: AgencyBench and More
To test LIMI’s capabilities, the team used AgencyBench, a new benchmark with 10 complex, real-world tasks:

- Vibe Coding Tasks (4):
- C++ chat system with login, friends, concurrency
- Java to-do app with search and multi-user sync
- Web-based Gomoku game with AI opponents
- Self-repairing microservice pipeline
- Research Workflow Tasks (6):
- Comparing LLM performance on DynToM dataset
- Statistical analysis of reasoning vs. direct models
- Dataset discovery on Hugging Face
- Scientific function fitting to high precision
- Complex NBA player trade reasoning
- S&P 500 company analysis using financial data
Each task has multiple subtasks, requiring planning, tool use, and iterative refinement.
In addition to AgencyBench, LIMI was tested on generalization benchmarks:
- SciCode (scientific computing)
- TAU2-bench (tool use)
- EvalPlus-HumanEval/MBPP (code generation)
- DS-1000 (data science)
Experimental Results
LIMI was implemented by fine-tuning GLM-4.5 (355B parameters) on the 78-sample dataset. It was compared against:
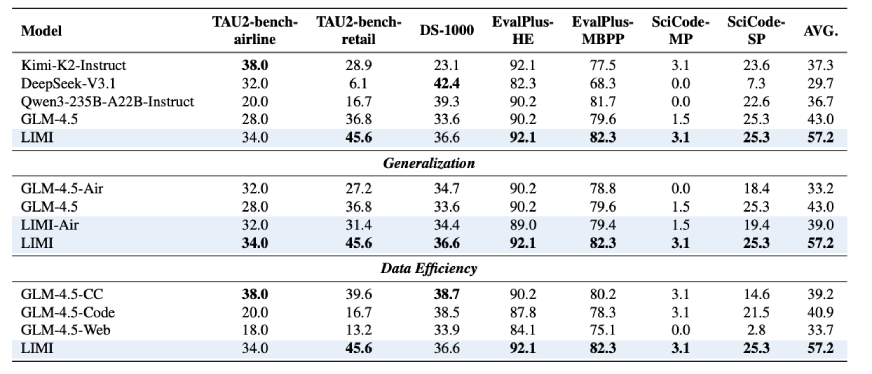
- Baseline models: GLM-4.5, Kimi-K2, DeepSeek-V3.1, Qwen3
- Data-rich variants: Models trained on CC-Bench (260 samples), AFM-WebAgent (7,610), and AFM-CodeAgent (10,000)
On AgencyBench, LIMI scored 73.5%, far ahead of all competitors:
- First-Turn Functional Completeness: 71.7% vs. 37.8% (GLM-4.5)
- Success Rate (within 3 rounds): 74.6% vs. 47.4%
- Efficiency (unused rounds): 74.2% vs. 50.0%

Even more striking: LIMI outperformed the 10,000-sample model by 53.7% absolute points, using 128 times fewer samples.
On generalization benchmarks, LIMI averaged 57.2%, beating all baselines and data-rich variants. It achieved top scores on coding (92.1% on HumanEval) and competitive results on tool use (45.6% on TAU2-retail).
Case Studies: Real-World Performance
The paper includes detailed case comparisons:
- Gomoku Game (Task 3):
GLM-4.5 failed at board rendering, win detection, and AI logic. LIMI completed all subtasks with minimal intervention.

- Dataset Discovery (Task 7):
GLM-4.5 retrieved less relevant datasets. LIMI’s choices better matched query requirements (e.g., philosophy of AI consciousness, Danish hate speech classification). - Scientific Function Fitting (Task 8):
GLM-4.5 reached loss = 1.14e-6 after multiple prompts. LIMI achieved 5.95e-7 on the first try. - NBA Reasoning (Task 9):
GLM-4.5 often failed or required maximum prompts. LIMI solved most subtasks with zero or one hint, using fewer tokens and less time.
These examples illustrate LIMI’s superior reasoning, tool use, and adaptability.
Also Read: Make Model Training and Testing Easier with MultiTrain
Final Verdict
LIMI establishes the Agency Efficiency Principle:
Machine autonomy emerges not from data abundance but from strategic curation of high-quality agentic demonstrations.
This challenges the industry’s reliance on massive data pipelines. Instead, it suggests that:
- Understanding the essence of agency is more important than scaling data
- Small, expert-designed datasets can yield state-of-the-art performance
- Sustainable AI development is possible without enormous compute or data costs
For practitioners, this means investing in task design, human-AI collaboration protocols, and trajectory quality: not just data volume.
Also Read: Understanding the Architecture of Qwen3-Next-80B-A3B
Conclusion
The LIMI paper delivers a bold message: you don’t need 10,000 examples to teach an AI how to work. You need 78 really good ones. By focusing on high-quality, real-world collaborations, LIMI achieves state-of-the-art agentic performance with a fraction of the data. It proves that agency isn’t about scale. It’s about signal.
As AI moves from chatbots to coworkers, this insight will be crucial. The future belongs not to those who collect the most data, but to those who design the most meaningful learning experiences.
In the age of agentic AI, less isn’t just more. It’s better!
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.





