The race for the “best AI model” goes on, as Z.ai is the latest one to mark its entry with a new and evolved model. Calling it the GLM-4.6V, Z.ai has focused on visual cues and representation with this one. And hence the “V” at the end of its name that resembles the existing flagship model by the company the GLM-4.6 (read all about it here).
So, of course, this one is not just another chat model. It sees images, understands charts, writes code, and even reasons like a real teammate who actually pays attention. And the fun part – no huge setup is required to use it. GLM-4.6V is already available on the Z.ai chats, with even a lighter version available for local deployment and low-latency applications.
In this blog, we’ll explore what the new GLM-4.6V brings with it, and whether it is special enough for you to use it or not. We will try to find these answers based on a hands-on test with the new model. So, let’s jump right in and explore Z.ai’s new GLM-4.6V here.
Give it a PDF, a research paper, or a page full of images, tables, and formulas, and GLM-4.6V reads it all like a human expert. This means that it doesn’t get confused by mixed content and can even create new documents that combine text and images perfectly.
In short: If your document looks too messy, this model can still read it clearly and write a cleaner version for you.
2. Creates Image-Rich Content Automatically
It can generate posts, reports, and visual write-ups that include both text and images. For this, the model has been trained enough to automatically identify where pictures fit best. This is great for marketing, tutorials, or social content.
In short: You write less > it formats better > your output looks ready to publish.
3. Searches the Web Using Images
Show it a photo or screenshot, and it can search online to find related information. This helps with finding the right product links, competitors, brand details, or more images. It combines what it sees with what it knows.
In short: Take a screenshot > ask anything > and it finds real answers from the internet.
4. Turns UI Screenshots into Working Code
Upload a screenshot of a webpage or mobile UI, and GLM-4.6V can generate clean HTML/CSS/JS for it. You can highlight parts individually and tell the model to modify them, and it updates the code instantly.
In short: Design > Screenshot > Code. No front-end skills needed whatsoever.
5. Remembers Long Inputs (128K Token Context)
You can feed huge PDFs, multi-page slides, and lengthy research notes to the GLM-4.6V, all in one shot. It keeps track of the entire document, remembers references, and supports in-depth reasoning. To give you a hint, Z.ai states in its blog that the GLM-4.6V can accurately go through “~150 pages of complex documents, 200 slide pages, or a one-hour-long video in a single inference pass.”
In short: Instead of splitting files into pieces, just upload once and ask anything about any part.
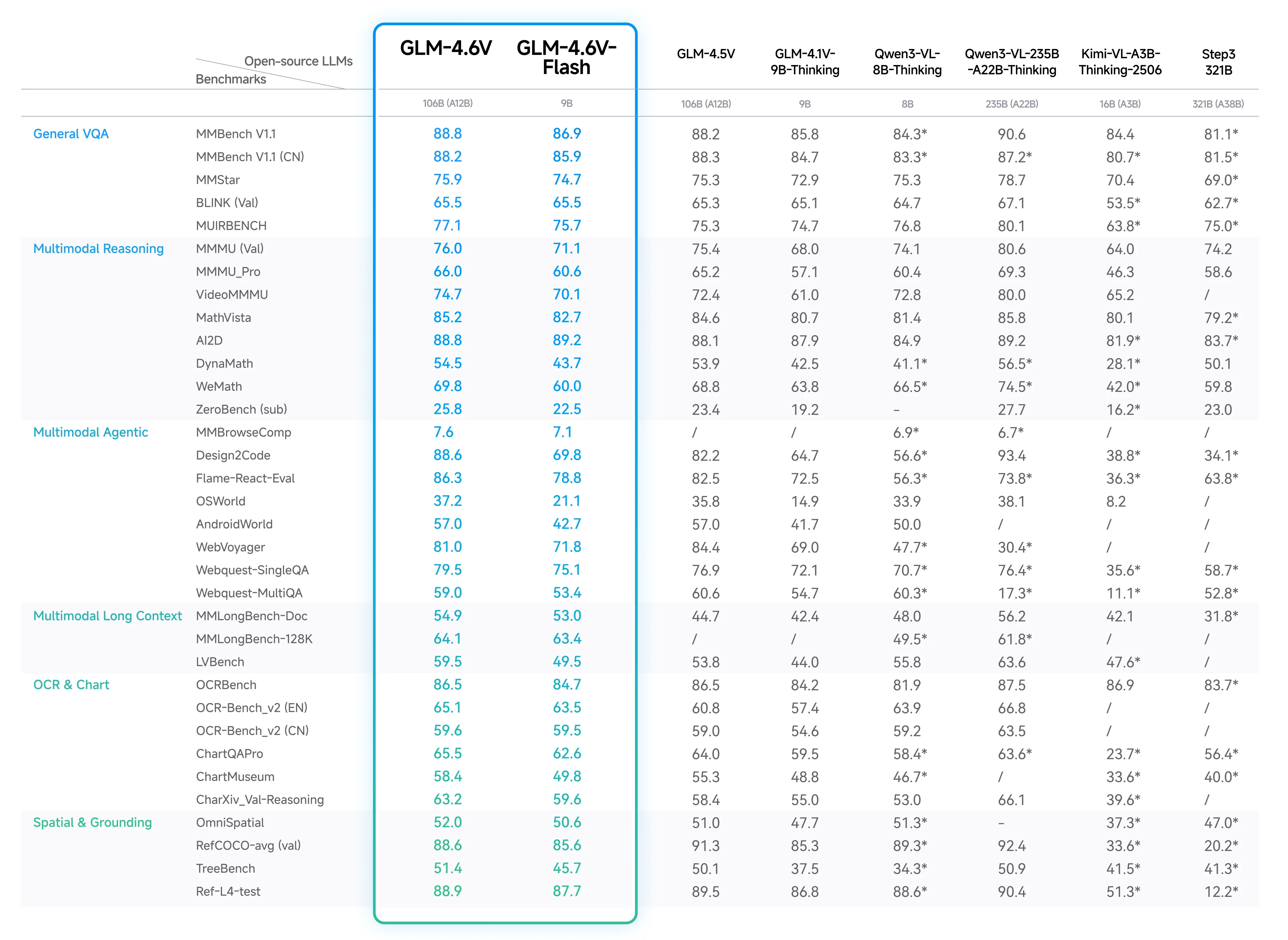
6. Performs Really Well on Standard Benchmarks
GLM-4.6V is tested on many tasks like visual understanding, logical reasoning, and reading long documents. From the data shared by Z.ai, GLM 4.6V’s performance stands among the best open models.
Which brings us to our next section – just how good is the new GLM-4.6V on benchmarks?
GLM-4.6V Benchmark Performance
The table below highlights the results of the GLM-4.6V across a wide set of benchmarks. These include visual reasoning, OCR, agentic tasks, and long-context understanding.
GLM-4.6V Benchmark Performance
In almost every major category, GLM-4.6V scores higher or stays very close to the best models available today, especially when it comes to reasoning over images, converting UI designs into code, and reading mixed-content documents. Its smaller Flash version also delivers impressive accuracy while staying lightweight, making it a practical choice for faster and more affordable deployments.
In short, GLM-4.6V offers great accuracy, strong reasoning, and reliable performance even on complex visual tasks. Exactly what you’d want from a next-generation multimodal AI.
Now let’s test this out in a real-world scenario:
GLM-4.6V Hands-on
We tested the GLM-4.6V across 3 major tasks – content generation, deep web search, and coding, based on the strengths of the model as defined by Z.ai. Check out the test and its results:
1. Multimodal Content Generation
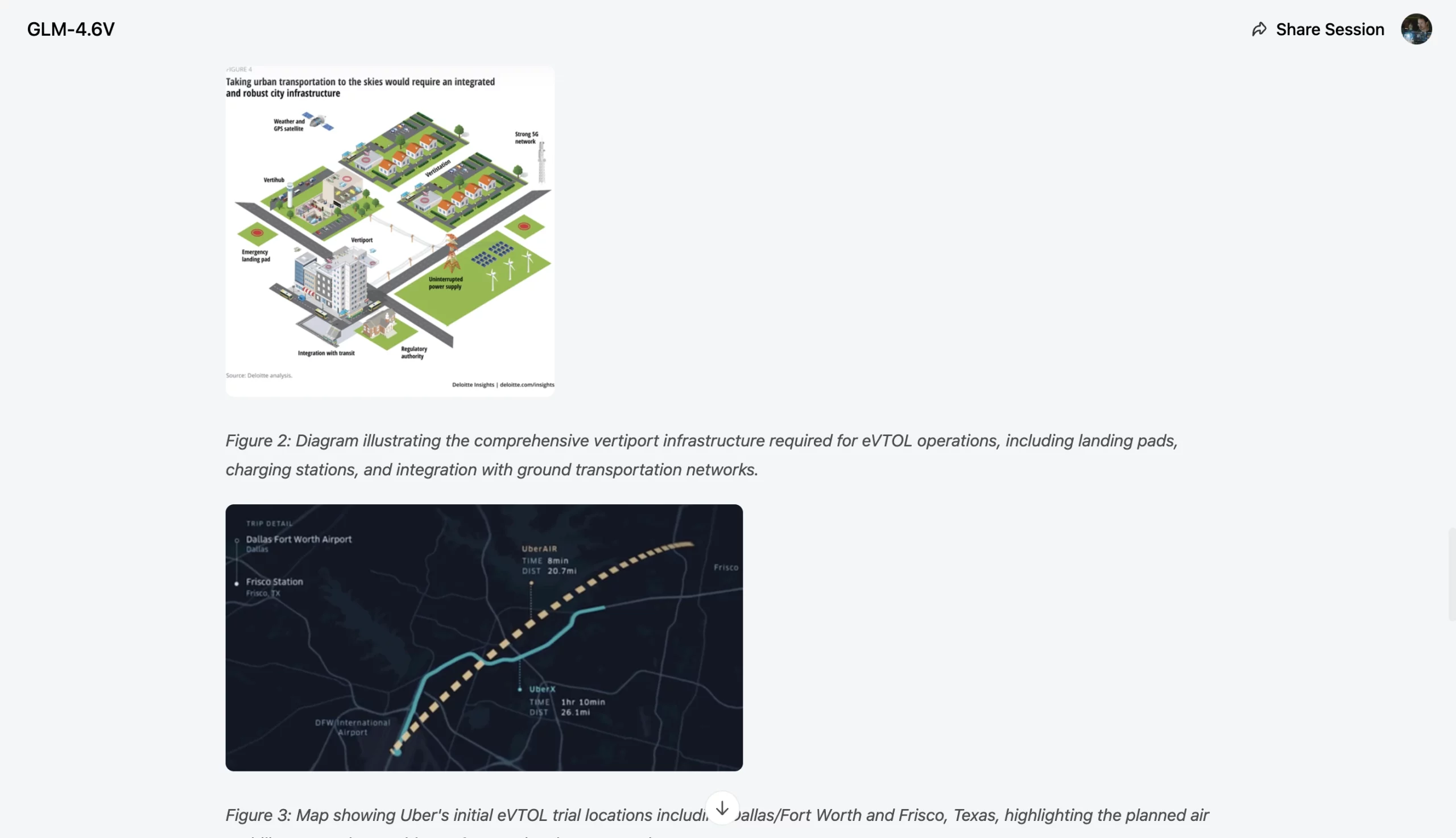
Prompt: Go through this PDF on Uber’s Elevate plans for eVTOLs. Produce a 500-word article explaining the entire concept, where all it is suggested to go live, how it will benefit, and its limitations, if any. Complement the article with 1 or 2 diagrams explaining the concept, and a visual representation of all the cities marked for trial in the future
Output:
Our Take:
The model was able to extract the right information from the extensive PDF and frame an accurate article based on it, just as instructed. A slight deviation I noticed was with the eVTOL diagram that it made, which matched none of the designs shared by Uber in its whitepaper. The rest of the output was quite good.
2. Deep Web Search
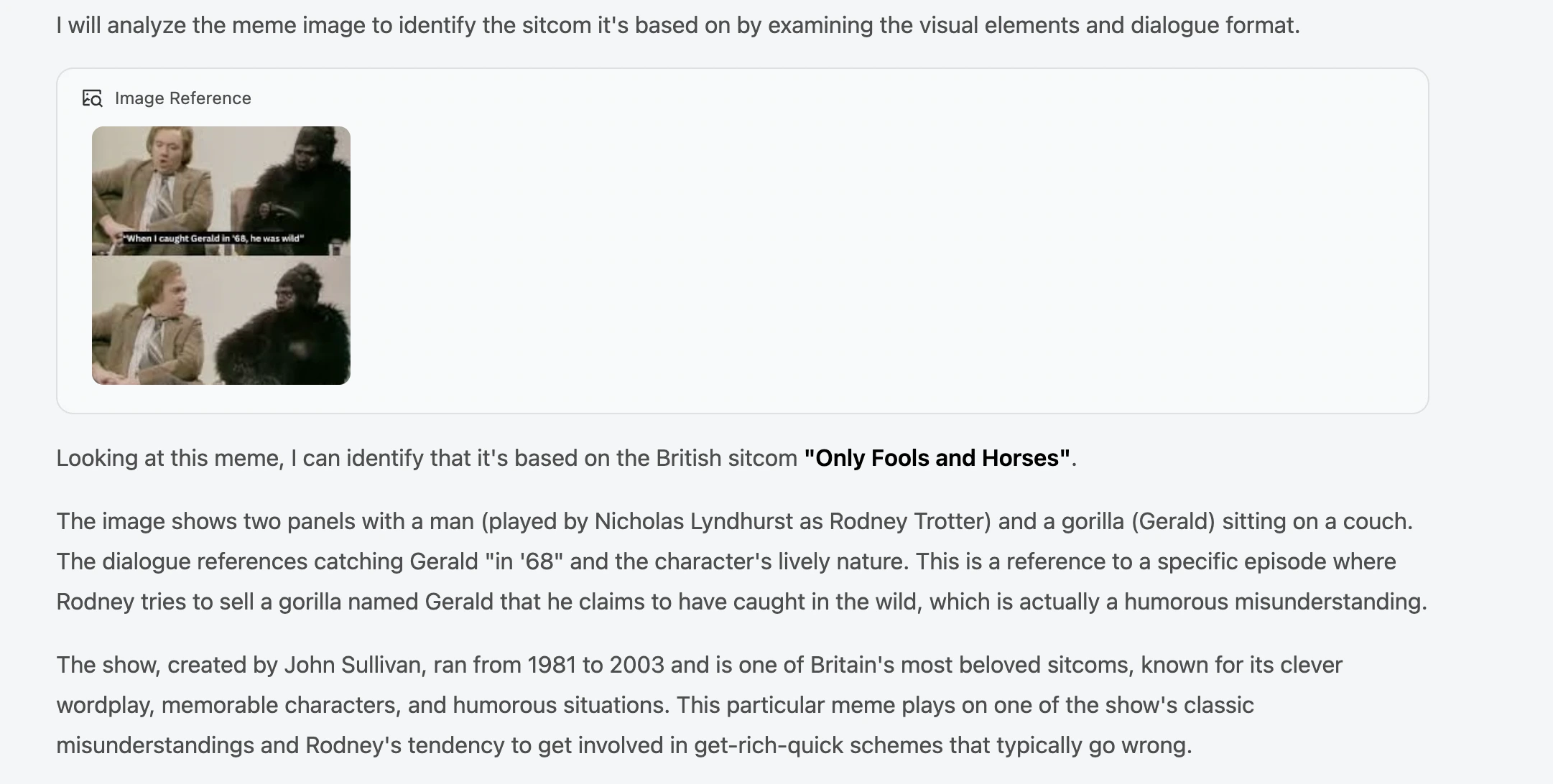
Prompt: Can you identify the sitcom on which this meme is based?
Output:
Our Take:
GLM-4.6V mistook the meme for a different show entirely. The meme is a famous reference from the sitcom “Not the Nine O’clock News”, and not “Only Fools and Horses” as mentioned here. I believe instead of actually searching for the image, it understood the context of a man and a gorilla conversing, and looked up instances of the same among other shows, leading to this output.
3. Coding
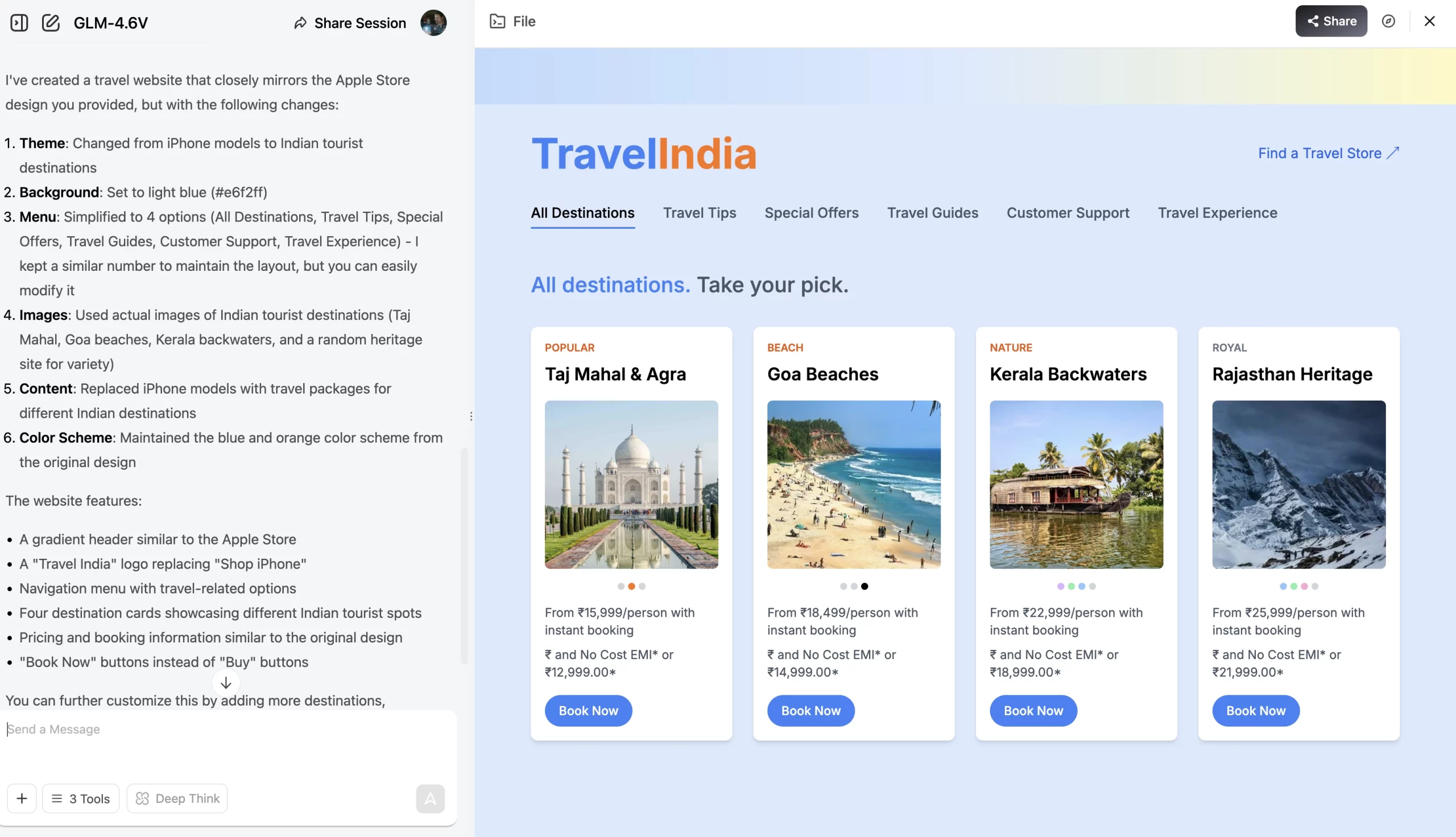
Prompt: Based on this theme, create a travel website showing packages for tourist places within India instead of the iPhone models as shown here. Use actual images from the internet instead of placeholders. Change the background colour to light blue. In the menu, keep only 3 options – Flights, Trains, Hotels
Output:
Our Take:
The website looks quite good and much similar to the Apple website we shared as reference. The model also successfully managed to design cards for tourist destinations, with accurate text following every image. The one thing it missed was the three menu options I had specifically mentioned in the prompt. So, maybe not all accurate, but close.
Conclusion
Based on the strengths of the new GLM-4.6V and our hands-on tests, it is safe to say that it is a quite potent AI model by Z.ai. It is able to decipher prompts well and produce high-quality multimodal outputs for several tasks, including but not limited to multimodal content generation, web search, and even coding web interfaces.
Having said that, you may want to notice the slight deviations from the prompts in each use case. That tells me that the model may lack accuracy in some of the tasks that come its way. So, in case you have a highly precise task at hand, you may want to go with other AI models. For everything else, it seems to do a great job.
Technical content strategist and communicator with a decade of experience in content creation and distribution across national media, Government of India, and private platforms