The future of artificial intelligence is here and to the developers, it is in the form of new tools that transform the way we code, create and solve problems. GLM-4.7 Flash, an open-source large language model by Zhipu AI, is the latest big entrant but not simply another version. This model brings great power and astonishing efficiency, so state-of-the-art AI in the field of code generation, multi-step reasoning and content generation contributes to the field as never before. We should take a closer look at the reasons why GLM-4.7 Flash is a game-changer.
Table of contents
Architecture and Evolution: Smart, Lean, and Powerful
GLM-4.7 Flash has at its core an advanced Mixture-of-Experts (MoE) Transformer architecture. Think about a team of specialized professionals; suppose, each and every expert is not engaged in all the problems, but only the most relevant are engaged in a particular task. This is how MoE models work. Although the entire GLM-4.7 model contains enormous and huge (in the thousands) 358 billion parameters, only a sub-fraction: about 32 billion parameters are active in any particular query.
GLM-4.7 Flash version is yet simpler with approximately 30 billion total parameters and thousands of active per request. Such a design renders it very efficient since it can operate on relatively small hardware and still access a huge amount of knowledge.
Easy API Access for Seamless Integration
GLM-4.7 Flash is easy to start with. It is available as the Zhipu Z.AI API platform providing a similar interface to OpenAI or Anthropic. The model is also versatile to a broad range of tasks whether it comes to direct REST calls or an SDK.
These are some of the practical uses with Python:
1. Creative Text Generation
Need a spark of creativity? You may make the model write a poem or marketing copy.
import requests
api_url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
user_message = {"role": "user", "content": "Write a short, optimistic poem about the future of technology."}
payload = {
"model": "glm-4.7-flash",
"messages": [user_message],
"max_tokens": 200,
"temperature": 0.8
}
response = requests.post(api_url, headers=headers, json=payload)
result = response.json()
print(result["choices"][0]["message"]["content"])Output:
2. Document Summarization
It has a big context window that makes it easy to overview lengthy documents.
text_to_summarize = "Your extensive article or report goes here..."
prompt = f"Summarize the following text into three key bullet points:\n{text_to_summarize}"
payload = {
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 500,
"temperature": 0.3
}
response = requests.post(api_url, json=payload, headers=headers)
summary = response.json()["choices"][0]["message"]["content"]
print("Summary:", summary)Output:
3. Advanced Coding Assistance
GLM-4.7 Flash is indeed outstanding in coding. You may say: create functions, describe complicated code or even debug.
code_task = (
"Write a Python function `find_duplicates(items)` that takes a list "
"and returns a list of elements that appear more than once."
)
payload = {
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": code_task}],
"temperature": 0.2,
"max_tokens": 300
}
response = requests.post(api_url, json=payload, headers=headers)
code_answer = response.json()["choices"][0]["message"]["content"]
print(code_answer)Output:
Key Improvements That Matter
GLM-4.7 Flash is not an ordinary upgrade but it comes with much improvement over its other versions.
- Enhanced Coding and “Vibe Coding”: This model was optimized on large datasets of code and thus its performance on coding benchmarks was competitive with larger, proprietary models. It further brings about the notion of Vibe coding, where one considers the code formatting, style and even the appearance of UI to produce a smoother and more professional appearance.
- Stronger Multi-Step Reasoning: This is a distinguishing aspect as the reasoning is enhanced.
- Interleaved Reasoning: The model processes the instructions and then thinks (before advancing on responding or calling a tool) so that it may be more apt to follow the complex instructions.
- Preserved Reasoning: It retains its reasoning procedure over several turns in a conversation, so it will not forget the context in a complex and lengthy task.
- Turn-Level Control: Developers are able to manage the depth of reasoning made by each query by the model to tradeoff between speed and accuracy.
- Speed and Cost-Efficiency: The Flash version is focused on speed and cost. Zhipu AI is free to developers and its API rates are much lower than most competitors, which means that powerful AI can be accessible to projects of any size.
Use Cases: From Agentic Coding to Enterprise AI
GLM-4.7 Flash has the potential of many applications due to its versatility.
- Agentic Coding and Automation: This paradigm may serve as an AI software agent, which may be provided with a high-level objective and produce a full-fledged, multi-part answer. It is the best in quick prototyping and automatic boilerplate code.
- Long-Form Content Analysis: Its enormous context window is ideal when summarizing reports that are long or analyzing log files or responding to questions that require extensive documentation.
- Enterprise Solutions: GLM-4.7 Flash used as a fine-tuned self-hosted open-source allows companies to use internal data to form their own, privately owned AI assistants.
Performance That Speaks Volumes
GLM-4.7 Flash is a high-performance tool, which is proven by benchmark tests. It has been scoring top results on the difficult models of coding such as SWE-Bench and LiveCodeBench using open-source programs.
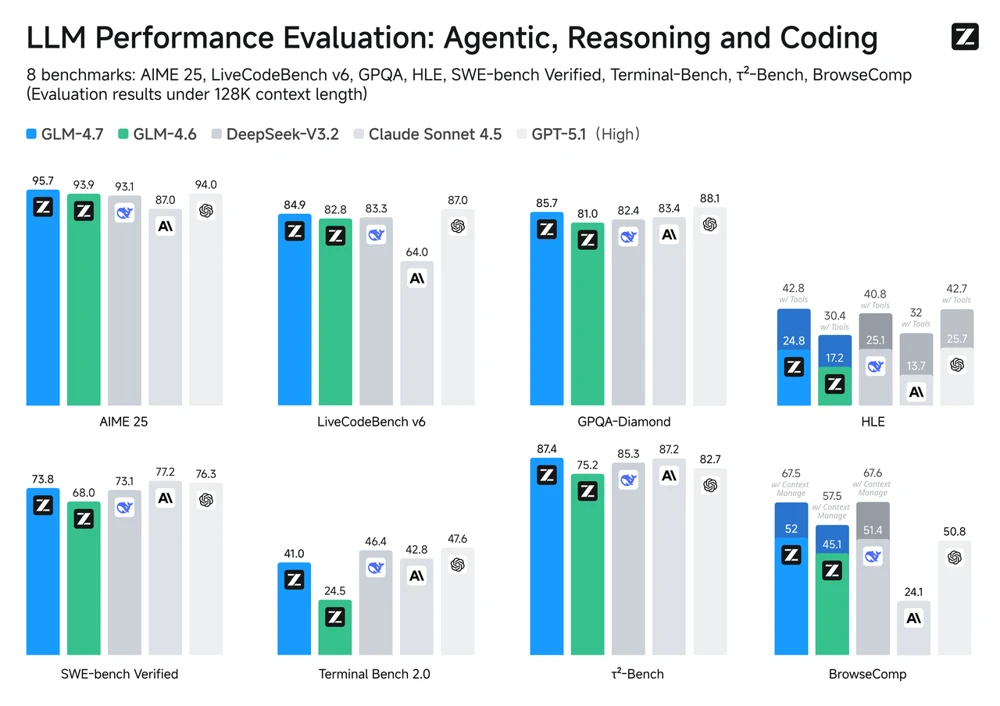
GLM-4.7 was rated at 73.8 per cent in a test at SWE-Bench, which entails the solving of real GitHub problems. It was also superior in math and reasoning, obtaining a score of 95.7 percent on the AI Math Exam (AIME) and improving by 12 percent on its predecessor in the difficult reasoning benchmark HLE. These figures show that GLM-4.7 Flash does not only compete with other models of its kind, but it usually outsmarts them.
Why GLM-4.7 Flash is a Big Deal
This model is important in a number of reasons:
- High Performance at Low Cost: It offers features that can compete with the highest end proprietary models at a small fraction of the cost. This allows advanced AI to be available to personal developers and startups, as well as massive companies.
- Open Source and Flexible: GLM-4.7 Flash is free, which means that it gives unlimited control. You can customize it for specific domains, deploy it locally to ensure data privacy, and avoid vendor lock-in.
- Developer-Centric by Design: The model is easy to integrate into developer workflows and supports an OpenAI-compatible API with built-in tool support.
- End-to-End Problem Solving: GLM-4.7 Flash is capable of helping to solve bigger and more complicated tasks in a sequence. This liberates the developers to concentrate on high-level approach and novelty, instead of losing sight in the implementation details.
Conclusion
GLM-4.7 Flash is a huge leap towards strong, useful and available AI. You can customize it for specific domains, deploy it locally to protect data privacy, and avoid vendor lock-in. GLM-4.7 Flash offers the means to create more, in less time, whether you are creating the next great app, automating complex processes, or just need a smarter coding partner. The age of the fully empowered developer has arrived and open-source schemes such as GLM-4.7 Flash are on the frontline.
Frequently Asked Questions
Q1. What is GLM-4.7 Flash?
A. GLM-4.7 Flash is an open-source, lightweight language model designed for developers, offering strong performance in coding, reasoning, and text generation with high efficiency.
Q2. What is a Mixture-of-Experts (MoE) architecture?
A. It’s a model design where many specialized sub-models (“experts”) exist, but only a few are activated for any given task, making the model very efficient.
Q3. How large is the context window for GLM-4.7 Flash?
A. The GLM-4.7 series supports a context window of up to 200,000 tokens, allowing it to process very large amounts of text at once.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






