You must have faced the never-ending wait of an AI model taking its time to answer your query. To put an end to this wait, the new Mercury 2 reasoning model of Inception Labs is now live. It works a bit differently from others. It employs diffusion to provide quality answers at nearly instant speed. In this article, we shall experience the unique qualities of the Mercury 2 reasoning model and experiment with its strengths.
Table of contents
A New Way to Think: Diffusion vs. Auto-regression
Auto-regressive decoding is a process that most large language models currently use, such as those produced by Google and OpenAI. They produce one word or token of text at a time. This acts as a typewriter, with the successive word being bound with the previous word.
Although it works, it also has a bottleneck. Difficult questions demand chains of thoughts and the model has to go through them in a sequence. This is a serial process that restricts speed and has high costs. It is particularly useful for deep reasoning processes.
The Mercury 2 reasoning model acts differently. It is among the initial commercial diffusion language models. Rather than following a token-by-token approach, it begins with a crude version of the complete answer. It then makes it better by a process of refinement. Consider it more of an editor than a typewriter. It checks and corrects the whole response simultaneously, and as such, it is able to correct the errors early in the process. The speed of this method lies in this parallelism.
This is not a new concept in AI. Diffusion models have already been successful in image and video creation. This technology is now being used by Inception Labs, a start-up by academics at Stanford, UCLA, and Cornell, and it is performing remarkably well.
Speed and Cost: The Mercury 2 Advantage
The speed of the Mercury 2 reasoning model is its most prominent quality. It has a throughput of approximately 1,000 tokens in benchmarks. In perspective, other popular models such as Claude 4.5 Haiku and GPT-5 mini run at roughly 89 and 71 tokens per second, respectively. This increases Mercury 2’s speed by more than tenfold. This is not just a figure on a chart, but it represents a difference in the real world. To handle more complicated tasks, it can take other models several seconds to answer a question. Meanwhile, Mercury 2 can answer a question in less than two seconds.

This speed does not come at any cost. As a matter of fact, Mercury 2 is much less expensive than its competitors. It has a price of 0.25 per million input tokens and an input price of 0.75 per million output tokens. It costs about 2.5 times as much to produce a response as GPT-5 mini, and more than 6.5 times as much as Claude Haiku 4.5. This speed, coupled with low cost, makes new use cases possible, particularly those applications that are based on real-time interactions and intricate loops of AI agents.
Quality and Performance
Speed can only be utilized when the responses are correct. In this regard, the Mercury 2 reasoning model stands on its own. It matches all other most popular models in terms of quality standards. It scored 91.1 on the AIME 2025 math benchmark. It also scored well in the GPQA assessment of science on the graduate level and instruction following on the IFBench. These scores indicate that the error correction nature of the diffusion process does not affect the quality at the cost of speed.
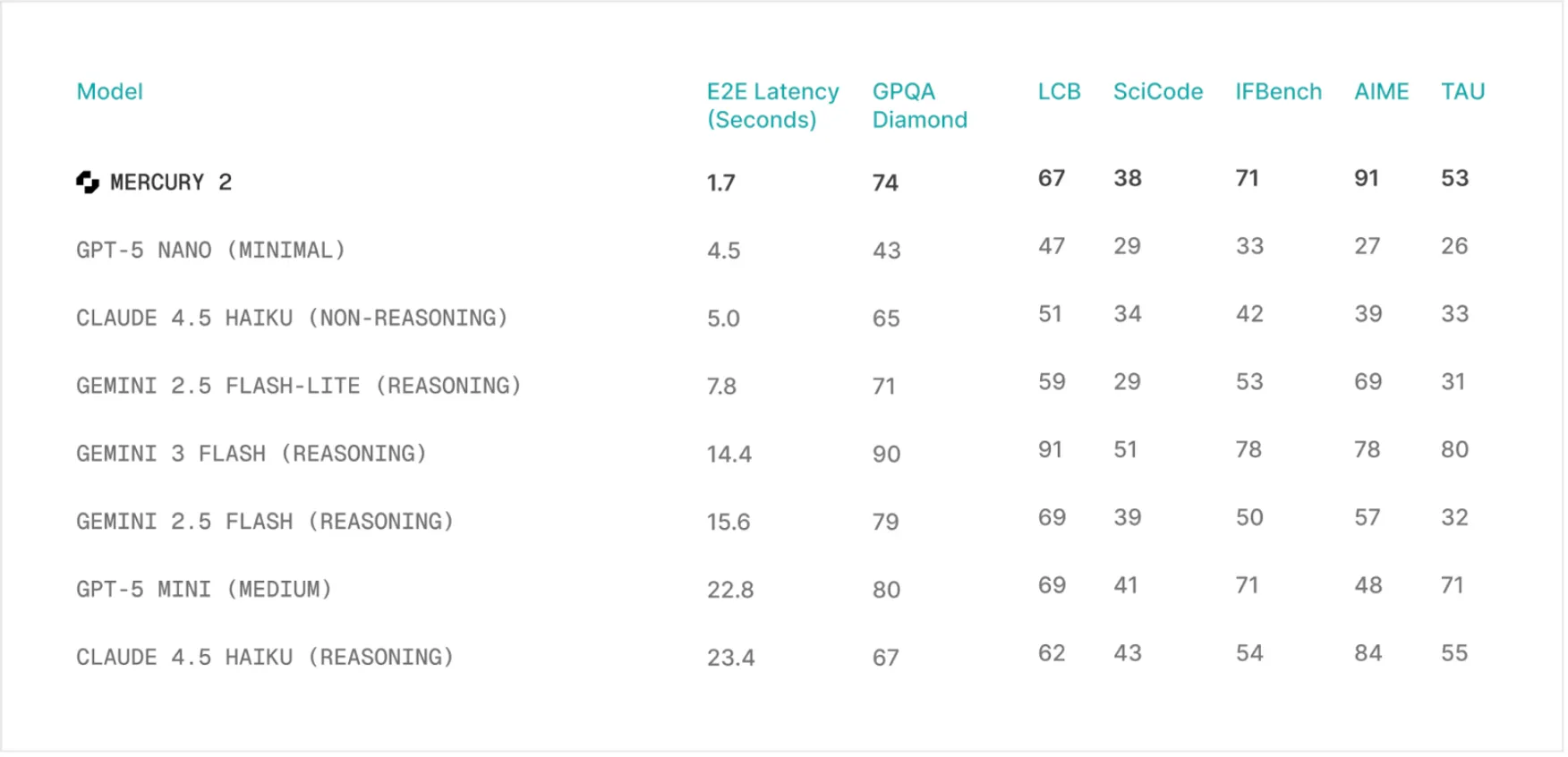
The model also encourages a 128K size context window, tool use, and JSON output. It is hence a handy tool for the developers. The features are critical in the construction of advanced applications that demand high-throughput reasoning. Its capability to process massive information and communicate with other applications makes it adequately situated in applications such as real-time voice assistants, search tools, and code assistances
Hands-On with the Mercury 2 Reasoning Model
Seeing is believing. Mercury 2 is most effectively understood by experiment. You can either interact with the model or subscribe to API access to create your own applications.
- Chat Access: https://chat-mercury2.inceptionlabs.ai/
- API Early Access: https://platform.inceptionlabs.ai
An excellent way of experimenting with the model and testing the unique capabilities is to experiment with its reasoning_effort setting. A simple, real-life problem.
The Car Wash Test
Ask the model the following question:
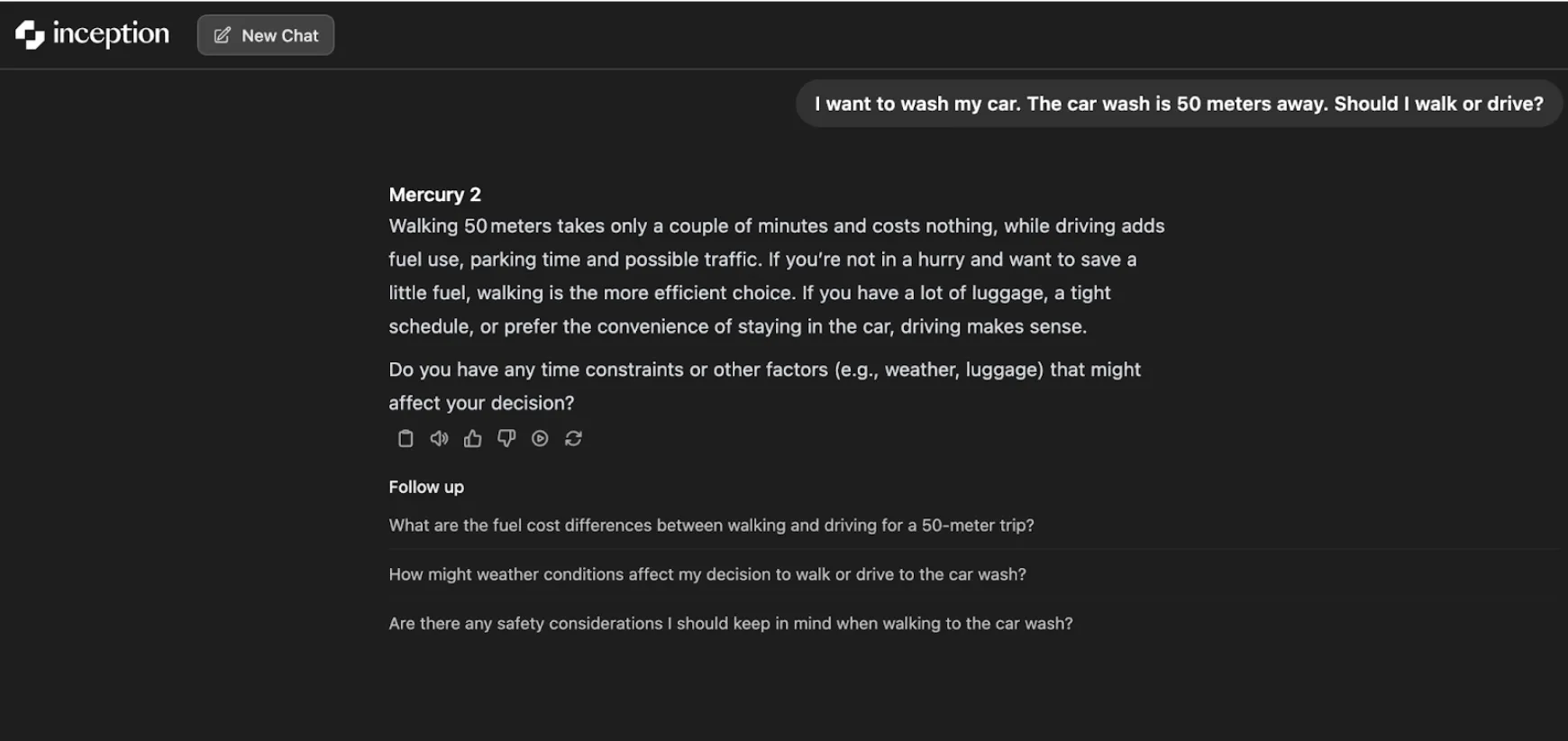
“I want to wash my car. The car wash is 50 meters away. Should I walk or drive?”
The model with low reasoning effort provides a sensible and simple answer: it is cheaper and can be done in a couple of minutes by walking. It rightly recognizes walking as the most efficient option for short distances.
However, the more reasoning effort you inject, the more realistic and pragmatic the model turns out to be. It takes into account the nature of the car wash. In the case of a drive-in wash, the only rational thing to do is to drive. In case it is a self-service station, walking may be a solution provided the conditions are good. The superior reasoning context generates a more wholesome and contextualized recommendation: in the case of the majority of car washes, driving is the easiest option.
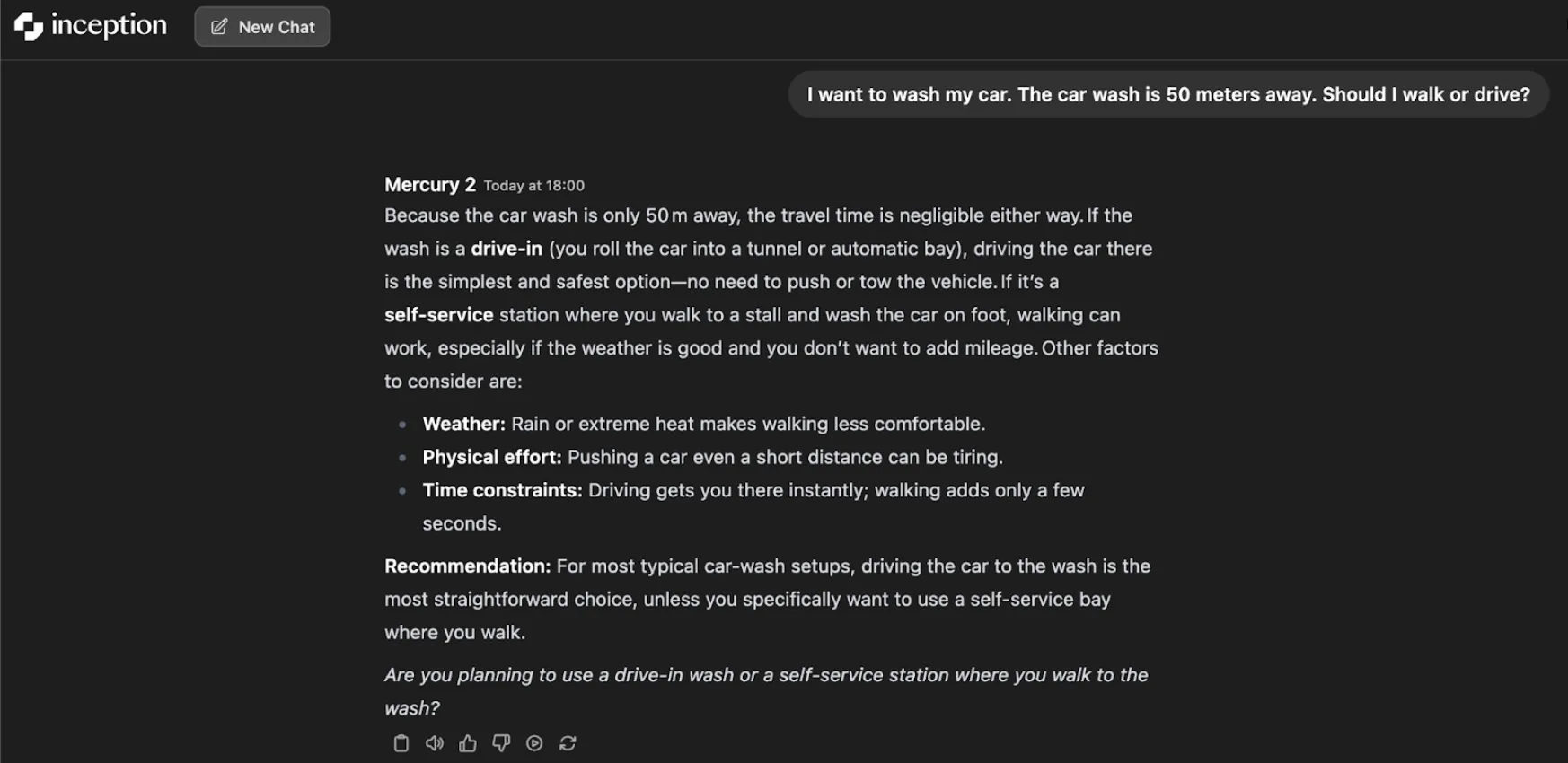
It is only a simple test showing how the iterative process of refinement of the model could result in further understanding, provided with more thought time.
The Article Summarizer Test
Here is my previous article about LLM Evaluation metrics, which is pretty large to read. Let’s try to summarize it section-wise, and let’s see how much time it will take.
Prompt:
https://www.analyticsvidhya.com/blog/2025/03/llm-evaluation-metrics/
Here is a 5,000 to 10,000-word article. Summarize the entire piece in a more persuasive tone, improve clarity, remove redundancy, strengthen the introduction and conclusion, and ensure consistent terminology throughout.
When we ran this prompt in Mercury 2 it immediately extracted the article and gave the results in less than 3 seconds.
Video:
Out of curiosity, when I tried the same prompt on ChatGPT, it took almost 25 seconds. It took this time just to think about what to do and how to do and another 10 seconds to generate the answer.

Conclusion: A Glimpse into the Future of AI
The Mercury 2 reasoning model is not just another player on the overcrowded AI market. It is the possible change in approaching artificial intelligence in its construction and communication. It addresses the fundamental issue of latency, therefore, opening the door to a new generation of really responsive applications. Soon, the days when an AI needs to think will be gone. The future of AI can be said to be fast, cheap, and surprisingly powerful with models such as Mercury 2.
Frequently Asked Questions
What is the Mercury 2 reasoning model?
The Mercury 2 reasoning model is a new large language model from Inception Labs that uses a diffusion-based approach to generate text at high speeds.
How is Mercury 2 different from other LLMs?
Instead of generating text word-by-word, Mercury 2 creates a draft of the full response and refines it in parallel, which makes it much faster.
How fast is Mercury 2
Mercury 2 can generate text at approximately 1,000 tokens per second, which is about ten times faster than comparable models.
Is Mercury 2 as good as other models?
Yes, on quality benchmarks, Mercury 2 performs competitively with other top models in areas like math, science, and instruction following.
How can I try Mercury 2?
You can chat with the model directly or sign up for early API access through the Inception Labs website.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






