Have you ever asked an LLM a question, changed the wording a few times, and still felt the answer wasn’t quite right? If you’ve worked with tools like ChatGPT or Gemini, you’ve probably rewritten prompts, added more context, or used phrases like “be concise” or “think step by step” to improve results. But what if improving accuracy was as simple as copying your entire prompt and pasting it again? That’s the idea behind prompt repetition. It may sound too simple to matter, but research shows that giving the model your question twice can significantly improve accuracy on many tasks, making it one of the easiest performance boosts you can try.
Table of contents
- What Is Prompt Repetition and Why Try It?
- Prompt Repetition in Action
- Result of the Prompt Repetition Experiment
- Example from the Paper: The NameIndex Task
- But What About Latency and Token Costs?
- When Does Prompt Repetition Work Best?
- How to Implement Prompt Repetition in Practice
- Prompt Repetition vs. Chain-of-Thought Prompting
- Practical Takeaways for Engineers
- Conclusion
What Is Prompt Repetition and Why Try It?
To understand why repetition helps, we need to look at how LLMs process text. Most large language models are trained in a causal way. They predict tokens one by one, and each token can only attend to the tokens that came before it. This means the order of information in your prompt can influence the model’s understanding.
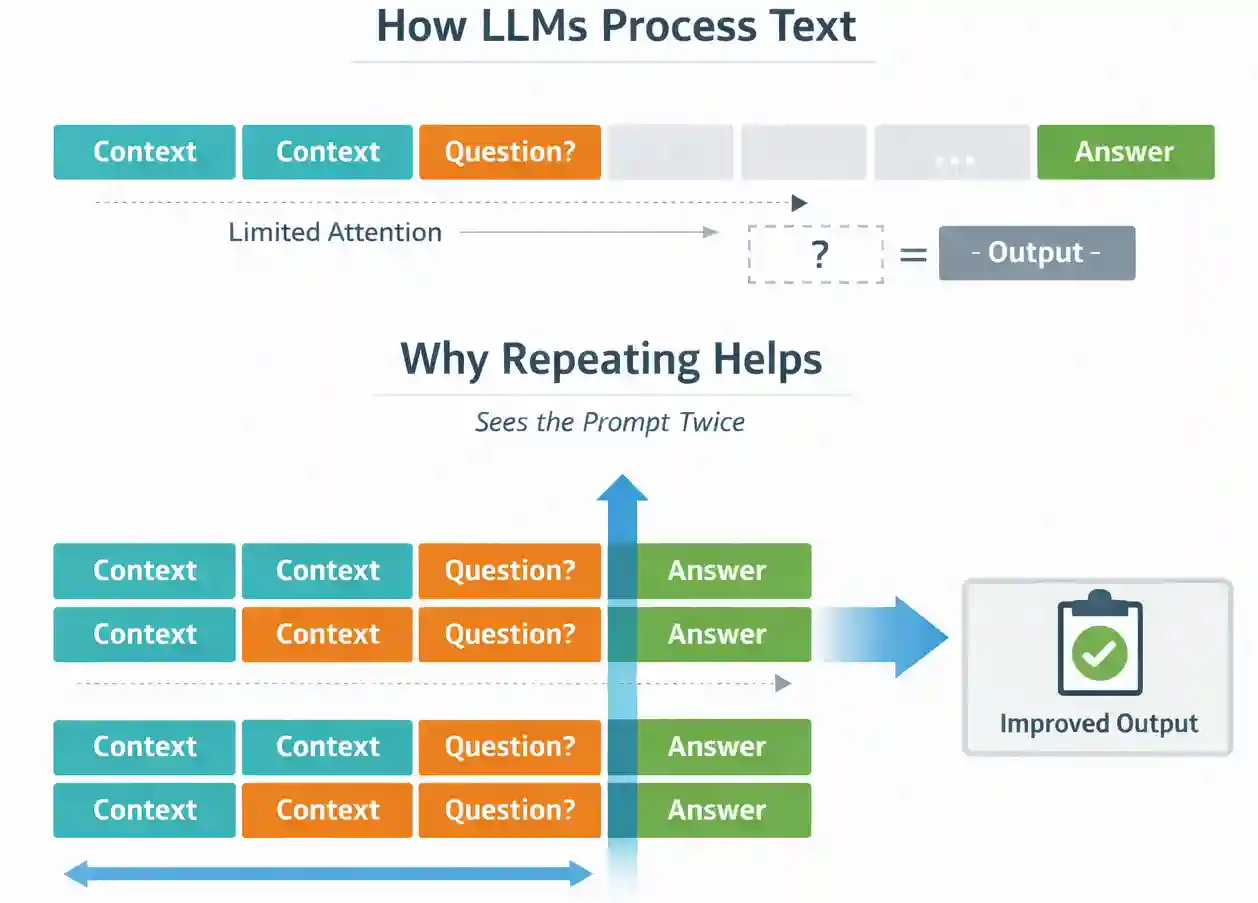
Prompt repetition helps reduce this ordering effect. When you duplicate the prompt, every token gets another opportunity to attend to all relevant information. Instead of seeing the context once, the model effectively processes it twice during the input (prefill) stage.
Importantly, this happens before the model starts generating an answer. The output format does not change, and the model does not generate extra tokens. You are simply improving how the model processes the input.
Also Read: Prompt Engineering Guide 2026
Prompt Repetition in Action
The study evaluated prompt repetition across 7 different tasks using 7 LLMs. These were not small experimental models. They included widely used models such as Gemini, GPT-4o, Claude, and DeepSeek, accessed through their official APIs. The seven tasks consisted of:
Five standard benchmarks:
- ARC (science reasoning questions)
- OpenBookQA
- GSM8K (math word problems)
- MMLU-Pro (multi-domain knowledge)
- MATH
Two custom-designed tasks:
- NameIndex
- MiddleMatch
The custom tasks were specifically designed to test how well models handle structured and positional information.
For each task, the researchers compared two setups:
- The baseline prompt
- The exact same prompt repeated twice
Nothing else was changed. The output format remained the same. The model was not fine-tuned. The only difference was that the input was duplicated.
They then measured:
- Accuracy
- Output length
- Latency
Guide to AI Benchmarks that cover everything MMLU, HumanEval, and More Explained
Result of the Prompt Repetition Experiment
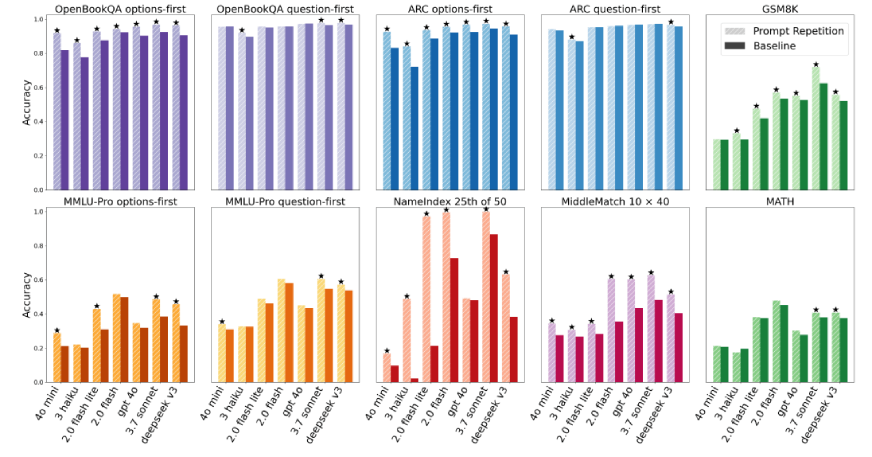
Across seventy total comparisons covering different models and benchmarks, prompt repetition improved accuracy forty-seven times. It never significantly reduced performance. The improvements were especially noticeable in multiple-choice formats and in structured tasks where the model needed to carefully track positional information.
Example from the Paper: The NameIndex Task
In the NameIndex task, the model is given a list of 50 names and asked a direct question: “What is the 25th name?” The task does not require reasoning or interpretation. It only requires accurate positional tracking within a list.

In the baseline setting, performance was low. For example, Gemini 2.0 Flash Lite achieved 21.33% accuracy. After applying prompt repetition, accuracy increased to 97.33%. This is a major improvement in reliability.
List indexing requires the model to correctly encode sequence and position. When the prompt appears once, the model processes the list and question in a single pass. Some positional relationships may not be strongly reinforced. When the full list and question are repeated, the model effectively processes the structure twice before answering. This strengthens its internal representation of ordering.
But What About Latency and Token Costs?
Whenever we improve accuracy, the next question is obvious: What does it cost? Surprisingly, almost nothing.
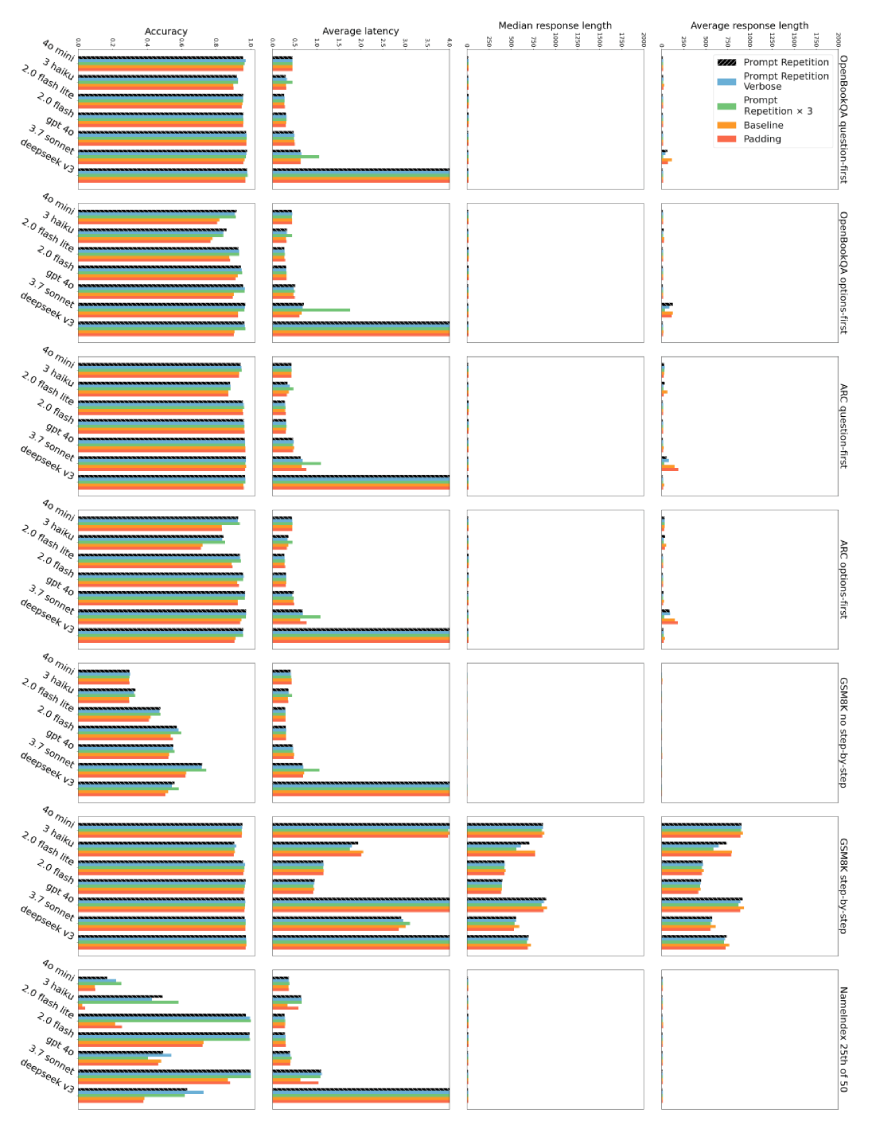
These figures compare:
- Accuracy
- Average response length
- Median response length
- Latency
The key finding:
- Prompt repetition does not increase output token length.
- The model doesn’t generate longer answers.
- Latency also remains roughly the same, except in very long prompt scenarios (particularly with Anthropic models), where the prefill stage takes slightly longer.
This matters in production systems.
Unlike chain-of-thought prompting, which increases token generation and cost, prompt repetition shifts computation to the prefill stage, which is parallelizable.
In real-world applications:
- Your cost per request doesn’t spike
- Your response format remains identical
- Your downstream parsing logic remains intact
This makes it extremely deployment-friendly.
When Does Prompt Repetition Work Best?
Prompt repetition does not magically fix every problem. The research shows that it is most effective in non-reasoning tasks, especially when the model must carefully process structured or ordered information.
It tends to work best in scenarios such as:
- Multiple-choice question answering
- Tasks involving long context followed by a short question
- List indexing or retrieval problems
- Structured data extraction
- Classification tasks with clearly defined labels
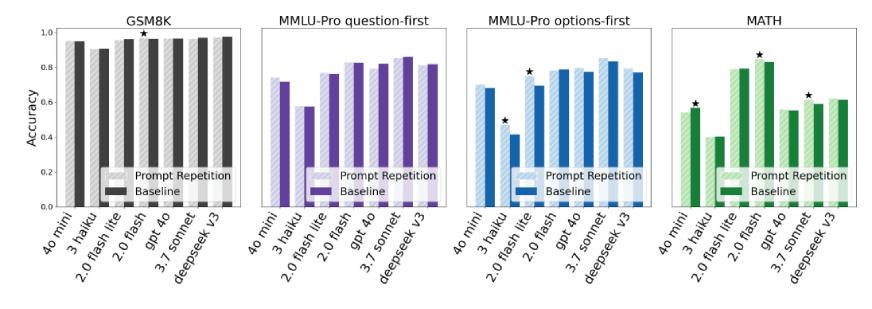
The improvements are particularly noticeable when the model must correctly track positions or relationships within structured inputs. Repeating the prompt reinforces those relationships.
However, when explicit reasoning is enabled, such as prompting the model to “think step by step,” the benefits become smaller. In those cases, the model often restates or reprocesses parts of the question during reasoning anyway. Repetition still does not hurt performance, but the improvement is usually neutral rather than dramatic.
The key takeaway is simple. If your task does not require long chain-of-thought reasoning, prompt repetition is likely worth testing.
How to Implement Prompt Repetition in Practice
The implementation is straightforward. You do not need special tooling or model changes. You simply duplicate the input string before sending it to the model.
Instead of sending:
prompt = queryYou send:
prompt = query + "\n" + queryThat is the entire change.
There are a few practical considerations. First, ensure your prompt length does not exceed the model’s context window. Doubling a very long prompt may push you close to the limit. Second, test the change on your specific task. While the research shows consistent gains, every production system has its own characteristics.
The benefit of this approach is that nothing else in your system needs to change. Your output format remains the same. Your parsing logic remains the same. Your evaluation pipeline remains the same. This makes it easy to experiment without risk.
Prompt Repetition vs. Chain-of-Thought Prompting
It is important to understand how prompt repetition differs from chain-of-thought prompting.
Chain-of-thought prompting encourages the model to explain its reasoning step by step. This often improves performance on math and logic-heavy tasks, but it increases output length and token usage. It also changes the structure of the response.
Prompt repetition does something different. It does not change the output style. It does not ask the model to reason aloud. Instead, it strengthens how the input is encoded before generation begins.
In the experiments, when reasoning prompts were used, repetition produced mostly neutral results. That makes sense. If the model is already revisiting the question during its reasoning process, duplicating the prompt adds little new information.
For tasks that require detailed reasoning, chain-of-thought may still be useful. For structured or classification-style tasks where you need concise answers, prompt repetition offers a simpler and cheaper improvement.
Practical Takeaways for Engineers
If you are building LLM-powered systems, here is what this research suggests:
- Test prompt repetition on non-reasoning tasks.
- Prioritize structured or position-sensitive workflows.
- Measure accuracy before and after the change.
- Monitor context length to avoid hitting token limits.
Because this method does not change output formatting or significantly increase latency, it is safe to test in staging environments. In many cases, it can improve robustness without architectural changes or fine-tuning.
In production systems where small improvements in accuracy translate into measurable business impact, even a few percentage points can matter. In some structured tasks, the gains are much larger.
Also Read:
Conclusion
Prompt engineering often feels like trial and error. We adjust phrasing, add constraints, and experiment with different instructions. The idea that simply repeating the entire prompt can improve accuracy may sound trivial, but the experimental evidence suggests otherwise.
Across multiple models and seven different tasks, prompt repetition consistently improved performance without increasing output length or significantly affecting latency. The approach is easy to implement, does not require retraining, and does not alter response formatting.
Try it out yourself and let me know your take in the comment section.
Find all details here: Prompt Repetition Improves Non-Reasoning LLMs Research Paper
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.






