A few years ago, generating an image from text felt magical. Then text-to-video turned prompts into moving scenes. Now models generate complete video sequences without cameras, actors, or editing timelines. ByteDance’s Seedance 2.0 pushes this further. Instead of short silent clips, it delivers a multimodal system that plans scenes in shots, synchronizes audio natively, and supports reference-driven control across text, image, video, and sound. This article breaks down its architecture, key features, and how it compares to Sora 2, Veo 3.1, and Kling 3.0.
Table of contents
What is Seedance 2.0?
Seedance 2.0 is ByteDance’s advanced multimodal video generation model that creates cinematic, multi-shot videos with synchronized audio. It accepts text, image, video, and audio inputs, enabling reference-driven control and structured scene planning within a unified diffusion-based architecture.
Source: Ivanna | AI Art & Prompts
How to Access Seedance 2.0?
Right now, Seedance 2.0 does not have a fully open global API, but some third-party apps and model hosting platforms provide limited access. Most of these are UI-based creative tools where you can generate videos with usage caps, region restrictions, or invite-only access.
You can check out this page for reference.
Key Features
Immersive Audio-Visual Experience
An immersive audio-visual experience is delivered through exceptional motion stability and native audio-video joint generation. By producing synchronized visuals and sound within the same generation process, the model achieves ultra-realistic output that feels cohesive and cinematic rather than artificially assembled.
Create with Director-level Control
Support for images, audio, and video as reference inputs enables creators to transform ideas into visuals with a high degree of control. Performance, lighting, shadow, and camera movement can all be guided, allowing for structured scene creation that resembles intentional direction rather than prompt-only generation.
Cinematic, Industry-Aligned Output
Note: All the above videos are taken from ByteDance’s website.
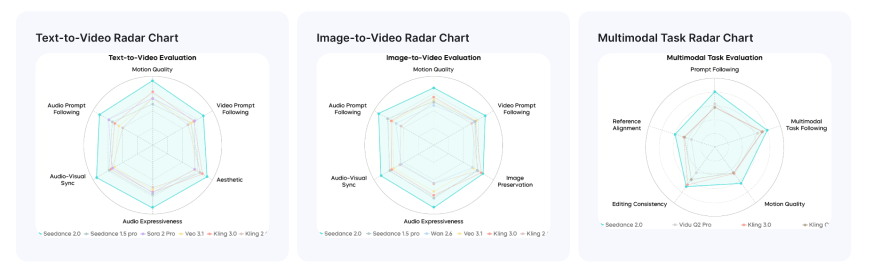
Performance of Seedance 2.0
Benchmark results from SeedVideoBench-2.0 indicate leading performance across multiple task categories. The model performs strongly in text-to-video, image-to-video, and multimodal tasks, demonstrating consistent capability across different generation scenarios.
How Does Seedance 2.0 Work?
Seedance 2.0 operates as a unified multimodal diffusion system that jointly generates video and audio from structured conditioning inputs. Instead of treating text, images, video references, and sound as separate signals, it encodes them into a shared latent space and performs coordinated denoising across time. The result is a multi-shot, synchronized audio-video sequence generated within a single pipeline.
Here is how the system is structured.
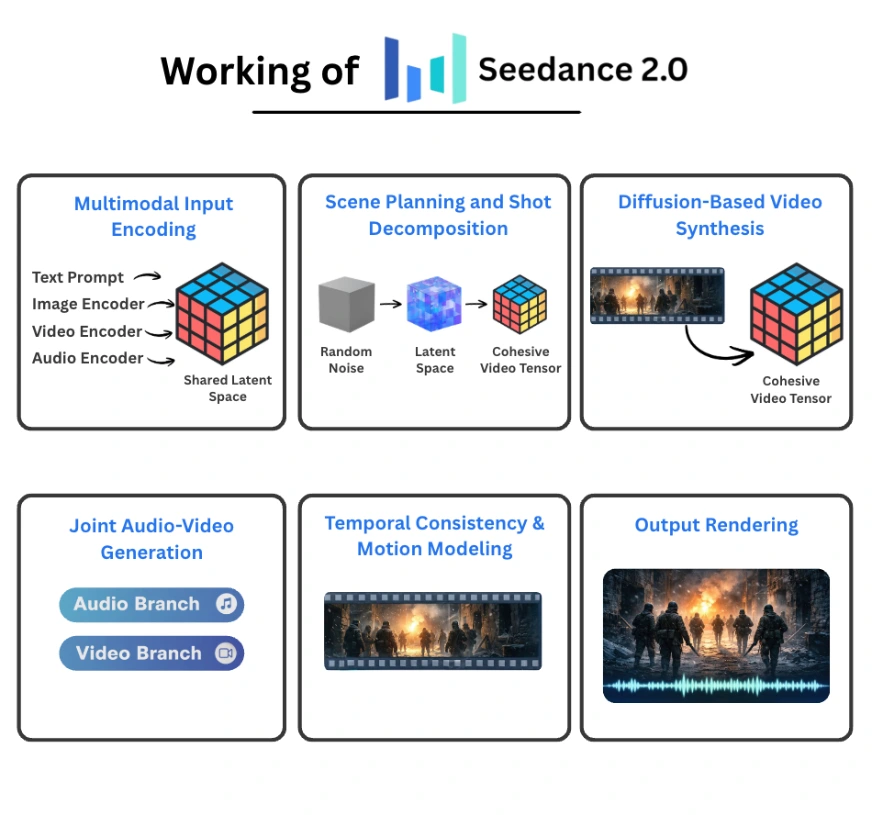
Multimodal Input Encoding
Each modality is processed by a dedicated encoder:
- A text encoder converts prompts into semantic embeddings.
- An image encoder transforms images into patch-level visual tokens.
- A video encoder produces spatiotemporal tokens that capture motion and scene structure.
- An audio encoder extracts waveform or spectrogram representations.
All embeddings are projected into a shared latent representation. This unified space allows cross-modal interaction. A textual instruction about lighting can influence visual tone, while a music reference can shape pacing and movement. Because everything lives in the same representational space, conditioning is coherent rather than loosely stitched together.
Scene Planning and Shot Decomposition
Before frame synthesis begins, Seedance interprets the prompt and constructs a structured internal plan.
Instead of generating a single uninterrupted clip, the system:
- Parses narrative intent.
- Breaks the scene into multiple shots.
- Plans transitions and continuity across them.
This planning layer functions like an automated storyboard generator. Character identity, lighting conditions, and spatial layout are preserved across cuts. That prevents identity drift and abrupt visual inconsistencies that often occur in naive video diffusion systems.
The result is not just motion over time, but a sequence that resembles intentional cinematography.
Diffusion-Based Video Synthesis
Video generation is handled through a spatiotemporal diffusion process.
The pipeline works as follows:
- Initialize random noise in latent space.
- Condition the denoising steps on multimodal embeddings.
- Iteratively refine spatial and temporal representations.
- Produce a coherent video tensor.
Unlike image diffusion, video diffusion must maintain consistency across time. The transformer backbone attends across frames to preserve object structure and motion continuity. This reduces flicker, prevents object morphing, and stabilizes camera movement.
Joint Audio-Video Generation
One of the most distinctive elements of Seedance 2.0 is simultaneous audio and video generation.
The architecture includes:
- A video branch responsible for visual denoising.
- An audio branch responsible for waveform generation.
These branches exchange temporal signals during inference. When a visible event occurs in the video stream, the audio branch generates corresponding sound aligned to that exact moment. Lip movement can synchronize with speech. Environmental effects match physical interactions.
Generating both modalities together improves alignment compared to systems that attach audio after video synthesis is complete.
Temporal Stability and Motion Modeling
Video synthesis introduces challenges that static image models do not face:
- Long-range temporal coherence
- Consistent character identity
- Physically plausible motion
Seedance addresses these through:
- Spatiotemporal attention mechanisms
- Motion-aware latent conditioning
- Large-scale video-audio training data
By modeling motion trajectories instead of independent frames, the system maintains smoother transitions and more stable object behavior across time.
Output Rendering
After all planned shots are generated:
- Shot segments are combined internally.
- Audio streams are aligned with the visual timeline.
- The final video file is rendered.
The output can span up to approximately 15 seconds and may include multiple camera angles within a single generation request.
Seedance 2.0 vs Sora 2
Sora 2 is often described as a reality simulator. It excels in modeling physics, including gravity, fluid motion, and object permanence even when objects move off-screen. For long-duration realism and physically coherent environments, Sora remains extremely strong.
Seedance competes closely on realism but differentiates itself through its quad-modal reference system. Unlike Sora, which primarily relies on text and limited image input, Seedance allows direct assignment of text, photo, video, and audio references. This enables style transfer, motion cloning, and voice-guided generation in ways that are more dynamic than Sora’s prompt-based approach.
Another important difference lies in audio generation. Seedance uses a dual-branch transformer to generate video and audio simultaneously. This leads to tighter synchronization between visible events and sound. Sora treats audio more as a secondary process rather than a tightly coupled generation stream.
Seedance 2.0 vs Google Veo 3.1
Veo 3.1 provides precise control through masked editing and camera-specific commands such as pan, tilt, and zoom. This makes it feel like a digital editing suite where creators can refine specific areas of a frame without regenerating the entire scene.
Seedance takes a reference-driven approach instead of mask-driven editing. Instead of manually modifying parts of a video, users can upload reference clips to transfer motion style, lighting, or vibe into a new generation. If Veo emphasizes surgical editing, Seedance emphasizes controlled style replication.
In terms of audio-video alignment, Seedance maintains an advantage due to its joint generation architecture. Veo’s synchronization is strong, but not as tightly integrated as Seedance’s simultaneous audio-video diffusion.
Seedance 2.0 vs Kling 3.0
Both Seedance and Kling perform well in maintaining character consistency, but their methods differ.
Kling’s Omni Mode allows users to bind specific faces, outfits, and elements into reusable assets. This is useful when building recurring characters for episodic content. It creates a controlled asset library that can be reused across scenes.
Seedance focuses more on reference cloning and style transfer. Instead of binding internal assets, it enables users to transfer motion, lighting, and performance style from external media. Kling is stronger for building a reusable cast, while Seedance is stronger for replicating a specific cinematic feel from an existing reference.
Kling also offers strong control over dialogue tone and multilingual speech generation. Its synchronization outperforms several competitors. However, Seedance still holds a slight edge in frame-accurate audio-video alignment.
Also Read: Top 10 AI Video Generators
Conclusion
Seedance 2.0 feels like a genuine step forward in AI video generation. The quad-modal inputs, tight audio-video sync, and built-in shot planning make it more than just another prompt-to-video tool. It starts to look like a lightweight virtual production system. Sora 2, Veo 3.1, and Kling 3 each have clear strengths, but Seedance 2.0 stands out for how much control it gives creators. If global access opens up and API support expands, this could become a powerful tool for real-world creative workflows.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.






