You walk into the interview room. The whiteboard displays the following prompt: “A major retailer wants to deploy a GenAI chatbot for customer support. How would you approach this?” You have 35 minutes. Your palms are sweating.
Sound familiar? GenAI case studies currently serve as the primary challenge which interviewers use to test candidates in product management, consulting and AI engineering positions. Most candidates fail this challenge because they lack the ability to establish a standard process for solving these problems.
This guide gives you that framework. We’ll break it apart, then pressure-test it across 2 real-world scenarios you’re likely to see in 2026 interviews.
Table of contents
Why GenAI Case Studies Are Different from Traditional Ones?
Case studies for traditional products follow an expected pattern. Find the user, identify their issue, create the feature, and measure how successful that was are all in a tidy, sequential order. But when it comes to GenAI, the case studies do not adhere to that same structure in three specific ways:
- Systems are probabilistic: You’re not designing a button that always does the same thing. You’re managing a model that might hallucinate, drift, or produce wildly different outputs on Tuesday than it did on Monday. Interviewers want to see that you understand this.
- Evaluation is nebulous: Asking “Did the chatbot interact with me correctly?” seems like a simple query. Unfortunate (or fortunate), it is not. The question will depend on four major characteristics: context, tone, completeness of response and whether the user trusted the GenAI to proceed with their plans or actions. Candidates should have a well-defined method of determining success metrics for a system that is subjectively successful.
- Risk factors are enormous: The user gets annoyed by a button that doesn’t seem to do what it is supposed to do; the user receives medical advice from an AI assistant and that advice is based on hallucinations of the AI, resulting in unacceptable results. Interviewers are specifically looking to see if you think about safety and reliability when designing something and consider contingencies and other outcomes.
If a candidate treats a GenAI case study as a traditional case study, the interviewer will likely have an average or worse response because they failed to highlight all the differences explained above.
The GATHER Framework: Your 6-Step Playbook

I have amassed the greatest GenAI case study response templates into a 6-step process: GATHER. It can be applied to several job titles product manager, consultant, ML engineer, solutions architect. You can customize your degree of depth per role while maintaining the same framework.
G: Ground the Problem
Before getting into anything relating to AI find out what business context you are working in by posing the following questions (out loud to the interviewer).
- Who is the user? Is it your internal team or the end customer?
- What is the current process currently?
- What does success look like mathematically? Revenue increases, cost reductions, NPS increases, etc.?
- Are there any regulatory or compliance requirements unaided by artificial intelligence?
This step usually takes around 2-3 Minutes. This will showcase that you are mature enough to conduct this step correctly, while most candidates do not complete this step and simply type their answer “We will use RAG” and leave there will be you!

A: Assess AI Appropriateness
Not every issue requires the use of GenAI or LLMs to solve the issue at hand. One of the more effective signals you could thus give is by stating that “This may not be an ideal task for a LLM or could be accomplished in a different way with LLMs”.
A good test for which technologies are appropriate for the proposed solution is to ask if this problem requires “generation,” “retrieval,” “classification” or “reasoning.” GenAI tends to have significant advantages in generation and unstructured multi-step reasoning. If you can classify or extract structured data, there are likely to be more affordable and dependable alternatives such as standard ML approaches.
If you believe that GenAI is the appropriate technology to be applied, be specific about why you think so; for example, “We are using GenAI as our source of input is unstructured natural language and our request for output is based on multi-level contextual based reasoning.”

T: Technical Architecture (High Level)
You do not need to build out an entire system for the project or show a complete schematic of how all the system’s pieces will fit together. However, you do need to demonstrate your understanding of how the system’s pieces are related. The following list represents what a majority of interviewers would expect to see as a base level of architecture:

Identify your decisions. Are you using RAG or fine-tuning to retrieve documents? What retrieval method have you chosen (e.g. vector search, keyword hybrid, or knowledge graph)? How have you applied your safety filters (e.g. pre-inference, post-inference, both)?
Each decision will create a tradeoff that you should state explicitly. An example would be, “I would choose RAG because the products being offered will change weekly at a retailer and, because of the rate of change in the retailer’s product listings, fine-tuning will not be able to keep pace.”
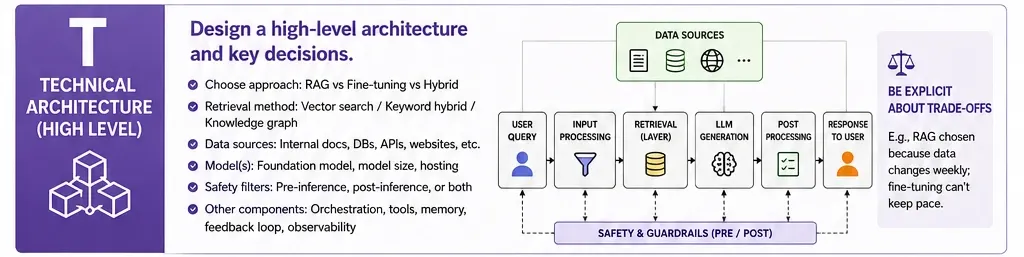
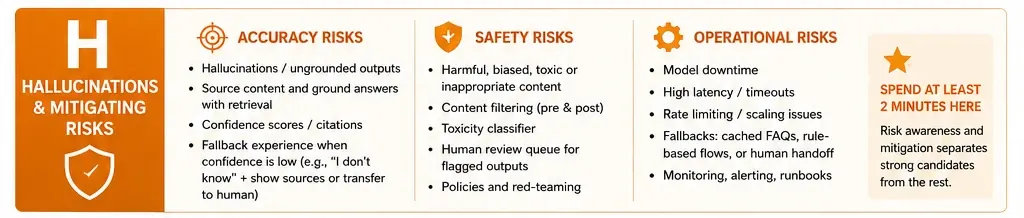
H: Hallucinations & Mitigating Risks
This is where you’re going to see the greatest differentiation from one person to the other. Here spend at least two solid minutes talking about the risks. You want to group these risks into three buckets:
- Accuracy Risks: How do you deal with hallucinations? How do you source your content and generate it backed by retrieval? How do you provide confidence scores? How do you provide a fallback experience when the model is not confident?
- Safety Risks: What happens when the model generates content that is harmful, biased, or otherwise inappropriate? You will want to have content filtering mechanisms in place, such as a toxicity classifier, human review queue for flagged outputs, etc.
- Operational Risks: What happens if the model goes down? What happens if the latency is too long? What will your fallback experience be? For example, “If the model does not respond to a user query request within three seconds, we will return an FAQ response that is cached and then route the user to a human agent.”

E: Evaluation Metrics
This is the “WHAT of your results!” Define your interpretation of success. There are 3 categories of metrics:
- Model metrics: Examples of model metrics are relevance to the question, groundedness (did it reference a legitimate source) and toxicity rating (did you discern if the answer was obscene or derogatory). Model metrics are defined using eval datasets during offline evaluations.
- Product metrics: Examples of product metrics include customer completion rates (did you complete what was needed), user satisfaction scores (i.e. thumbs up / thumbs down), human escalation rates (how often humans had to be involved in solving the customer’s issue) and length of time to resolution.
- Business metrics: Examples of business metrics include cost of per ticket, customer retention, Net Promoter Score (NPS) change, and amount of time freed by a support team.
Most prior candidates have only mentioned one of the three categories. By addressing all three you demonstrate to the interviewer that you are looking at this problem as a system rather than as separate parts.
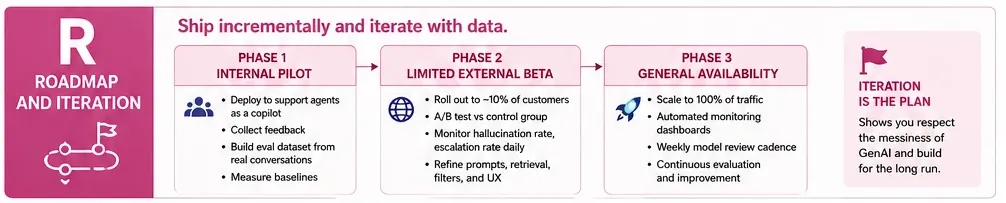
R: Roadmap and Iteration
You should always end with a rollout plan of your project in different phases. This displays that you’ve shipped things in production before (or at least think like someone who has).
Phase 1: Internal pilot where you can deploy to support agents as a copilot, not customer-facing. Collect feedback and then build your eval dataset from real conversations.
Phase 2: Limited external beta while rolling out to 10% of customers. A/B test against the control group. It helps in monitoring hallucination rate and escalation rate daily.
Phase 3: General availability and scaling to full traffic. Set up automated monitoring dashboards and establish a weekly model review cadence.
This phased approach is important for interviewers. It shows you respect the messiness of GenAI systems and wouldn’t just push a model straight to production.
Worked Examples Using the GATHER Framework
Let’s look at how to put the framework into practice using two example scenarios you’ll encounter on a regular basis.
Scenario 1: E-commerce support Agent
The Interviewer: “Create an e-commerce company Chatbot to support its customers using GenAI.”
- Ground: Online shoppers who have order-related issues, such as tracking, returns, refunds. The ‘static’ FAQs are currently the only source of information and customers wait an average of 15 minutes before speaking with a representative to resolve their issue. Our objective is 40% Reduction in cost-per-ticket.
- Assess: Strong GenAI fit, types of questions in natural language, varied in nature and requiring a context-based response (based upon information about the order). A rule-based chatbot would not be able to effectively resolve many of the types of questions that are asked.

- Technology: RAG architecture that collects data from order databases, product catalogues, return policy documents, etc. Pre-built retrieval index which is updated nightly. The LLM utilises this retrieved context as input for generating a response. The output from the model needs to have all PII stripped prior to being returned to the requester.
- Hallucination/Risk: Every response returned should be supported by a retrieval policy document. If there is any doubt about the confidence level of the retrieved response (e.g., < 0.7 confidence) automatically escalate the request to a human. The model should never generate a return policy based upon hypothetical data.
- Evaluation Metrics: Measure the rate that requests have been resolved (Target = 65% without Human Handoff), the CSAT for each interaction, and the Hallucination Rate (Target = < 2%).
- Roadmap: Initially, the chatbot functions as an agent copilot providing draft responses for agents to improve upon prior to being placed into a customer-facing role 4 weeks after the agent validates the application.
Here’s how you can answer in detail:
Now let’s take a look at using GATHER framework in much more detail:
Scenario 2: Hospital Patient Record Summarizer
The Interviewer: “There are over 10,000 doctors working at Apollo Hospitals and these doctors are in 73 different hospitals. Each day, doctors spend about 2.5 hours reading through patient charts before a consultation. The Chief Medical Information Officer of Apollo wants to create a GenAI tool that will automatically generate patient summary documents. How would you go about building such a tool?”
G – Ground the Problem
A cardiologist reviewing a follow-up patient needs a very different summary from an ER doctor assessing a first-time patient. The summary format must therefore reflect both the provider’s role and the clinical context.
The first step is to understand Apollo Hospital’s current EHR system, likely custom-built or HIS-based. Next, assess how clinical notes are stored, since Indian hospital records often combine typed text, scanned handwritten notes, and dictated audio. The level of structure will directly shape the technical approach for generating patient summaries.
Finally, compliance is critical. DISHA and NABH-related requirements may restrict patient data from leaving Apollo’s infrastructure, especially if summary generation depends on information outside Apollo’s systems.
A – Assess the AI Sufficiency
This use case involves summarizing and combining large amounts of unstructured information. Doctor notes are often inconsistent, filled with slang, jargon, and varying sentence structures, making rule-based systems ineffective. GenAI is better suited for this task.
However, the risk is significant because an incorrect summary could lead to patient harm or death. To reduce this risk, the solution should prioritize extractive approaches over abstractive ones, using generated summaries only when combining multiple validated pieces of information into a higher-level summary.
T – Technical Architecture
On-premises application. No connectivity to any cloud APIs. The model operates via Apollo Data Centre.
The pipeline works in a way when a patient’s ID is queried, a request is made to the EHR to extract patient’s clinical notes, lab results, medication history, allergies and imaging reports. Each type of data is processed in a different extraction module. Data is structured (labs, vitals) when formatted; unstructured (clinical notes) is processed via large language models before it is formatted. The output is in the form of a structured template (not free text).
H – Hallucinations/Risks
The worst-case scenario is a severe hallucination where the system shows the patient is taking Warfarin instead of Aspirin. If the physician misses this, they may prescribe a drug that interacts with Warfarin, leading to a bleeding event.
To prevent this, medication, allergy, and condition summaries must be traceable to source records through entity extraction rather than entity generation. If the model produces a medication not found in the patient’s medical record, the system should flag it, remove it from the output, and avoid showing it to the physician.
For clinical note summarization, I would use a “quote and cite” approach. Example: “Patient presents with consistent chest tightness (Dr. Sharma, 03/14/2026).” This gives providers both the statement and its source.
E – Evaluation
It will be evaluated based on three tiers:
- The model tier conducts a factual accuracy audit which requires a monthly review of 500 summaries that are checked against their source records. The system evaluates entity-level precision and recall for three medical categories which include medications and allergies and conditions.
- The product tier measures clinician adoption through the question of whether doctors read the summary. The system achieves faster document review processes. The “Trust score” measures confidence through a monthly survey which asks respondents whether they felt assured in using the summary without verifying details from the complete medical record.
- The business tier measures the average time required to start consultations while evaluating whether the time has increased or decreased. The system tracks the daily patient throughput of doctors who work a standard day. The system measures doctor satisfaction levels together with their burnout assessment metrics.
R – Roadmap
Phase 1: In the first two months, medical staff will create read-only summaries for follow-up visits in one department. These will appear beside the full chart, which remains accessible. Doctors will rate each summary with thumbs up/down.
Phase 2: From months three to four, the system will include issues such as drug interactions and canceled screenings, and expand to three more departments. The clinical team will audit 200 summaries weekly.
Phase 3: From month six, the system will support emergency department workflows with high-stakes summary formats. It will also connect with clinical decision support systems to flag alerts and add relevant text.
Five Mistakes That Tank GenAI Case Study Answers
Here are 5 of the most common mistakes in GenAI case study answers:
- You are moving to “RAG” in 30 seconds. So far you have not asked any clarifying questions. Ground the problem first.
- Ignoring risk. No discussion of hallucinations or bias or safety? In GenAI interviews, this is a disqualifier.
- Talking about the LLM like it’s a black box. Saying “we will pass it to GPT” to the interviewer indicates you have never shipped an AI product.
- There is no human in the loop. Anytime you have a strong answer, there should be someone else to fall back on whether they’re agents, editor, Physician, or an Attorney. Show where a human is going to be.
- There is no phased rollout. A red flag is you are launching to 100% of your users from day one. Start with a pilot.
Night-Before Checklist
Even after all the preparation, you might feel nervous for what’s coming but here’s a list to check or basically sleep on for the next day:
- The first thing you will want to do is run through GATHER once from memory on a random prompt. For example, the case ‘create a GenAI travel planner’ seems to work perfectly.
- Next, refresh your memory of the tradeoffs between RAG and fine-tuning, as this has been the most frequently asked technical topic in GenAI interviews these days.
- Thirdly, you need to have two ‘war stories’ (i.e., things that have gone wrong) related to some type of AI. A perfect example is the Air Canada chatbot lawsuit since it clearly demonstrates that you are familiar with this area.
- Fourthly, you need to understand what BLEU, ROUGE, and BERTScore evaluate; however, human evaluation will always be more valuable than any automated measure.
- Finally, practice saying it out loud. It is one thing to read a framework; it is another to explain it while under pressure.
Conclusion
Interviews for GenAI case studies are not designed to “test” your knowledge of transformer architectures but rather to assess whether you can reason through complex, probabilistic systems and deliver them from a risk perspective. GATHER provides a structure, and the six examples provide the muscle memory, but the single thing that will get you the job offer is practice until it is second nature to you, and all that you are doing is demonstrating sound reasoning.
Grab a friend, randomly select a scenario, and begin discussion around that scenario. Your future interviewer will appreciate you for it.
Frequently Asked Questions
Q1. What is the GATHER framework?
A. A 6-step playbook for solving GenAI case study interviews with structure, risk awareness, evaluation, and rollout planning.
Q2. Why are GenAI case studies different?
A. GenAI systems are probabilistic, harder to evaluate, and carry bigger safety risks than traditional product case studies.
Q3. What mistake should candidates avoid?
A. Do not jump straight to RAG. First, clarify the problem, user, success metrics, risks, and rollout plan.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]






