On June 3, 2026, Google introduced Gemma 4 12B Unified, an open-source multimodal model designed to understand text, images, audio, and video within a single architecture. It combines a 256K context window with an efficient, laptop-friendly design aimed at agentic workflows and local deployment.
The release also raises interesting questions about Google’s broader AI strategy, particularly the gap between the models emphasized in public APIs and those made widely available through open-source tooling. In this article, we’ll examine Gemma 4 12B Unified’s architecture, capabilities, and what its release means for developers.
Table of contents
What is Gemma 4 12B?
Gemma 4 12B Unified is Google DeepMind’s mid-sized open source model in the Gemma 4 family. Google describes it as a dense multimodal model built to bring agentic multimodal intelligence directly to laptops. It bridges the gap between the smaller Gemma 4 E4B edge model and the larger Gemma 4 26B A4B Mixture-of-Experts model.
The public model card lists Gemma 4 models in five sizes: E2B, E4B, 12B Unified, 26B A4B, and 31B. Gemma 4 12B Unified has 11.95B parameters, 48 layers, 1024-token sliding window attention, a 256K context window, a 262K vocabulary, and support for text, image, and audio inputs.
Key Features
Gemma 4 12B supports:
- Text generation and chat
- Long-context reasoning up to 256K tokens
- Coding, code completion, and code correction
- Function calling for agentic workflows
- Video understanding by processing video as frames
- Audio speech recognition and speech-to-translated-text translation
- Multilingual use, with out-of-the-box support for 35+ languages and pre-training over 140+ languages
Google also highlights automatic speech recognition, diarization, video understanding, coding, and agentic reasoning in the Gemma 4 12B developer guide.
Why Google Needed a Mid-sized Unified Model?
The original Gemma 4 family released on March 31, 2026 with E2B, E4B, 31B, and 26B A4B variants. Google then released Gemma 4 MTP drafters on April 16, 2026, followed by Gemma 4 12B Unified on June 3, 2026. This makes the 12B release a follow-up expansion of the family rather than the original Gemma 4 launch.
The release fills a practical deployment gap. E2B and E4B are designed for edge and mobile-class use cases, while 26B A4B and 31B target higher-end workstations and servers. Gemma 4 12B is positioned as a laptop-ready model that provides stronger reasoning and multimodal capability than the edge models while using less memory than the larger 26B MoE model.
Main Changes from Earlier Gemma 4 Models
| Area | Earlier Gemma 4 models | Gemma 4 12B Unified |
| Model size | E2B, E4B, 26B A4B, 31B initially | Adds a mid-sized 12B dense option |
| Multimodal design | Other models use dedicated vision and audio encoders depending on size | Encoder-free projection of image and audio into the LLM |
| Audio | E2B and E4B had native audio; 31B and 26B A4B do not list audio support | First mid-sized Gemma 4 model with native audio |
| Context | 128K for E2B/E4B, 256K for larger models | 256K |
| Deployment target | Edge models for mobile, larger models for workstations and servers | Laptop-first local multimodal agents |
| Fine-tuning | Separate encoders can add complexity | Unified token loop can be tuned in one pass |
| Benchmarks | E4B is lighter, 26B A4B is stronger | 12B sits between them in most official scores |
Architecture Overview
1. Unified encoder-free design
The most important technical change in Gemma 4 12B is its encoder-free multimodal architecture. Traditional multimodal models often use separate encoders for image and audio inputs before passing representations into the language model. Google says Gemma 4 12B removes those separate multimodal encoders and projects raw image patches and audio waveforms directly into the LLM embedding space. (blog.google)
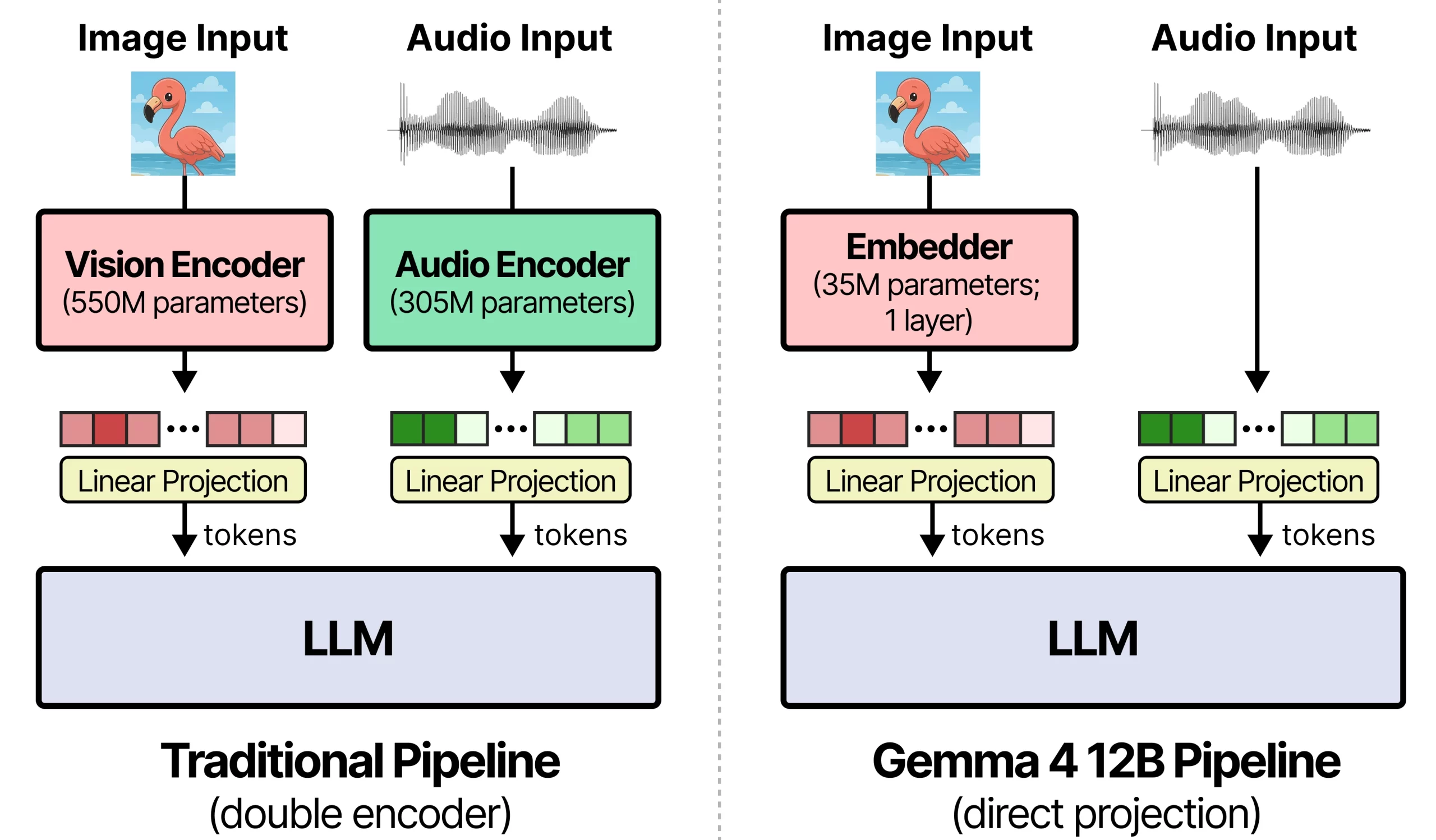
2. Vision processing
For vision, the developer guide says Gemma 4 12B replaces the multi-layer vision encoder used in other medium-sized Gemma 4 models with a 35M parameter vision embedder. Raw 48×48 pixel patches are projected into the LLM hidden dimension with a single matrix multiplication, and spatial information is attached through factorized coordinate lookup matrices.
3. Audio processing
For audio, Gemma 4 12B removes the separate conformer-based audio encoder used in smaller Gemma 4 variants. It slices raw 16 kHz audio into 40 ms frames and linearly projects those frames into the LLM input space.
4. Decoder and attention
The model card states that Gemma 4 uses a hybrid attention mechanism that interleaves local sliding window attention with full global attention, with the final layer always global. It also uses unified keys and values in global layers and Proportional RoPE for long-context efficiency.
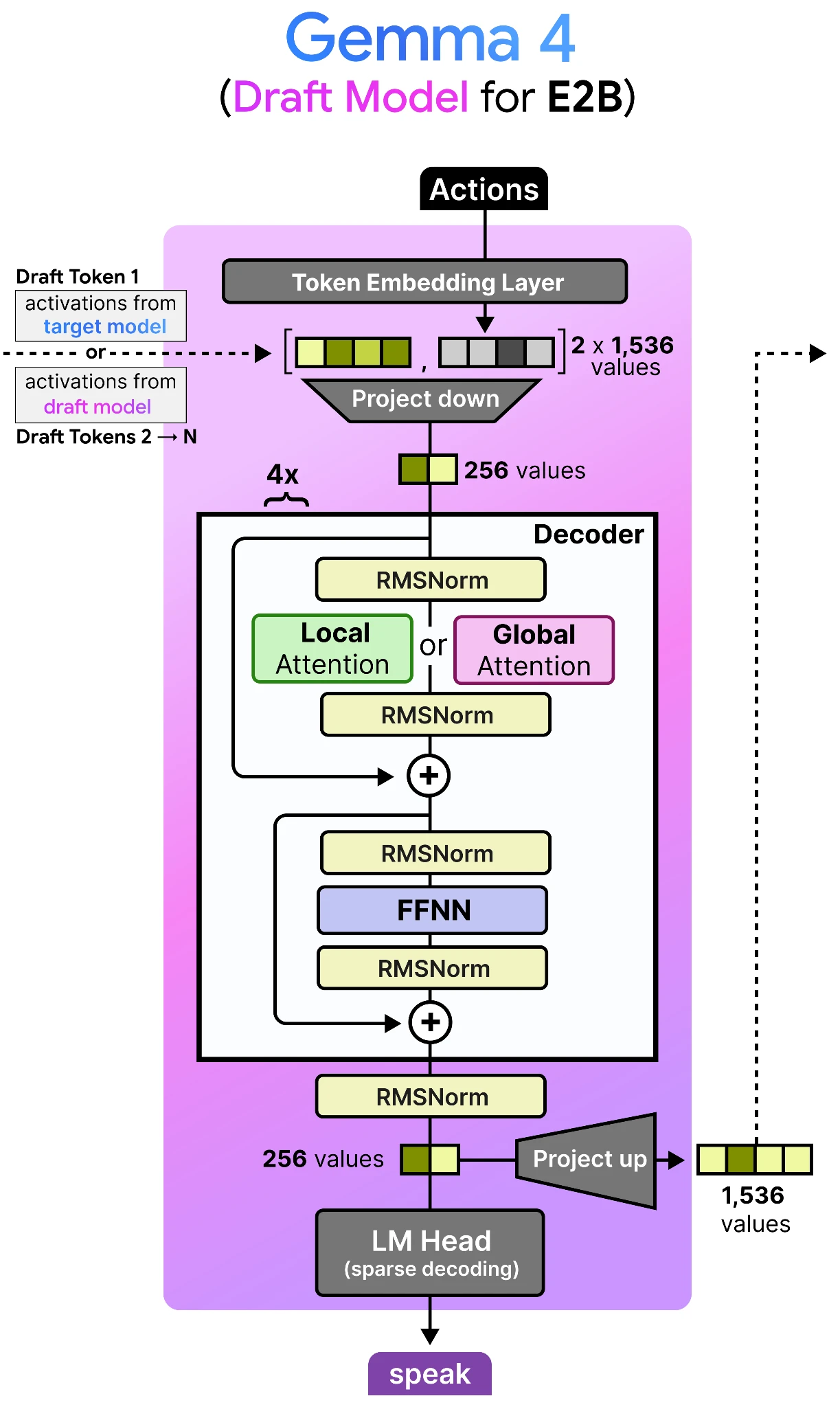
5. MTP drafters for lower latency
Gemma 4 12B is “drafter-ready,” meaning it supports Multi-Token Prediction drafters for speculative decoding. Google’s MTP documentation explains that a smaller draft model predicts several future tokens, while the target model verifies them in parallel, improving decoding speed without changing the final verified output quality.
Availability and Access
Gemma 4 12B is available as open weights in pre-trained and instruction-tuned variants through Hugging Face and Kaggle. Google’s launch post also lists LM Studio, Ollama, Google AI Edge Gallery, Google AI Edge Eloquent, LiteRT-LM, Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM, and Unsloth as supported ecosystem paths.
Hands-on: Run Gemma 4 12B with Ollama
- Download Ollama from https://ollama.com/download/
- Install it in your system and type ollama in terminal to verify the installation:
- In a fresh terminal window, paste
ollama run gemma4:12band press Enter
This will download gemma4 12b in your PC and you can interact with it directly
Hands-on: Image Understanding
Let’s test Gemma4 12B for image understanding for which this model is known for.
We’ll be using Ollama here but not in terminal but through code
For using this install the ollama python sdk:
!pip install ollama
import ollama
# Define the model ID
MODEL_ID = "gemma4:12b" # Ensure this matches your local Ollama model name
# Hands-on: Image Understanding
# Note: Google recommends placing image content before text in multimodal prompts.
# For local files, pass the path string. For URLs, download the image first.
image_messages = [
{
"role": "user",
"content": "Extract the key trends from this table.",
"images": ["financia_table.png"],
}
]
image_response = ollama.chat(model=MODEL_ID, messages=image_messages)
print(image_response["message"]["content"])Output:
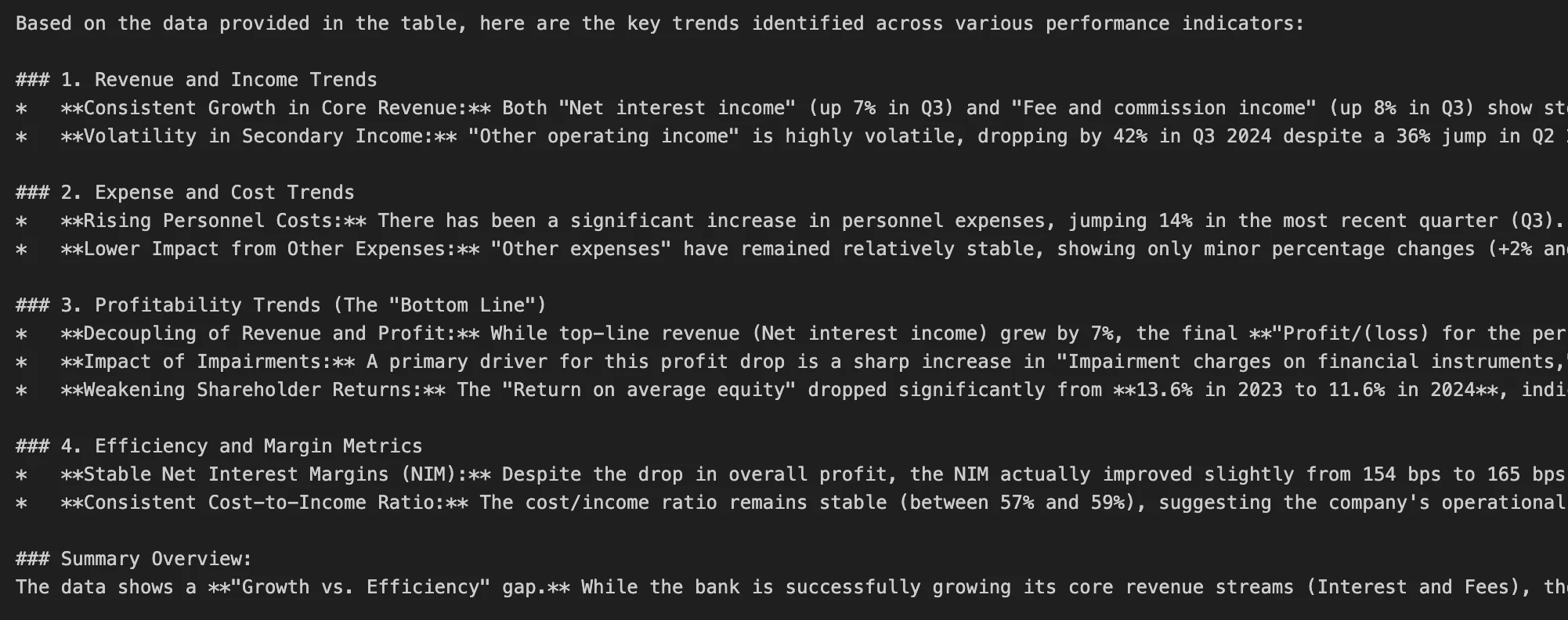
We can see Gemma4 12B is able to analyse the image successfully. Google recommends placing image content before text in multimodal prompts.
Benchmarks and Comparison
The official model card reports the following instruction-tuned benchmark results:
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 12B Unified | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B |
| MMLU Pro | 85.2% | 82.6% | 77.2% | 69.4% | 60.0% | 67.6% |
| AIME 2026, no tools | 89.2% | 88.3% | 77.5% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 72.0% | 52.0% | 44.0% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 1659 | 940 | 633 | 110 |
| GPQA Diamond | 84.3% | 82.3% | 78.8% | 58.6% | 43.4% | 42.4% |
| MMMU Pro | 76.9% | 73.8% | 69.1% | 52.6% | 44.2% | 49.7% |
| MATH-Vision | 85.6% | 82.4% | 79.7% | 59.5% | 52.4% | 46.0% |
| FLEURS, lower is better | unavailable | unavailable | 0.069 | 0.08 | 0.09 | unavailable |
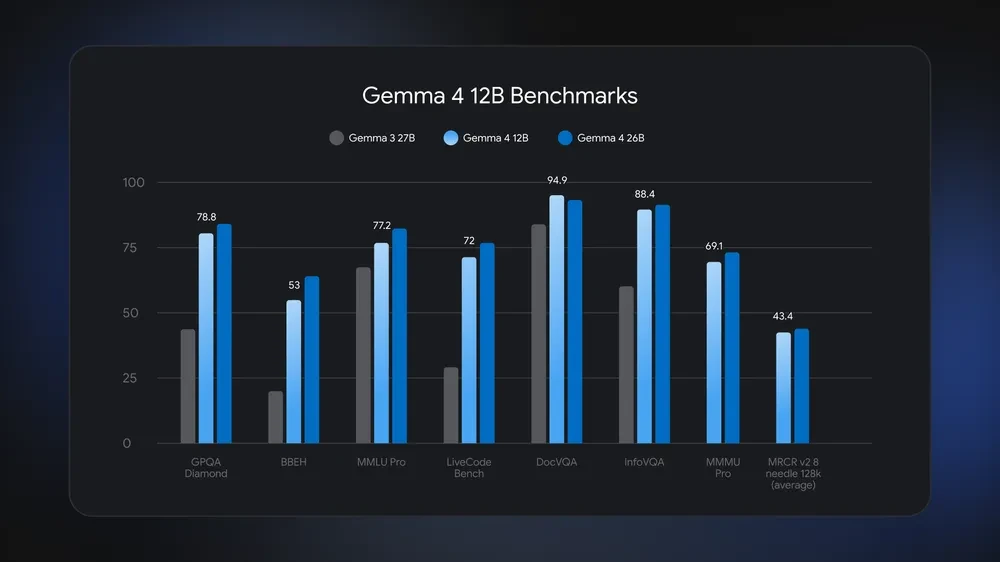
Gemma 4 12B sits between E4B and 26B A4B, offering a practical middle ground for local reasoning, coding, vision, and audio workloads.
Conclusion
Gemma 4 12B isn’t just an incremental update; it’s Google’s blueprint for bringing highly capable multimodal, agentic AI directly to everyday developer machines. By routing text, image, and audio into a single, encoder-free decoder transformer, it completely eliminates pipeline complexity for local voice, coding, and document workflows.
Ultimately, this model offers technical leaders the perfect middle ground between tiny edge models and massive cloud infrastructure. The smart play is clear: deploy it as a powerful local open-weight model, verify API availability before scaling, and anchor your deployment around measurable latency, safety, and compliance requirements.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






