A few years ago, choosing an AI model was relatively simple. You probably didn’t even know the term AI model as ChatGPT was used synonymously with it. It was the obvious (and maybe the only) choice at the time.
But times have changed. ChatGPT is no longer the one-stop for AI models. Claude, Grok, Gemini, Deepseek, Qwen, Kimi, Llama… and many more are available to use. This choice was supposed to empower the users. But this is reality has had the opposite effect!
This is because these models look and feel the same (the same chatbot interface) and are evolving at a comparable pace. So the real question is no longer “Which model is the best?”
It is: Which model is the best for me?
And based on what I’ve seen, this is where most people get it wrong.
Table of contents
The Problem
ChatGPT can write polished emails for you. But so can Claude, DeepSeek, Gemini, and almost every other AI model today.
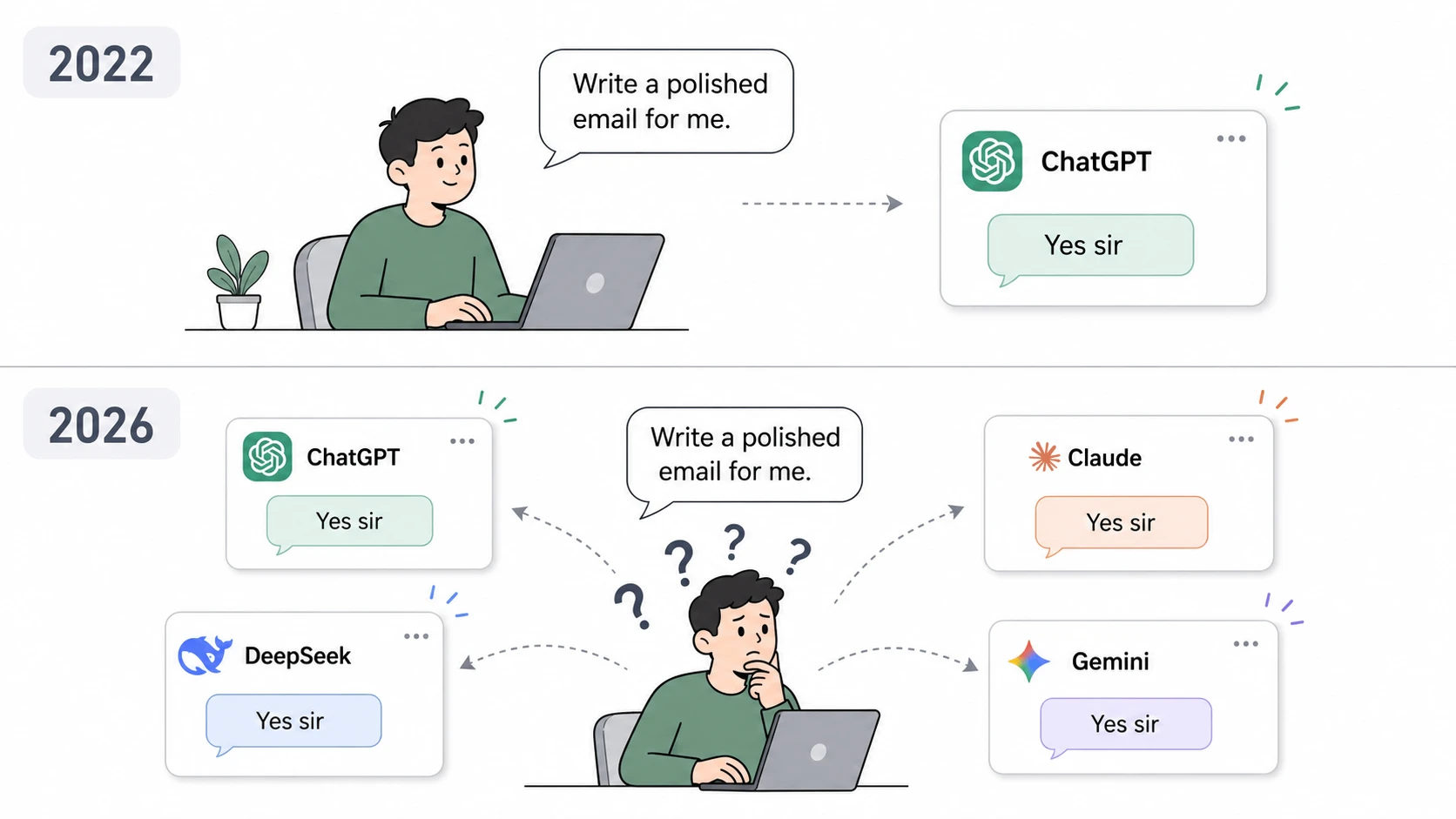
That is the problem.
At the surface level, these models are interchangeable. They can all summarize documents, explain concepts, write code, and answer questions. For the average user, the differences are not immediately obvious.
So people start choosing models for the wrong reasons:
- Their friend recommended it.
- It went viral on social media last week.
- It topped an AI benchmark (which isn’t always a good indicator)
- It was the first model they tried.
- It happens to be the default option in an app they already use.
None of these are terrible reasons. But they are not particularly thoughtful ones either.
The better way to choose an AI model is to stop asking which one is best overall and start asking what you actually need the model to do. But before going over what to do when choosing a model, let’s take a look at a few things not to do.
Benchmarks: The Smoke Screen
Most people start using a chatbot for one primary reason. Maybe they need help writing, coding, researching, or brainstorming.
And if you’re here for best of the best in a specific domain you can use this table as a guide for picking your model:
Now if the previous table was able to influence your model choice, this is the exact problem I was referring to.
Because, these results were obtained using the flagship version of the listed models, which are all paid. This might not be a problem for those who have a subscription of these models, but for those without, here is how the equation changes:
- Claude Opus: Can’t be accessed without a paid subscription.
- GPT-5.5 Thinking: Free users get 10 GPT-5.5 messages every 5 hours, then chats switch to the mini model: Thinking access is much more limited than paid tiers.
- Gemini 3.1 Pro: Google uses compute-based limits that refresh every 5 hours until a weekly cap is reached: higher access to Gemini 3.1 Pro is tied to Google AI Pro/Ultra plans.
- GPT Image 2: ChatGPT Free includes image generation, but OpenAI lists it as limited and slower.
You can clearly see how these models are no longer a choice if you’re are lacking a subscription.

Considering that most of the users of an AI model are using the free tier, the disparity in the service model is noteworthy.
Note: This should alert you for any benchmark or metric for a model. This is because most of these are obtained using the SOTA variants of the models which are usually paid. Their free variants — leave a lot to be desired.
The Perspective: What works for Us?
Choosing a model based solely on benchmark rankings is a lot like choosing a car based solely on its top speed. The number may be correct, but you might be looking for safety and comfort (making it kind of pointless).
In practice, factors like pricing, rate limits, context windows, ecosystem integrations, and even response style preference often have a bigger impact on the user experience than a few percentage points on a leaderboard.

This is why two people can look at the exact same benchmark results and still arrive at completely different model choices.
- A software engineer with a AI model subscription
- A student using free-tier tools
- A marketer already embedded in Google’s ecosystem
These are solving different problems under different constraints.
So before deciding which model to use, it helps to zoom out from the leaderboards and consider the factors that actually shape your day-to-day experience.
The Choice: Your Own Framework
Instead of relying on a benchmark or a framework someone posted online, we’ll build our own evaluation metric.
Start with something simple: list the three most common tasks you use a chatbot for.
Your actual tasks.
For me, that would be:
- Writing a first draft of an article.
- Comparing several options (on Amazon) and recommending one.
- Learning something new through a back-and-forth conversation.
The point is to ground the evaluation in our own reality.
You don’t care if a model tops a benchmark leaderboard if it fails at the things you actually need it to do.
- Claude might be the smartest model on paper, but if you need image generation and it can’t create images, it’s useless.
- Gemini might score exceptionally well on coding benchmarks while being terrible at making purchasing decisions makes it a terrible choice.
So instead of asking “Which model is the best?”, we’re asking a much narrower question:
Which model is the best for me?
Once you’ve picked your tasks, create a simple scoring rubric.
For each task, rate the model on a scale of 1 to 5. The exact criteria don’t matter. Maybe you care about accuracy. About speed, or maybe you care about how often the model misunderstands instructions.
Just make sure you’re measuring the same things across every model. Then run each task through every chatbot you’re evaluating.
My Choice
In my case upon evaluation the top 3 models right now on my workload gave me the following results:
| Task | GPT | Claude | Gemini |
| Writing | ★★★★★ | ★★★★☆ | ★★☆☆☆ |
| Research | ★★★★★ | ★★★★☆ | ★★★★☆ |
| Learning | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| Final Score | 14/15 Winner | 12/15 | 10/15 |
GPT-5.5 came out ahead for my workload because it was consistently useful across all three tasks.
- Claude Opus-4.8 was comparable to GPT-5.5, but the paywall behind models was a no-go for me.
- Gemini 3.5 Pro was godaweful when it came to writing drafts.
Conclusion
There is no universally best AI model. The right choice depends on your preference and work. Benchmarks can guide you, but they cannot make that decision for you.
The safest approach is simple: test a few models on three tasks you regularly perform, score them consistently, and pick the one that wins for your use case. That keeps your decision grounded in evidence, not hype.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






