For years, AI progress has centered on scaling individual foundation models: larger parameters, longer context windows, stronger reasoning, and better tool use. Sakana AI’s Fugu points elsewhere, behaving like one model from the outside while coordinating multiple expert agents internally.
A single API call can trigger direct answering, specialist delegation, intermediate verification, and final synthesis, hiding orchestration complexity behind a normal LLM interface. In this article, a practical guide to Fugu’s architecture, variants, pricing, benchmarks, access, code, tests, enterprise fit, trade-offs, and use cases.
Table of contents
What is Sakana Fugu?
Sakana Fugu is an OpenAI-compatible managed model API that looks like a single LLM but works as a multi-agent system internally. Developers send a prompt to one model ID, such as fugu or fugu-ultra, while Fugu handles agent selection, role assignment, coordination, verification, and final response.
Instead of manually building planner, coder, reviewer, researcher, or supervisor agents with frameworks like LangGraph, AutoGen, or CrewAI, teams get orchestration packaged into the model itself. This reduces the need to manage prompts, routing, retries, memory, state, monitoring, and failure recovery.
Why the naming matters
The name “Sakana” means fish in Japanese. The company often frames its research around collective intelligence, similar to how a school of fish can behave as one coordinated system. Fugu follows that idea. Many agents coordinate behind one interface.
Why Multi-Agent System as a Model Matters
Most production AI systems today fall into one of three patterns:
- Single-model prompting
- Tool-augmented LLM applications
- Manually designed multi-agent workflows
Single-model prompting is simple, but it can fail on complex tasks that require planning, execution, verification, and iteration.
Tool-augmented LLMs improve usefulness by connecting models to search, databases, code execution, APIs, or business systems. But the model still usually acts as the central reasoning engine.
Multi-agent workflows go further. They divide work across specialized agents. For example:
- A planner breaks down the task.
- A researcher gathers context.
- A coder writes code.
- A reviewer checks for correctness.
- A verifier tests the answer.
- A supervisor coordinates the process.
This can improve reliability on difficult tasks, but building it well is hard. Teams must answer many system design questions:
- Which agent should handle which task?
- How should agents communicate?
- When should the system stop?
- How should intermediate outputs be verified?
- How should cost and latency be controlled?
- How should failures be recovered?
- How should compliance restrictions be applied?
Fugu attempts to make this easier by turning multi-agent orchestration into a model-level capability. The developer does not need to design every agent interaction manually.
Fugu vs Fugu Ultra
Sakana Fugu comes in two main model options: Fugu and Fugu Ultra.
Fugu
Fugu is the default model for everyday work. It balances performance and latency. It is suitable for coding support, code review, chatbots, internal assistants, document analysis, and interactive workflows where response time matters.
A key point is that Fugu can route to the best model based on the task. It also allows users to opt specific agents out of the model pool, which can help with data, privacy, compliance, or organizational requirements.
Fugu Ultra
Fugu Ultra is optimized for maximum answer quality. It coordinates a deeper pool of expert agents and is intended for hard, high-stakes, multi-step problems. According to the Sakana, Fugu Ultra can route between one to three agents depending on the problem.
Fugu Ultra is better suited for workloads where accuracy, depth, and persistence matter more than latency. Examples include:
- Paper reproduction
- Kaggle-style data science workflows
- Cybersecurity analysis
- Literature review
- Patent investigation
- Deep technical research
- Complex code review
- Scientific reasoning
Comparison table
| Feature | Fugu | Fugu Ultra |
| Best for | Everyday coding, chat, review, interactive workflows | Hard reasoning, research, high-stakes analysis |
| Design goal | Balance quality and latency | Maximize quality |
| Agent pool | Flexible, with opt-out support | Fixed full pool |
| Latency | Lower | Higher |
| Cost | Depends on active underlying agent tier | Fixed token pricing |
| Recommended users | Developers, product teams, internal tools | Researchers, advanced developers, enterprise analysis teams |
| Main trade-off | Less depth than Ultra | Higher cost and response time |
Architecture: How Fugu Works Internally
Fugu’s architecture can be understood as a managed orchestration layer wrapped inside a model API.
From the outside, the flow looks like this:
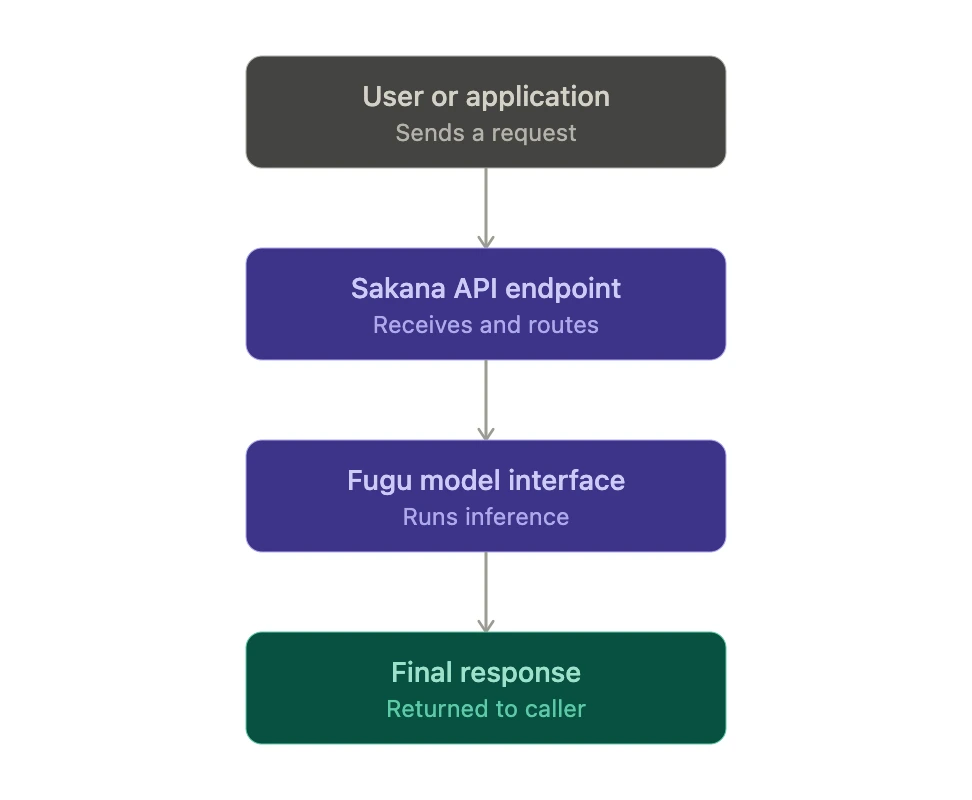
Internally, the system is closer to this:
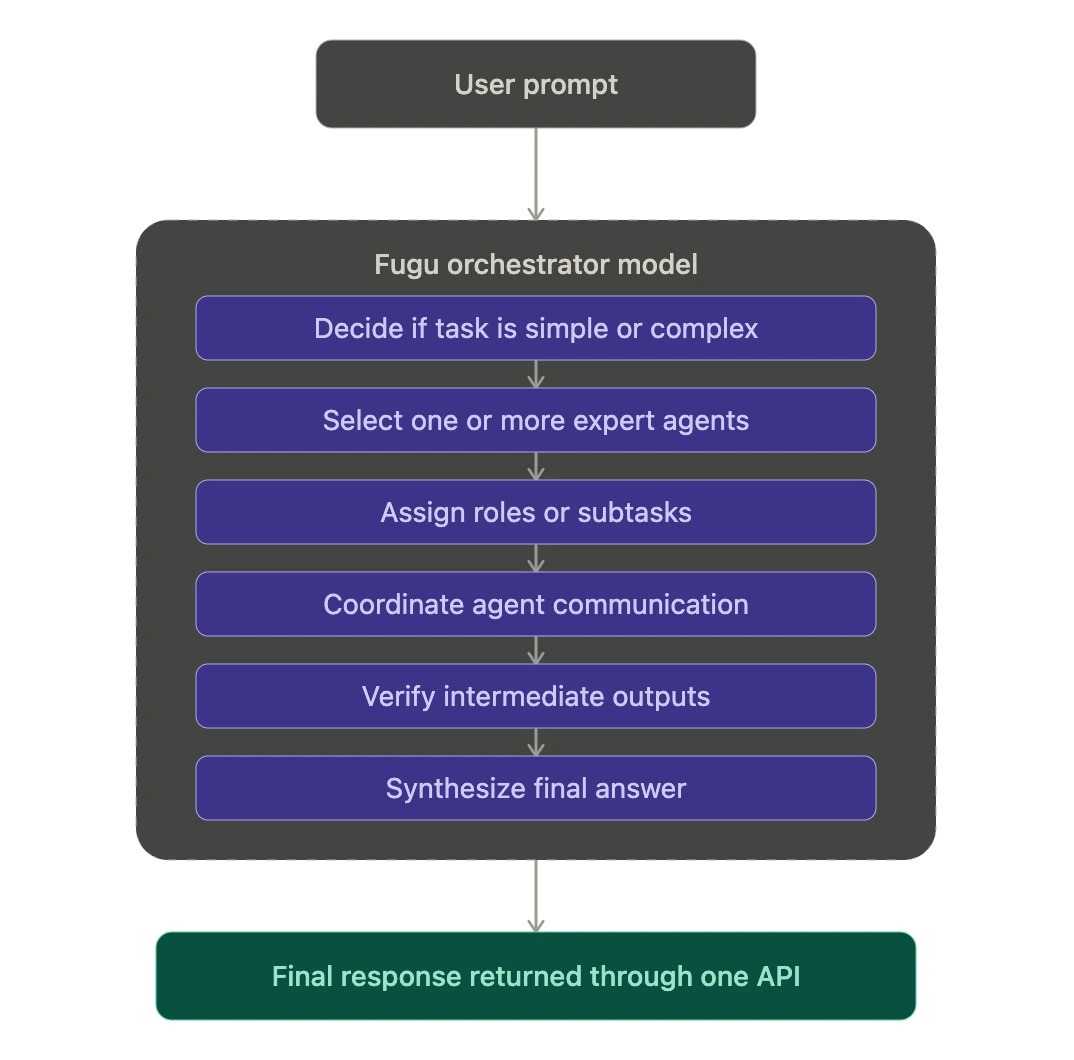
Sakana Fugu exposes a single API while internally coordinating a pool of specialized models. The user sends one request, and Fugu handles routing, delegation, verification, and synthesis.
Core architecture components
1. API gateway
The developer interacts with a standard API surface. This matters because Fugu supports OpenAI-compatible endpoints, so teams can reuse existing OpenAI SDK clients with a different base URL and API key.
2. Orchestrator model
The orchestrator is the core intelligence layer. It decides how the task should be handled. For simpler tasks, it may answer with minimal orchestration. For complex tasks, it can coordinate multiple expert agents.
3. Agent pool
Fugu has access to a pool of underlying models or agents. These agents may have different strengths across coding, reasoning, research, long-context analysis, or other specialized tasks.
4. Dynamic routing
Instead of hardcoding a workflow, Fugu dynamically selects which agent or agents to use. This is important because model strengths are often task-specific. One model may perform better at code generation, another at mathematical reasoning, another at long-context synthesis.
5. Delegation and communication
The orchestrator can break down a complex task into subtasks. It can send focused instructions to different agents and control what context each agent receives.
6. Verification
For difficult tasks, the system can use verification-style behavior. One agent may solve, another may critique or validate, and the orchestrator may combine the results.
7. Synthesis
The final answer is returned as a single response. The user does not see the full internal agent graph. .
Pricing
Fugu has two pricing modes: pay-as-you-go and subscription plans.
Pay-as-you-go
Pay-as-you-go is designed for heavier production workloads. Sakana says consumption-based tokens are served at higher priority than monthly-plan tokens.
Fugu pricing
Fugu pricing depends on the active agent setup.
| Active agents | Billing rule |
| 1 agent | Pay the standard rate for the specific underlying model |
| Multiple agents | Fees are not stacked. You are charged one rate based on the top-tier model involved |
This is important because many multi-agent systems become expensive when each model call is billed separately. Fugu’s pricing model tries to avoid stacking model fees across agents.
Fugu Ultra pricing
Fugu Ultra has fixed pricing for fugu-ultra-20260615 per 1M tokens.
| Token type | Standard price | Context greater than 272K |
| Input | $5 per 1M tokens | $10 per 1M tokens |
| Output | $30 per 1M tokens | $45 per 1M tokens |
| Cached input | $0.50 per 1M tokens | $1.00 per 1M tokens |
Subscription plans
Subscription plans are designed for individuals and everyday hands-on use. Every tier includes both Fugu and Fugu Ultra.
| Plan | Price | Best for | Usage |
| Standard | $20/month | Lightweight daily usage, occasional API calls, small experiments | Baseline allowance |
| Pro | $100/month | Regular coding, review, research, and analysis sessions | 10x Standard usage |
| Max | $200/month | Heavy long-running workloads | 20x Standard usage |
Benchmark Results
Sakana reports Fugu and Fugu Ultra benchmark scores across coding, reasoning, science, agentic tasks, long-context reasoning, and cybersecurity-style evaluation.
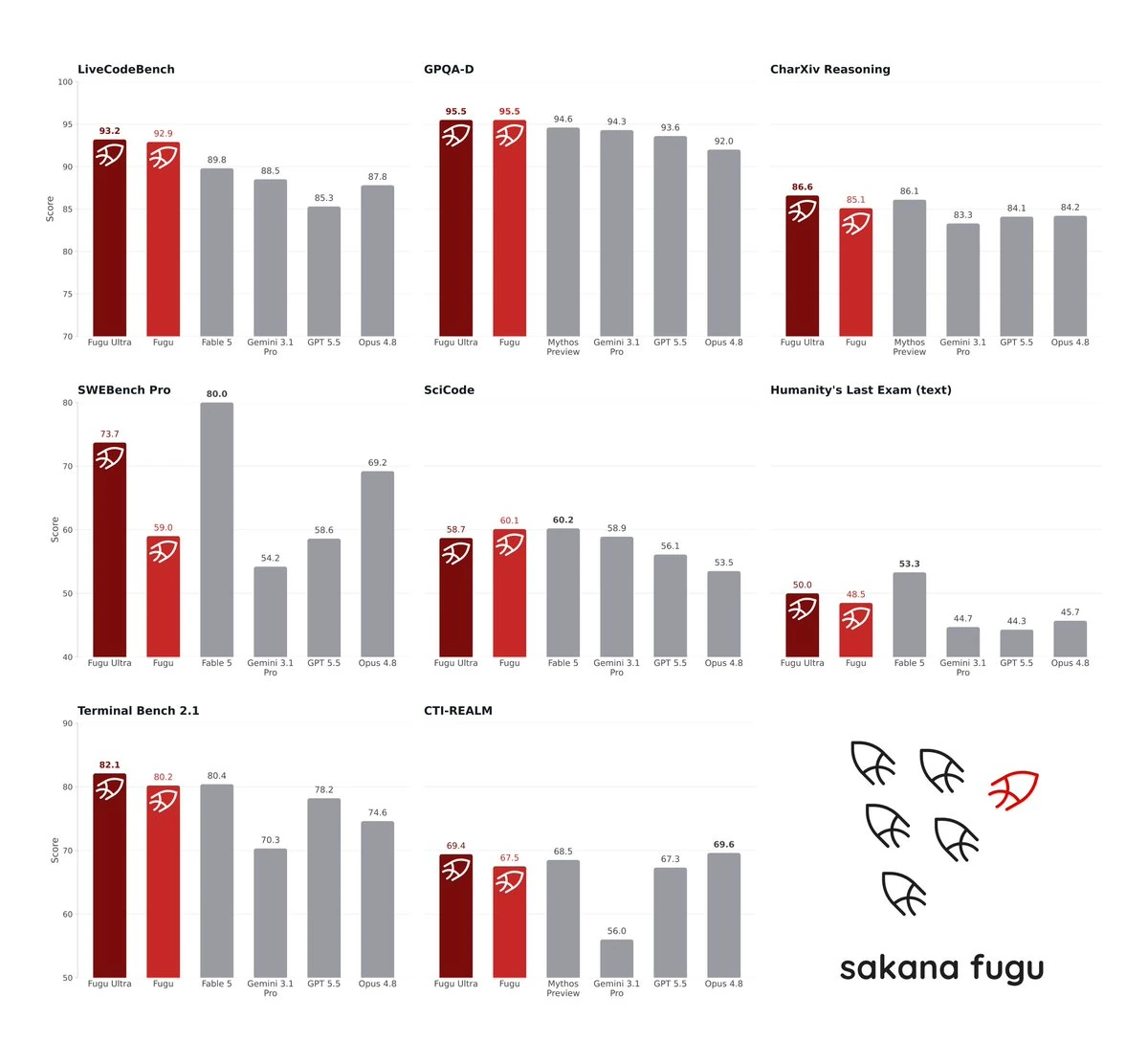
Sakana Fugu and Fugu Ultra compared with frontier baseline models across coding, reasoning, science, long-context, and agentic benchmarks.
Benchmarks are useful, but they should not be treated as direct production guarantees. Fugu’s benchmark profile suggests three practical insights.
1. Fugu is strongest when tasks require orchestration
The strongest use case is not a simple one-shot answer. The model is designed for tasks that benefit from decomposition, expert selection, verification, and synthesis.
Examples:
- Debug this repository.
- Review this pull request.
- Reproduce this research paper.
- Investigate this patent landscape.
- Analyze a possible security vulnerability.
- Compare multiple technical approaches and recommend one.
2. Ultra is not always automatically better
Fugu Ultra is optimized for answer quality, but Fugu can outperform it on some benchmarks. Developers should benchmark both models on their own workload before standardizing.
A practical routing strategy could be:
Use fugu for interactive work.
Use fugu-ultra for complex, high-value tasks.
Fallback to fugu when latency or cost matters.
3. Multi-agent performance comes with hidden complexity
Even though Fugu hides orchestration complexity from the developer, the underlying system still performs additional work. This can affect latency, cost, and observability.
Teams should monitor:
- Total tokens
- Orchestration tokens
- Latency by task type
- Quality by workload category
- Failure cases
- Model version behavior
- Cost per successful outcome
Technical Hands-on: Using Sakana Fugu API
Sakana fugu documentation: https://console.sakana.ai/get-started
1: Create an API key
Go to the Sakana console API key page login and create API: https://console.sakana.ai/api-keys
Create an API key and store it securely. The key is shown only once.
2: Set environment variables
export FUGU_API_KEY="your_api_key_here"
export FUGU_BASE_URL="https://api.sakana.ai/v1"
3: Install the OpenAI Python SDK
pip install openai 4: Basic Responses API call
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["FUGU_API_KEY"],
base_url=os.environ.get("FUGU_BASE_URL", "https://api.sakana.ai/v1"),
)
response = client.responses.create(
model="fugu",
input="Explain Sakana Fugu in simple terms for a software engineer.",
)
print(response.output_text)Step 5: Use Fugu Ultra for harder reasoning
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["FUGU_API_KEY"],
base_url=os.environ.get("FUGU_BASE_URL", "https://api.sakana.ai/v1"),
)
response = client.responses.create(
model="fugu-ultra",
instructions="You are a senior AI architect. Be precise and technical.",
input="""
Compare single-agent LLM systems, manually designed multi-agent workflows,
and Sakana Fugu-style multi-agent systems as a model.
Focus on architecture, cost, latency, observability, and governance.
""",
)
print(response.output_text)Conclusion
Sakana Fugu stands out because it shifts the abstraction layer. Instead of offering just another large model, it packages multi-agent orchestration behind a model API.
For developers, this means easier access to agentic workflows without building complex orchestration systems from scratch. For technical leaders, it offers a managed way to improve reasoning, coding, research, and analysis while reducing dependence on a single model provider.
Fugu is best suited for complex, ambiguous, high-value tasks rather than simple chatbot prompts. Still, teams should adopt it carefully, given its limited routing transparency, possible latency, unclear token accounting, and regional constraints.
The simplest way to think about Fugu is this: it is not just a model you prompt. It is a model that manages other models. That makes it an important step toward the next generation of AI applications.
Frequently Asked Questions
Q1. Is Sakana Fugu a single model or a multi-agent system?
A. It is exposed as a single model API, but internally it behaves as a multi-agent orchestration system.
Q2. What model IDs should I use?
A. Use fugu for standard work and fugu-ultra for complex, high-value tasks. Use fugu-ultra-20260615 if you want to pin a specific Ultra version.
Q3. Is Fugu OpenAI-compatible?
A. Yes. It supports OpenAI-compatible Responses, Chat Completions, and Models APIs.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






