The latest release of GPT-5 has taken the world by storm. OpenAI’s newest flagship model has received mixed reviews – while some praise its capabilities, others highlight its shortcomings. This made me wonder: Is GPT-5 truly superior to the original favorite, GPT-4o?
Personally, GPT-4o was my go-to LLM for everything from text summarization to image generation and data analysis. Now that OpenAI has replaced it with GPT-5, I decided to put both models to the test. Is this upgrade genuinely evolutionary, or a rushed move that might diminish ChatGPT’s appeal?
Let the battle of the GPTs begin!
Table of contents
GPT 5 and GPT 4o: A Quick Reminder
Let’s quickly dive into details about the two chatGPT models that we will be testing in this blog: GPT-5 and GPT 4o
GPT-5
Released last week, GPT-5 now stands as ChatGPT’s most advanced model. OpenAI’s latest multimodal LLM introduces agentic capabilities and a ‘unified system’ for task assessment. This system automatically determines whether a query requires deep reasoning or basic processing. Unlike previous models, GPT-5 follows a ‘learn-by-doing’ approach. It shows increased empathy while being less agreeable than its predecessors. Along with this GPT-5 comes with enhanced coding, writing and vibecoding powers
Find more in my previous article on GPT-5.
GPT-4o
Released last year, GPT-4o (where “o” means “omni”) was the first-of-its-kind model. This multimodal changed the way people used ChatGPT. The model came with enhanced coding and visual analysis capabilities. GPT-4o came with speech recognition and speech analysis features too. The model came with increased processing speed and reduced response latency. OpenAI’s GPT-4o generated more natural and sensible responses, and was able to access tools and give real-time information.
To know more, checkout this article on GPT 4o.
GPT 5 vs GPT 4o: Feature Comparison
| Feature | GPT-4o | GPT-5 |
| Release Date | May 2024 | Aug 2025 |
| Modalities | Text, Image, Audio | Text, Image, Audio, Video |
| Context Window (ChatGPT) | ~128k tokens | 256k tokens |
| Context Window (API) | ~128k tokens | 400k tokens |
| Reasoning Mode | Single model | Dual-mode: Fast + Deep Reasoning |
| Hallucination Rate | Low | Lowest yet among OpenAI models |
| Personalization | None | Personality presets + tone control |
| Tool Integration | Limited | Gmail, Calendar, code tools, more |
| Safe Completions | No | Yes – bounded, useful answers |
| SWE-bench Verified | 30.8% accuracy | 74.9% accuracy |
| AIME 2025 (Math) | 71% | 94.6% (without tools) |
| VideoMMMU | 58.8% | 81.1% |
| HealthBench | 31.6% | 46.2% |
| Target Use Cases | Real-time interaction, creative tasks | Complex reasoning, enterprise workflows |
GPT 5 vs GPT 4o: Task Comparison
Now, let’s put both models to the test by evaluating their performance on the following tasks:
- Content creation
- Image Generation
- Coding
- Image Analysis
- Reasoning
Let the GPT-5 vs GPT-4o battle begin!
Task 1: Content Creation
Read the article at https://www.analyticsvidhya.com/blog/2024/07/building-agentic-rag-systems-with-langgraph/ to understand the process of creating a vector database for Wikipedia data. Then, provide a concise summary of the key steps.”
GPT-5 Response:
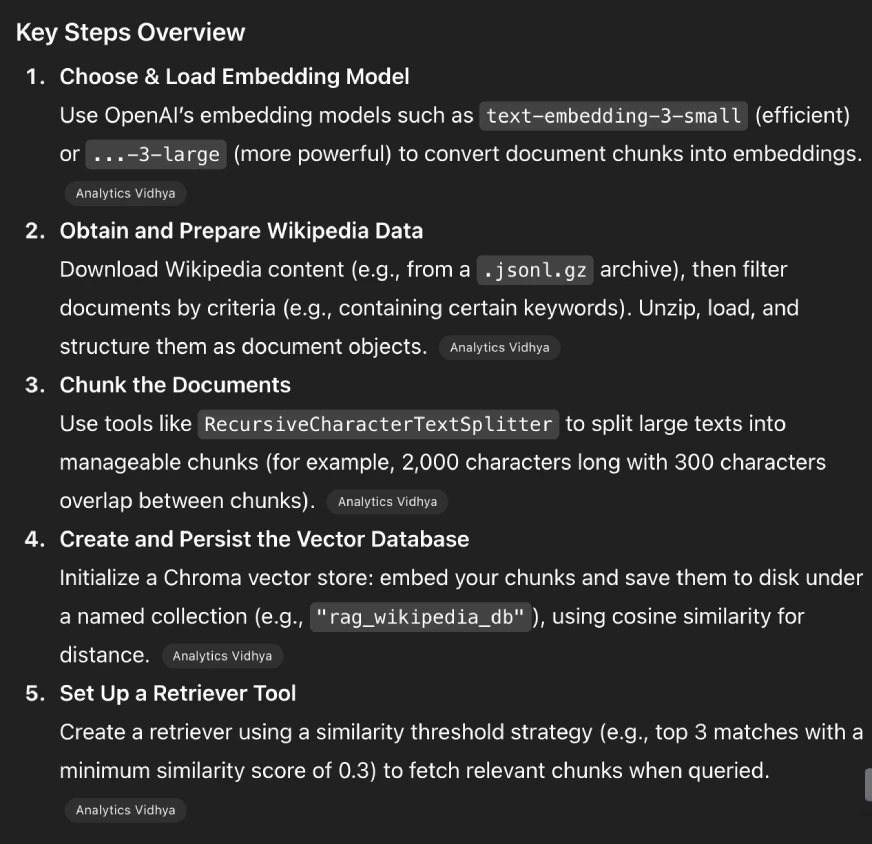
GPT-4o Response:

Observation:
The response generated by GPT-5 is the concise summary that a person knowledgeable on the topic would want. The steps are all listed in proper order and come with just enough context. On the other hand, GPT-4o’s response is a summary of all the steps mentioned in the blog. It lists all the steps that were covered in the blog in the same manner as discussed there. The difference in the approach of the two models is: GPT-5 merges the points to generate a concise summary of the entire process, whereas GPT-4o creates a concise summary of all the steps covered in the blog.
Task 2: Image Generation
The image is of working of a voice agent. It has 3 main parts
Speech-to-text (STT): Captures and converts your spoken words into text.
Agentic logic: This is your code (or your agent), which figures out the appropriate response
Text-to-speech (TTS): Converts the agent’s text reply back into audio that is spoken aloud.
Convert this basic image into vibrant image.
GPT-5 Response:
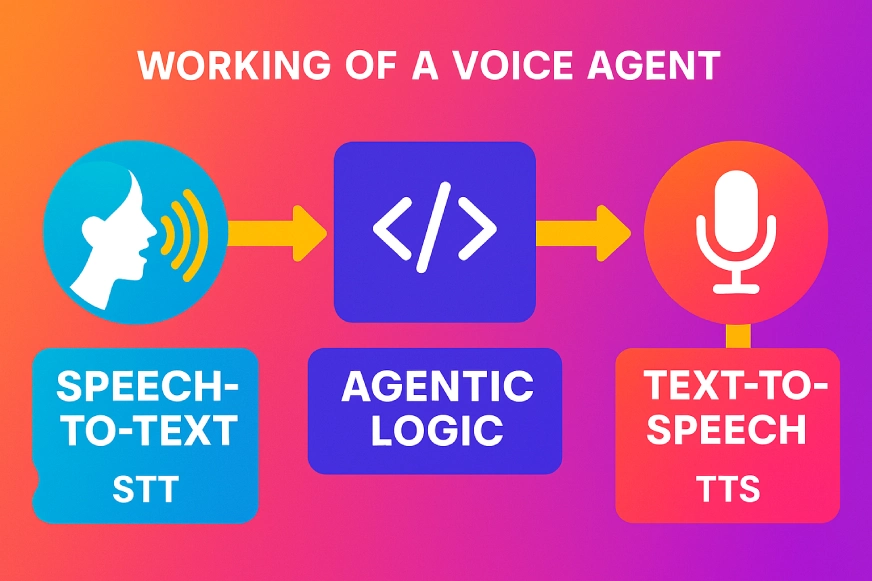
GPT-4o Response:

Observation:
The task was simple, and both models executed it quite well. Starting with GPT-5, it created a vibrant image with popping colors. The image it generated had text and icons; however, there was a minor error – a small arrow connecting the mic icon with the TTS box. As for the image generated by GPT-4o, it used solid colors, making it less vibrant. The strengths of GPT-4o’s image were the audio input and output sources that it included.
Task 3: Coding
Basic HTML code for a word-counting website.
GPT-5 Response:
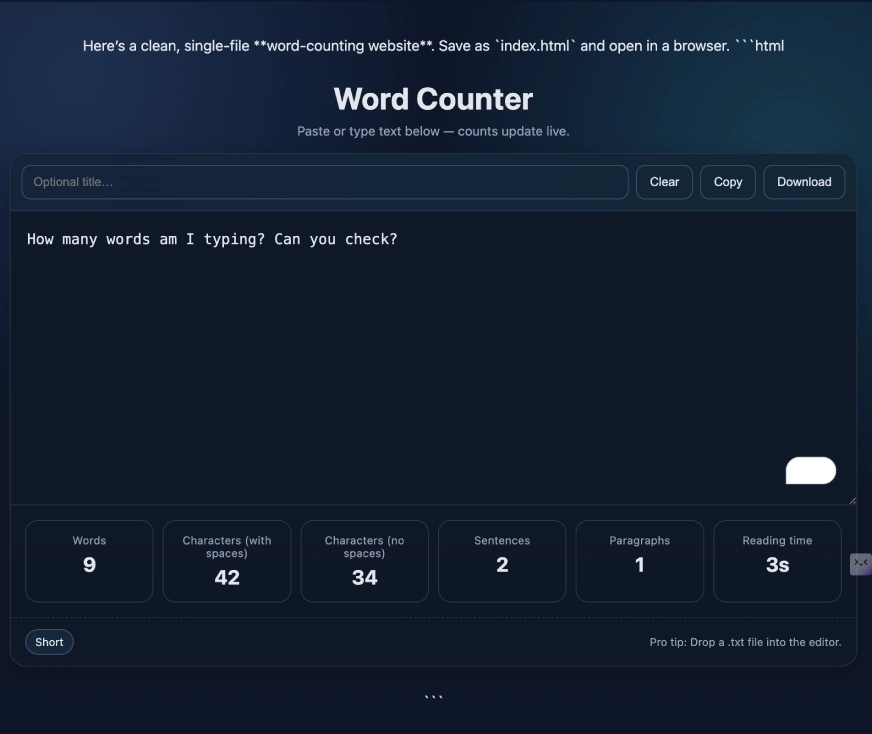
GPT-4o Response:

Observation:
GPT-5 took some time to generate the code for this query, specifically for the word counter website. However, the final output was quite impressive. The UI/UX and features came together to create a fully functional word-counting webpage. On the other hand, GPT-4o’s output felt lackluster in comparison. The UI/UX was basic, offering only the core word-counting feature without additional refinements. Its design also appeared somewhat outdated
Task 4: Image Analysis
Calculate the output of this circuit diagram.

GPT-5 Response:

GPT-4o Response:

Observation:
GPT-5 answered this question quickly, analyzing both the image and its components efficiently. It correctly identified the half-wave rectifier, read the values marked on the diagram, and applied the proper logic to calculate the output current and voltage values. In contrast, GPT-4o struggled with this task. While it recognized the output waveform, it failed to process other critical factors. Most notably, GPT-4o couldn’t extract the necessary values from the image to perform any calculations.
Task 5: Reasoning
Solve the following Sudoku and give the final solution as an image.
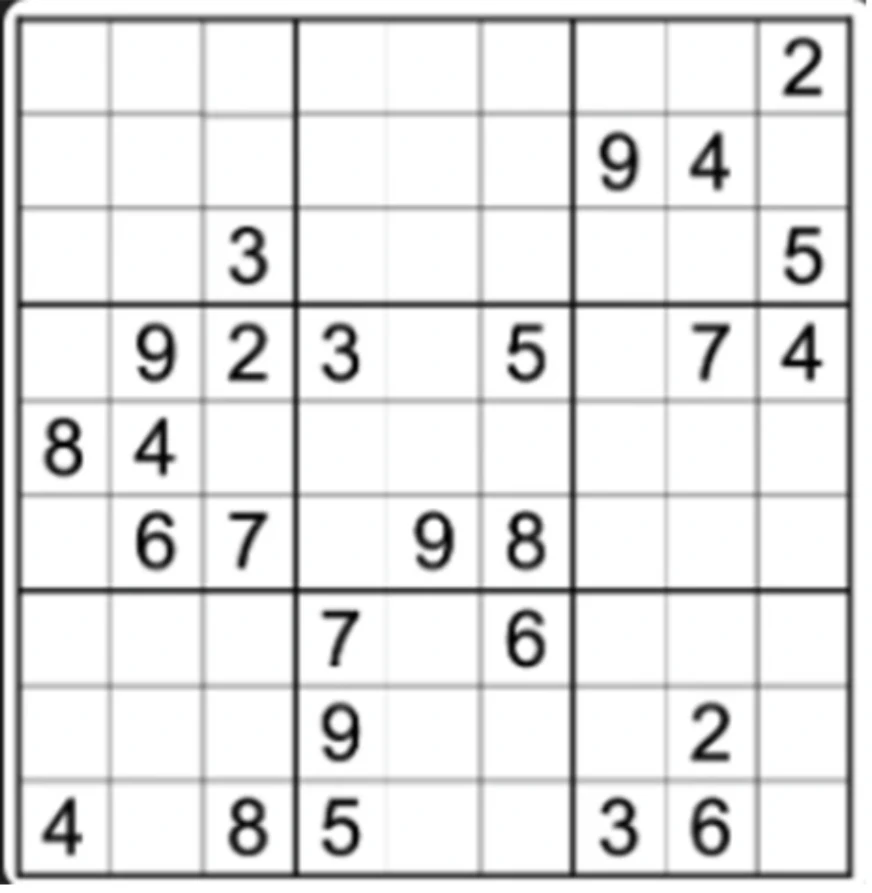
GPT-5 Response:

GPT-4o Response:

Observation:
GPT-5 initially struggled with image interpretation, taking over three minutes to process the input. Rather than solving the puzzle independently, it requested confirmation of multiple values within the image. After I manually provided all the row values, the model successfully processed and solved the puzzle, yielding a correct solution, though requiring significant user assistance.
GPT-4o, by contrast, failed to solve the puzzle entirely. It simply populated all missing values with zeros and presented this as its output solution.
GPT-5 vs GPT-4o: Final Verdict
Selecting a clear winner has never been more challenging. Here’s how the two LLMs performed across different tasks:
| Task | GPT-5 | GPT-4o |
|---|---|---|
| Content Creation | More concise | Better summarized |
| Image Generation | More vibrant | More creative |
| Coding | Great | Limited capability |
| Image Analysis | Average | Average |
| Reasoning | Excellent | Basic capability |
Is there a clear winner between the two? The answer is no. Performance varies significantly by task:
- GPT-5 dominates in coding and reasoning
- GPT-4o holds its own in content creation and image generation/analysis
- Speed vs. Depth: GPT-4o delivers faster responses, while GPT-5 sometimes hesitates between thorough analysis and quick generation
Context matters: Remember that GPT-4o is a year older. While GPT-5 benefits from more recent training data and agentic optimizations, is it truly groundbreaking compared to its predecessor? Not exactly.
Conclusion
As the world demands GPT-4o’s comeback, I wholeheartedly agree.
While GPT-5 has improved since Day 1 (now outperforming its Day 3 results), its rushed launch left users struggling to adapt. The truth is, GPT-5 only marginally surpasses GPT-4o on specific tasks, making it painfully hard to abandon our beloved GPT-4o for something that feels merely “a tad better.” Perhaps OpenAI needed more rigorous testing before release. But now that it’s live, we can only watch its evolution.
Today? I’d sign any petition to bring back GPT-4o. ChatGPT has changed, and not for the better. Let me know your thoughts in the comment section.
PS: I took GPT 4o outputs from our previous blogs:
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.






