If you use AI tools regularly, you must’ve had this easy realisation – no one tool is perfect for all tasks. While some lead the pack in terms of content production (like ChatGPT), there are others that are way better at generating images and videos (like Gemini). With such specific use-cases, we’ve seen a horde of AI tools flood the market. Now, Alibaba’s Qwen plans to challenge this scattered AI-tool-pool with its all-new Qwen3-Omni.
How? The Qwen team introduces Qwen3-Omni as a new AI model that understands text, images, audio, and even video in one seamless flow. Moreover, the model and replies in text or voice in real time, consolidating all use-cases in a single, seamless conversation. It’s fast, open source, and designed to work like a true all-rounder. In short, Qwen3-Omni wants to end the compromises and bring one model that does it all.
But does it do that? We try it out here for all its claims. Before that, let’s explore what the model brings to the table.
Table of contents
What is Qwen3-Omni?
For those unaware, the Qwen family of large language models come from the house of Alibaba. Qwen3-Omni is its latest flagship release, built to be “truly multimodal” in every sense. With that, the company basically means that the Qwen3-Omni doesn’t just process words, but also understands images, audio, and video, while generating natural text or speech back in real time.
Think of it as a single model that can recommend a pasta dish in French, describe a music track’s emotion, analyze a spreadsheet, and even answer questions about what’s happening in a video clip, all without switching tools.
As per its release announcement, what sets Qwen3-Omni apart is its focus on speed and consistency. Instead of adding separate plug-ins for different media types, the model has been trained to handle everything natively. The result is a system that feels less like “text with add-ons” and more like an AI that sees, hears, and talks in one continuous flow.
For researchers and businesses, this unlocks new possibilities. Customer support agents can now see product issues via images. Tutoring systems can listen and respond like a human. Productivity apps can now blend text, visuals, and audio in ways older models couldn’t manage.
Key Features of Qwen3-Omni
Other than its multimodal design, Qwen3-Omni also stands out for its speed, versatility, and real-time intelligence. Here are the highlights that define the model:
- Truly multimodal: Processes text, images, audio, and video seamlessly.
- Real-time responses: Delivers instant outputs, including lifelike voice replies.
- Multilingual ability: Supports dozens of languages with fluent translation.
- Audio reasoning: Understands tone, emotion, and context in speech or music.
- Video understanding: Analyzes moving clips, not just static images.
- Open source release: Available freely for developers and research.
- Low-latency design: Optimized for fast, interactive applications.
- Consistent performance: Maintains strength across text and multimodal tasks.
- Flexible deployment: Can run on cloud or local systems.
- Enterprise-ready: Built for integration into apps, agents, and workflows.
How Does Qwen3-Omni Work?
Most AI models add on new skills as extra modules. That is exactly why some systems chat well, yet struggle with images, or process audio but lose context. Qwen3-Omni takes a different route, adopting a new Thinker–Talker architecture that is specifically designed for real-time speed.
The model combines four input streams: text, images, audio, and video into a shared space. This allows it to reason across formats in one flow. For instance, it can watch a short clip, hear the dialogue, and explain what happened using both visuals and sound.
Another key feature is low-latency optimization. Qwen’s team engineered the system for instant responses, making conversations feel natural, even in voice. This is why Qwen3-Omni can respond mid-sentence instead of pausing awkwardly.
And because it’s open source, developers and researchers can see how these mechanisms work and adapt them into their own apps.
Qwen3-Omni Architecture
At its core, Qwen3-Omni is powered by a new Thinker–Talker architecture. The Thinker generates text, while the Talker converts those high-level ideas into natural, streaming speech. This split design is what enables the model to speak in real time without awkward pauses.
To strengthen its audio understanding, the system uses an AuT encoder trained on 20 million audio hours of data, giving it a deep grasp of speech, sound, and music. Alongside this, a Mixture of Experts (MoE) setup makes the model highly efficient, supporting fast inference even under heavy use.
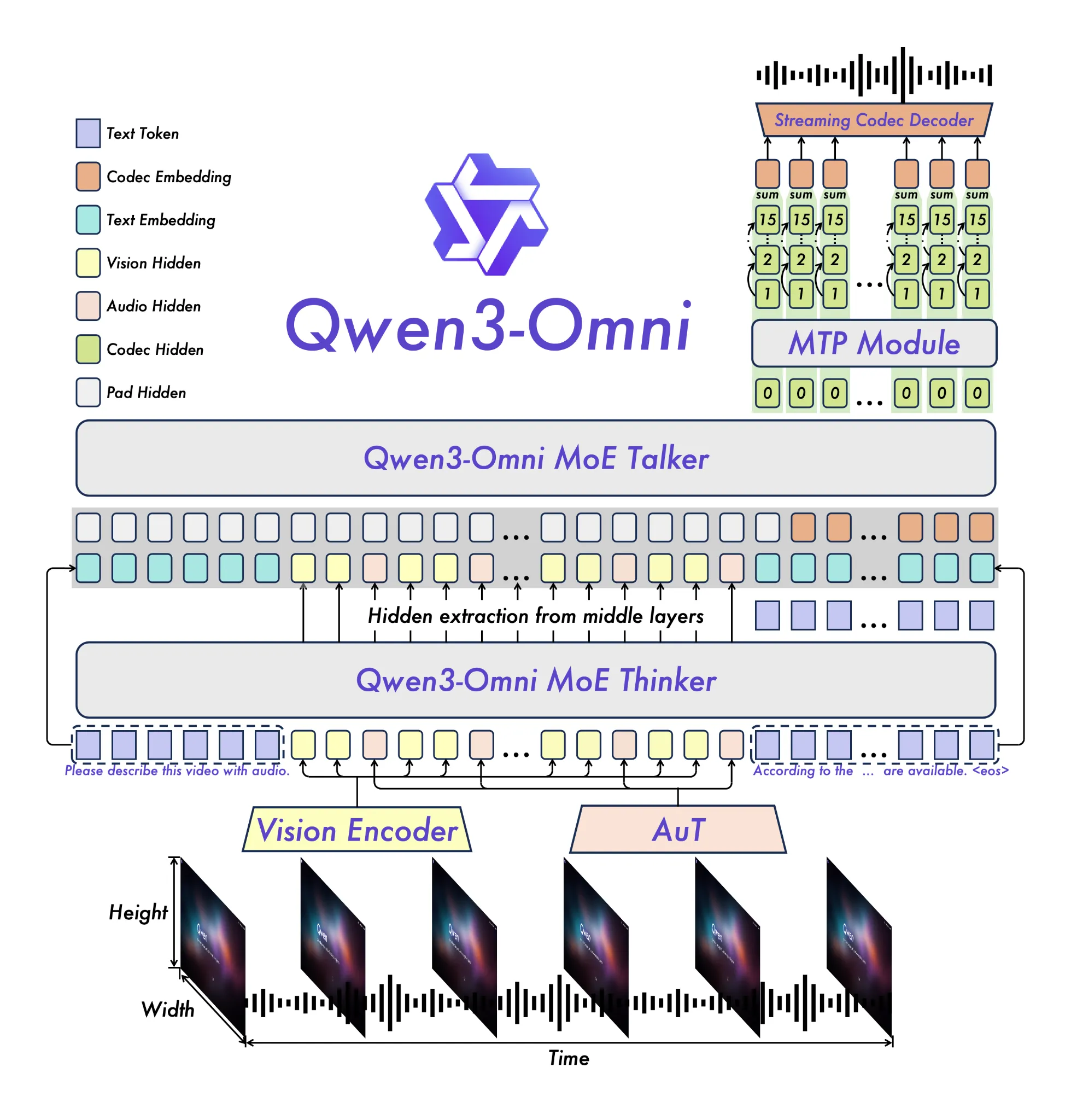
Finally, Qwen3-Omni introduces a multi-codebook streaming approach that allows speech to be rendered frame by frame, with extremely low latency. Combined with training that mixes unimodal and cross-modal data, the model delivers balanced performance across text, images, audio, and video, without sacrificing quality in any one area.
Qwen3-Omni: Benchmark Performance
Several evaluations were done to test Qwen3-Omni across leading benchmarks. Here is the summary:
- MMLU (Massive Multitask Language Understanding): Measures knowledge across 57 subjects. Qwen3-Omni scores 88.7%, outperforming GPT-4o (87.2%) and Gemini 1.5 Pro (85.6%).
- MMMU (Massive Multitask Multimodal Understanding): Tests college-level visual problem-solving across text and images. Qwen3-Omni achieves 82.0%, ahead of GPT-4o (79.5%) and Gemini 1.5 Pro (76.9%).
- Math (AIME 2025): Competition-level math problem solving. Qwen3-Omni records 58.7%, stronger than GPT-4o (53.6%) and Claude 3.5 Sonnet (52.7%).
- Code (HumanEval): Programming completion tasks. Qwen3-Omni reaches 92.6%, surpassing GPT-4o (89.2%) and Claude 3.5 Sonnet (87.1%).
- Speech Recognition (LibriSpeech): Evaluates automatic speech recognition. Qwen3-Omni hits 1.7% WER (word error rate), matching Gemini 2.5 Pro and beating GPT-4o (2.2%).
- Instruction Following (IFEval): Measures the accuracy of following natural language instructions. Qwen3-Omni achieves 90.2%, exceeding GPT-4o (86.9%) and Gemini 1.5 Pro (85.1%).
Alongside these, Qwen3-Omni shows strong results on additional tests like VQA-v2 for vision question answering and MOS-X for speech quality. Together, these results place it among the most capable open-source multimodal models to date.
Qwen3-Omni: How to Access
Qwen3-Omni is already available through Qwen’s official platform and API endpoints, making it easy for developers and enterprises to start experimenting today.
Here’s how you can try it out:
- On the Web: Go to the Qwen official site, sign in, and select Qwen3-Omni to start generating text, images, or videos directly in the browser.
- Via API: Access the model through ModelScope or Hugging Face, where APIs and documentation are provided for developers.
- Enterprise Access: Use Qwen3-Omni on Alibaba Cloud for scalable infrastructure and enterprise-level support.
Qwen3-Omni: Hands-on
I tried the new Qwen3-Omni to test its capabilities across all its claims. Here are the tests I put it through and the results it was able to deliver.
1. Text Generation
The go-to use case for any AI model, I tried Qwen3-Omni’s text generation ability using the following prompt.
Prompt:
Generate text for an elaborate 2-page printable magazine-style flier for an electric bicycle. The bicycle comes in three colours – black, blue, and red. It has a range of 30kms per charge and a top speed of 20 kms. It charges in 3 hours. Imagine all other necessary information and specifications.
Make sure to highlight all the features of the e-bike within the flier, and introduce it to the masses in as appealing manner as possible. target audience – young professionals in urban settings looking for a last-mile connectivity solution.
Output:
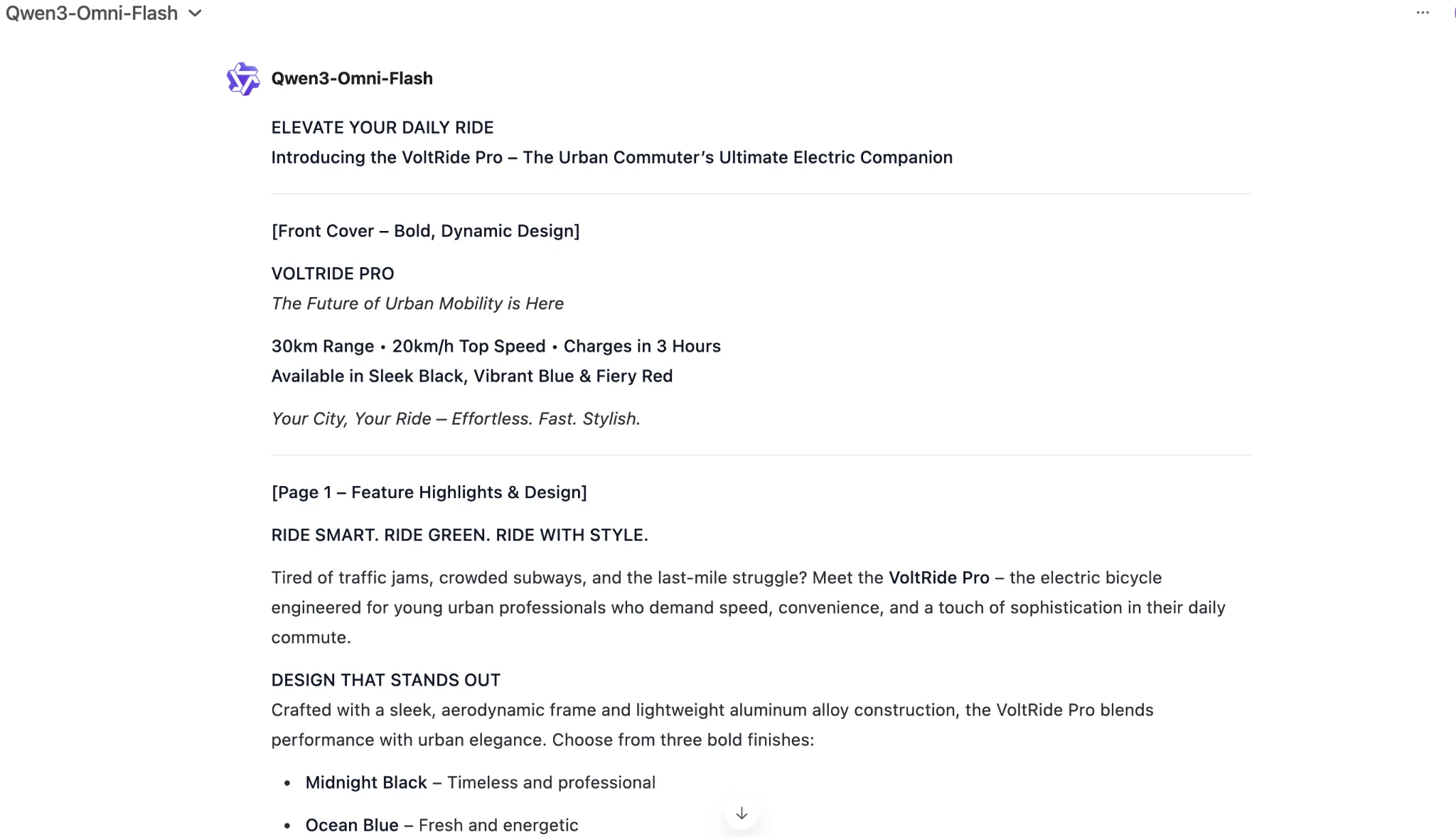

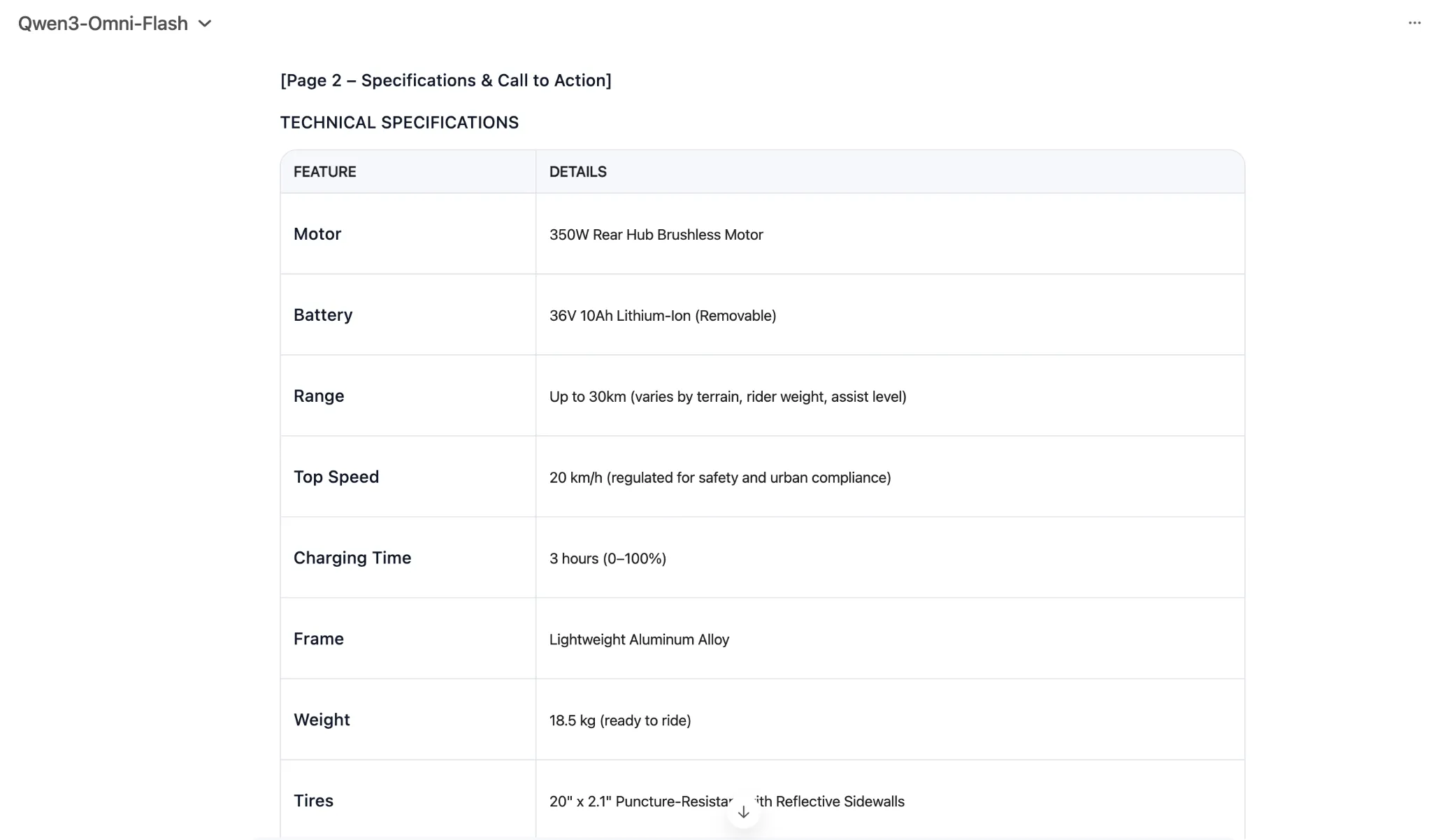
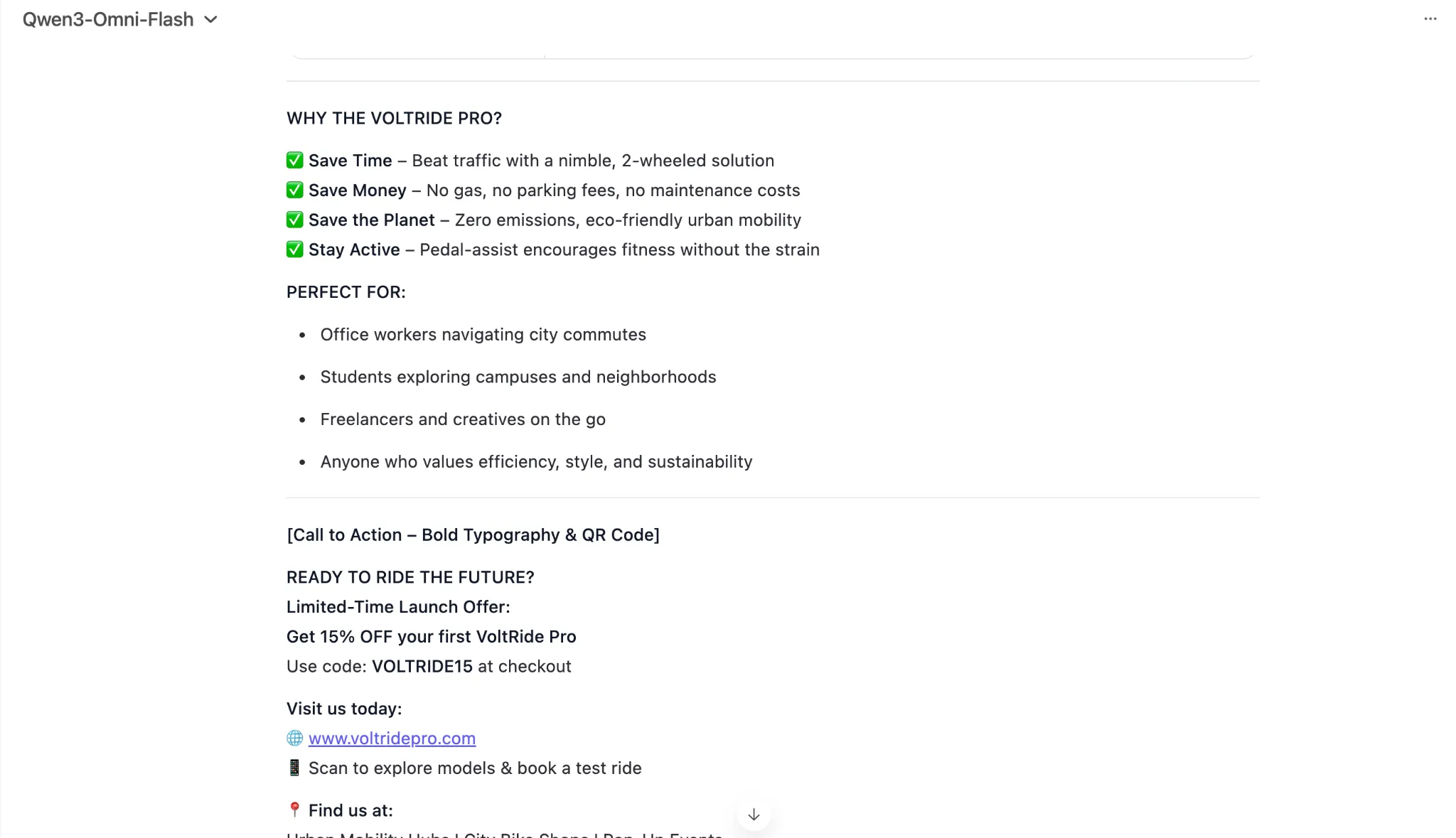
As you can see, the latest Qwen AI model was quite on-point with the task at hand, generating a near-perfect response in exactly the format one would envision for a product flier. 10 on 10 to Qwen3-Omni for text generation here.
2. Image Generation
Next comes the test for image generation. Also, to test its claimed omni-modal capability, I followed up to the earlier prompt with an image generation task.
Prompt:
can you create the front cover you mention in the product description above? Make it catchy, with vibrant colours, and show all three colour variations of the e-cycle stacked side by side
Output:

As you can see, the new Qwen3 model was able to produce a super-aesthetic image following the prompt to accuracy. A small detail it missed out on was the colour of one of the bikes, which was supposed to be Red, instead of Orange, as shown here. Yet, the overall output is quite pleasing, and it earns my recommendation for image generation.
A Big Note: To generate an image on Qwen3-Omni, even within the same chat window, you will have to click on the “Image Generation” option first. Without this, it will simply generate a prompt for the image, instead of an actual image. This beats the whole purpose of it being a seamless workflow within an “omni-modal”, as other tools like ChatGPT offer.
An even bigger flaw here: To go back from the image generation window to any other, you will have to start a New Chat all over again, losing all the context of your last chat. This basically means Qwen3-Omni lacks massively on a seamless workflow that an all-encompassing AI tool should follow.
3. Video Generation
Again, you will have to call the Video Generation tool in a chat window on the Qwen3-Omni, so as to make a video. Here is the prompt I used and the subsequent result I got.
Prompt:
generate an ad commercial of the electric bicycle we discussed earlier, showing a young boy zooming along city roads on the e-bike. Show a few text tags along the video, including “30Kms Range” to highlight the e-bikes features. Keep vibrant colours and make the overall theme very catchy for potential buyers
Output:
As you can see, the video is not very good, with a strange, unrealistic flow to it. The colours are washed out, there are no details within the video, and the AI model completely failed to induce text within the video accurately. So I wouldn’t really recommend it for video generation purposes to anyone.
4. Coding
To test the coding abilities of the new Qwen3 model, here is the prompt I used and the result it delivered.
Prompt:
please write a code for a 3-page website of the electric bicycle we have discussed in other chats. make sure to showcase the three colours in a carousel at the home page. keep one page for product specifications and the third one for how the e-bike is eco friendly and ideal for last mile commute
Output:
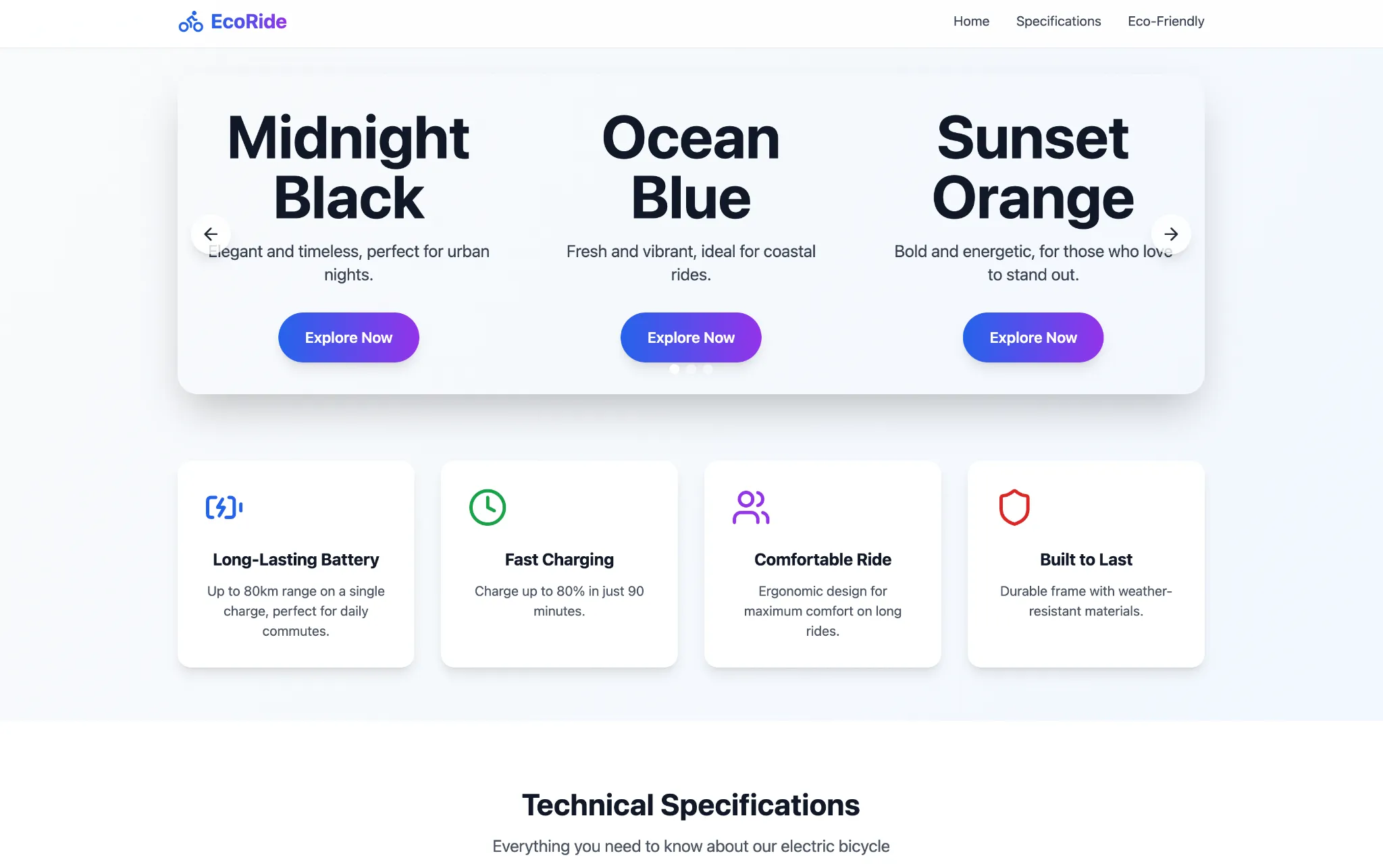
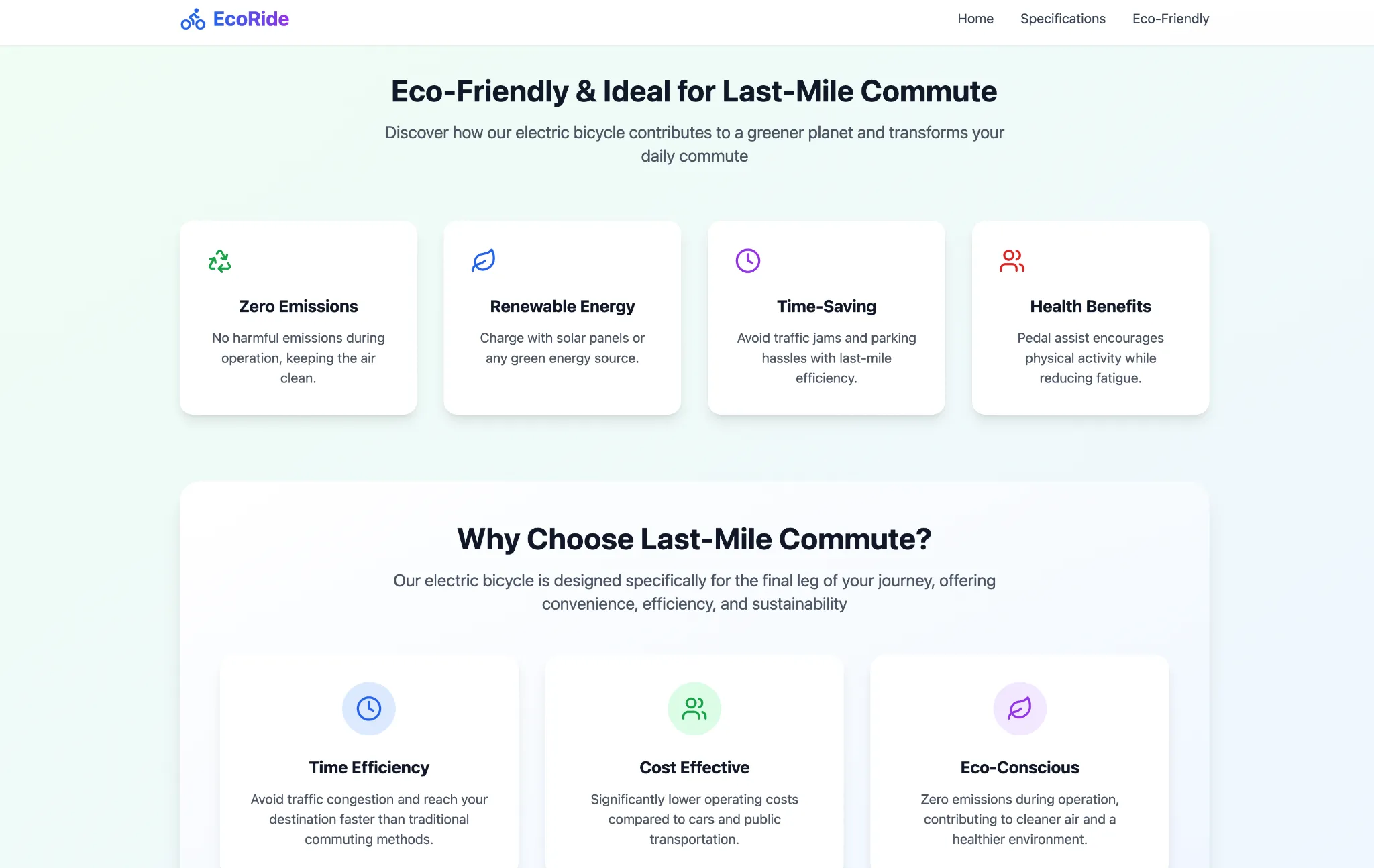
It seems to have done part of the work on the website, having created the asked-for pages yet nothing inside them. Though whatever it came up with, the Qwen3-Omni did a good job in terms of aesthetics and functionality of the website, which looks quite pleasing overall. Takeaway – you may wish to be highly specific with your prompts when using Qwen3-Omni for web development.
Conclusion
It is clear that Alibaba’s Qwen team has made one of the boldest steps yet in multimodal AI. From the Thinker–Talker architecture that enables real-time streaming speech, to the AuT audio encoder trained on 20 million hours of data, the model’s design clearly focuses on speed, versatility, and balance across modalities. Benchmark results back this up: the new Qwen3 model consistently outperforms rivals across tasks like MMLU, HumanEval, and LibriSpeech, showing it is not just an open-source release but a serious contender in the AI race.
That said, the hands-on experience shows a more nuanced picture. On core abilities like text and image generation, the new AI model delivers highly accurate, creative outputs, even if it occasionally misses fine details. But its biggest flaw is workflow: switching between text, image, and video modes requires starting fresh chats, breaking the “seamless omni-modal” promise. In other words, Qwen3-Omni is powerful and impressive, but not yet perfect. And there might be a while before it really achieves what it has set out for.






