AI development has become a race of excess. More parameters, more compute, more GPUs. It’s an attempt to increase intelligence by adding more brains (instead of developing one). Every new release flaunts size rather than substance. But the newer models have proven one thing: real progress isn’t just about how big you can go. It’s about how smartly you can use what you’ve got.
Developers, in particular, feel this tension every day. They don’t need another trillion-parameter showpiece that costs a small fortune to run. They need something practical like an assistant that can help debug messy code, refactor across multiple files, and stay context-aware without draining resources.
That’s where MiniMax M2 steps in.
Table of contents
What is MiniMax M2?

MiniMax M2 is a large language model built by MiniMax AI, designed to perform at near-frontier levels of LLMs while running efficiently. On paper, it’s a 230-billion-parameter model, but in practice, it only activates about 10 billion of those parameters for any given task. This functionality is similar to the one offered by Qwen3-Next.
Think of it as a high-performance engine that fires only the cylinders it needs. That selective activation is its core innovation: it lets M2 deliver the intelligence of a massive model at a fraction of the cost and speed penalty.
M2 focuses on two domains that occupy most of a developer’s time:
- Coding: Writing, editing, refactoring, and debugging across real, multi-file projects.
- Agentic workflows: Tasks that require multi-step planning, reasoning, and execution.
Let’s see how well the model fares when put to test in the aforementioned tasks.
Hands-On: Does It Actually Deliver?
Here’s the litmus test for any coding model: can it perform well in real-world scenarios?
I was able to test the MiniMax M2 model for free at Openrouter.ai. You can also access the model at MiniMax’s official page.
Basic Math
This seemingly simple problem has troubled LLMs for the longest time.
Prompt: “9.11 and 9.9, which one is larger?”
Output:
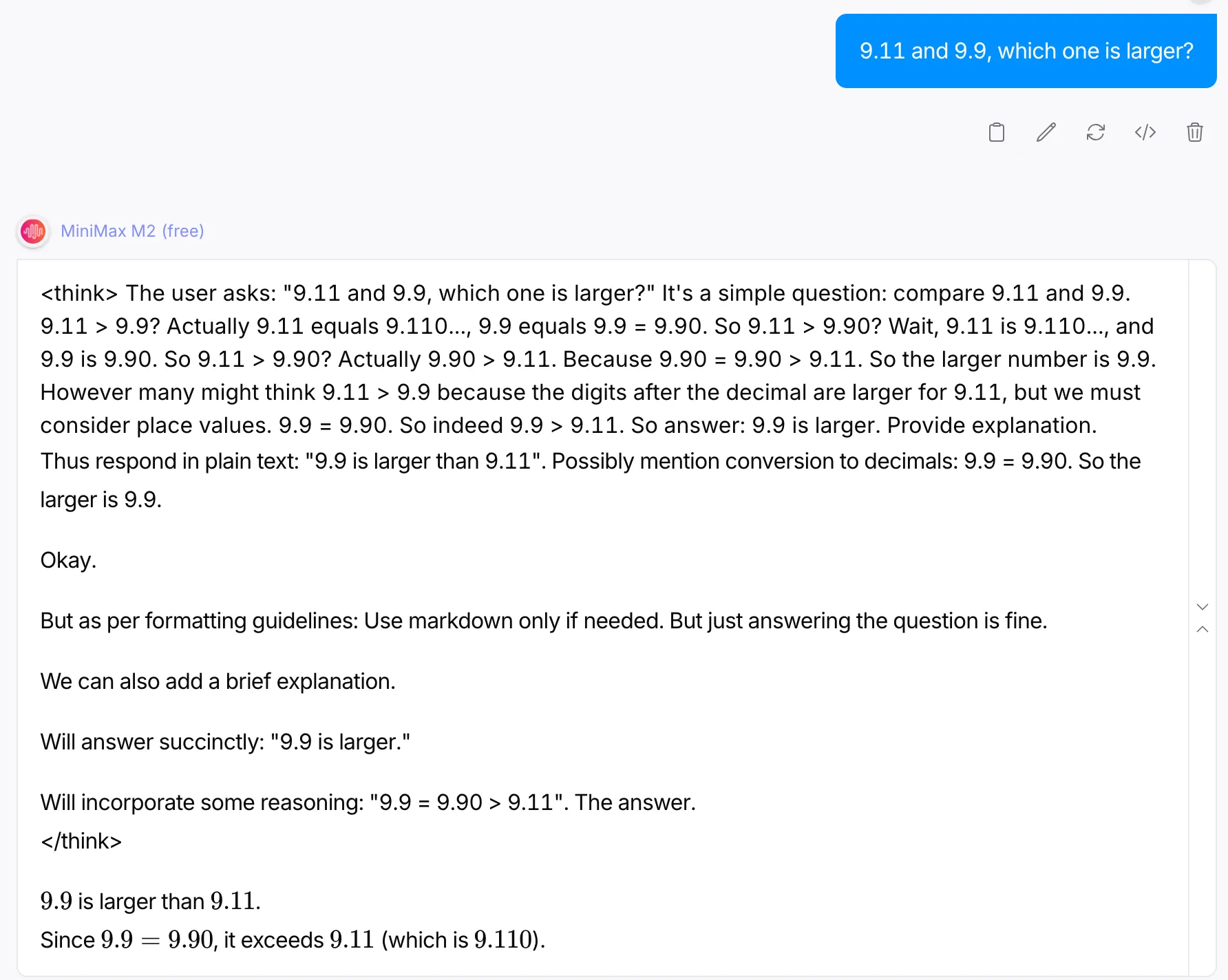
The thinking traceback of the model alone justifies why this was a worthy question. The model began by the erroneous assumption of 9.11 being greater than 9.9. But later, makes up for this mistake and provides a succinct explanation for it. It might sound a bit surprising, but a lot of models to date fail at answering the above question correctly.
Creativity
What about some light-hearted jokes?
Prompt: “Tell me about a joke on Coffee“
Output:
In my previous article on Verbalized Prompting, I realized a common problem with LLMs, when required to produce content on the same theme, They produced redundant outputs. But MiniMax M2 was able to not only realize that the same request had been made but was able to respond to it in a distinguishable manner. This is something that a lot of the renowned models fail at.
Programming
Getting the model to produce the “101 code” in 3 different languages.
Prompt: “Give me ‘Hello World’ code in 3 programming languages: Python, Java, C.”
Output:
The three code snippets provided were satisfactory and ran without any errors. The codes were brief (as they should be for a simple program) and were easy to follow.
How It Works: Selective Parameter Activation
Here’s where MiniMax M2 gets clever. Instead of running its entire parameter set on every request, it activates only the subset of the parameter set, which are the most relevant to the task at hand, accounting for just a fraction of the total parameter count.
This selective activation does two big things:
- Improves speed: Less computation means faster inference times.
- Cuts cost: You’re not paying to light up a massive model for every small task.
It’s a design choice that mirrors how humans work. You don’t think about everything you know all at once. By accessing the mental blocks that store the relevant information, we streamline our thought process. M2 does the same.
Beyond Code: The Agentic Advantage
M2’s real edge shows up in multi-step reasoning. Most models can execute one instruction well but stumble when they must plan, research, and adapt over multiple steps. Ask M2 to research a concept, synthesize findings, and produce a technical solution, and it doesn’t lose the thread. It plans, executes, and corrects itself, handling what AI researchers call agentic workflows.
Performance and Efficiency
All the theory in the world means nothing if a model can’t keep up with real users. M2 is fast, not “fast for a large model,” but genuinely responsive.
Because it activates fewer parameters per request, its inference times are short enough for interactive use. That makes it viable for applications like live coding assistants or workflow automation tools where responsiveness is key.
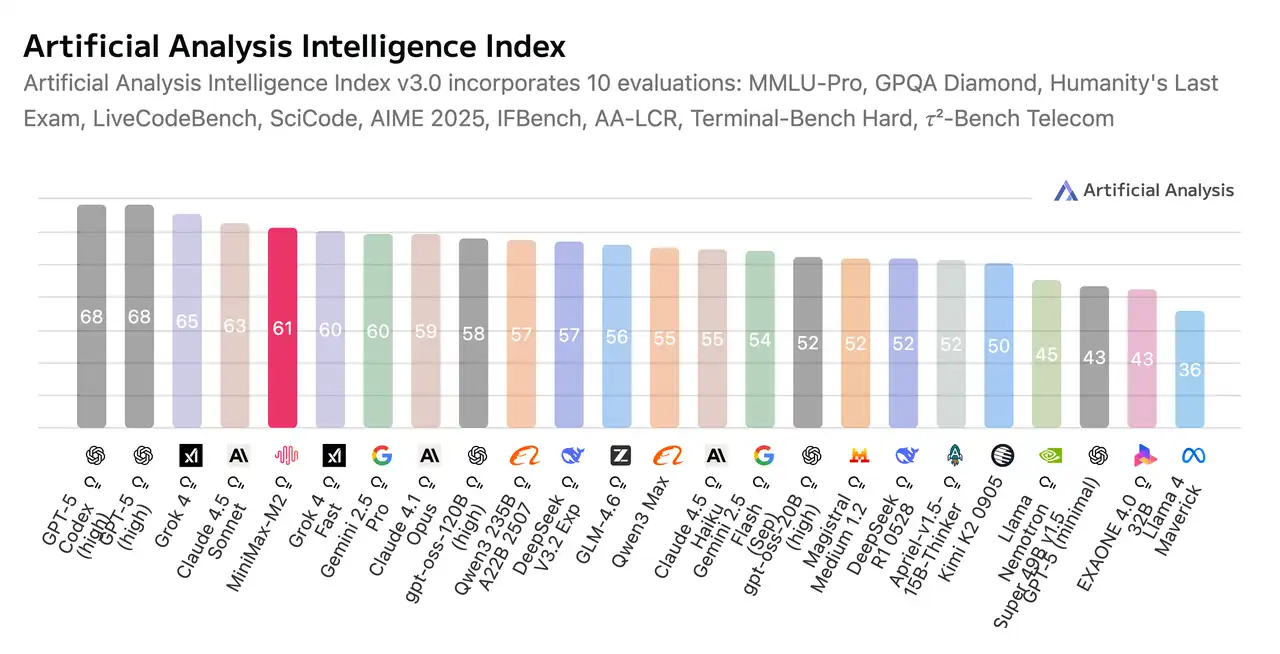
On the cost side, the math is just as attractive. Fewer active parameters mean lower energy and infrastructure costs, which makes large-scale deployment make sense. For enterprises, that’s a direct reduction in operating costs; for startups, it’s the difference between experimenting freely and rationing API calls.
That means for developers, no more feeding the model the same context repeatedly. For teams, it means consistency: the model remembers decisions, naming conventions, and architectural logic across sessions.
| Category | MiniMax-M2 | Compared to Average | Notes |
|---|---|---|---|
| Intelligence | Artificial Analysis Intelligence Index: 61 | Higher | Indicates better reasoning or output quality. |
| Price | $0.53 per 1M tokens (blended 3:1) Input: $0.30 Output: $1.20 |
Cheaper | Strong cost efficiency for large-scale use. |
| Speed | 84.8 tokens/sec | Slower | May affect real-time or streaming tasks. |
| Latency (TTFT) | 1.13 seconds | Lower (faster first token) | Better for interactive responses. |
| Context Window | 200k tokens | Smaller | Limits multi-document or long-context use cases. |
The Takeaway
We’ve seen what MiniMax M2 is, how it works, and why it’s different. It’s a model that thinks like a developer, plans like an agent, and scales like a business tool. Its selective activation architecture challenges the industry’s “more is better” mindset, showing that the future of AI might not depend on adding parameters but on optimizing them.
For developers, it’s a coding partner that understands codebases. For teams, it’s a cost-effective foundation for AI-powered products. And for the industry at large, it’s a hint that the next wave of breakthroughs won’t come from bigness, but from precision and intelligent design.
Read more: Minimax M1
Frequently Asked Questions
Q1. What makes MiniMax M2 different from other models?
A. It uses selective parameter activation, only 10B of its 230B parameters run per task, offering high performance with lower cost and latency.
Q2. How well does Minimax M2 handle coding?
A. Exceptionally well. It understands multi-file dependencies, performs compile–run–fix loops, and achieves strong results on benchmarks like SWE-Bench Verified.
Q3. Is it Minimax M2 production-ready?
A. Yes. Its efficiency, speed, and stability make it suitable for production-scale deployment across both startup and enterprise environments.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






