The evolution of artificial intelligence from stateless models to autonomous, goal-driven agents depends heavily on advanced memory architectures. While Large Language Models (LLMs) possess strong reasoning abilities and vast embedded knowledge, they lack persistent memory, making them unable to retain past interactions or adapt over time. This limitation leads to repeated context injection, increasing token usage, latency, and reducing efficiency. To address this, modern agentic AI systems incorporate structured memory frameworks inspired by human cognition, enabling them to maintain context, learn from interactions, and operate effectively across multi-step, long-term tasks.
Robust memory design is critical for ensuring reliability in these systems. Without it, agents face issues like memory drift, context degradation, and hallucinations, especially in long interactions where attention weakens over time. To overcome these challenges, researchers have developed multi-layered memory models, including short-term working memory and long-term episodic, semantic, and procedural memory. Additionally, effective memory management techniques—such as semantic consolidation, intelligent forgetting, and conflict resolution—are essential. The analysis also compares leading frameworks like LangMem, Mem0, and Zep, highlighting their role in enabling scalable, stateful AI systems for real-world applications.
Table of contents
- The Architectural Imperative: Operating System Analogies and Frameworks
- Short-Term Memory: The Working Context Window
- Long-Term Memory: The Tripartite Cognitive Model
- Advanced Memory Management and Consolidation Strategies
- Algorithmic Strategies for Resolving Memory Conflicts
- Comparative Analysis of Enterprise Memory Frameworks: Mem0, Zep, and LangMem
- Mem0: The Universal Personalization and Compression Layer
- Architectural Focus and Capabilities
- Conflict Resolution and Management
- Deployment and Use Cases
- Zep: Temporal Knowledge Graphs for High-Performance Relational Retrieval
- LangMem: Native Developer Integration for Procedural Learning
- Architectural Focus and Capabilities
- Conflict Resolution and Management
- Deployment and Use Cases
- Enterprise Framework Benchmark Synthesis
- Conclusion
The Architectural Imperative: Operating System Analogies and Frameworks
Modern AI agents treat the LLM as more than a text generator. They use it as the brain of a larger system, much like a CPU. Frameworks like CoALA separate the agent’s thinking process from its memory, treating memory as a structured system rather than just raw text. This means the agent actively retrieves, updates, and uses information instead of passively relying on past conversations.
Building on this, systems like MemGPT introduce a memory hierarchy similar to computers. The model uses a limited “working memory” (context window) and shifts less important information to external storage, bringing it back only when needed. This allows agents to handle long-term tasks without exceeding token limits. To stay efficient and accurate, agents also compress information—keeping only what’s relevant—just like humans focus on key details and ignore noise, reducing errors like memory drift and hallucinations.
Short-Term Memory: The Working Context Window
Short-term memory in AI agents works like human working memory—it temporarily holds the most recent and relevant information needed for immediate tasks. This includes recent conversation history, system prompts, tool outputs, and reasoning steps, all stored within the model’s limited context window. Because this space has strict token limits, systems typically use FIFO (First-In-First-Out) queues to remove older information as new data arrives. This keeps the model within its capacity.
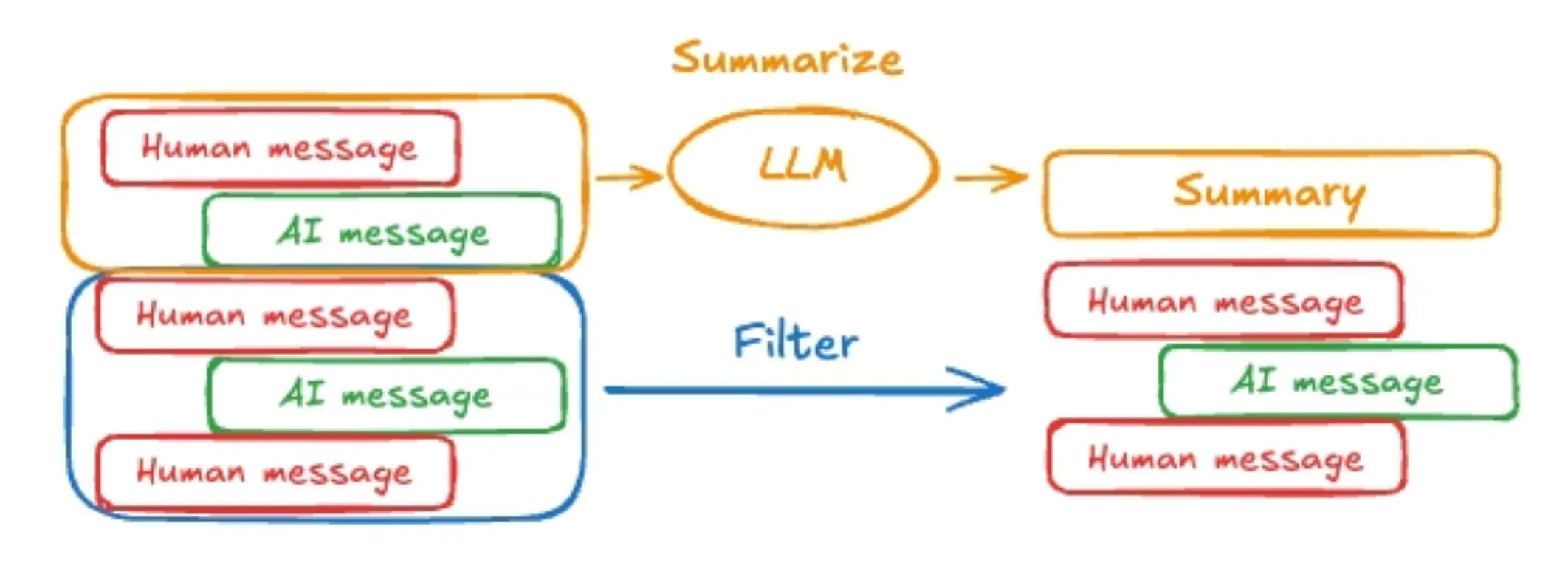
However, simple FIFO removal can discard important information, so advanced systems use smarter memory management. These systems monitor token usage and, when limits are close, prompt the model to summarize and store key details in long-term memory or external storage. This keeps the working memory focused and efficient. Additionally, attention mechanisms help the model prioritize relevant information, while metadata like session IDs, timestamps, and user roles ensure proper context, security, and response behavior.
Long-Term Memory: The Tripartite Cognitive Model
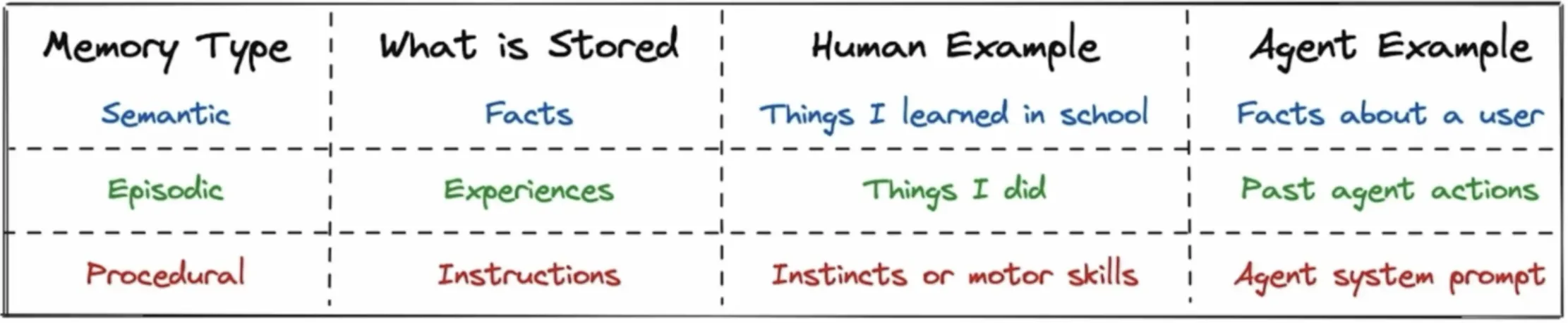
Long-term memory acts as the enduring, persistent repository for knowledge accumulated over the agent’s lifecycle, surviving well beyond the termination of individual computing sessions or chat interactions. The migration of data from a short-term working context to long-term storage represents a fundamental cognitive compression step that isolates valuable signal from conversational noise. To create human-like continuity and more sophisticated intelligence, systems divide long-term storage into three distinct operational modes: episodic, semantic, and procedural memory. Each modality requires fundamentally different data structures, storage mechanisms, and retrieval algorithms.
To better understand the structural requirements of these memory types, we must observe how data patterns dictate database architecture choices. The following table illustrates the required storage and query mechanics for each memory type, highlighting why monolithic storage approaches often fail.
| Memory Type | Primary Data Pattern | Query / Retrieval Mechanics | Optimal Database Implementation |
|---|---|---|---|
| Episodic | Time-series events and raw transcripts | Temporal range queries, chronological filtering | Relational databases with automatic partitioning (e.g., Hypertables) |
| Semantic | High-dimensional vector embeddings | K-nearest neighbor search, cosine similarity | Vector databases (pgvector, Pinecone, Milvus) |
| Procedural | Relational logic, code blocks, state rules | CRUD operations with complex joins, exact ID lookups | Standard relational or Key-Value storage (e.g., PostgreSQL) |
A multi-database approach—using separate systems for each memory type—forces serial round-trip across network boundaries, adding significant latency and multiplying operational complexity. Consequently, advanced implementations attempt to consolidate these patterns into unified, production-grade databases capable of handling hybrid vector-relational workloads.
Episodic Memory: Events and Sequential Experiences
Episodic memory in AI agents stores detailed, time-based records of past interactions, similar to how humans remember specific events. It typically consists of conversation logs, tool usage, and environmental changes, all saved with timestamps and metadata. This allows agents to maintain continuity across sessions—for example, recalling a previous customer support issue and referencing it naturally in future interactions. Inspired by human biology, these systems also use techniques like “experience replay.” They revisit past events to improve learning and make better decisions in new situations.
However, relying only on episodic memory has limitations. While it can accurately retrieve past interactions, it does not inherently understand patterns or extract deeper meaning. For instance, if a user repeatedly mentions a preference, episodic memory will only return separate instances rather than recognizing a consistent interest. This means the agent must still process and infer patterns during each interaction, making it less efficient and preventing true knowledge generalization.
Semantic Memory: Distilled Facts and Knowledge Representation
Semantic memory stores generalized knowledge, facts, and rules, going beyond specific events to capture meaningful insights. Unlike episodic memory, which records individual interactions, semantic memory extracts and preserves key information—such as turning a past interaction about a peanut allergy into a permanent fact like “User Allergy: Peanuts.” AI systems typically implement this with knowledge bases, symbolic representations, and vector databases. They often integrate these with Retrieval-Augmented Generation (RAG) to provide domain-specific expertise without retraining the model.
A crucial part of building intelligent agents is converting episodic memory into semantic memory. This process involves identifying patterns across past interactions and distilling them into reusable knowledge. Inspired by human cognition, this “memory consolidation” ensures agents can generalize, reduce redundancy, and improve efficiency over time. Without this step, agents remain limited to recalling past events rather than truly learning from them.
Procedural Memory: Operational Skills and Dynamic Execution
Procedural memory in AI agents represents “knowing how” to perform tasks, focusing on execution rather than facts or past events. It governs how agents carry out workflows, use tools, coordinate sub-agents, and make decisions. This type of memory exists in two forms: implicit (learned within the model during training) and explicit (defined through code, prompts, and workflows). As agents gain experience, frequently used processes become more efficient, reducing computation and speeding up responses—for example, a travel agent knowing the exact steps to search, compare, and book flights across systems.
Modern advancements are making procedural memory dynamic and learnable. Instead of relying on fixed, manually designed workflows, agents can now refine their behavior over time using feedback from past tasks. This allows them to update their decision-making strategies, fix errors, and improve execution continuously. Frameworks like AutoGen, CrewAI, and LangMem support this by enabling structured interactions, role-based memory, and automatic prompt optimization, helping agents evolve from rigid executors into adaptive, self-improving systems.
Advanced Memory Management and Consolidation Strategies
The naive approach to agent memory management—simply appending every new conversation turn into a vector database—inevitably leads to catastrophic systemic failure. As the data corpus grows over weeks or months of deployment, agents experience debilitating retrieval noise, severe context dilution, and latency spikes as they attempt to parse massive arrays of slightly relevant vectors. Effective long-term functionality requires highly sophisticated orchestration to govern how the system consolidates, scores, stores, and eventually discards memories.
Asynchronous Semantic Consolidation
Attempting to extract complex beliefs, summarize overarching concepts, and dynamically update procedural rules during an active, user-facing session introduces unacceptable latency overhead. To mitigate this, enterprise-grade architectures uniformly rely on asynchronous, background consolidation paradigms.
During the active interaction (commonly referred to as “the hot path”), the agent leverages its existing context window to respond in real-time, functioning solely on read-access to long-term memory and write-access to its short-term session cache. This guarantees zero-latency conversational responses. Once the session terminates, a background cognitive compression process is initiated. This background process—often orchestrated by a smaller, highly efficient local model (such as Qwen2.5 1.5B) to save compute costs—scans the raw episodic history of the completed session. It extracts structured facts, maps new entity relationships, resolves internal contradictions against existing data, and securely writes the distilled knowledge to the semantic vector database or knowledge graph.
This tiered architectural approach naturally categorizes data by its operational temperature:
- Hot Memory: The immediate, full conversational context held within the prompt window, providing high-fidelity, zero-latency grounding for the active task.
- Warm Memory: Structured facts, refined preferences, and semantic nodes asynchronously extracted into a high-speed database, serving as the primary source of truth for RAG pipelines.
- Cold Archive: Highly compressed, serialized logs of old sessions. These are removed from active retrieval pipelines and retained purely for regulatory compliance, deep system debugging, or periodic batched distillation processes.
By ensuring the main reasoning model never sees the raw, uncompressed history, the agent operates entirely on high-signal, distilled knowledge.
Intelligent Forgetting and Memory Decay
A foundational, yet deeply flawed, assumption in early AI memory design was the necessity of perfect, infinite retention. However, infinite retention is an architectural bug, not a feature. Imagine a customer support agent deployed for six months; if it perfectly remembers every minor typo correction, every casual greeting, and every deeply obsolete user preference, the retrieval mechanism rapidly becomes polluted. A search for the user’s current project might return fifty results, and half of them could be badly outdated. That creates direct contradictions and compounds hallucinations.
Biological cognitive efficiency relies heavily on the mechanism of selective forgetting, allowing the human brain to maintain focus on relevant data while shedding the trivial. Applied to artificial intelligence, the “intelligent forgetting” mechanism dictates that not all memories possess equal permanence. Utilizing mathematical principles derived from the Ebbinghaus Forgetting Curve—which established that biological memories decay exponentially unless actively reinforced—advanced memory systems assign a continuous decay rate to stored vectors.
Algorithms Powering Intelligent Forgetting
The implementation of intelligent forgetting leverages several distinct algorithmic strategies:
- Time-to-Live (TTL) Tiers and Expiration Dates: The system tags each memory with an expiration date as soon as it creates it, based on that memory’s semantic category. It assigns immutable facts, such as severe dietary allergies, an infinite TTL, so they never decay. It gives transient contextual notes, such as syntax questions tied to a temporary project, a much shorter lifespan—often 7 or 30 days. After that date passes, the system aggressively removes the memory from search indices to prevent it from conflicting with newer information.
- Refresh-on-Read Mechanics: To mimic the biological spacing effect, the system boosts a memory’s relevance score whenever an agent successfully retrieves and uses it in a generation task. It also fully resets that memory’s decay timer. As a result, frequently used information stays preserved, while contradictory or outdated facts eventually fall below the minimum retrieval threshold and get pruned systematically.
- Importance Scoring and Dual-Layer Architectures: During the consolidation phase, LLMs assign an importance score to incoming information based on perceived long-term value. Frameworks like FadeMem categorize memories into two distinct layers. The Long-term Memory Layer (LML) houses high-importance strategic directives that decay incredibly slowly. The Short-term Memory Layer (SML) holds lower-importance, one-off interactions that fade rapidly.
Furthermore, formal forgetting policies, such as the Memory-Aware Retention Schema (MaRS), deploy Priority Decay algorithms and Least Recently Used (LRU) eviction protocols to automatically prune storage bloat without requiring manual developer intervention. Engine-native primitives, such as those found in MuninnDB, handle this decay at the database engine level, continuously recalculating vector relevance in the background so the agent always queries an optimized dataset. By transforming memory from an append-only ledger to an organic, decay-aware ecosystem, agents retain high-signal semantic maps while effortlessly shedding obsolete noise.
Algorithmic Strategies for Resolving Memory Conflicts
Even with aggressive intelligent forgetting and TTL pruning, dynamic operational environments guarantee that new facts will eventually contradict older, persistent memories. A user who explicitly reported being a “beginner” in January may be operating as a “senior developer” by November. If both data points reside permanently in the agent’s semantic memory, a standard vector search will indiscriminately retrieve both, leaving the LLM trapped between conflicting requirements and vulnerable to severe drift traps. Addressing memory drift and contradictory context requires multi-layered, proactive conflict resolution strategies.
Algorithmic Recalibration and Temporal Weighting
Standard vector retrieval ranks information strictly by semantic similarity (e.g., cosine distance). Consequently, a highly outdated fact that perfectly matches the phrasing of a user’s current prompt will inherently outrank a newer, slightly rephrased fact. To resolve this structural flaw, advanced memory databases implement composite scoring functions that mathematically balance semantic relevance against temporal recency.
When evaluating a query, the retrieval system ranks candidate vectors using both their similarity score and an exponential time-decay penalty. Thus, the system enforces strict hypothesis updates without physically rewriting prior historical facts, heavily biasing the final retrieval pipeline toward the most recent state of truth. This ensures that while the old memory still exists for historical auditing, it is mathematically suppressed during active agent reasoning.
Semantic Conflict Merging and Arbitration
Mechanical metadata resolution—relying solely on timestamps and recency weights—is often insufficient for resolving highly nuanced, context-dependent contradictions. Advanced cognitive systems utilize semantic merging protocols during the background consolidation phase to enforce internal consistency.
Instead of mechanically overwriting old data, the system deploys specialized arbiter agents to review conflicting database entries. These arbiters utilize the LLM’s natural strength in understanding nuance to analyze the underlying intent and meaning of the contradiction. If the system detects a conflict—for example, a database contains both “User prefers React” and “User is building entirely in Vue”—the arbiter LLM decides whether the new statement is a duplicate, a refinement, or a complete operational pivot.
If the system identifies the change as a pivot, it does not simply delete the old memory. Instead, it compresses that memory into a temporal reflection summary. The arbiter generates a coherent, time-bound reconciliation (e.g., “User utilized React until November 2025, but has since transitioned their primary stack to Vue”). This approach explicitly preserves the historical evolution of the user’s preferences while strictly defining the current active baseline, preventing the active response generator from suffering goal deviation or falling into drift traps.
Governance and Access Controls in Multi-Agent Systems
In complex multi-agent architectures, such as those built on CrewAI or AutoGen, simultaneous read and write operations across a shared database dramatically worsen memory conflicts. To prevent race conditions, circular dependencies, and cross-agent contamination, systems must implement strict shared-memory access controls.
Inspired by traditional database isolation levels, robust multi-agent frameworks define explicit read and write boundaries to create a defense-in-depth architecture. For example, within an automated customer service swarm, a “retrieval agent” logs the raw data of the user’s subscription tier. A separate “sentiment analyzer agent” holds permissions to read that tier data but is strictly prohibited from modifying it. Finally, the “response generator agent” only possesses write-access for drafted replies, and cannot alter the underlying semantic user profile. By enforcing these strict ontological boundaries, the system prevents agents from using outdated information that could lead to inconsistent decisions. It also flags coordination breakdowns in real time before they affect the user experience.
Comparative Analysis of Enterprise Memory Frameworks: Mem0, Zep, and LangMem
These theoretical paradigms—cognitive compression, intelligent forgetting, temporal retrieval, and procedural learning—have moved beyond academia. Companies are now actively turning them into real products. As industry development shifts away from basic RAG implementations toward complex, autonomous agentic systems, a diverse and highly competitive ecosystem of managed memory frameworks has emerged.
The decision to adopt an external memory framework hinges entirely on operational scale and application intent. Before you evaluate frameworks, you need to make one fundamental engineering assessment. If agents handle stateless, single-session tasks with no expected carryover, they do not need a memory overlay. Adding one only increases latency and architectural complexity. Conversely, if an agent operates repeatedly over related tasks, interacts with persistent entities (users, vendors, repositories), requires behavioral adaptation based on human corrections, or suffers from exorbitant token costs due to continuous context re-injection, a dedicated memory infrastructure is mandatory.
The following comparative analysis evaluates three prominent systems—Mem0, Zep, and LangMem—assessing their architectural philosophies, technical capabilities, performance metrics, and optimal deployment environments.
Mem0: The Universal Personalization and Compression Layer

Mem0 has established itself as a highly mature, heavily adopted managed memory platform designed fundamentally around deep user personalization and institutional cost-efficiency. It operates as a universal abstraction layer across various LLM providers, offering both an open-source (Apache 2.0) self-hosted variant and a fully managed enterprise cloud service.
Architectural Focus and Capabilities
Mem0’s primary value proposition lies in its sophisticated Memory Compression Engine. Rather than storing bloated raw episodic logs, Mem0 aggressively compresses chat histories into highly optimized, high-density memory representations. This compression drastically reduces the payload required for context re-injection, achieving up to an 80% reduction in prompt tokens. In high-volume consumer applications, this translates directly to massive API cost savings and heavily reduced response latency. Benchmark evaluations, such as ECAI-accepted contributions, indicate Mem0 achieves 26% higher response quality than native OpenAI memory while utilizing 90% fewer tokens.
At the base Free and Starter tiers, Mem0 relies on highly efficient vector-based semantic search. However, its Pro and Enterprise tiers activate an underlying knowledge graph, enabling the system to map complex entities and their chronological relationships across distinct conversations. The platform manages data across a strict hierarchy of workspaces, projects, and users, allowing for rigorous isolation of context, though this can introduce unnecessary complexity for simpler, single-tenant projects.
Conflict Resolution and Management
Mem0 natively integrates robust Time-To-Live (TTL) functionality and expiration dates directly into its storage API. Developers can assign specific lifespans to distinct memory blocks at inception, allowing the system to automatically prune stale data, mitigate context drift, and prevent memory bloat over long deployments.
Deployment and Use Cases
With out-of-the-box SOC 2 and HIPAA compliance, Bring Your Own Key (BYOK) architecture, and support for air-gapped or Kubernetes on-premise deployments, Mem0 targets large-scale, high-security enterprise environments. It is particularly effective for customer support automation, persistent sales CRM agents managing long sales cycles, and personalized healthcare companions where secure, highly accurate, and long-term user tracking is paramount. Mem0 also uniquely features a Model Context Protocol (MCP) server, allowing for universal integration across almost any modern AI framework. It remains the safest, most feature-rich option for compliance-heavy, personalization-first applications.
Zep: Temporal Knowledge Graphs for High-Performance Relational Retrieval

If Mem0 focuses on token compression and secure personalization, Zep focuses on high-performance, complex relational mapping, and sub-second latency. Zep diverges radically from traditional flat vector stores by employing a native Temporal Knowledge Graph architecture, positioning itself as the premier solution for applications requiring deep, ontological reasoning across vast timeframes.
Architectural Focus and Capabilities
Zep operates via a highly opinionated, dual-layer memory API abstraction. The API explicitly distinguishes between short-term conversational buffers (typically the last 4 to 6 raw messages of a session) and long-term context derived directly from an autonomously built, user-level knowledge graph. As interactions unfold, Zep’s powerful background ingestion engine asynchronously parses episodes, extracting entity nodes and relational edges, executing bulk episode ingest operations without blocking the main conversational thread.
Zep uses an exceptionally sophisticated retrieval engine. It combines hybrid vector and graph search with multiple algorithmic rerankers. When an agent requires context, Zep evaluates the immediate short-term memory against the knowledge graph, and rather than returning raw vectors, it returns a highly formatted, auto-generated, prompt-ready context block. Furthermore, Zep implements granular “Fact Ratings,” allowing developers to filter out low-confidence or highly ambiguous nodes during the retrieval phase, ensuring that only high-signal data influences the agent’s prompt.
Conflict Resolution and Management
Zep addresses memory conflict through explicit temporal mapping. Because the graph plots every fact, node, and edge chronologically, arbiter queries can trace how a user’s state evolves over time. This lets the system distinguish naturally between an old preference and a new operational pivot. Zep also allows for custom “Group Graphs,” a powerful feature enabling shared memory and context synchronization across multiple users or business units—a capability often absent in simpler, strictly user-siloed personalization layers.
Deployment and Use Cases
Zep excels in latency-sensitive, compute-heavy production environments. Its retrieval pipelines are heavily optimized, boasting average query latencies of under 50 milliseconds. For specialized applications like voice AI assistants, Zep provides a return_context argument in its memory addition method; this allows the system to return an updated context string immediately upon data ingestion, eliminating the need for a separate retrieval round-trip and further slashing latency. While its initial setup is more complex and entirely dependent on its proprietary Graphiti engine, Zep provides unmatched capabilities for high-performance conversational AI and ontology-driven reasoning.
LangMem: Native Developer Integration for Procedural Learning

LangMem represents a distinctly different philosophical approach compared to Mem0 and Zep. LangChain developed LangMem as an open-source, MIT-licensed SDK for deep native integration within the LangGraph ecosystem. It does not function as an external standalone database service or a managed cloud platform.
Architectural Focus and Capabilities
LangMem entirely eschews heavy external infrastructure and proprietary graphs, utilizing a highly flexible, flat key-value and vector architecture backed seamlessly by LangGraph’s native long-term memory store. Its primary objective sets it apart from the others. It aims not just to track static user facts or relationships, but to improve the agent’s dynamic procedural behavior over time.
LangMem provides core functional primitives that allow agents to actively manage their own memory “in the hot path” using standard tool calls. More importantly, it is deeply focused on automated prompt refinement and continuous instruction learning. Through built-in optimization loops, LangMem continuously evaluates interaction histories to extract procedural lessons, automatically updating the agent’s core instructions and operational heuristics to prevent repeated errors across subsequent sessions. This capability is highly unique among the compared tools, directly addressing the evolution of procedural memory without requiring continuous manual intervention by human prompt engineers.
Conflict Resolution and Management
Because LangMem offers raw, developer-centric tooling instead of an opinionated managed service, the system architect usually defines the conflict-resolution logic. However, it natively supports background memory managers that automatically extract and consolidate knowledge offline, shifting the heavy computational burden of summarization away from active user interactions.
Deployment and Use Cases
LangMem is the definitive, developer-first choice for engineering teams already heavily invested in LangGraph architectures who demand total sovereignty over their infrastructure and data pipelines. It is ideal for orchestrating multi-agent workflows and complex swarms where procedural learning and systemic behavior adaptation are much higher priorities than out-of-the-box user personalization. While it demands significantly more engineering effort to configure custom extraction pipelines and manage the underlying vector databases manually, it entirely eliminates third-party platform lock-in and ongoing subscription costs.
Enterprise Framework Benchmark Synthesis
The following table synthesizes the core technical attributes, architectural paradigms, and runtime performance metrics of the analyzed frameworks, establishing a rigorous baseline for architectural decision-making.
| Framework Capability | Mem0 | Zep | LangMem |
|---|---|---|---|
| Primary Architecture | Vector + Knowledge Graph (Pro Tier) | Temporal Knowledge Graph | Flat Key-Value + Vector store |
| Target Paradigm | Context Token Compression & Personalization | High-Speed Relational & Temporal Context Mapping | Procedural Learning & Multi-Agent Swarm Orchestration |
| Average Retrieval Latency | 50ms – 200ms | < 50ms (Highly optimized for voice) | Variable (Entirely dependent on self-hosted DB tuning) |
| Graph Operations | Add/Delete constraints, Basic Cypher Filters | Full Node/Edge CRUD, Bulk episode ingest | N/A (Relies on external DB logic) |
| Procedural Updates | Implicit via prompt context updates | Implicit via high-confidence fact injection | Explicit via automated instruction/prompt optimization loops |
| Security & Compliance | SOC 2, HIPAA, BYOK natively supported | Production-grade group graphs and access controls | N/A (Self-Managed Infrastructure security applies) |
| Optimal Ecosystem | Universal (MCP Server, Python/JS SDKs, Vercel) | Universal (API, LlamaIndex, LangChain, AutoGen) | Strictly confined to LangGraph / LangChain environments |
The comparative data underscores a critical reality in AI engineering: there is no monolithic, universally superior solution for AI agent memory. Simple LangChain buffer memory suits early-stage MVPs and prototypes operating on 0-3 month timelines. Mem0 provides the most secure, feature-rich path for products requiring robust personalization and severe token-cost reduction with minimal infrastructural overhead. Zep serves enterprise environments where extreme sub-second retrieval speeds and complex ontological awareness justify the inherent complexity of managing graph databases. Finally, LangMem serves as the foundational, open-source toolkit for engineers prioritizing procedural autonomy and strict architectural sovereignty.
Conclusion
The shift from simple AI systems to autonomous, goal-driven agents depends on advanced memory architectures. Instead of relying only on limited context windows, modern agents use multi-layered memory systems—episodic (past events), semantic (facts), and procedural (skills)—to function more like human intelligence. The key challenge today is not storage capacity, but effectively managing and organizing this memory. Systems must move beyond simply storing data (“append-only”) and instead focus on intelligently consolidating and structuring information to avoid noise, inefficiency, and slow performance.
Modern architectures achieve this by using background processes that convert raw experiences into meaningful knowledge. They also continuously refine how they execute tasks. At the same time, intelligent forgetting mechanisms—like decay functions and time-based expiration—help remove irrelevant information and prevent inconsistencies. Enterprise tools such as Mem0, Zep, and LangMem tackle these challenges in different ways. Each tool focuses on a different strength: cost efficiency, deeper reasoning, or adaptability. As these systems evolve, AI agents are becoming more reliable, context-aware, and capable of long-term collaboration rather than just short-term interactions.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.






