A year or two ago, using advanced AI models felt expensive enough that you had to think twice before asking anything. Today, using those same models feels cheap enough that you don’t even notice the cost.
This isn’t just because “technology improved” in a vague sense. There are specific reasons behind it, and it comes down to how AI systems spend computation. That’s what people mean when they talk about token economics.
Table of contents
Tokens: The Fundamental Unit
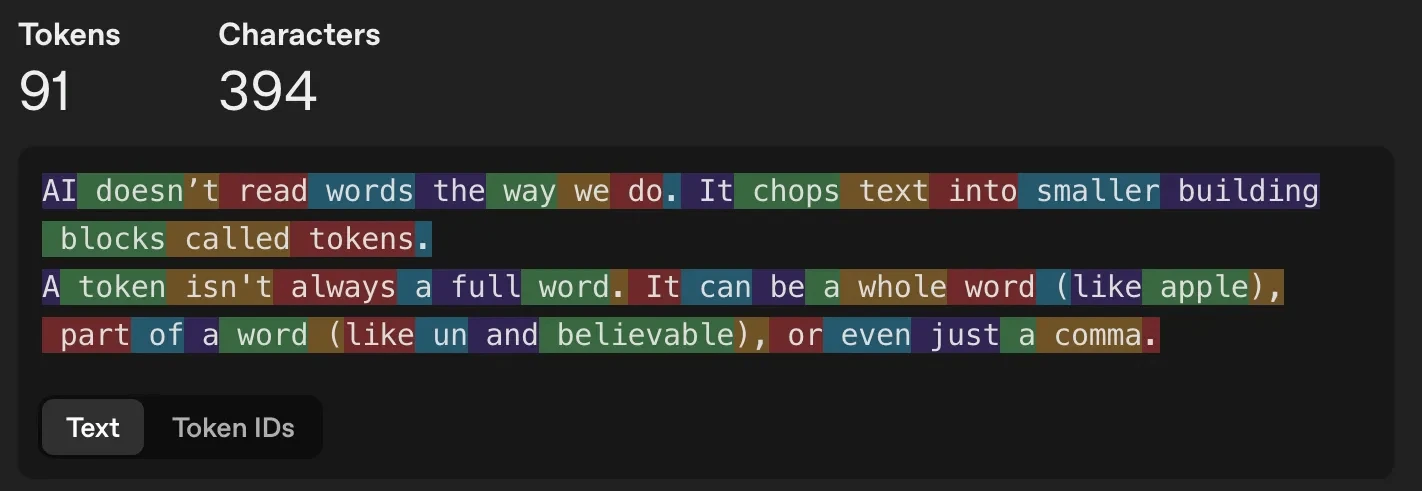
AI doesn’t read words the way we do. It chops text into smaller building blocks called tokens.
A token isn’t always a full word. It can be a whole word (like apple), part of a word (like un and believable), or even just a comma.
Each token generated requires a certain amount of computation. So if you zoom out, the cost of using AI comes down to a simple relationship:
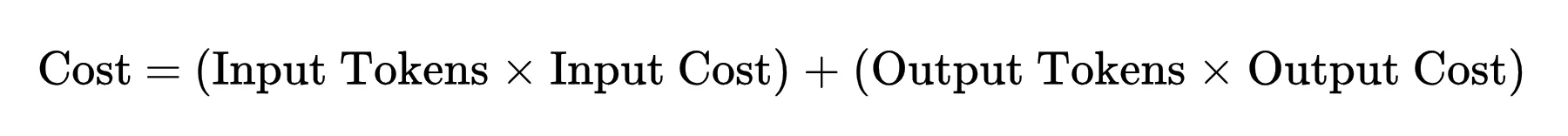
Since AI token costs are per million tokens, the equation evaluates to:
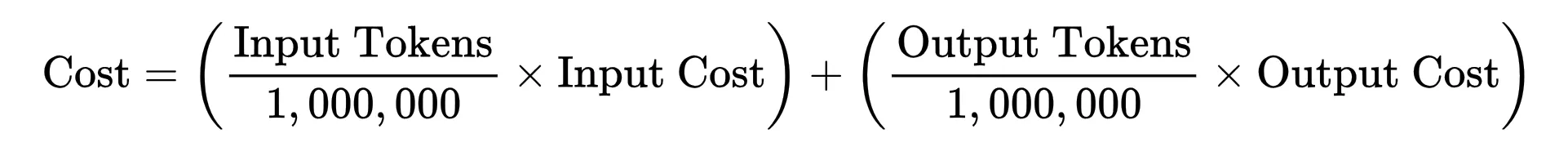
Click here to see how the cost is calculated for a model
We’d be doing the math on Gemini 3.1 Pro Preview.
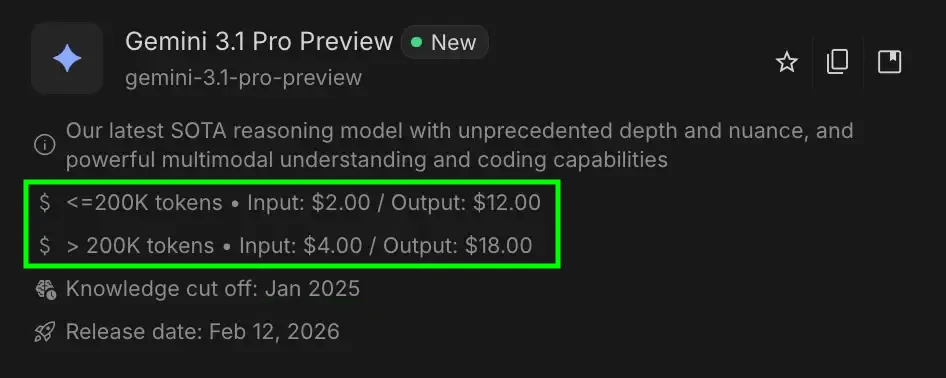
Let’s say you send a prompt that is 50,000 tokens (Input Tokens) and the AI writes back 2,000 tokens (Output Tokens).
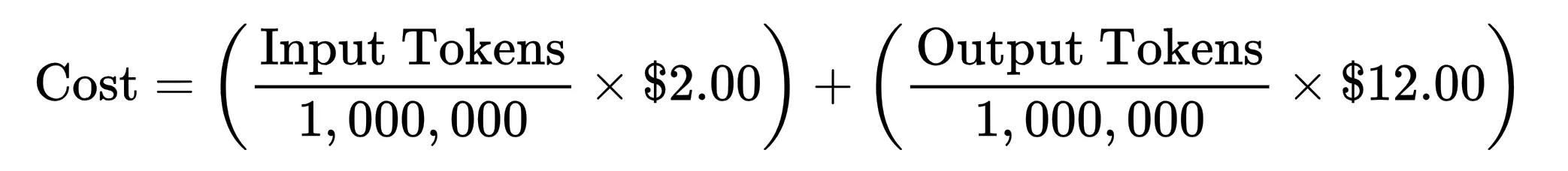
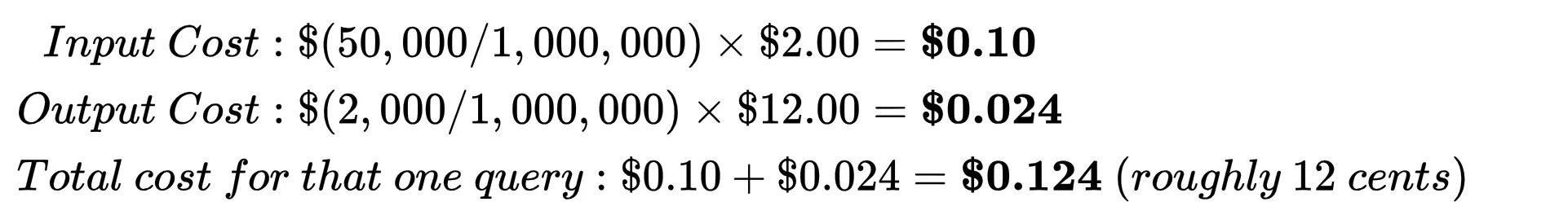
Since tokens are the currency of AI. If you control tokens, you control costs.
If AI is getting cheaper, it means we’re doing one of two things:
- Reducing how much compute each token needs (Input/Output tokens)
- Making that compute cheaper (Token price)
In reality, we did both!
Using less compute per token
The first wave of improvements came from a simple realization:
We were using more computation than necessary.
Early models treated every request the same way. Small or large query, text or image inputs, run the full model at full precision every time. That works, but it’s wasteful.
So the question became: where can we cut compute without hurting output quality?
Quantization: Making each operation lighter
The most direct improvement came from quantization. Models originally used high-precision numbers for calculations. But it turns out you can reduce that precision significantly without degrading performance in most cases.
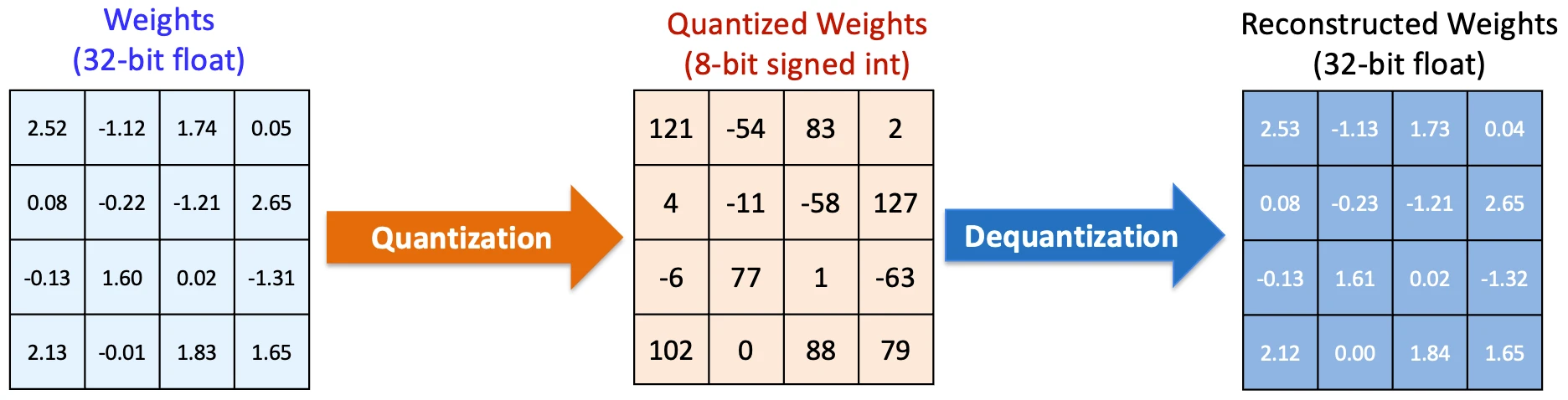
This effect compounds quickly. Every token passes through thousands of such operations, so even a small reduction per operation leads to a meaningful drop in cost per token.
Note: Full-precision quantization constants (a scale and a zero point) must be stored for every block. This storage is essential so the AI can later de-quantize the data.
MoE Architecture: Not using the whole model every time
The next realization was even more impactful:
Maybe we don’t need the entire model to work for every response.
This led to architectures like Mixture of Experts (MoE).
Instead of one large network handling everything, the model is split into smaller “experts,” and only a few of them are activated for a given input. A routing mechanism decides which ones matter.
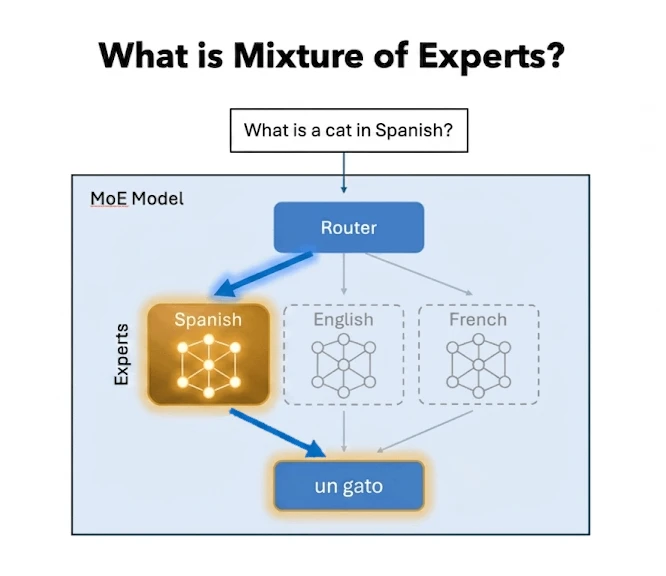
So the model can still be large and capable overall, but for any query, only a fraction of it is actually doing work.
That directly reduces compute per token without shrinking the model’s overall intelligence.
SLM: Choosing the right model size
Then came a more practical observation.
Most real-world tasks aren’t that complex. A lot of what we ask AI to do is repetitive or straightforward: summarizing text, formatting output, answering simple questions.
That’s where Small Language Models (SLMs) come in. These are lighter models designed to handle simpler tasks efficiently. In modern systems, they often handle the bulk of the workload, while larger models are reserved for harder problems.

So instead of optimizing one model endlessly, use a much smaller model that fits your purpose.
Distillation: Compressing large models into smaller ones
Distillation is when a large model is used to train a smaller one, transferring its behavior in a compressed form. The smaller model won’t match the original in every scenario, but for many tasks, it gets surprisingly close.
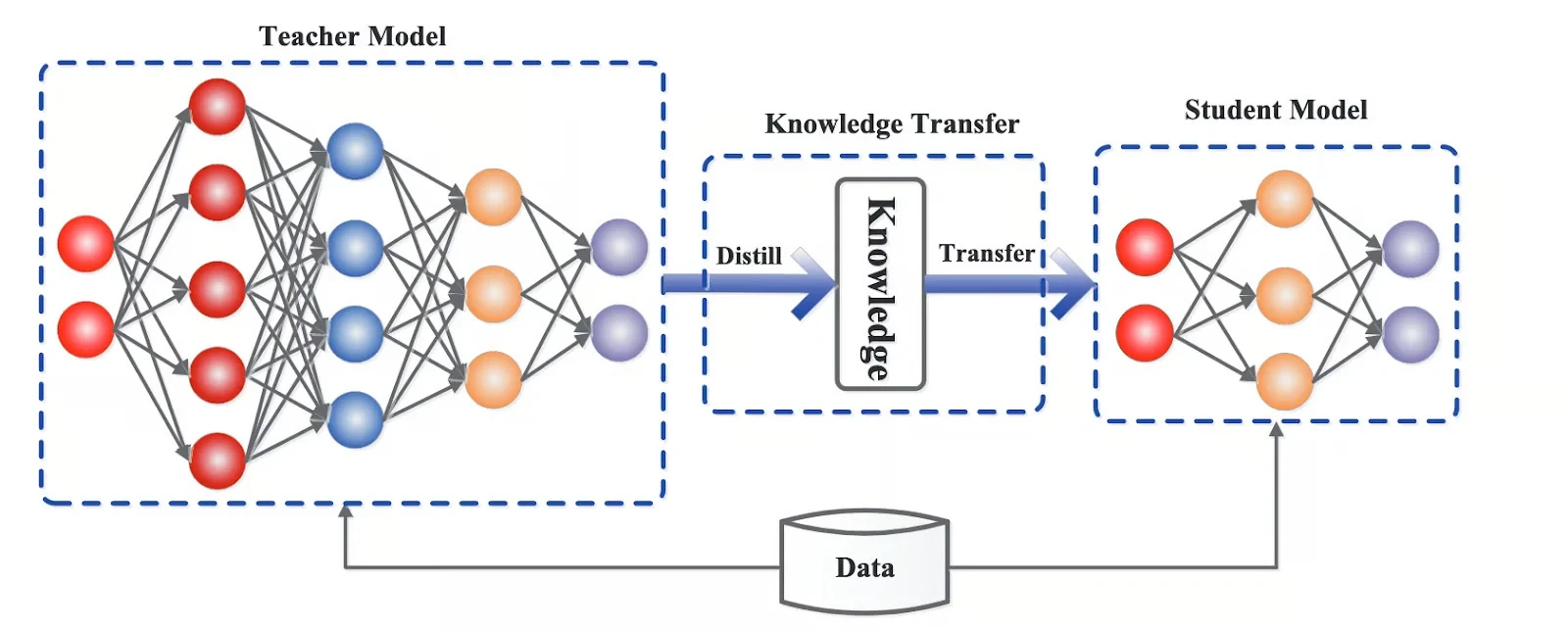
This means you can serve a much cheaper model while preserving most of the useful behavior.
Again, the theme is the same: reduce how much computation is needed per token.
KV Caching: Avoiding repeated work
Finally, there’s the realization that not every computation needs to be done from scratch.
In real systems, inputs overlap. Conversations repeat patterns. Prompts share structure.
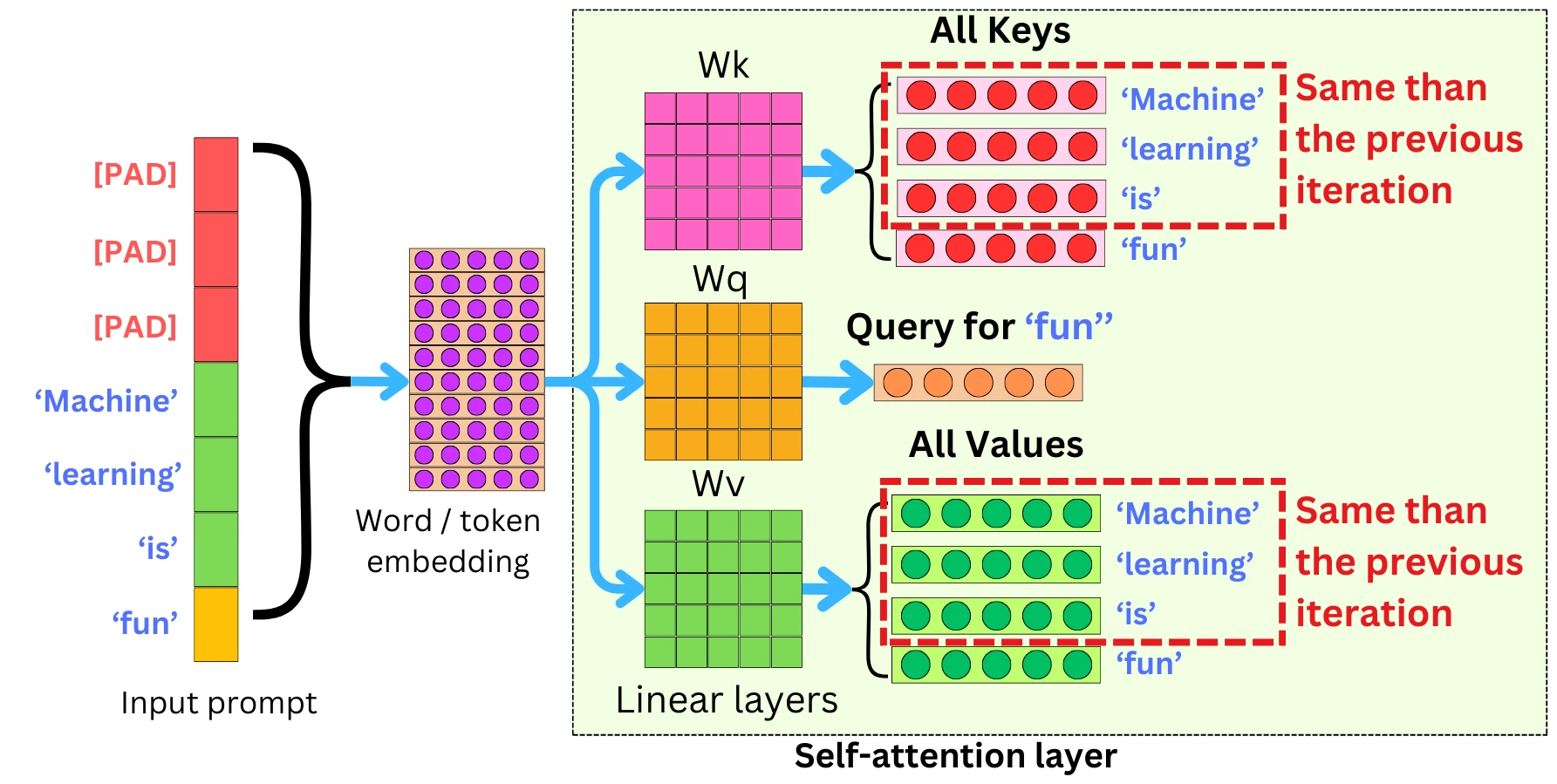
Modern implementations take advantage of this through caching which is reusing intermediate states from previous computations. Instead of recalculating everything, the model picks up from where it left off.
This doesn’t change the model at all. It just removes redundant work.
Note: There are modern caching techniques like TurboQuant which offers extreme compression in KV caching technique. Leading to even higher savings.
Making compute itself cheaper
Once the amount of compute per token was reduced, the next step was obvious:
Make the remaining compute cheaper to run.
Executing the same model more efficiently
A lot of progress here comes from optimizing inference itself.
Even with the same model, how you execute it matters. Improvements in batching, memory access, and parallelization mean that the same computation can now be done faster and with fewer resources.
You can see this in practice with models like GPT-4 Turbo or Claude 4 Haiku. These are entirely new intelligence layers which are engineered to be faster and cheaper to run compared to earlier versions.
This is what often shows up as “optimized” or “turbo” variants. The intelligence hasn’t changed: the execution has simply become tighter and more efficient.
Hardware that amplifies all of this
All these improvements benefit from hardware that’s designed for this kind of workload.
Companies like NVIDIA and Google have built chips specifically optimized for the kinds of operations AI models rely on, especially large-scale matrix multiplications.

These chips are better at:
- handling lower-precision computations (important for quantization)
- moving data efficiently
- processing many operations in parallel
Hardware doesn’t reduce costs on its own. But it makes every other optimization more effective.
Putting it all together
Early AI systems were wasteful. Every token used the full model, full precision, every time.
Then things shifted. We started cutting unnecessary work:
- lighter operations
- partial model usage
- smaller models for simpler tasks
- avoiding recomputation
Once the workload shrank, the next step was making it cheaper to run:
- better execution
- smarter batching
- hardware built for these exact operations.
That’s why costs dropped faster than expected.
There isn’t just a single factor leading this change. Instead it is a steady shift toward using only the compute that’s actually needed.
Frequently Asked Questions
Q1. What are tokens in AI and why do they matter?
A. Tokens are chunks of text AI processes. More tokens mean more computation, directly impacting cost and performance.
Q2. Why is AI getting cheaper over time?
A. AI is cheaper because systems reduce compute per token and make computation more efficient through optimization techniques and better hardware.
Q3. How is AI cost calculated using tokens?
A. AI cost is based on input and output tokens, priced per million tokens, combining usage and per-token rates.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






