Claude Haiku 4.5 is Anthropic’s latest small model, released on 15th October to all users. It’s a strong reminder that speed and intelligence don’t have to come at a high price.
Just five months ago, Claude Sonnet 4 was considered the benchmark for balanced performance. Now, Haiku 4.5 delivers nearly the same coding and reasoning skills at one-third the cost and more than twice the speed.
This release isn’t just another upgrade. It shows how much ground smaller models can cover when designed well. In this article, we’ll look at what’s new in Haiku 4.5, how it performs, and why it matters.
Table of contents
Background: Where Haiku Fits in the Claude Family
Anthropic’s Claude family includes three core models Opus, Sonnet, and Haiku. Each model is designed for different needs.
- Claude Opus is the most capable model. It is built for deep reasoning and complex tasks.
- Claude Sonnet offers balance between intelligence and efficiency. It is ideal for professional and enterprise tasks.
- Claude Haiku is the smallest and fastest of the three. It is build for applications that demand speed, scalability, and cost-effectiveness.
With Haiku 4.5, Anthropic has pushed this lightweight model even further, offering faster responses, improved coding skills, and reliable accuracy at minimal cost. It’s the ideal choice for developers seeking both performance and scalability.
Key improvements in Haiku 4.5 over Haiku 3.5
Near-frontier performance at high speed
Claude Haiku 4.5 delivers performance comparable to Sonnet 4 across reasoning, coding, and complex tasks, but at over twice the speed and one-third the cost, making it ideal for high-volume applications.
Extended thinking capabilities
For the first time in the Haiku family, 4.5 supports extended thinking, enabling advanced reasoning:
- Access internal reasoning for complex problem-solving
- Summarized thinking outputs for production-ready deployments
- Interleaved thinking between tool calls for multi-step workflows
- Control token budgets to balance reasoning depth with speed
Context Awareness
Claude Haiku 4.5 introduces context awareness, allowing the model to manage its conversation space more effectively:
- Token budget tracking: Monitors remaining context after each tool call in real time
- Improved task persistence: Executes tasks efficiently by understanding available space
- Multi-context workflows: Handles state transitions smoothly across extended sessions
This is the first Haiku model to include native context awareness.
Strong Coding and Tool Use
Claude Haiku 4.5 offers robust coding capabilities and full tool support:
- Coding proficiency: Excels at code generation, debugging, and refactoring
- Full tool integration: Works with all Claude 4 tools, including bash, code execution, text editor, web search, and computer use
- Enhanced computer use: Optimized for autonomous desktop and browser automation
- Parallel tool execution: Coordinates multiple tools efficiently for complex workflows
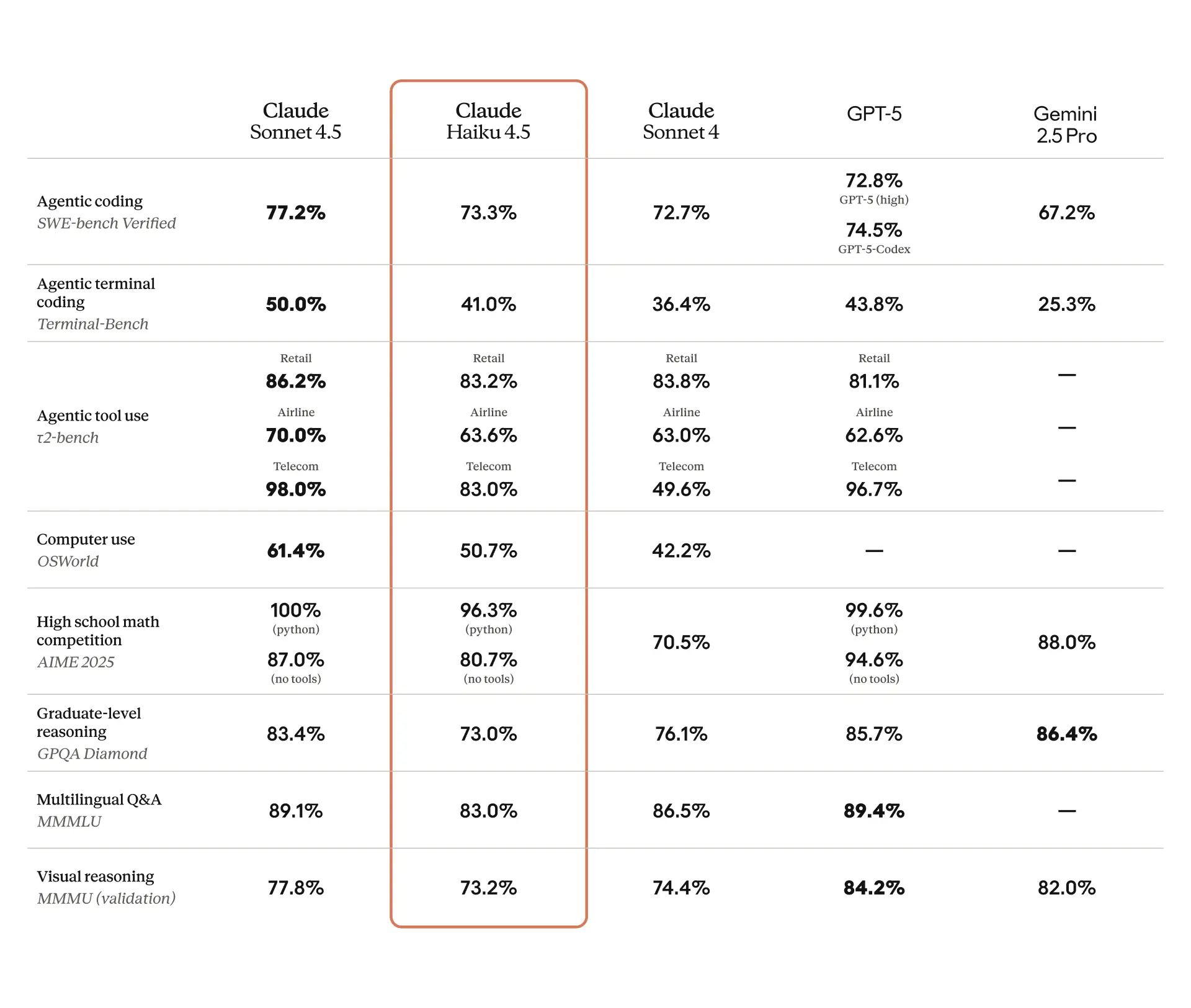
Benchmarks & Comparative Evaluation
Across standard benchmarks, Claude Haiku 4.5 punches above its weight. It matches Sonnet 4.5 on many coding and reasoning tests while delivering substantially better efficiency, roughly one-third the cost and over twice the speed in throughput and latency-sensitive tasks.
Compared to earlier Haiku releases, 4.5 improves token-per-second throughput, multi-tool orchestration, and multi-turn coherence, making it particularly strong for real-time assistants and high-volume pipelines.
In short, Haiku 4.5 offers near-frontier accuracy with a clear edge in cost-performance and responsiveness.
Safety evaluations
In its safety assessments, Anthropic reports that Claude Haiku 4.5 passed comprehensive alignment tests with low rates of concerning behavior and clear gains over Haiku 3.5. Automated evaluations showed Haiku 4.5 has a statistically significant lower rate of misaligned behaviors than both Sonnet 4.5 and Opus 4.1, making it the company’s safest model by that metric.
Tests also found only limited risks around chemical, biological, radiological, and nuclear (CBRN) content, so Haiku 4.5 is being released under AI Safety Level 2 (ASL-2), while Sonnet 4.5 and Opus 4.1 remain classified at ASL-3.
Real World Tasks with Haiku 4.5
In this section, we will put this latest LLM to test on three main tasks around:
- Coding
- Reasoning
Coding
Prompt 1: “Create a webpage where objects fall under gravity and interact with the environment. The objects could be anything: squares, images, or shapes.
Requirements:
- Objects accelerate downward (gravity).
- Objects can collide with the “ground” or other surfaces and stop or bounce.
- Allow the user to spawn objects by clicking or dragging.
Bonus:
- Add wind or drag affecting the objects.
- Different object types with varying mass and elasticity.“
Output:
You can try it out yourself here: Claude
Review:
It created a good web app that followed most of the laws of physics. As a bonus, I added variations for mass and elasticity, but it ignored them. The simulation correctly applied gravity (objects accelerating downward), and all objects exhibited angular momentum. However, after collisions, only the round ball should have continued spinning, the others should have stopped, but they didn’t. When I pointed out this issue, it corrected the behavior, though its initial response had the previously mentioned mistake.
Reasoning
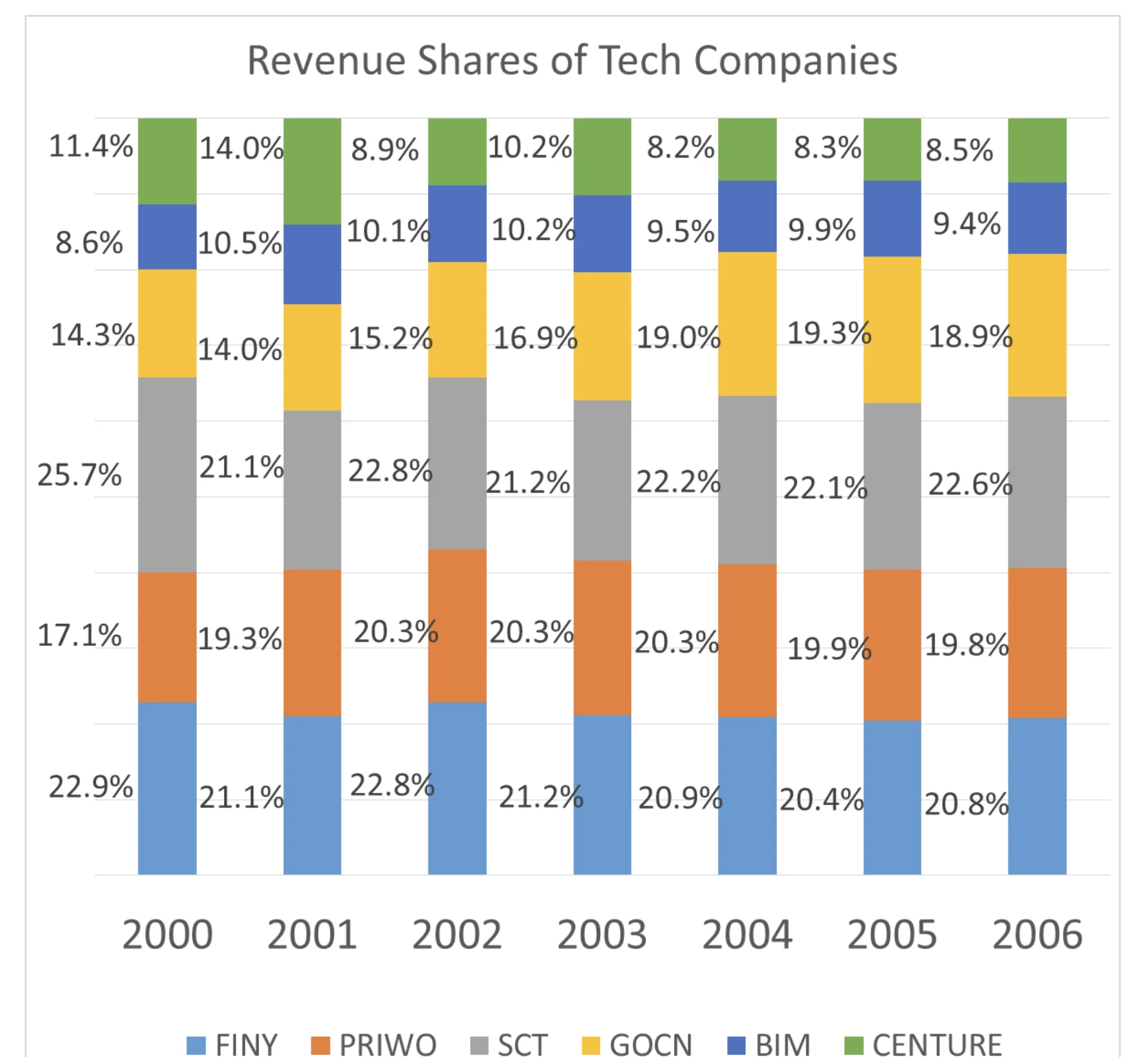
Prompt: “Chart represent the revenue share of the different companies in the tech sector in Cuckooland. Analyse the Graph and answer the following:
- In 2001, the company that grew the quickest grew by 100%, what was the growth rate of the company that had the least growth rate?
- In 2002, the growth rate of the overall sector was 39%, what was the absolute growth rate seen by SCT?
- Total revenue in 2006 was $21.2 bn, total revenue in 2005 was $18.1 bn. What was the absolute growth rate seen in Centure?
- In 2004, the entire industry added $4bn, of which an increase of $1bn was contributed by COGN, what was the growth rate seen by the entire sector in 2004?“
Output:
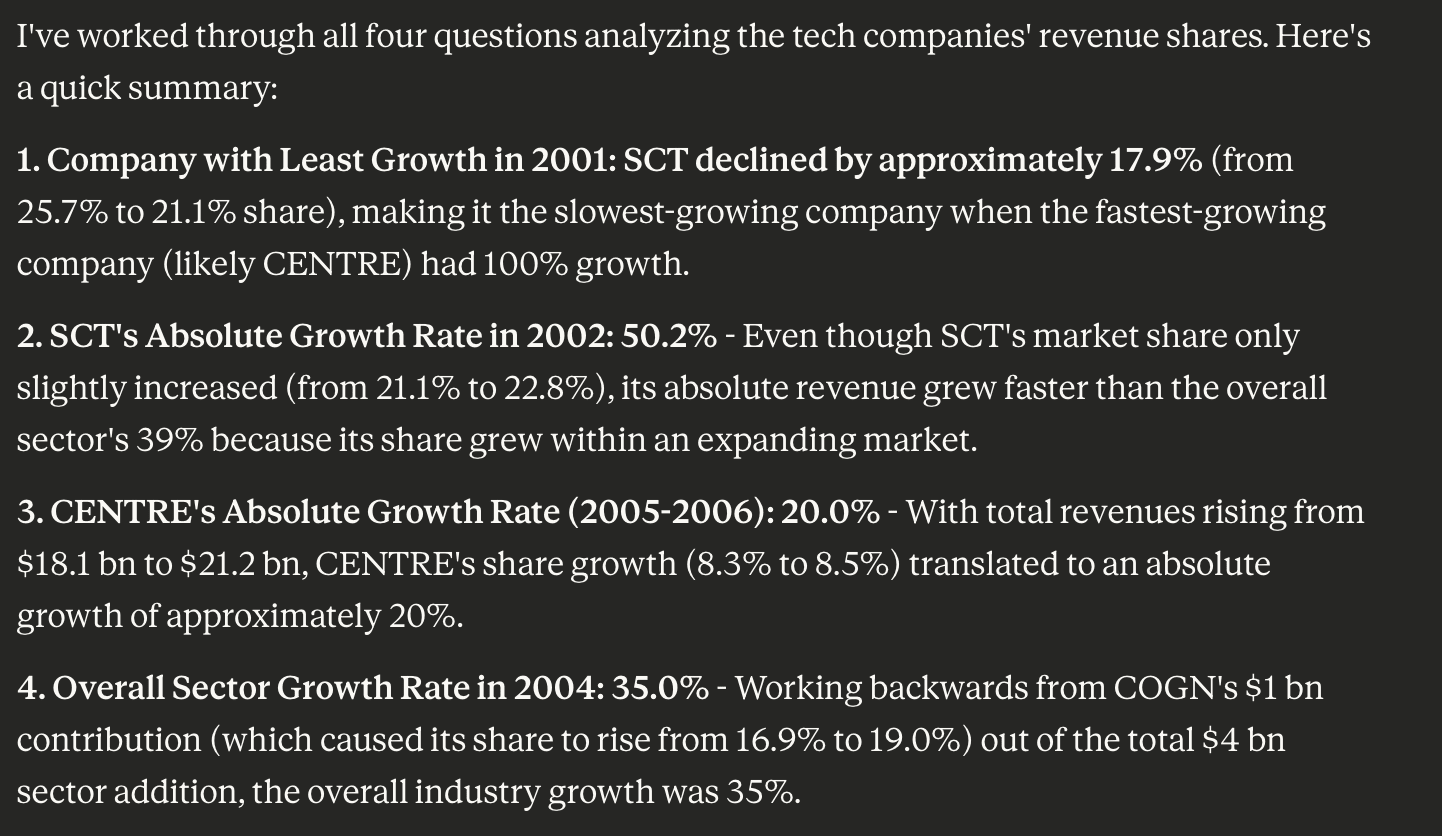
Reasoning:
Review:
First answer is wrong. The correct answer is 33%. First question had three parts: first to find the highest growth company, then to find the slowest growth company and then the growth of the slowest growth company. It completed the first two parts satisfactorily but in third part it only calculated the change in revenue share.
Prompt 2: “Two Egg Problem (Hard Version) You have a 100-floor building and two identical eggs. You want to find the highest floor from which an egg can be dropped without breaking. What is the minimum number of drops needed in the worst case?“
Output:
Review:
It has done a good job here, by giving the correct answer with proper reasoning and mathematics behind it.
Prompt 3: “If a person has a gold bar and needs to pay a worker an equal portion of gold for 6 consecutive days, what is the minimum number of cuts the person must make?”
Output:
Review:
It has done a good job here, by giving the correct answer. But instead of giving the answer directly, it has made one more iteration.
Conclusion
Claude Haiku 4.5 proves that small models can deliver big results. With near-frontier intelligence, extended reasoning, and lightning-fast responses, it successfully bridges the gap between efficiency and capability. Anthropic has refined Haiku into a model that performs complex coding and reasoning tasks at a fraction of the cost, without compromising accuracy or safety.
In real-world tests, Haiku 4.5 demonstrated strong coding proficiency, logical reasoning, and the ability to adapt to user feedback, making it suitable for both developers and enterprises. Its inclusion of extended thinking, context awareness, and enhanced tool use marks a meaningful evolution in how lightweight models can be deployed for large-scale, intelligent workflows.
Overall, Claude Haiku 4.5 is a powerful step forward for accessible, high-speed AI, offering the perfect blend of intelligence, performance, and safety for modern applications.
Frequently Asked Questions
Q1. What makes Claude Haiku 4.5 different from earlier Haiku models?
A. It’s faster, smarter, and more efficient. Haiku 4.5 matches near-Sonnet 4 performance at one-third the cost and twice the speed, with new features like extended reasoning, context awareness, and improved coding abilities.
Q2. How safe is Claude Haiku 4.5 compared to other Claude models?
A. It’s Anthropic’s safest model yet, rated AI Safety Level 2. Tests show fewer misaligned behaviors than both Sonnet 4.5 and Opus 4.1.
Q3. Who should use Claude Haiku 4.5?
A. Developers and teams needing fast, scalable, and affordable AI for coding, reasoning, or high-volume workflows will benefit most from Haiku 4.5’s speed and efficiency.
Data Analyst with over 2 years of experience in leveraging data insights to drive informed decisions. Passionate about solving complex problems and exploring new trends in analytics. When not diving deep into data, I enjoy playing chess, singing, and writing shayari.






