This article was published as a part of the Data Science Blogathon
Dummy data is needed for a variety of purposes. Finding the required data in a specific format can be difficult. This article explores the different ways of creating the dummy data using the Faker package in Python.
Topics covered in this article are as follows:
- What is dummy data?
- Why do we need dummy data?
- How to install the Faker Package?
- How to create and initialize a Faker Generator?
- How to create a name, address, and random text using Faker?
- How to create the same dummy data?
- How to create unique dummy data?
- How to create currency-related dummy data using Faker?
- How to create localized dummy data Using Faker?
- How to create a dummy dataset using Faker?
- What are Providers?
- Command-line usage of Faker Package
- Alternate ways of creating dummy data in Python
What Is Dummy Data?
Dummy data is also called random data. As the name suggests, it is fake data that is generated randomly. It acts as a substitute or placeholder for the live data.
Why Do We Need Dummy Data?
Dummy data is used for testing and operational purposes. It is used to test what you have developed and how your code reacts to different kinds of inputs.
In Python, one can create the dummy data using the Faker package. It is an open-source library that generates dummy data of many different types.
How To Install The Faker Package for Dummy Data?
One can install the Faker package using the pip command as follows:
Pip install Faker
How To Create And Initialize A Faker Generator?
One can use the Faker() method to create and initialize a Faker Generator.
from faker import Faker fake = Faker()
Now, as you are ready with your installation and initialization of a Faker generator, you can create any data you want.
How To Create A Name, Address, And Random Text Using Faker?
The name() method can be used to create a full name. If you want the only first name or last name instead of the full name, you can use the methods first_name() and last_name().
Each call to these methods will generate a random name.
Let’s jump into the code to see how these methods work.
from faker import Faker
fake = Faker()
print(fake.first_name())
print(fake.last_name())
print(fake.name())For creating address and random text, you can use address() and text() methods.
fake.address() ‘4843 Gordon Field Suite 617nSouth Karen, SC 39850’
fake.text() ‘Game trade he different. There can between program. Million produce believe small along both.nCost best week tell capital authority. Food wish inside far evening my. Simple fly break career maybe.’
The text() method above created a single paragraph.
For creating multiple names, you can put the name() method in a for loop as follows:
for _ in range(10): print(fake.name())
Dr. Marissa Valencia DDS
Jessica Byrd
Anna Mendez
Jessica Robertson
Marvin Duncan
Robert Good
Barbara Jackson
James Faulkner
Destiny Harvey
Christine Hughes
How To Create The Same Dummy Data using Faker Package?
In some cases, you might want to reproduce the same data set. It is possible by seeding the generator. You can use the seed() method to produce the same dummy data as follows:
Faker.seed(111) print(fake.first_name()) 'Christy Bender'
How To Create Unique Dummy Data using Faker Package?
To ensure that the generated dummy data is unique, you can use the .unique property of the generator.
names = [fake.unique.first_name() for i in range(100)]
Each time, the above code will be executed, it will generate unique 100 names.
How To Create Currency-related Dummy Data Using Faker Package?
You can use the following Faker() properties for creating cryptocurrency related dummy data
cryptocurrency() – It creates cryptocurrency name and it’s corresponding code.
cryptocurrency_name() – It creates cryptocurrency name.
cryptocurrency_code() – It creates cryptocurrency code.
Let’s implement some of these properties and see the results.
fake.cryptocurrency_name() ‘Bitcoin’
fake.cryptocurrency()
('ETC', 'Ethereum Classic')
You can use the following Faker() properties for creating currency related dummy data
currency() – It creates currency name and it’s corresponding code.
currency_name() – It creates currency name.
currency_code() – It creates currency code.
fake.currency()
('TZS', 'Tanzanian shilling')
fake.currency_name() ‘Turkish lira’
Command-line Usage Of Faker Package
After installation of the Faker package, you can also invoke it from the command line. You can directly write the code at the command prompt.
What Are Providers?
So far we have used Faker generator properties like name(), first_name, last_name, address, etc. There are many such properties packaged in ‘Providers’. Some are Standard Providers while others are Community Providers developed by the community.
There are many Standard Providers like credit_card, date_time, internet, person, profile, bank, etc. which helps in creating the relevant dummy data.
You can find more information about the complete list of Standard Providers and their properties here.
There are many Community Providers like Credit Score, Air Travel, Vehicle, Music, Microservice, etc. You can also create your provider and add it to the Faker package.
You can find more information about the complete list of Community Providers and their properties here.
How To Create Localized Dummy Data Using Faker Package?
You can create the localized dummy data by providing the required locale as an argument to the Faker Generator.
It also supports multiple locales. In that case, all the locales need to be provided in the python list data type.
The default locale is ‘en_US’ i.e. US English.
Let’s code to create 10 Hindi names.
from faker import Faker
fake = Faker('hi_IN')
for _ in range(10):
print(fake.name())
अद्वैत दयाल देन्यल अब्बासी हासन महाराज इशान जमानत कुमारी खान हासन काले विक्रम रामशर्मा हासन मंगल इन्दु गायकवाड श्री महाराज
How To Create A Dummy Dataset Using Faker Package?
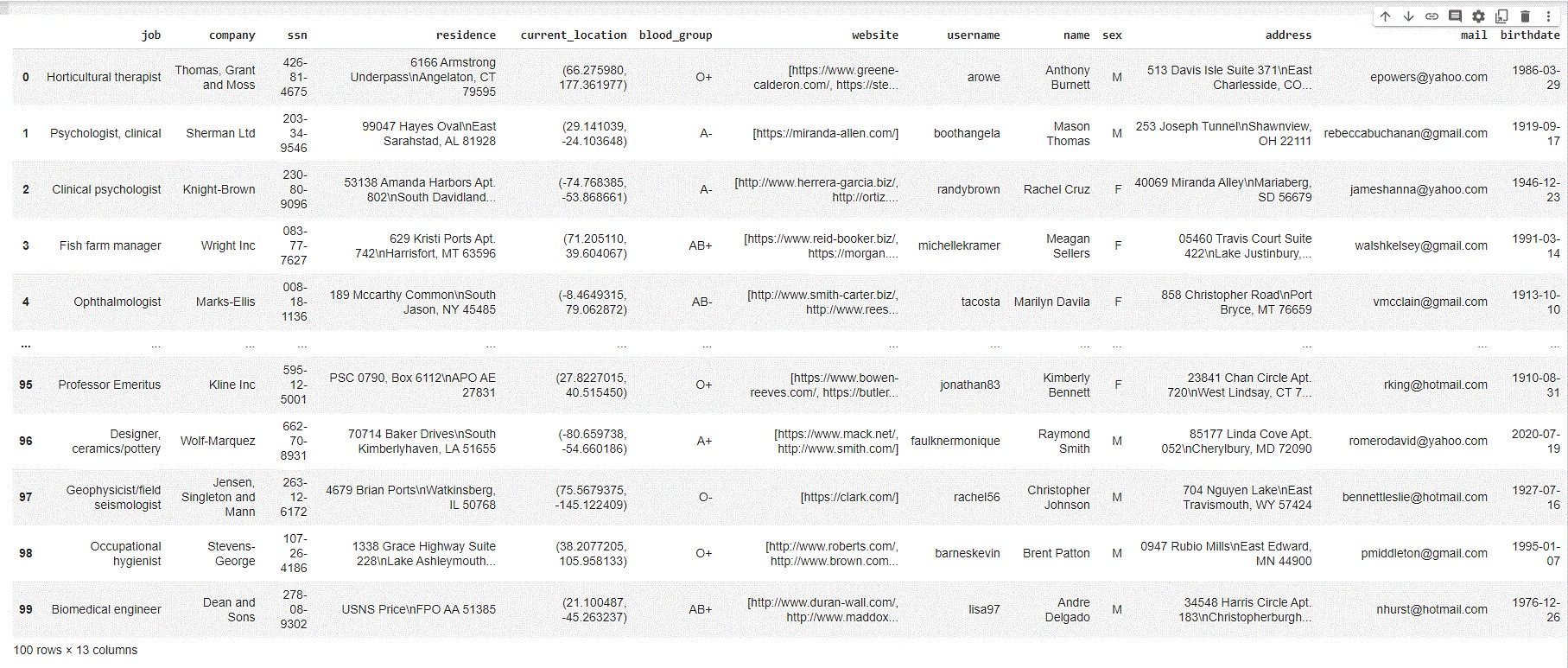
We will create a dummy dataset of 100 people with attributes like job, company, residence, username, name, address, current location, mail, etc. We will use the Standard Provider ‘Profiles’ to create this data and use Pandas Dataframes to save it.
from faker import Faker import pandas as pd fake = Faker() profileData = [fake.profile() for i in range(100)] df = pd.DataFrame(profileData) df
Alternate Ways Of Creating Dummy Data In Python
There are some other ways to create the dummy data. They are as follows:
- Fauxfactory
It can be used when you need some random fake data such as strings, numbers, dates, times, IP, email addresses, etc. for quick testing of your code. You can find more information about it here.
- Using Random module from Numpy library in Python
If you want only pseudo-random numbers then they can be generated using the random package. It has different functions like rand(), randint() and choice().
Conclusion
We learned how to use the Faker package in Python to create various types of data. We explored how to create names, personal profiles, currency-related data. We also learned how to reproduce the same dummy data as well as how to generate the unique data. We explored the providers and also learned that it is possible to create locale-specific data.
There is a lot more we can do with this package. I have shared a few examples of generating fake data. I hope it will be useful for testing your application and reduce the overhead of finding real data.
References:
For more information about the Faker Package, you can visit here.






