This article was published as a part of the Data Science Blogathon.
Introduction
Data mining is extracting relevant information from a large corpus of natural language. Large data sets are sorted through data mining to find patterns and relationships that may be used in data analysis to assist solve business challenges. Thanks to data mining techniques and technologies, enterprises can forecast future trends and make more educated business decisions.
Syntax and semantics are the two major components of any written language. Syntax is the rules/grammar should follow by the writer while writing a language, and semantics is the internal meaning of the sentence or phrases the author has written.
So as a result, two types of data mining techniques are widely used in the data science industry today.
Syntax-based data mining: Here, we extract the data based on characters or words in the sentence. Not taking the implicit meaning. E.g. TF-IDF Method.
Pros:
- Easy to implement
- Easy to interpret
Cons:
- Not always accurate
- Not taking the actual context of the data mining scenario
Semantic-based data mining: Here, we are extracting the data based on the internal meaning of the corpus and sentence. Working based on the implicit meaning of the sentence.
Pros:
- Takes the actual context of the data mining scenario
- Can build more trust and robustness with the end user
Cons:
- Hard to implement
- More calculations need for the text matching
As we have seen above, not only do semantic-based data mining applications have many advantages, but also it can make a strong trust connection between the end user.

Many organizations and tech companies working on data mining are now turning from syntax-based data mining processes to semantic base data mining processes. So in this blog, I am describing some interview questions on semantic-based data mining that may chance to ask in the data mining engineer interview process.
Semantics-based Data Mining Interview Questions
1 – What is semantic search? How does it differ from syntactic search?
Ans: Semantic search is a method of data searching in which a search query seeks to identify keywords and ascertain the intent and context of the words being used. Search engines utilise semantic search as a method to try to decipher your search query’s context and intent to provide you with results that are relevant to your search.
Syntactic matching refers to matching search terms to keywords depending on the search terms entered into the search engine. This would be phrase- and exact-matching. Semantic matching matches search queries to keywords based on the intent of the searcher’s input. Broad match applies here.
2- What is the role of embeddings in semantic search?
Ans: In semantic search, the search operations are performed based on the embeddings. There are different types of semantic search is there. E.g., Textual semantic search in the case of natural language systems, Visual semantic search in the case of image processing systems..etc. Whatever the case, we convert the input and corpus objects to numerical fixed-length vectors. And the rest of the matching operations are applied to these vectors. These vectors are called embeddings.
A sample flow diagram is shown below.
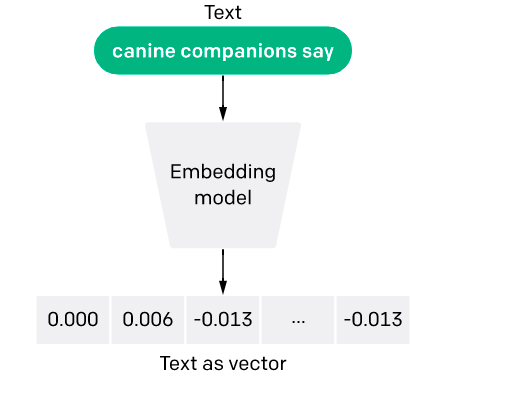
Making the textual sentences into embedding format enables the system to perform mathematical operations faster by retaining the inner meaning. Also, embedding will help systems encode similar sentences to similar encoding vectors with fixed/variable length.
So any semantic search-based system will contain the following 2 modules minimum.
1 – Embedding module
Where the encoding of the objects to embedding takes place
2 – Searching module
Where the actual search/match operations upon the embedding take place
3 – What are the different types of semantic similarity methods?
Ans:
There are different types of semantic similarity methods. All of the methods are categorized under four major types. Those are
- Knowledge-Based Similarity
- This kind is what we use to compare concepts semantically. A node in an ontology graph represents each notion in this category. Because the graph represents the concepts from the corpus, this approach is also known as the topological approach. A smaller number of edges connecting two concepts (nodes) indicates that they are more semantically and conceptually similar.
- E.g., In The below image, Figure – 1, the similarity structure shows that the coin is more related to money than the credit
- Statistical-Based Similarity
- This kind uses feature vectors learned from the corpus to calculate semantic similarity.
- Word embeddings can be used in conjunction with most of the techniques in this category to improve results because they capture the semantic relationship between words.
- String-Based Similarity
- To calculate the distance between non-zero feature vectors, evaluating semantic similarity does not depend on this type alone but rather mixes it with other types.
- It again classified into two major types
- Character-Based Similarity Measure
- Longest Common Substring (LCS)
- Damerau-Levenshtein
- Jaro
- Jaro-Winkler
- Needleman-Wunsch
- Etc…
- Term-Based Similarity Measure
- Block Distance
- Cosine Similarity
- Soft Cosine Similarity
- Sorensen-Dice index
- Euclidean Distance:
- Jaccard Index
- Etc…
- Character-Based Similarity Measure
- Language Model-Based Similarity
- The scientific community first used this type in 2016 to quantify the semantic similarity of two English sentences under the premise that they are syntactically sound.
- This type has five main steps:
- Removing stop words
- Tagging the two phrases using any Part of Speech (POS) algorithm
- From the tagging step output, this type forms a structure tree for each phrase (parsing tree)
- Building an undirected weighted graph using the parsing tree
- Finally, the similarity is calculated as the minimum distance path between nodes (words)
Figure – 1
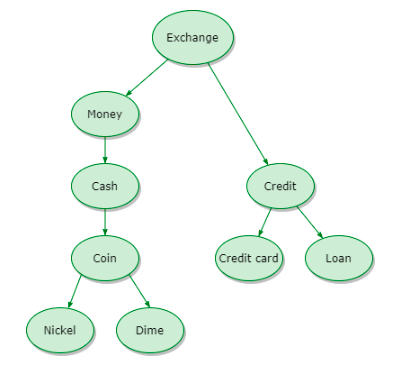
source: https://www.baeldung.com/cs/semantic-similarity-of-two-phrases
4 – How can we transform natural language sentences into vectors/embeddings?
Ans: There are different methods to convert sentences to vectors/embeddings. Some of those are
- One Hot Encoding
- Each word in the vocabulary V is given an integer index, I, in this manner, ranging from 0 to V-1. The vector representation for each word is of length V, with all 0s except 1 at the ith index for the corresponding word. It is a representation at the word level.
- BOW & BON
- Bag Of Words(BOW)
- As its name implies, Bag Of Word is simply a collection of words that ignores two important factors in its vector representations. 1) The order of the tokens in the sentence or sequence, and 2) the token’s semantic significance. The majority of Bag of Words is based only on the frequency of tokens found in a sentence. It is a representation at the sentence level.
- Bag Of N-grams(BON)
- BON can be considered an improved form of BoW in which, rather than measuring the frequency of individual tokens, we generate groups of N tokens and do so. The term “N-gram” refers to each group. This is a sentence-level illustration.
- Bag Of Words(BOW)
- TF-IDF
- A single float value per word called TF-IDF solves a particular word significance problem that may be highly useful in text classification. There is currently no idea of word importance or how significant a single word is in a document or sentence in any of the three versions we read above. It is a representation at the sentence level.
- Word2Vec (CBoW & Skip Gram)
- Word2Vec is a neural network-based model for learning word embeddings and is known as one of the most well-known names in the word embedding arena. The two most pressing issues we had before are resolved: lower dimension representations and context-based word interpretation (vicinity words). It is a representation at the word level.
- Continuous Bag Of Words (CBoW)
- CBoW aims to train a Neural Network that predicts the target word using input from context words.
- Skip Gram Model
- Skip Gram, which operates in complete opposition to CBoW, aims to anticipate context words from a single input word.
- Continuous Bag Of Words (CBoW)
- Word2Vec is a neural network-based model for learning word embeddings and is known as one of the most well-known names in the word embedding arena. The two most pressing issues we had before are resolved: lower dimension representations and context-based word interpretation (vicinity words). It is a representation at the word level.
- fastText
- fastText is another word embedding method that extends the word2vec model. Instead of learning vectors for words directly, fastText represents each word as an n-gram of characters
- Global Vectors (GloVe)
- We can utilise the complete corpus to derive an embedding for a word using the GloVe approach. It is a vector representation technique at the word level. GloVe incorporates the core of the entire corpus using word-word co-occurrence probability. The gloVe is the name given to the created embedding because it is a global statistic.
- Doc2Vec (Distributed Memory & Distributed BoW)
- A good approach for getting document/paragraph/sentence embedding in a fixed-length vector is Doc2Vec, which is an extension of Word2Vec. It has two variants, just like Word2Vec:
- Distributed Memory Doc2Vec for skip-gram model
- Distributed BoW Doc2Vec for BoW model
- A good approach for getting document/paragraph/sentence embedding in a fixed-length vector is Doc2Vec, which is an extension of Word2Vec. It has two variants, just like Word2Vec:
- Transformer based embedding
- These are the latest types of word embeddings based on transformer architecture. The major advantage of this embedding is that it can capture the full context of the sentence it is embedding.
- Several transformer-based models are available for this and can generate the best contextual embedding based on the use case.
- Etc…
5 – Describe the vector database and its use cases.
Ans: A vector database, which has features like CRUD operations, metadata filtering, and horizontal scaling, indexes and saves vector embeddings for quick retrieval and similarity searches. Vector databases are used in cases where the traditional Relational Database Management Systems or semi-structured data storage structures are not enough to meet the actual requirement.
Normally vector databases are used in the case of large amounts of unstructured data handling scenarios. Usually, unstructured data are encoded in the format of embedding and stored those embeddings in the vector database. When the user query arrives, it will match the query embedding with corpus embeddings and then retrieve the most semantically matching results for the end user.
Other than textual embeddings, vector databases can handle any kind of embedding, such as visual, video, and concept embeddings…So as a result, vector databases can use for multi-domain semantic matching scenarios.
.jpg)
6 – Explain ANN in semantic search
Ans: An approximative closest neighbor search algorithm may return points at most c times farther away from the query than its nearest points.
An estimated nearest neighbor is frequently almost as good as an exact one, which is one of the appeals of this method. Particularly, minor variations in distance shouldn’t matter, provided the distance metric effectively conveys the idea of user quality.
ANN uses methods like locality-sensitive-hashing to better balance speed and accuracy, acting as a faster classifier with a little accuracy trade-off. With datasets in higher dimensions, where algorithms like KNN will fail to perform better and relevant results within optimized time
There are five different types of ANN-based algorithms are used in semantic search. Those are,
- Brute Force
- Although it isn’t strictly an ANN algorithm, it offers the most logical solution and a standard against which to compare all other models. Before sorting, it estimates the distance between each point in the datasets to determine which point is closest to the other. extremely ineffective
- Hashing Based(LSH)
- involves a stage of preprocessing when the data is filtered into several hash tables to prepare for the querying procedure. After receiving a query, the algorithm loops back through the hash tables, collecting all similarly hashed locations and assessing closeness to produce a list of the closest neighbors.
- Graph-Based
- begins with a set of “seeds” and produces several graphs before utilizing the best-first search to traverse the graphs. The implementation may identify the “true” nearest neighbor by using a visited vertex parameter from each neighbor.
- Partition Based
- The implementation divides the dataset into increasingly distinguishable subsets until it settles on the closest neighbor.
- Hybrid
- This is the combination of some of the above methods.
7 – What are the ANN benchmarks?
Ans: Fast nearest-neighbor searches in high-dimensional spaces are a growingly important challenge in the case of semantic search. A benchmarking environment for approximate nearest neighbor algorithms search is called ANN-Benchmarks.
The idea of comparing/benchmarking ANN algorithms to comprehend better how implementation options can vary based on the kind and quantity of the dataset
There are several precomputed data sets available for this. All data sets are divided into train and test sets and include the top 100 neighbors’ ground truth information. They are kept in HDF5 format. The following table contains info about the different datasets used for the ANN benchmarks.
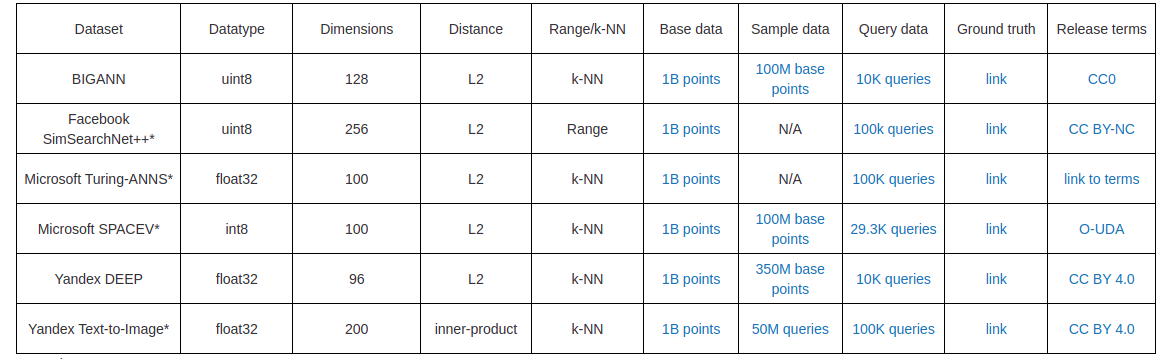
Different methods of approximate nearest neighbor-based searching techniques are evaluated as part of the ANN benchmarking. Some of the evaluated techniques are VESPA, ANNOY, FIASS, and K-GRAPH… etc
Here is the full list
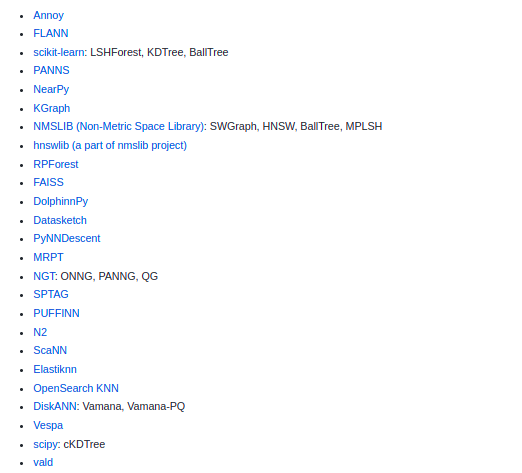
For more details, please check the official GitHub page here
8 – Compare WEAVIATE, ANNOY, and FIASS
Ans:
- WEAVIATE
- Weaviate is a vector search engine and vector database. It uses machine learning to vectorize and store data and to find answers to natural language queries. Low-latency vector search engine with out-of-the-box support for different unstructured media types. It offers Semantic Search, Question-Answer-Extraction, Classification, Customizable Models, and more. In weaviate, Vectorized search along with Multilayered graph(HNSW) storage enhances the semantic level data retrieving. The transformer Based module can use for vectorization and GraphQL for querying.
- ANNOY
- To locate the closest approximate neighbors, the library Annoy is being employed. It is an open-source library that can be used to look for points in space that are nearby a given query point. To allow many processes to share the same data, it generates sizable read-only file-based data structures mapped into memory. It is utilized to compare words or texts in a vector space for our purposes. Spotify develops the library.
- FIASS
- Faiss is a package for grouping and searching for comparable objects in dense vectors. It has algorithms that can search through vector set collections of any size, including those that would not fit in RAM. Additionally, it has an accompanying code for parameter adjustment and evaluation. Faiss is a C++ program that has full Python/NumPy wrappers. On the GPU, some of the most beneficial algorithms are implemented. It is developed at Facebook AI Research.
9 – Have you practical coding experience with semantic text search tools?
Ans – Yes.
The tools I have used for the development of semantic matching in the unstructured data domain are given as follows. An official website link is also provided. Please check.
10- Explain Locality Sensitive Hashing
Ans– Locality-sensitive hashing (LSH) is a way used in computer science that hashes similar inputs into the same “buckets” with a high likelihood (The number of buckets is much smaller than the universe of possible input items). LSH is one of the algorithms for approximate nearest neighbors.
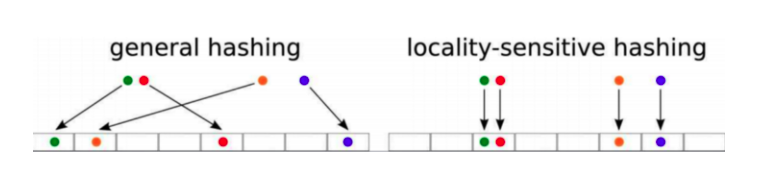
https://towardsdatascience.com/understanding-locality-sensitive-hashing-49f6d1f6134
Advantages
Near-duplicate detection
Large-scale image search
Audio/video fingerprinting
Faster data mining
etc…
The process
The term “LSH” refers to a family of functions that hashes similar inputs into the same “buckets” with a high likelihood (The number of buckets is much smaller than the universe of possible input items) and others in different . This makes differentiating between observations that are similar in several ways easier.
Steps
The LSH algorithm has three major modules
- Shingling
-
- This stage involves converting each document into a set of k characters ( k-shingles or k-grams). The main concept is to represent each document on our application as a set of k-shingles.
- Now, we need a metric to check how similar different documents are. For this, the Jaccard Index is a proposed option. Documents A and B’s Jaccard Index is represented as:
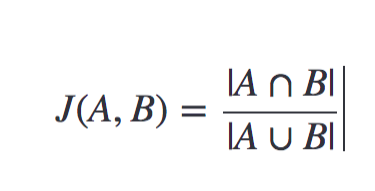
- Min hashing
-
- Hashing is to use the hashing algorithm H to each document into a tiny signature. The choice of hashing function and the similarity metric we employ are closely related. The proper hashing function for Jaccard similarity is min-hashing.
- Locality-sensitive hashing(LSH)
- Given the signatures of two documents, finding an algorithm that can determine if the two documents constitute a candidate pair—i.e., whether their similarity exceeds a threshold t—is the aim of LSH.
For more details, you can check this blog here.
Conclusion
Semantic search in unstructured data is one of the hottest research domains today. Because all of us like a search engine or an AI application that can read our actual intent while interacting rather than just do – don’t do command manner. Semantic search does the same, operating on all domains, including text, visual, speech, etc. Using this technique, we can extract semantically similar data from large corpora. In this blog, I have covered some common interview questions that may ask in the data mining interview process.
Key Takeaways
- In contrast to lexical search, which focuses on finding exact matches between the query words or their variants without considering the query’s overall meaning, semantic search refers to search with meaning.
- The term “embedding” refers to how words are represented for text analysis, often as a real-valued vector that encodes the word’s meaning.
- To manage the distinct structure of vector embeddings, vector databases were specifically designed. They compare values and select the ones most similar to one another to index vectors for quick search and retrieval.
- Locality-sensitive hashing is an algorithmic technique used in computer science that, with a high degree of probability, hashes similar input items into the same “buckets.”
- It is permitted for an approximate nearest neighbor search algorithm to return points that are at most c times farther away from the query than its nearest points.
I hope this article helped you to strengthen your semantic search fundamental concepts. Feel free to leave a remark below if you have any questions, concerns, or recommendations.
Keep learning..😊 !
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.






