The AI battle in 2025 is definitely getting charged with the launch of Google’s Gemini 2.0 Flash and OpenAI’s o4-mini. These new models arrived weeks apart, showcasing comparable advanced features and benchmark performances. Beyond the marketing claims, this Gemini 2.0 Flash vs o4-mini comparison aims to bring out their true strengths and weaknesses by comparing their performance on real-world tasks.
Table of Contents
- What is Gemini 2.0 Flash?
- What is o4-mini?
- How to Access o4-mini?
- Pricing of o4-mini
- Gemini 2.0 Flash vs o4-mini: Task-Based Comparison
- Gemini 2.0 Flash vs o4-mini: Benchmark Comparison
- Gemini 2.0 Flash vs o4-mini: Speed and Efficiency Comparison
- Gemini 2.0 Flash vs o4-mini: Feature Comparison
- Conclusion
- Frequently Asked Questions
What is Gemini 2.0 Flash?
Google created Gemini 2.0 Flash in an effort to address the most frequent criticism of big AI models: they are too slow for real-world applications. Rather than just simplifying their existing architecture, Google’s DeepMind team completely rethought inference processing.
Key Features of Gemini 2.0 Flash
Gemini 2.0 Flash is a lightweight and high-performance variant of the Gemini family, built for speed, efficiency, and versatility across real-time applications. Below are some of its standout features:
- Adaptive Attention Mechanism: Gemini 2.0 Flash flexibly distributes computational resources according to content complexity, in contrast to standard methods that process all tokens with identical computational intensity.
- Speculative Decoding: By employing a specialised distillation model to forecast many tokens at once and verifying them concurrently, the model significantly speeds up output creation.
- Hardware-Optimized Architecture: Specifically made for Google’s TPU v5e chips, the hardware-optimized architecture allows for previously unheard of throughput for cloud deployments.
- Multimodal Processing Pipeline: Instead of handling text, pictures, and audio independently, this pipeline uses unified encoders that pool computational resources.
Also Read: Image Generation with Gemini 2.0 Flash Experimental – Not Quite What I Expected!
How to Access the Gemini 2.0 Flash?
Gemini 2.0 Flash is available across three different platforms – the Gemini chatbot interface, Google AI Studio, and Vertex AI as an API. Here’s how you can access the model on each of these platforms.
- Via Gemini Chatbot:
- Sign in to Google Gemini with your Gmail credentials.
- 2.0 Flash is the default model chosen by Gemini when you open a new chat. If at all it is not already set, you can choose it from the model selection drop down box.
- Via Google AI Studio (Gemini API):
- Access Google AI Studio by logging through your Google account.
- Choose “gemini-2.0-flash” from the model selection tab on the right, to open an interactive chat window.

- To gain programmatic access, install the GenAI SDK and use the following code:
from google import genai
client = genai.Client(api_key="YOUR_GEMINI_API_KEY")
resp = client.chat.create(
model="gemini-2.0-flash",
prompt="Hello, Gemini 2.0 Flash!"
)- Via Vertex AI (Cloud API):
- Use Vertex AI’s Gemini 2.0 flash prediction endpoint to include it into your apps.
- Token charging is according to the rate card for the Gemini API.
Also Read: I Tried All the Latest Gemini 2.0 Model APIs for Free
What is o4-mini?
The most recent development in OpenAI’s “o” series, the o4-mini, is geared towards improved reasoning abilities. The model was developed from the ground up to optimize reasoning performance at moderate computational requirements, and not as a condensed version of a larger model.
Key Features of o4-mini
OpenAI’s o4-mini comes with a bunch of advanced features, including:
- Internal Chain of Thought: Before producing answers, it goes through up to 10x more internal reasoning stages than conventional models.
- Tree Search Reasoning: Chooses the most promising of several reasoning paths by evaluating them all at once.
- Self-Verification Loop: Checks for mistakes and inconsistencies in its own work automatically.
- Tool Integration Architecture: Specifically good at code execution, native support for calling external tools.
- Resolving Intricate Issues: Excels at solving complex problems in programming, physics, and mathematics that stumped previous AI models.
Also Read: o3 vs o4-mini vs Gemini 2.5 pro: The Ultimate Reasoning Battle
How to Access o4-mini?
Accessing o4-mini is simple and can be done through the ChatGPT website or using the OpenAI API. Here’s how to get started:
- Via ChatGPT Web Interface:
- To create a free account, visit https://chat.openai.com/ and sign in (or sign up).
- Open a new chat and choose the ‘Reason’ feature before entering your query. ChatGPT, by default, uses o4-mini for all ‘thinking’ prompts on the free version. However, it comes with a daily usage limit.
- ChatGPT Plus, Pro, and other paid users can choose o4-mini from the model dropdown menu at the top of the chat window to use it.

Pricing of o4-mini
OpenAI has designed o4-mini to be an affordable and efficient solution for developers, businesses, and enterprises. The model’s pricing is structured to provide results at a significantly lower cost compared to its competitors.
- In the ChatGPT web interface, o4-mini is free of charge with certain limits for free users.
- For limitless usage of o4-mini you need to have either a ChatGPT Plus ($20/month) or a Pro ($200/month) subscription.
- To use the “gpt-o4-mini” model via API, OpenAI charges $0.15 per million input tokens and $0.60 per million output tokens.
Gemini 2.0 Flash vs o4-mini: Task-Based Comparison
Now let’s get to the comparison between these two advanced models. When choosing between Gemini 2.0 Flash and o4-mini, it’s crucial to consider how these models perform across various domains. While both offer cutting-edge capabilities, their strengths may differ depending on the nature of the task. In this section, we’ll see how well both these models perform on some real-world tasks, such as:
- Mathematical Reasoning
- Software Development
- Business Analytics
- Visual Reasoning
Task 1: Mathematical Reasoning
First, let’s test both the models on their ability to solve complex mathematical problems. For this, we’ll give the same problem to both the models and compare their responses based on accuracy, speed, and other factors.
Prompt: “A cylindrical water tank with radius 3 meters and height 8 meters is filled at a rate of 2 cubic meters per minute. If the tank is initially empty, at what rate (in meters per minute) is the height of the water increasing when the tank is half full?”
Gemini 2.0 Flash Output:


o4-mini Output:


Response Review
| Gemini 2.0 Flash | o4-mini |
| Gemini correctly uses the cylinder volume formula but misunderstands why the height increase rate remains constant. It still reaches the right answer despite this conceptual error. | o4-mini solves the problem cleanly, showing why the rate stays constant in cylinders. It provides the decimal equivalent, checks units and does the verification as well and uses clear math language throughout. |
Comparative Analysis
Both reach the same answer, but o4-mini demonstrates better mathematical understanding and reasoning. Gemini gets there but misses why cylindrical geometry creates constant rates which reveals gaps in its reasoning.
Result: Gemini 2.0 Flash: 0 | o4-mini: 1
Task 2: Software Development
For this challenge, we’ll be testing the models on their capacity to generate clean, and efficient code.
Prompt: “Write a React component that creates a draggable to-do list with the ability to mark items as complete, delete them, and save the list to local storage. Include error handling and basic styling.”
Gemini 2.0 Flash Output:
o4-mini Output:
Response Review
| Gemini 2.0 Flash | o4-mini |
| Gemini delivers a comprehensive solution with all requested features. The code creates a fully functional draggable to-do list with localStorage support and error notifications. The detailed inline styles create a polished UI with visual feedback, like changing background colors for completed items. | o4-mini offers a more streamlined but equally functional solution. It implements drag–and-drop, task completion, deletion, and localStorage persistence with proper error handling. The code includes smart UX touches like visual feedback during dragging and Enter Key support for adding tasks. |
Comparative Analysis
Both models created amazing solutions meeting all requirements. Gemini 2.0 Flash provides a more detailed implementation with extensive inline styles and thorough code explanations. o4-mini delivers a more concise solution using Tailwind CSS classes and additional UX Improvements like keyboard shortcuts.
Result: Gemini 2.0 Flash: 0.5 | o4-mini: 0.5
Task 3: Business Analysis
For this challenge, we’ll be assessing the model’s capabilities to analyze business problems, interpret data and propose a strategic solution based on real-world scenarios.
Prompt: “Analyze the potential impact of adopting a four-day workweek for a mid-sized software company of 250 employees. Consider productivity, employee satisfaction, financial implications, and implementation challenges.”
Gemini 2.0 Flash Output:
o4-mini Output:
Response Review
| Gemini 2.0 Flash | o4-mini |
| The model provides a thorough analysis of implementing a four-day workweek at a Gurugram software company. It’s organized into clear sections covering recommendations, challenges, and benefits. The response details operational issues, financial impacts, employee satisfaction, and productivity concerns. | The model delivers a more visually engaging analysis using emojis, bold formatting, and bullet points. The content is structured into four impact areas with clear visual separation between advantages and challenges. The response incorporated evidence from relevant studies to support its claims. |
Comparative Analysis
Both models offer strong evaluations but with different approaches. Gemini provides a traditional in-depth narrative analysis focused on the Indian context, particularly Gurugram. o4-mini presents a more visually appealing response with better formatting, data references and concise categorization.
Result: Gemini 2.0 Flash: 0.5 | o4-mini: 0.5
Task 4: Visual Reasoning Test
Both the models will be given an image to identify and its working but the real question is, will it be able to identify its right name? Let’s see.
Prompt: “What is this device, how does it work, and what appears to be malfunctioning based on the visible wear patterns?”
Input Image:

Gemini 2.0 Flash Output:



o4-mini Output:



Response Review
| Gemini 2.0 Flash | o4-mini |
| Gemini incorrectly identifies the device as a viscous fan clutch for car cooling systems. It focuses on rust and corrosion issues, explaining clutch mechanisms and potential seal failures. | o4-mini correctly identifies the components as a power steering pump. It spots specific problems like pulley wear, heat exposure signs, and seal damage, offering practical troubleshooting advice. |
Comparative Analysis
The models disagree on what the device is. o4-mini’s identification as a power steering pump is correct based on the component’s design and features. o4-mini shows better attention to visual details and provides more relevant analysis of the actual components shown.
Result: Gemini 2.0 Flash: 0 | o4-mini: 1
Final Verdict: Gemini 2.0 Flash: 1 | o4-mini: 3
Comparison Summary
Overall, o4-mini demonstrates superior reasoning capabilities and accuracy across most tasks, while Gemini 2.0 Flash offers competitive performance with its main advantage being significantly faster response times.
| Task | Gemini 2.0 Flash | o4-mini |
| Mathematical Reasoning | Reached correct answer despite conceptual error | Demonstrated clear mathematical understanding with thorough reasoning |
| Software Development | Comprehensive solution with detailed styling and extensive documentation | Perfect implementation with additional UX features and concise code |
| Four Day Workweek Analysis | In-depth narrative analysis with regional context | Evidence based claims with visual engaging presentation |
| Visual Reasoning | Incorrectly identified with mismatched analysis | Correctly identified with relevant analysis |
Gemini 2.0 Flash vs o4-mini: Benchmark Comparison
Now let’s look at the performance of these models on some standard benchmarks.
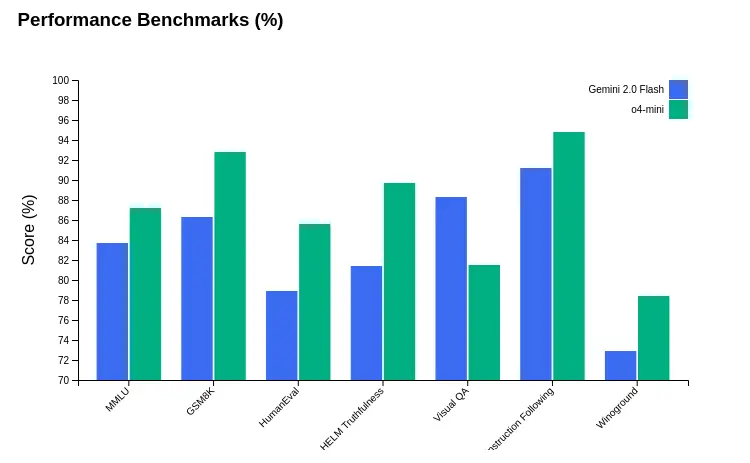
Each model shows clear strengths and weaknesses when it comes to different benchmarks. o4-mini wins at reasoning tasks while Gemini 2.0 Flash delivers much faster results. These numbers tell us which tool fits specific needs.
Looking at the 2025 benchmark results, we can observe clear specialization patterns between these models:
- o4-mini consistently outperforms Gemini 2.0 Flash on reasoning-intensive tasks, with a significant 6.5% advantage in mathematical reasoning (GSM8K) and a 6.7% edge in knowledge-based reasoning (MMLU).
- o4-mini demonstrates superior coding capabilities with an 85.6% score on HumanEval compared to Gemini’s 78.9%, making it the preferred choice for programming tasks.
- In terms of factual accuracy, o4-mini shows an 8.3% higher truthfulness rating (89.7% vs 81.4%), making it more reliable for information-critical applications.
- Gemini 2.0 Flash excels in visual processing, scoring 6.8% higher on Visual Question Answering tests (88.3% vs 81.5%).
- Gemini 2.0 Flash’s most dramatic advantage is in response time, delivering results 2.6x faster than o4-mini on average (1.7s vs 4.4s).
Gemini 2.0 Flash vs o4-mini: Speed and Efficiency Comparison
For a thorough comparison, we must also consider the speed and efficiency of the two models.

Energy efficiency is another area where Gemini 2.0 Flash shines, consuming approximately 75% less energy than o4-mini for equivalent tasks.
As we can see here, Gemini 2.0 Flash’s focus is on speed and efficiency whereas o4-mini emphasis on reasoning depth and accuracy. The performance differences show that these models have been optimized for different use cases and not for excelling across all domains.
Gemini 2.0 Flash vs o4-mini: Feature Comparison
Both Gemini 2.0 Flash and o4-mini represent fundamentally different approaches to modern AI, each with unique architectural strengths. Here’s a comparison of their features:
| Features | Gemini 2.0 Flash | o4-mini |
| Adaptive Attention | Yes | No |
| Speculative Decoding | Yes | No |
| Internal Chain of Thought | No | Yes (10× more steps) |
| Tree Search Reasoning | No | Yes |
| Self-Verification Loop | No | Yes |
| Native Tool Integration | Limited | Advanced |
| Response Speed | Very Fast (1.7s avg) | Moderate (4.4s avg) |
| Multimodal Processing | Unified | Separate Pipelines |
| Visual Reasoning | Strong | Moderate |
| Hardware Optimization | TPU v5e specific | General purpose |
| Languages Supported | 109 languages | 82 languages |
| Energy Efficiency | 75% less energy | Higher consumption |
| On-Premises Option | VPC processing | Via Azure OpenAI |
| Free Access Option | No | Yes (ChatGPT Web) |
| Price | $19.99/month | Free/$0.15 per 1M input tokens |
| API Availability | Yes (Google AI Studio) | Yes (OpenAI API) |
Conclusion
The battle between Gemini 2.0 Flash and o4-mini reveals a fascinating divergence in AI development strategies. Google has created a lightning-fast, energy-efficient model optimized for real-world applications where speed and responsiveness matter most. Meanwhile OpenAI has delivered unparalleled reasoning depth and accuracy for complex problem-solving tasks. Neither approach is universally superior – they simply excel in different domains, giving users powerful options based on their specific needs. As these advancements keeps on happening, one thing is for certain – the AI industry will keep evolving and with that new models will emerge giving us better results everyday.
Frequently Asked Questions
Q1. Can Gemini 2.0 Flash handle the same reasoning tasks as o4-mini, just more quickly?
A. Not entirely. While Gemini 2.0 Flash can solve many of the same problems, its internal reasoning process is less thorough. For straightforward tasks, you won’t notice the difference, but for complex multi-step problems (particularly in mathematics, logic, and coding), o4-mini consistently produces more reliable and accurate results.
Q2. Is the price difference between these models justified by performance?
A. It depends entirely on your use case. For applications where reasoning quality directly impacts outcomes—like medical diagnosis assistance, complex financial analysis, or scientific research—o4-mini’s superior performance may justify the 20× price premium. For most consumer-facing applications, Gemini 2.0 Flash offers the better value proposition.
Q3. Which model has better factual accuracy?
A. In our testing and benchmarks, o4-mini demonstrated consistently higher factual accuracy, particularly for specialized knowledge and recent events. Gemini 2.0 Flash occasionally produced plausible-sounding but incorrect information when addressing niche topics.
Q4. Can either model be deployed on-premises for sensitive applications?
A. Currently, neither model offers true on-premises deployment due to their computational requirements. However, both provide enterprise solutions with enhanced privacy. Google offers VPC processing for Gemini 2.0 Flash, while Microsoft’s Azure OpenAI Service provides private endpoints for o4-mini with no data retention.
Q5. Which model is better for non-English languages?
A. Gemini 2.0 Flash has a slight edge in multilingual capabilities, particularly for Asian languages and low-resource languages. It supports effective reasoning across 109 languages compared to o4-mini’s 82 languages.
Q6. How do these models compare on environmental impact?
A. Gemini 2.0 Flash has a significantly lower environmental footprint per inference due to its optimized architecture, consuming approximately 75% less energy than o4-mini for equivalent tasks. For organizations with sustainability commitments, this difference can be meaningful at scale.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]
Login to continue reading and enjoy expert-curated content.
Free Courses





Responses From Readers

