DeepSeek V3.1 didn’t arrive with flashy press releases or a massive campaign. It just showed up on Hugging Face, and within hours, people noticed. With 685 billion parameters and a context window that can stretch to 128k tokens, it’s not just an incremental update. It feels like a major moment for open-source AI. This article will go over DeepSeek V3.1 key features, capabilities, and a hands-on to get you started.
Table of contents
What exactly is DeepSeek V3.1?
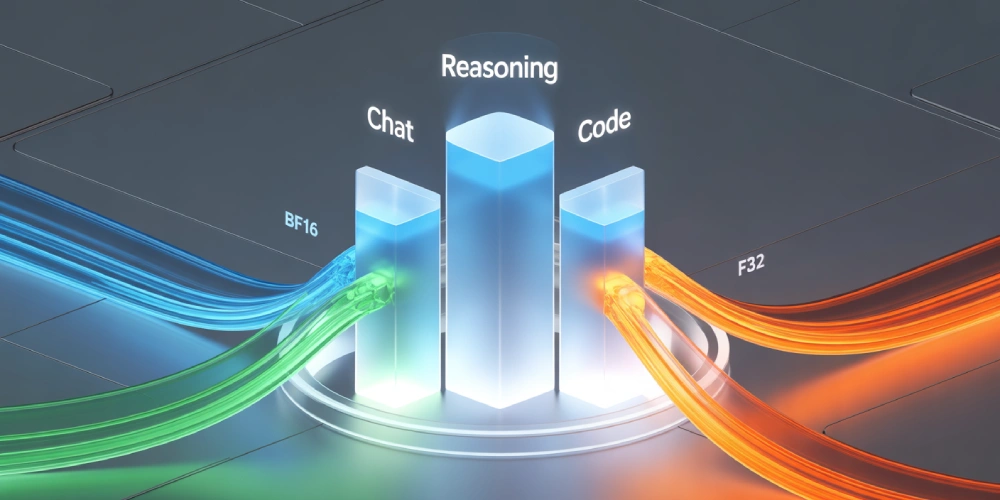
DeepSeek V3.1 is the newest member of the V3 family. Compared to the earlier 671B version, V3.1 is slightly larger, but more importantly, it’s more flexible. The model supports multiple precision formats—BF16, FP8, F32—so you can adapt it to whatever compute you have on hand.
It isn’t just about raw size, though. V3.1 blends conversational ability, reasoning, and code generation into one unified model or a Hybrid model. That’s a big deal! Earlier generations often felt like they were good at one thing but average at others. Here, everything is integrated.
How to Access DeepSeek V3.1

There are a few different ways to access DeepSeek V3.1:
- Official Web App: Head to deepseek.com and use the browser chat. V3.1 is already the default there, so you don’t have to configure anything.
- API Access: Developers can call the deepseek-chat (general use) or deepseek-reasoner (reasoning mode) endpoints through the official API. The interface is OpenAI-compatible, so if you’ve used OpenAI’s SDKs, the workflow feels the same.
- Hugging Face: The raw weights for V3.1 are published under an open license. You can download them from the DeepSeek Hugging Face page and run them locally if you have the hardware.
If you just want to chat with it, the website is the fastest route. If you want to fine-tune, benchmark, or integrate into your tools, grab the API or Hugging Face weights. The hands-on of this article is done on the Web App.
How is it different from DeepSeek V3?
DeepSeek V3.1 brings a set of important upgrades compared to earlier releases:
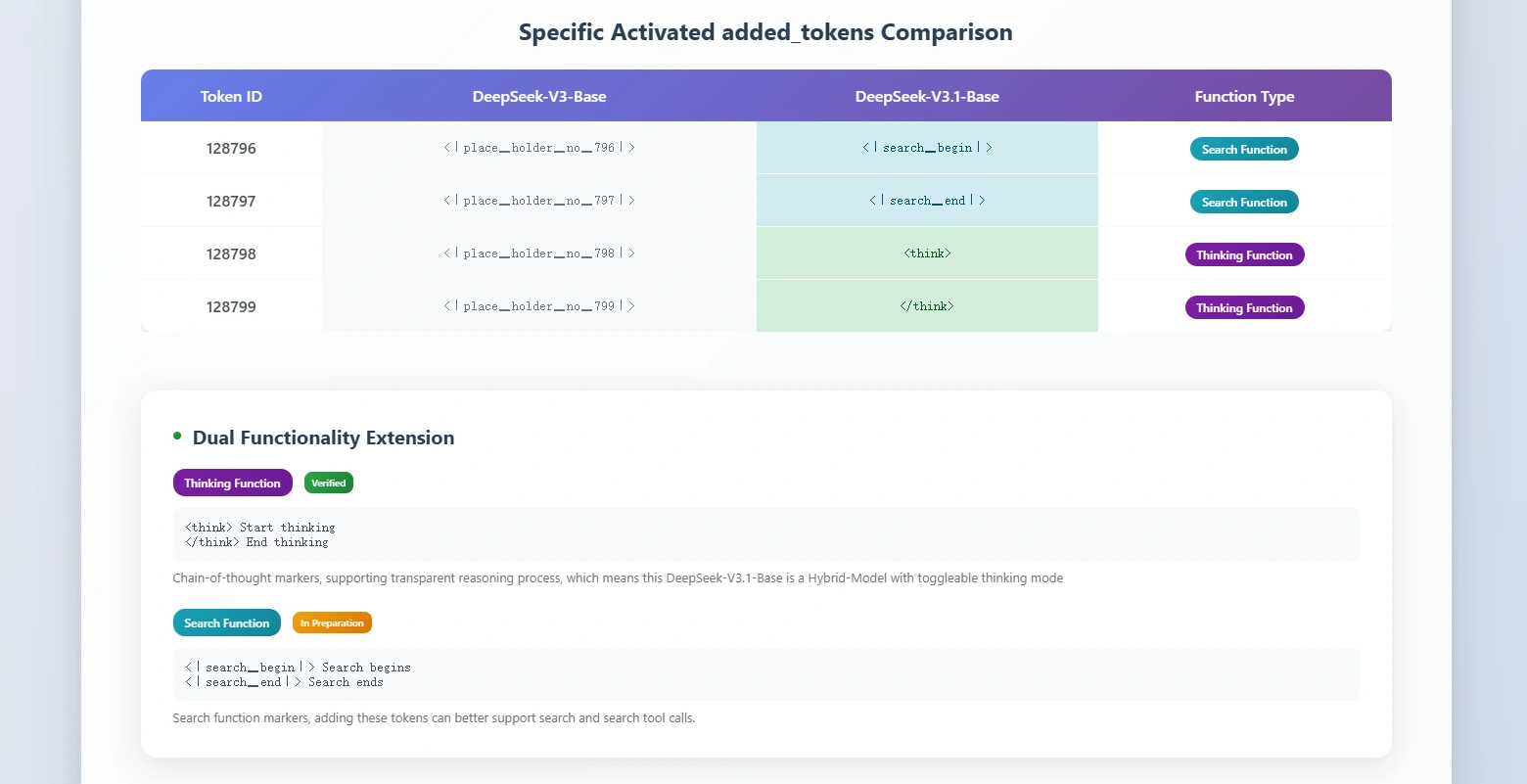
- Hybrid model with thinking mode: Adds a toggleable reasoning layer that strengthens problem-solving while aiming to avoid the usual performance drop of hybrids.
- Native search token support: Improves retrieval and search tasks, though community tests show the feature activates very frequently. A proper toggle is still expected in the official documentation.
- Stronger programming capabilities: Benchmarks place V3.1 at the top of open-weight coding models, confirming its edge in software-related tasks.
- Unchanged context length: The 128k-token window remains the same as in V3-Base, so you still get novel-length context capacity.
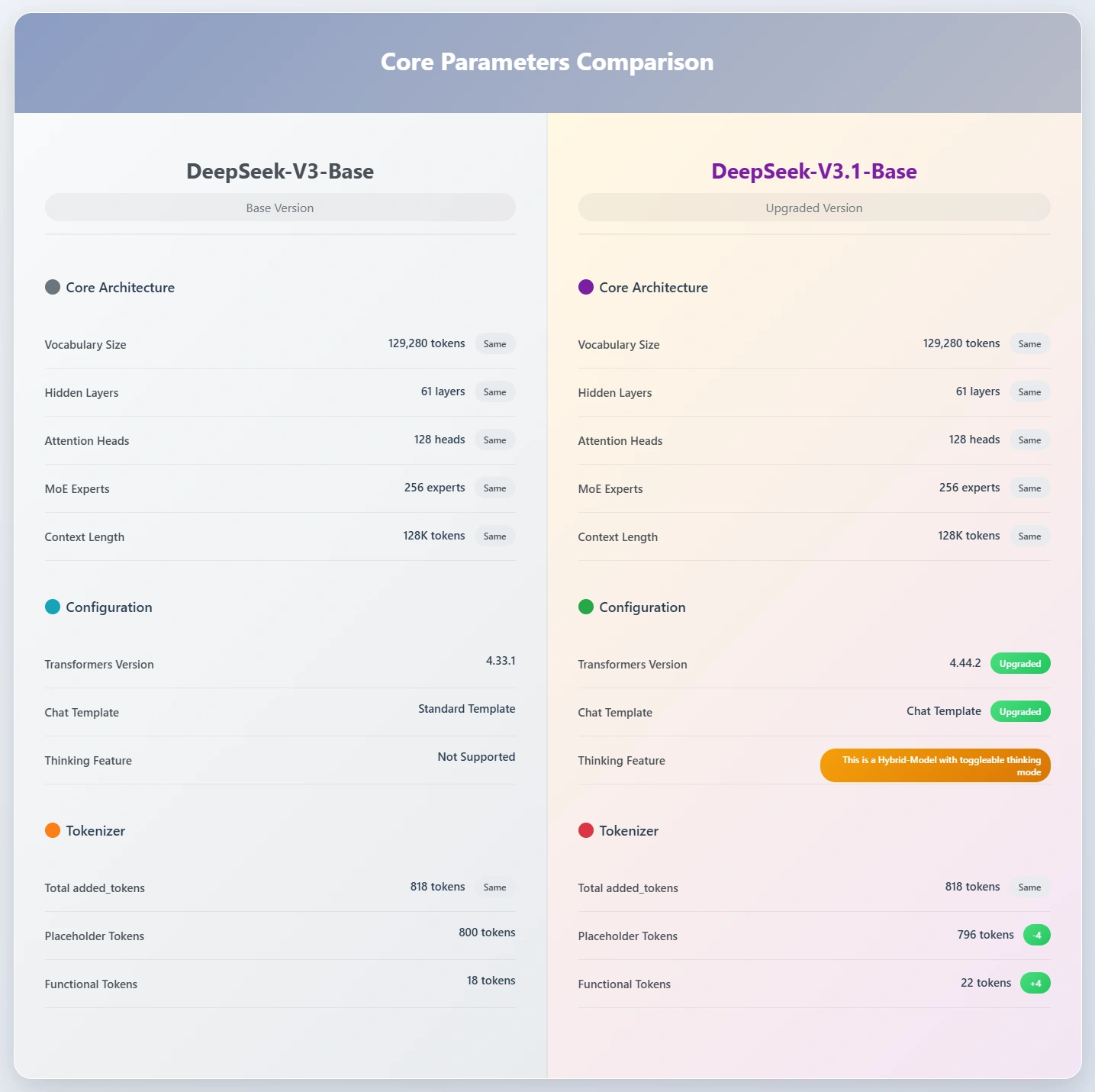
Taken together, these updates make V3.1 not just a scale-up, but a refinement.
Why people are paying attention
Here are some of the standout features of DeepSeek V3.1:
- Context window: 128k tokens. That’s the length of a full-length novel or an entire research report in one shot.
- Precision flexibility: Runs in BF16, FP8, or F32 depending on your hardware and performance needs.
- Hybrid design: One model that can chat, reason, and code without breaking context.
- Benchmark results: Scored 71.6% on the Aider coding benchmark, edging past Claude Opus 4.
- Efficiency: Performs at a level where some competitors would cost 60–70 times more to run the same tests.
- Open-Source: Probably the only open source model that is keeping up with the closed source releases.
Trying it out
Now we’d be testing DeepSeek V3.1 capabilities, using the web interface:
1. Long document summarization
A Room with a View by E.M. Forster was used as the input for the following prompt. The book is over 60k words in length. You can find the contents of the book at Gutenberg.
Prompt: “Summarize the key points in a structured outline.”
Response:
2. Step-by-step reasoning
Prompt: “Step-by-step reasoning
Work through this puzzle step by step. Show all calculations and intermediate times here. Keep units consistent. Do not skip steps. Double-check results with a quick check at the end of the think block.
A train leaves Station A at 08:00 toward Station B. The distance between A and B is 410 km.
Train A:
- Cruising speed: 80 km/h
- Scheduled stop: 10 minutes at Station C, located 150 km from A
- Track work zone: from the 220 km marker to the 240 km marker measured from A, speed limited to 40 km/h in that 20 km segment
- Outside the work zone, run at the cruising speed
.
. (Some parts omitted for brevity; Complete version can be seen in the following video)
.
Answer format (outside the think block only):
- Meet: [HH:MM], [distance from A in km, one decimal]
- Motion until meet: Train A [minutes], Train B [minutes]
- Final arrivals: Train A at [HH:MM], Train B at [HH:MM], First to arrive: [A or B]
Only include the final results and a one-sentence justification outside the think block. All detailed reasoning stays inside.”
Response:
3. Code generation
Prompt: “Write a Python script that reads a CSV and outputs JSON, with comments explaining each part.”
Response:
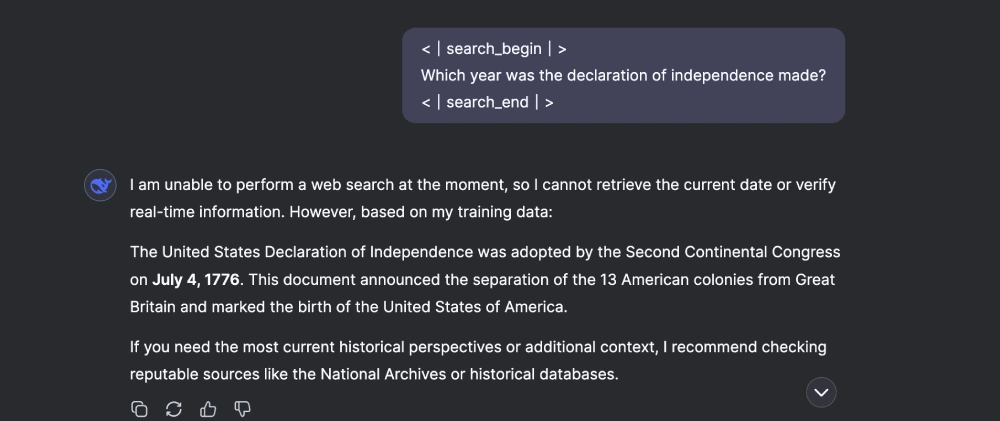
4. Search-style querying
Prompt: “<|search_begin|>
Which year was the declaration of independence made?
<|search_end|>”
Response:
5. Hybrid search querying
Prompt: “Summarize the main plot of *And Then There Were None* briefly.
Now, <|search_begin|> Provide me a link from where I can purchase that book. <|search_end|>. Finally, <think> reflect on how these themes might translate if the story were set in modern-day India? </think>”
Response:
Observation
Here are some of the things that stood out to me while testing the model:
- If the input length exceeds the limit, the part of the input would be used as an input (like in the first task).
- If tasks are basic, then the model goes overboard with overtly long responses (like in the second task).
- The tokens used to probe the search and reasoning capabilities aren’t reliable. Sometimes the model won’t invoke them, or else continue with its default prompt processing routine.
- The tokens
<|search_begin|>and<|search_end|>are part of the model’s vocabulary. - They act as hints or triggers to guide how the model should process the prompt. But since they’re tokens in the text space, the model often echoes them back literally in its output.
- Unlike an API “switch” that disappears behind the scenes, these tags are more like control instructions baked into the text stream. That’s why you’ll sometimes see them show up in the final reply.
Benchmarks: DeepSeek V3.1 vs Competitors
Community tests are already showing V3.1 near the top of open-source leaderboards for programming tasks. It doesn’t just score well—it does so at a fraction of the cost of models like Claude or GPT-4.
Here’s the benchmark comparison:
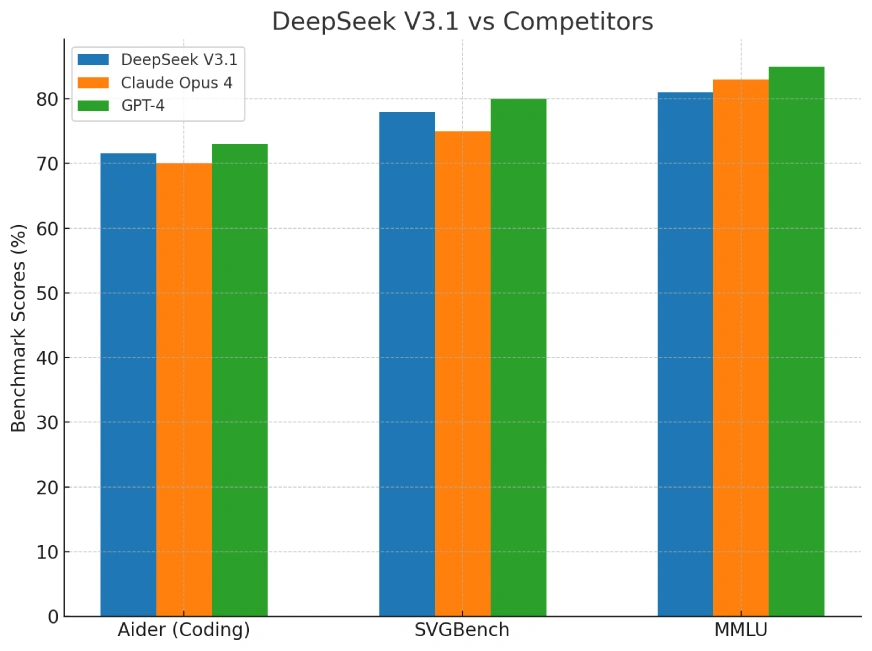
The benchmark chart compared DeepSeek V3.1, Claude Opus 4, and GPT-4 on three key metrics:
- Aider (coding benchmark)
- SVGBench (programming tasks)
- MMLU (broad knowledge and reasoning)
These cover practical coding ability, structured reasoning, and general academic knowledge.
Wrapping up
DeepSeek V3.1 is the kind of release that shifts conversations. It’s open, it’s massive, and it doesn’t lock people behind a paywall. You can download it, run it, and experiment with it today.
For developers, it’s a chance to push the limits of long-context summarization, reasoning chains, and code generation without relying solely on closed APIs. For the broader AI ecosystem, it’s proof that high-end capability is no longer restricted to just a handful of proprietary labs. We are no longer limited to selecting the correct tool for our use case. The model now does it for you, or could be suggested using defined syntax. This substantially increases the scope for different capabilities of a model being put into use for solving a complex query.
This release isn’t just another version bump. It’s a signal of where open models are headed: bigger, smarter, and surprisingly affordable.
Frequently Asked Questions
Q1. What makes DeepSeek V3.1 stand out compared to earlier models?
A. DeepSeek V3.1 introduces a hybrid reasoning mode, native search token support, and improved coding benchmarks. While its parameter count is slightly higher than V3, the real difference lies in its flexibility and refined performance. It blends chat, reasoning, and coding seamlessly while keeping the 128k context window.
Q2. How can someone access and use DeepSeek V3.1 today?
A. You can try DeepSeek V3.1 in the browser via the official DeepSeek website, through the API (deepseek-chat or deepseek-reasoner), or by downloading the open weights from Hugging Face. The web app is easiest for casual testing, while the API and Hugging Face allow advanced use cases.
Q3. What is special about the context window in DeepSeek V3.1?
A. DeepSeek V3.1 supports a massive 128,000-token context window, equal to hundreds of pages of text. This makes it suitable for entire book-length documents or large datasets. The length is unchanged from V3, but it remains one of the most practical advantages for summarization and reasoning tasks.
Q4. How do the special tokens like
<think> or <|search_begin|> work? A. These tokens act as triggers that guide the model’s behavior. <think> encourages step-by-step reasoning, while <|search_begin|> and <|search_end|> activate search-like retrieval. They often appear in outputs because they are part of the model’s vocabulary, but you can instruct the model not to display them.
Q5. How does DeepSeek V3.1 perform in benchmarks compared to rivals?
A. Community tests show V3.1 among the top performers in open-source coding benchmarks, surpassing Claude Opus 4 and approaching GPT-4’s level of reasoning. Its key advantage is efficiency—delivering comparable or better results at a fraction of the cost, making it highly attractive for developers and researchers.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






