It seems to be the season of new AI models. Right on the heels of the Gemini 3 announcement by Google, Grok has brought in a new model – Grok 4.1. Now available to all, the new Grok AI claims to bring “significant improvements to the real-world usability of Grok.” The rest of the announcement reads a tad bit too professional, especially considering it is Grok we talk about – the brainchild of the ‘notoriously famous for his witty humour’ Elon Musk.
Stress not, as I am here to break it down for you, piece by piece. In this article, we shall explore what the new Grok 4.1 brings to the table, how it compares to others, and how it fares in a review full of real-world tests performed by us. So without any further ado, let’s dive right into the nuances of this new model we call Grok 4.1.
Table of contents
What’s New With Grok 4.1
Did you read the “significant improvements” part above? This means Grok 4.1 isn’t just a predictable “slightly better, slightly faster” refresh. xAI is positioning this as the most capable Grok model to date. And just to stress how confident xAI is in the new model, know that it calls it “exceptionally capable” in creative, emotional, and collaborative interactions, as well as reliability. There are, of course, numbers to prove this.
As far as my experience with Grok goes, all of this basically means that Grok will finally feel less like a rebellious teenager who answers however it wants, and more like a cooperative grown-up who actually listens.
We are, of course, yet to test that out. All in time!
As per both internal and external testings, xAI says that Grok 4.1 delivers significant accuracy gains across math, coding, and advanced reasoning tasks. The model is designed to handle longer, more complex prompts without losing track of the conversation. This is especially something that its earlier versions struggled with. You also get better consistency in answers, especially in areas that require step-by-step reasoning or tool use.
With all the standard upgrades in place, there was only one thing left to improve on – hallucinations. xAI seems to have done that too with the Grok 4.1. The latest model is now more stable, meaning much less hallucination than ever before. This is further complemented by improved latency, leading to faster overall responses.
It seems like all of a sudden, Grok is not trying to be the funniest LLM on the internet anymore. It now wants to be the most reliable one.
But reliability requires solid numbers. Here are some that xAI shares.
Grok 4.1: Improvements Across Benchmarks
When xAI calls Grok 4.1 its “most capable model yet,” the numbers back it up. The model shows noticeable jumps across high-difficulty reasoning benchmarks, especially ones that stress multi-step logic, math, and coding accuracy.
Here’s how Grok 4.1 stacks up across popular benchmark evaluations:
Grok 4.1 Benchmark Performance
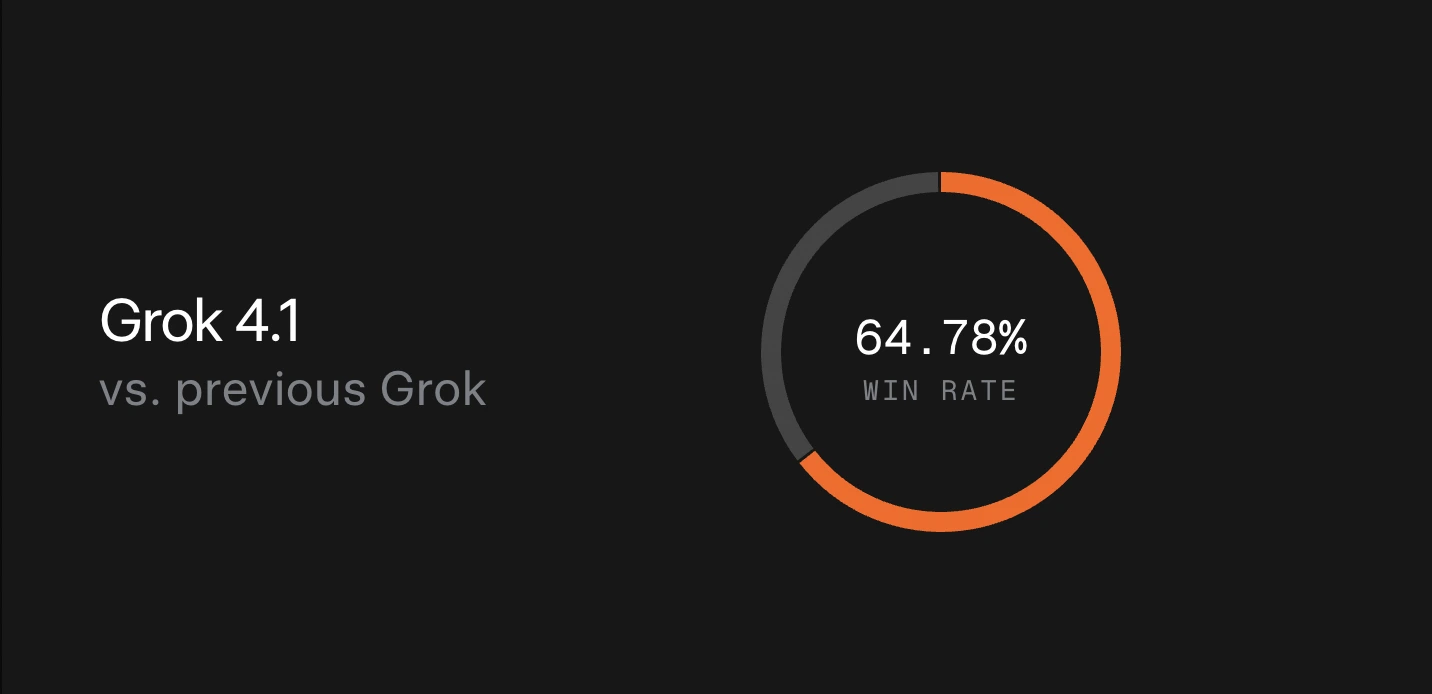
- 64.78% Win-Rate vs Previous Grok: In blind, real-traffic comparisons, Grok 4.1 is preferred nearly two-thirds of the time. This is a strong signal that users find its responses more helpful and reliable.
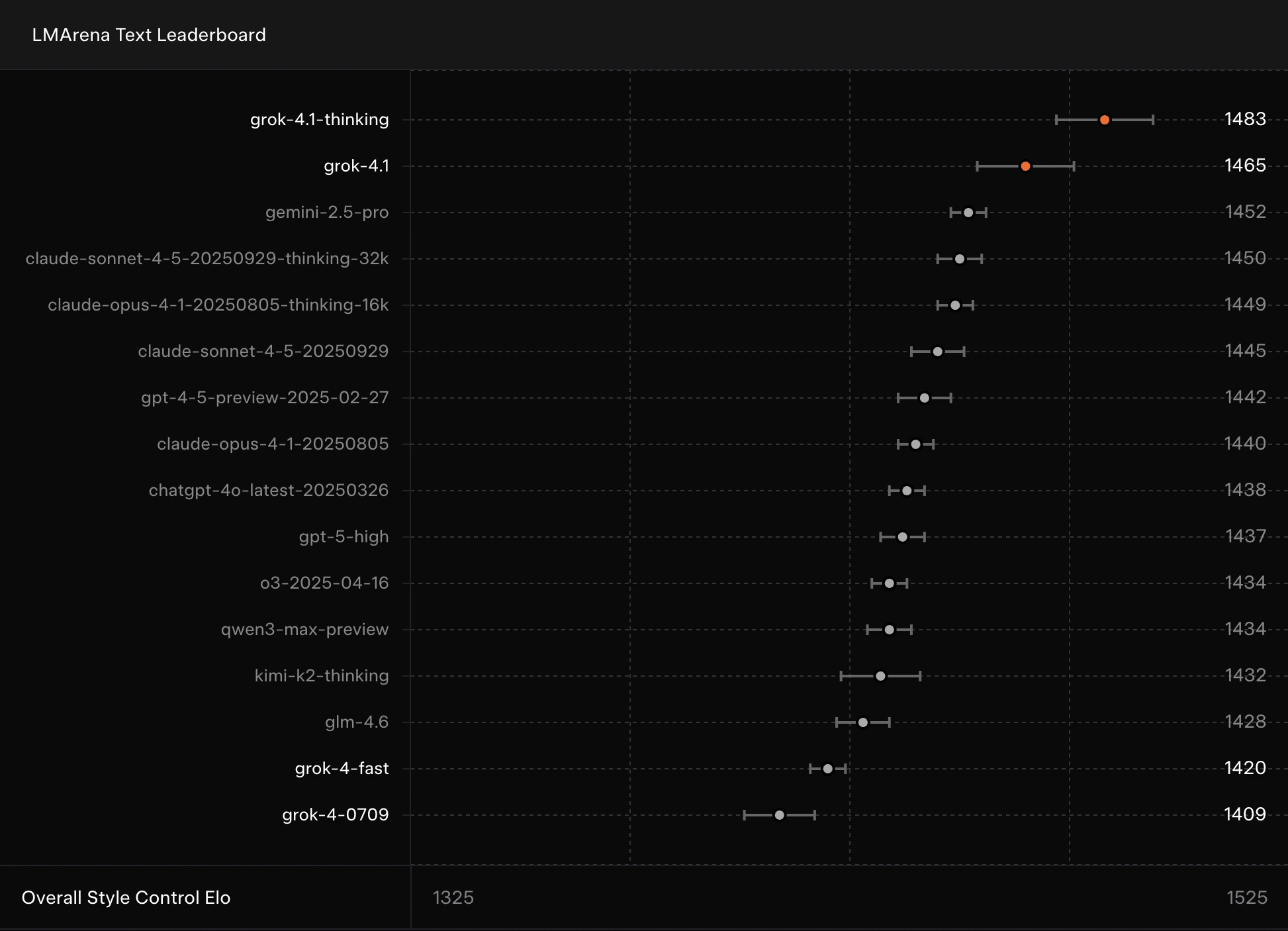
- #1 on LMArena Text Leaderboard (Thinking Mode): Grok 4.1 Thinking tops the chart with an Elo of 1483, followed by the non-thinking variant at 1465. Both rank above Gemini 2.5 Pro, Claude Sonnet/Opus variants, and GPT-4.5 preview models.
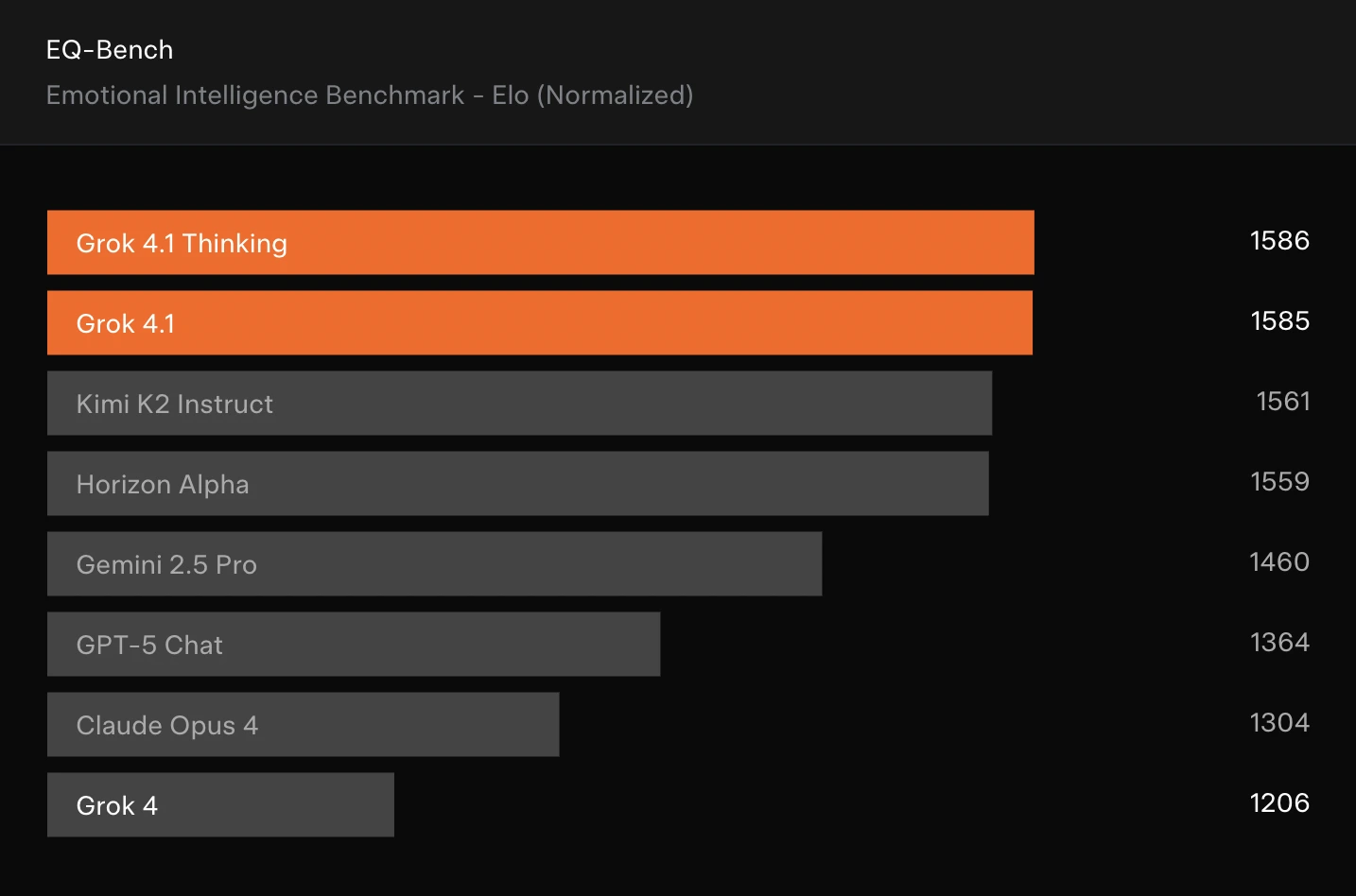
- Emotional Intelligence (EQ-Bench): Both variants again lead the board, ahead of Kimi K2 Instruct, Horizon Alpha, Gemini 2.5 Pro, GPT-5 Chat, and Claude Opus 4.
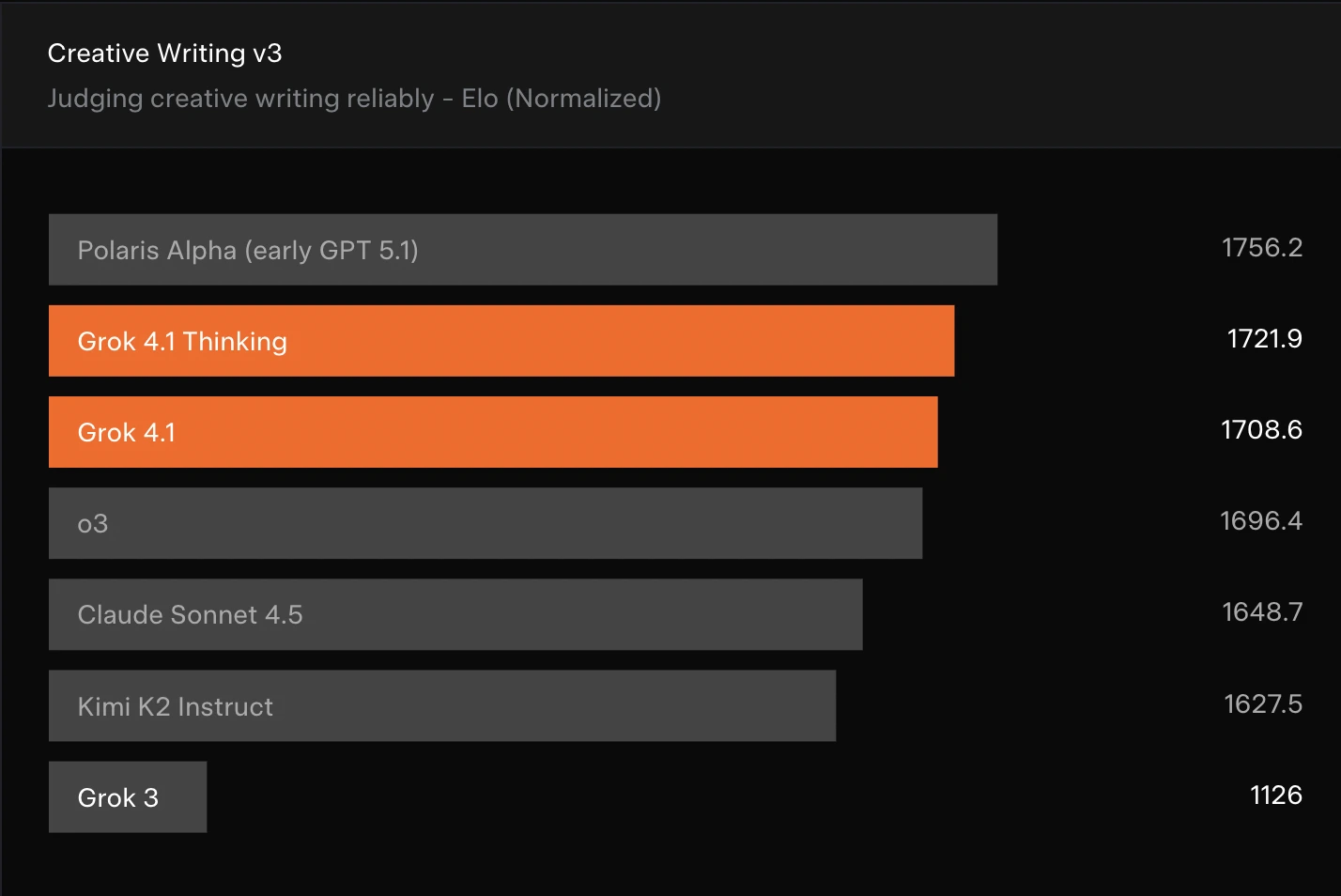
- Creative Writing (Creative Writing v3): Grok is comfortably placed in the top creative-writing models, outperforming o3 and Claude Sonnet 4.5, and far above Grok 3.
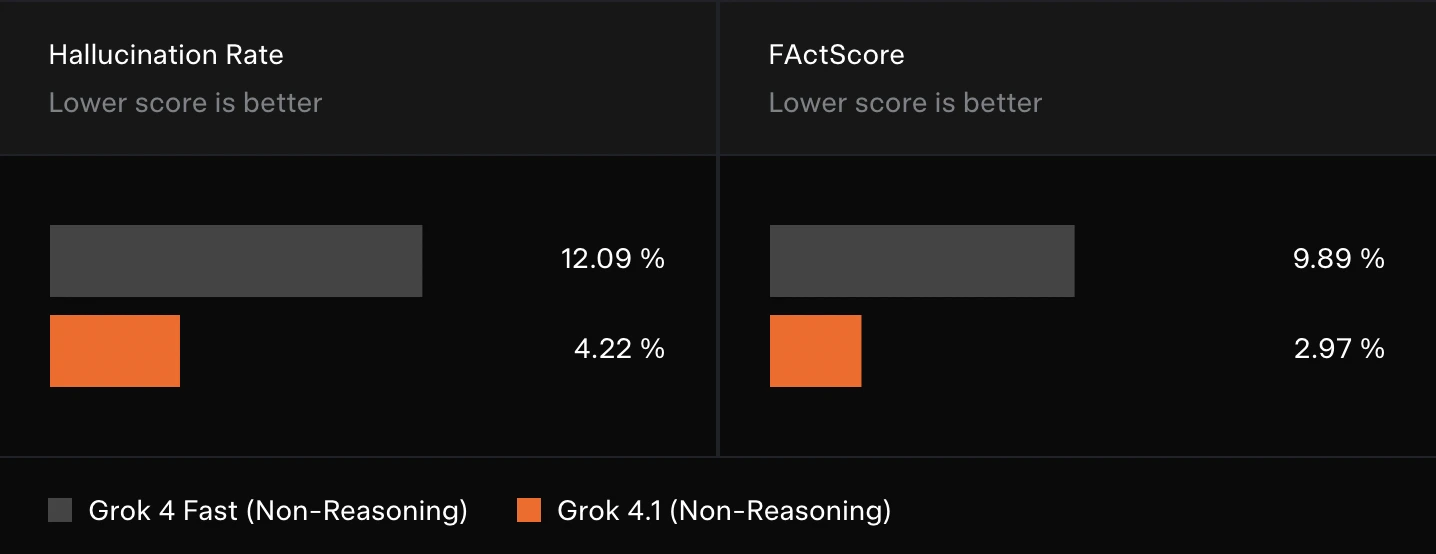
- Hallucination Rate: A dramatic drop in hallucination rate for Grok 4.1 indicates much more grounded responses.
- FactScore: It brings a major improvement in factual precision, especially in biography-oriented tasks.
You can check out these scores in the slideshow below:
Now that you know that the Grok 4.1 is indeed “capable,” here is how you can access it.
Grok 4.1 Pricing and Availability
Unlike many new AI models that hide behind “waitlists” and mysterious access tiers, Grok 4.1 is now available to all users on grok.com, X, and the iOS and Android apps for smartphones. For Tesla owners, it is also rolling out immediately in Auto mode and can be selected explicitly as “Grok 4.1” in the model picker.
As for the pricing, you know it is accessible when it is Elon Musk. Here is the pricing structure:
- Basic plan for Grok: Provides limited access to Grok 4.1, with a limited context memory.
- SuperGrok (Rs 700/ month): This is the real entry point for better access to Grok 4.1. You get increased access to the new model, better reasoning and search capabilities, extended memory (128K tokens), priority voice access, the Imagine image model, and access to companions Ani & Valentine.
- SuperGrok Heavy ($300/ month): A power-user tier offering extended access to Grok 4.1, plus an exclusive preview of Grok 4 Heavy. You also get unlimited Grok 3 usage, the longest memory window (256K tokens), and early access to upcoming features.
In short: Grok 4.1 is fully accessible today. However, you can only access it for a longer period if you’re subscribed to SuperGrok or above. The best part is that casual users can still stay on the basic Grok plan and have a taste of it.
Under the Hood: How Grok 4.1 Works
xAI doesn’t reveal every tiny detail of Grok’s internals, but the announcement gives us enough to piece together the big picture. Grok 4.1 is built on the same core lineage as previous Grok models. Though there are major system-level upgrades aimed at making the model more stable, more accurate, and more predictable in real-world tasks. Think of it less as a new engine and more as a highly tuned version of the Grok architecture that finally delivers consistent performance.
xAI mentions improvements in training efficiency, longer-context handling, and better tool-use reliability. These upgrades allow Grok 4.1 to stay coherent across large prompts, execute more precise step-by-step reasoning, and follow instructions with far less drift. The model also benefits from cleaner data pipelines and enhanced training signals, which reduce hallucinations and keep responses closer to ground truth.
Want it in simple words? Grok 4.1 is not a flashy architectural makeover – it is a smarter, more disciplined evolution of the Grok model. Know that it is engineered to behave better under pressure and produce output you can actually trust.
Though trust is hard to gain without a first-hand experience. So here is our hands-on trial with Grok 4.1 across use cases.
Grok 4.1 Review: Hands-on Tests
We tested Grok 4.1 for the most common use-cases in the world of AI tools. Here are is a look at how it fared in our tests.
Task 1: Text Generation
Prompt: “Write a short story (120–150 words) set in a near-future India where everyday life is powered by AI. The story must follow all of these rules:
– The tone should be hopeful, not utopian.
– Include exactly one named character.
– Mention a specific AI technology that exists today (e.g., LLMs, autonomous drones, vision models).
– End with a single-line moral that is not more than 8 words.
– Avoid clichés like ‘technology changed everything’. Make the writing vivid, grounded, and emotionally engaging.”
Output:
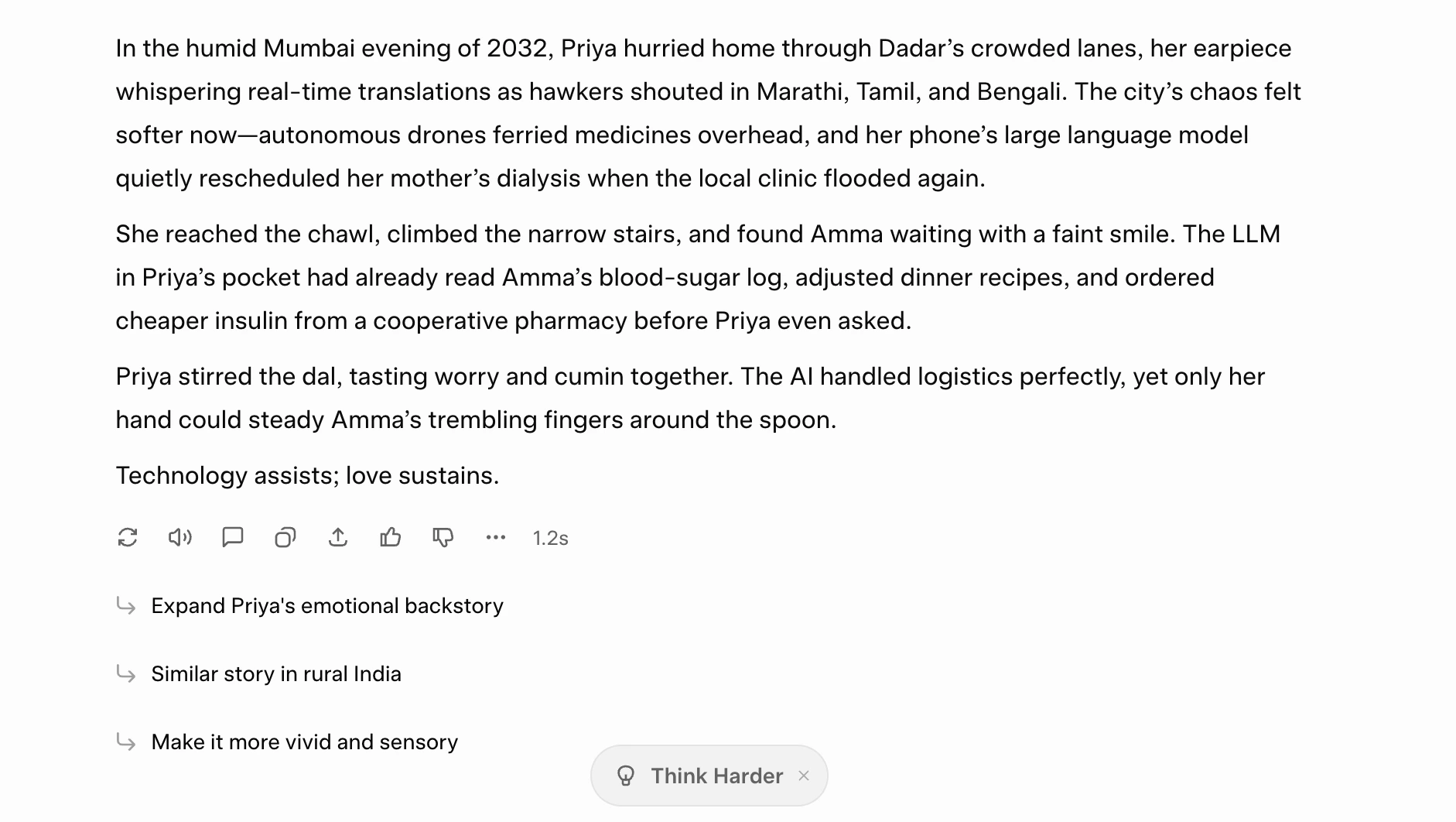
My take: Ok, I don’t say this often, but I think this is some of the best AI-produced writing I have come across lately. It follows all the instructions to the point, and the text clearly retains Grok’s renowned human-like feel. 10/10 for text generation to Grok 4.1.
Task 2: Image Generation
Prompt: “Can you generate an image to go along with the story above.“
Output:

My take: Not too good. While the images produced are quite detailed and set up the scene nicely, the overall narrative they present simply lacks logic and are borderline absurd. There are much better image generation AI tools out there.
Task 3: Video Generation
I simply used the “Make Video” option on the images generated above.
Output:
My take: Again, I am sure simply animating photos to the point of a video that does not make any sense is of no use to anyone. So even though the graphics are on-point, the lack of logic is glaringly obvious. You can probably do better with these video generation AI tools available online.
Task 4: Reasoning
Prompt: “I have three boxes:
– One box contains only apples
– Another contains only oranges
– A third box contains a mix of apples and oranges“All three boxes are incorrectly labeled. You are allowed to open only one box and pick only one fruit from it. Explain which box you should pick from, what fruit you expect, and how this single observation lets you correctly relabel all three boxes. Provide your explanation in no more than 6 sentences.
Output:
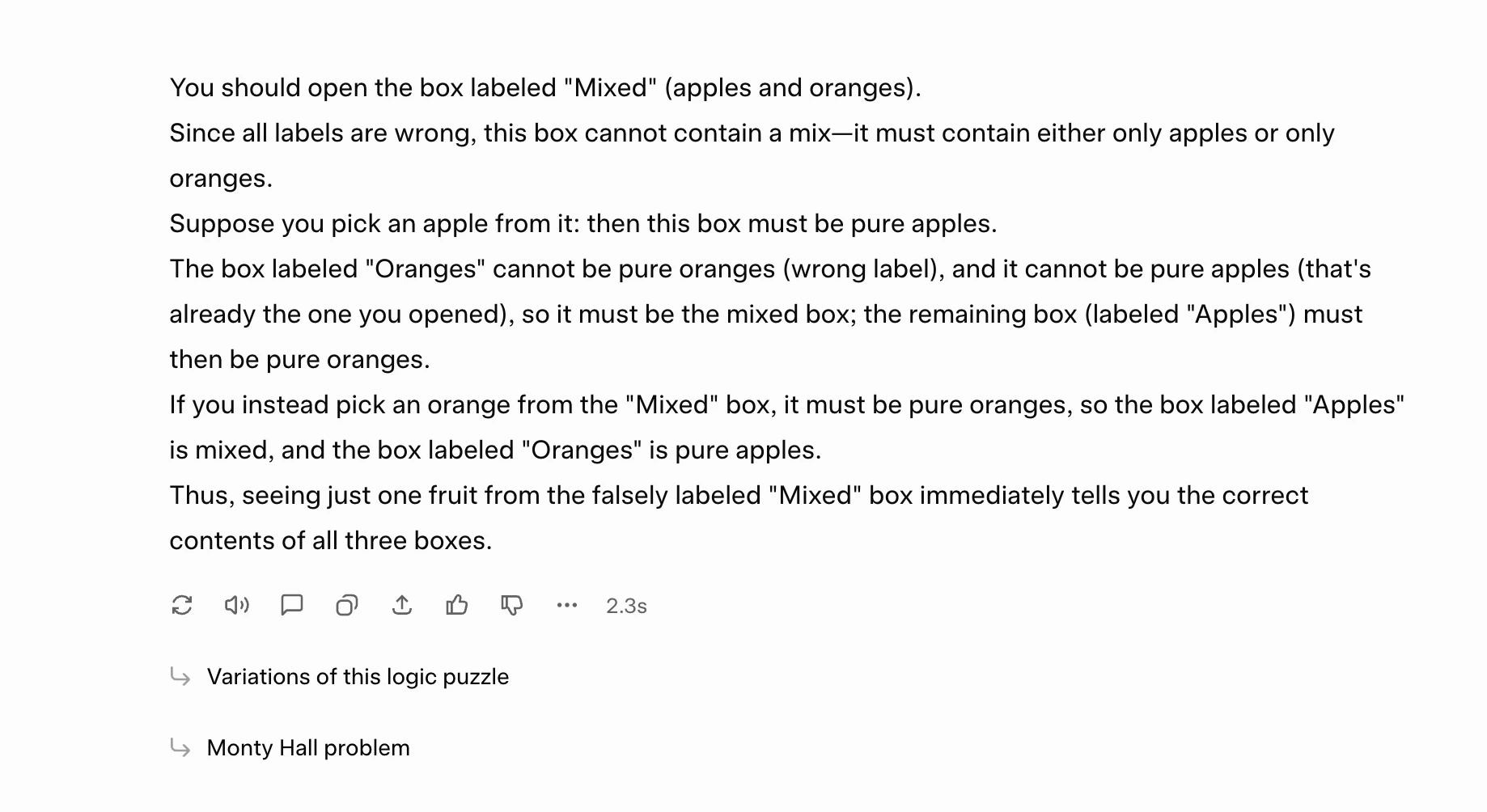
My take: It was a simple problem, and Grok 4.1 seems to have managed it quite well, complete with detailed reasoning for each step. I don’t see a reason why it would perform any differently for any other problem.
Task 5: Coding
Prompt: “Write a Python function group_anagrams(words: list[str]) -> list[list[str]] that groups words which are anagrams of each other.
Requirements:
– Words that are anagrams must appear in the same inner list.
– The order of groups does not matter, but words inside each group must be sorted alphabetically.
– The solution should be efficient for up to 10⁵ words.
– Add a short docstring and at least two example test cases in a if __name__ == “__main__”: block.
Explain your approach in 3–4 sentences after the code.“
Output:
def group_anagrams(words: list[str]) -> list[list[str]]:
"""
Groups a list of words into sublists where each sublist contains anagrams.
Words within each group are sorted alphabetically.
Returns a list of these groups (order of groups does not matter).
"""
from collections import defaultdict
groups = defaultdict(list)
for word in words:
# sorted(word) is O(k log k) where k = len(word)
key = tuple(sorted(word))
groups[key].append(word)
# Sort each group alphabetically and return
result = []
for anagram_list in groups.values():
result.append(sorted(anagram_list))
return result
if __name__ == "__main__":
# Test case 1
assert group_anagrams(["eat","tea","tan","ate","nat","bat"]) == [
["ate", "eat", "tea"], ["nat", "tan"], ["bat"]
]
# Test case 2
assert group_anagrams(["","b"]) == [[""], ["b"]]
print("All tests passed!")Approach: We use a hashmap where the key is the sorted version of each word (as a tuple for hashability) and the value is the list of original words that sort to that key. This canonical representation groups all anagrams together in O(n · k log k) time, which is efficient for n ≤ 10⁵ and typical word lengths. Finally, we sort the words inside each group alphabetically before returning the result.
My take: Grok 4.1 is completely on-point with the code and the approach it took to get there. With this, and the fact that it comes from a team spearheaded by the most renowned tech genius of our times, I am sure Grok 4.1 will deliver nothing short of accurate in this regard.
Conclusion
Grok 4.1 marks a clear turning point for xAI. What was once a model known mainly for its personality now finally shows up with the raw intelligence, consistency, and stability needed to compete in the big league. With noticeable improvements, the new xAI model feels less like an experimental side-project and more like a model genuinely built for real-world work.
Its performance across benchmarks, cleaner architectural tuning, and stronger instruction-following put it within striking distance of today’s leading LLMs. And our hands-on tests reinforce that this version of Grok is genuinely usable – not just clever, not just witty, but genuinely capable.
Will it dethrone OpenAI or Anthropic overnight? Probably not.
But with Grok 4.1, xAI finally seems to be giving them a run for their money. And that alone makes the next chapter of the AI race a lot more interesting.





