If you’re even slightly obsessed with AI voice models, Qwen3-TTS-Flash is one you shouldn’t miss. It’s the new flagship text-to-speech system from Qwen, designed to generate natural, expressive, human-like speech across 49+ sounds, 10 languages, and 9 Chinese dialects. This model is built for creators, developers, educators, and anyone who wants studio-quality voices without hiring voice actors or buying expensive tools.
And the best part? You can use it directly through the Qwen API.
In this article, I explain what makes the model special, why these updates matter, and how you can use it.
Table of contents
What’s New in Qwen3-TTS Flash?
Qwen3-TTS-Flash is a flagship text-to-speech model released as part of the Qwen3 series. It focuses on natural, expressive, multilingual voice generation. The model supports multi-timbre, multi-lingual, and multi-dialect synthesis, which means you can generate speech in different styles, accents, and languages using the same model.
Unlike older TTS systems, Qwen3-TTS-Flash does not only read the text. It understands tone, pacing, emotion, personality, and intent. The outputs sound calm, dramatic, lighthearted, childish, authoritative, warm, or playful. It responds to both the content of the text and the style you want.
Over 49 High-Quality Sounds
The first thing that sets Qwen3-TTS-Flash apart is the range of voices. The model supports 49 expressive timbres. These are not simple voices. They are fully-built character personalities with emotional range and identity.
You get soft conversational voices, deep mature voices, childlike tones, anime-style characters, warm narrators, strict instructors, friendly companions, and more. This makes it useful for learning apps, podcasts, game characters, brand videos, storytelling, and virtual assistants.
Some examples include:
- Momo, who sounds energetic and playful
- Ono Anna, who sounds friendly and warm
- Vivian, who has a proud, confident tone
- Eldric Sage, who sounds older and wiser
- Bunny, who sounds cute and expressive
- Elias, who speaks in a strict and formal manner
Each voice carries personality. You can feel the differences in attitude, age, and energy. Many other TTS models sound like they use the same base voice with different filters. Qwen3-TTS-Flash actually builds characters.
Also Read: 9 Best Open Source Text-to-Speech (TTS) Models
True Multilingual Speech Synthesis
Qwen3 TTS Flash works across 10 major languages. These include Chinese, English, German, Italian, Portuguese, Spanish, Japanese, Korean, French, and Russian. The model performs well in accuracy tests. It achieves a lower word error rate than systems like MiniMax, ElevenLabs, and GPT 4o Audio Preview. This is a big advantage for teams that create global content or products.
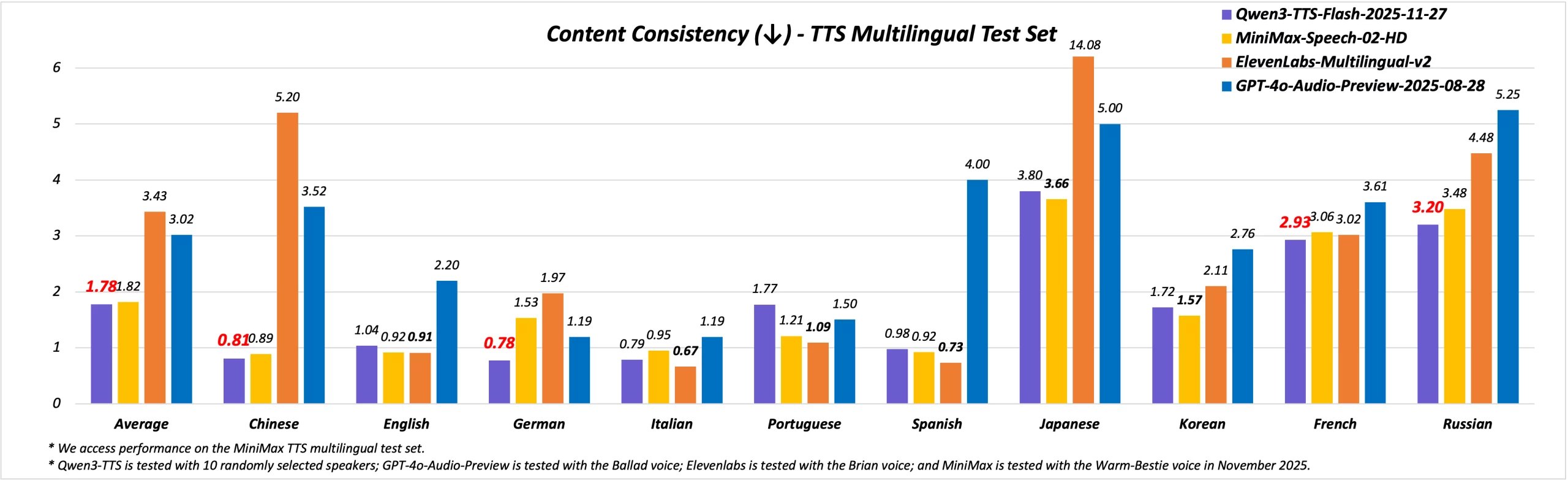
Dialects
This model doesn’t just handle languages, it nails dialects beautifully.
It supports:
- Mandarin
- Cantonese
- Hokkien
- Sichuanese
- Shaanxi
- Wu
- Beijing
- Tianjin
- Nanjing
Regional speech is recreated with correct tone, rhythm, cadence, slang, and the charm that usually gets lost in generic TTS models.
Better Speech Rate Control
Earlier TTS models often struggled with prosody, resulting in voices that felt mechanical or overly flat. Qwen3-TTS-Flash takes a major leap forward by improving this significantly. Instead of reading text in a uniform rhythm, the model adjusts tone and pacing based on meaning. Pauses appear naturally at moments where a human speaker would stop. Emotional sections receive subtle emphasis, and the model shifts speed depending on the mood of the sentence.
The rhythm feels natural. The speech rate adapts. The output is smooth and easy to listen to.
How to Access Qwen TTS Model?
You can access Qwen3-TTS in 2 ways depending on your workflow:
Using the Qwen API
This is the official and most reliable method.
You simply need:
- A DashScope API key from the Alibaba Cloud platform
- The DashScope Python SDK
Example Code:
import os
import requests
import dashscope
text = "Let me recommend a T shirt to everyone. This one is really good looking and the color is classy."
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash-2025-11-27",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Ryan",
language_type="English",
stream=False
)
audio_url = response.output.audio.url
save_path = "audio.wav"
try:
r = requests.get(audio_url)
r.raise_for_status()
with open(save_path, 'wb') as f:
f.write(r.content)
print("Saved to", save_path)
except Exception as e:
print("Error:", str(e))
Using Hugging Face (Free Trial)
Qwen provides a free demo on Hugging Face Spaces where you can:
- Paste text
- Select a voice
- Listen or download the generated audio
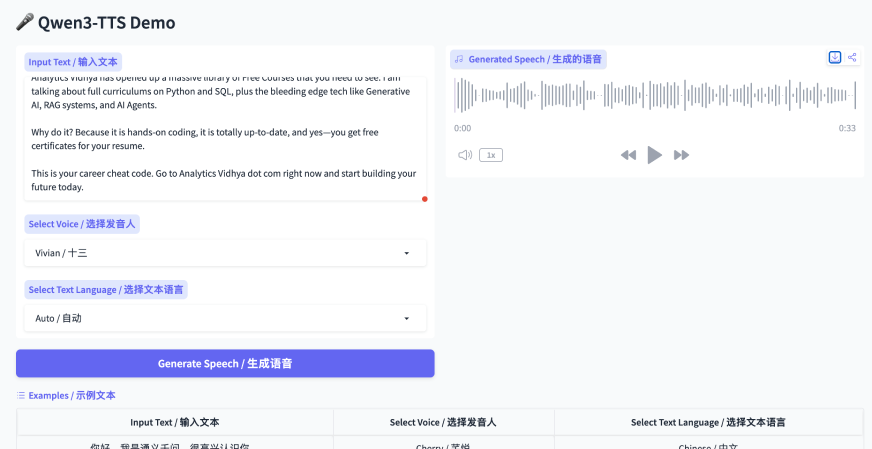
This version is good for testing, but the paid API gives much higher fidelity, more stable prosody, and faster generation. Click here to try it out!
Let’s Try it Out!
To understand how Qwen3-TTS-Flash performs in real scenarios, I tested it on three different scripts using three different voices. Each task targets a unique speaking style: promotional, narrative, and professional career guidance. Here is what I found.
Task 1: Promotional Script (Voice: Vivian, Language: English)
Script Used:
Stop scrolling for a second. If you are hearing this, you need to stop paying for expensive AI bootcamps.
Analytics Vidhya has opened up a massive library of Free Courses that you need to see. I am talking about full curriculums on Python and SQL, plus the bleeding edge tech like Generative AI, RAG systems, and AI Agents.
Why do it? Because it is hands-on coding, it is totally up-to-date, and yes—you get free certificates for your resume.
This is your career cheat code. Go to Analytics Vidhya dot com right now and start building your future today.
Output:
My Review
Vivian’s timbre handled this promo-style script extremely well. The energy was clear without sounding overdramatic. The model maintained a steady pace, emphasized the right phrases, and delivered a convincing call-to-action. The pronunciation was crisp, and the transitions between sentences felt natural. This output is strong enough for marketing videos, Instagram reels, or YouTube ads without requiring additional editing.
Task 2: Narrative + Reflective Script (Voice: Chelsie, Language: English)
Script Used:
Imagine waking up to a world where your schedule simply manages itself. No more jarring alarms, just a gentle rise in lighting to start your day.
In the modern era, artificial intelligence isn’t just a buzzword; it is woven into the fabric of our daily lives. From organizing complex data at 5G speeds to driving autonomous vehicles, automation is the new standard.
But the important question remains: does this technology bring us closer together, or does it drive us further apart? It is time to rethink how we connect in the digital age. Welcome to the next chapter.
Output:
My Review:
Chelsie handled the reflective tone beautifully. The voice carried emotional warmth, perfect for storytelling, product demos, or documentary-style videos. The pacing slowed at the right moments, giving the script a thoughtful and cinematic feel. The pauses and stress patterns sounded very human, with no robotic artifacts. This is ideal for narration or brand storytelling.
Task 3: Career-Focused Script (Voice: Ryan, Language: English)
Script Used:
Generative AI isn’t just a buzzword; it is the fastest-growing career track in tech history.
Let’s talk numbers. The demand for GenAI engineers has exploded, but the talent pool is nearly empty. That is why companies are paying massive premiums—with specialized roles easily clearing one hundred and fifty thousand dollars a year.
From finance to healthcare, every industry is desperate to integrate LLMs and agents. If you want a career that offers future-proof security and leverage, this is it.
The best time to pivot was yesterday. The second best time is right now. Start building.
Output:
My Review:
Ryan’s voice delivered a strong professional tone with just the right level of authority. The model emphasized career-focused phrases effectively while maintaining a smooth, confident delivery. This output sounds like something directly from a modern tech explainer or LinkedIn learning module. No noticeable distortion or pacing issues, making it ready for podcast intros, career guidance videos, or tech ads.
Performance and Practical Value
The model is fast, expressive, and reliable. It produces natural speech with strong clarity. It supports long texts and works well inside applications. The low word error rate makes it suitable for professional audio use cases.
Because it comes through an API, developers can integrate it into:
- Mobile apps
- Web apps
- Learning platforms
- Games
- Chatbots
- Customer support flows
- Voice agents
- Video scripts
It is one of the few TTS models that combines scale, expression, multilingual output, and character voices in a single package.
Also Read:
- Multilingual Text-to-Speech Models for Indic Languages
- Dia-1.6B TTS : Best Text-to-Dialogue Generation Model
- Bulbul-V2 by Sarvam AI: India’s Best TTS Model with Support for 11 Indian Languages
- Kokoro-82M: Compact, Customizable, and Cutting-Edge TTS Model
Conclusion
Qwen3-TTS-Flash is one of the most capable multilingual TTS systems currently available. With its huge timbre library, natural prosody, strong dialect support, and fast generation, it’s built for both everyday creators and large-scale enterprise use. Whether you’re narrating a video, building a voicebot, or crafting character dialogues, this model is powerful, flexible, and extremely easy to use through the API.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.





