OpenAI is out with a major update, building on its GPT-5 series with the all-new GPT-5.4. Introduced as GPT-5.4 Thinking, the model will also come with a GPT-5.4 Pro version for those seeking “maximum performance” on complicated tasks. Even the base version comes with a plethora of improvements over the outgoing GPT-5.2. These upgrades range across reasoning, coding, and agentic workflows, along with some nifty little features that users are sure to love.
For instance, OpenAI says that the GPT-5.4 Thinking will let you adjust the course of its thinking in the middle of a response. This means more appropriate results for your queries. Other than this, it carries improvements in deep web search and larger context windows. All in all, higher-quality, more accurate answers in less time.
Here, we explore all these features and benchmark performances of the new GPT-5.4 Thinking in detail, starting right with what the AI model is all about.
Also read: New Update Makes GPT-5.3 Instant More Useful For Everyday Tasks
Table of contents
What is GPT-5.4?
Just like with every new AI model, OpenAI uses the term “most capable and efficient frontier model” while introducing GPT-5.4 in its blog. However, there is a follow-up term that sheds a much brighter light on its nature. The adjectives above are used specifically in reference to “professional work.” Which means that the GPT-5.4, unlike earlier models that primarily pushed conversational intelligence, comes as a dedicated AI model for professionals.
For this, it brings improvements in reasoning, coding, and agentic workflows into a single system that is meant to handle real tasks across software tools and digital environments. Yet another highlight is its support for a massive context window of up to 1 million tokens. This allows the model to process long documents, datasets, and multi-step workflows without losing track of the task. On top of that, OpenAI says GPT-5.4 is its most token-efficient reasoning model yet, using significantly fewer tokens than GPT-5.2 to arrive at answers.
The list of features does not end here. Next, let’s look at all the key features that the GPT-5.4 carries.
Also read: I Tried GPT 5.2 and This is How It Went..
Key Highlights of the GPT-5.4 Family
Here are the key highlights of the GPT-5.4 family.
1. Native Computer Use and Stronger Vision Capabilities
One of the biggest upgrades in GPT-5.4 is its ability to interact with computers and visual interfaces more effectively. The model introduces native computer-use capabilities, allowing AI agents to operate software environments and execute workflows across applications. Combine this with stronger vision abilities, and the GPT-5.4 can better interpret screenshots, documents, and UI elements. This enables it to navigate systems, extract information, and complete tasks that require both visual understanding and action across tools.
2. Smarter Tool Discovery and Usage
GPT-5.4 also improves how models interact with large ecosystems of tools and connectors. It introduces something called “tool search,” which helps the model identify and use the right tools within complex environments. Instead of relying solely on predefined integrations, GPT-5.4 can dynamically discover the tools needed to complete a task. This makes it easier to build AI systems that work across multiple services without sacrificing reasoning capability.
3. Improved Performance on Knowledge Work
A major focus of GPT-5.4 is handling professional knowledge work more reliably. The model shows stronger performance on tasks involving spreadsheets, presentations, and long documents, where maintaining context and accuracy is critical. According to OpenAI’s evaluations, GPT-5.4 significantly improves output quality on these types of tasks, producing more polished results while requiring fewer corrective prompts from users.
4. Stronger Coding and Developer Workflows
GPT-5.4 also builds on the coding strengths introduced in GPT-5.3-Codex. The model maintains strong performance on software engineering benchmarks while improving its ability to handle longer development workflows. This allows it to assist with debugging, writing code across multiple files, and coordinating tasks that require reasoning across large codebases.
5. Greater Control Through Steerability
Another improvement comes in the form of better steerability, especially in ChatGPT. With GPT-5.4 Thinking, the model can present an upfront reasoning plan before producing its final output. This allows users to guide the direction of the response while it is still being generated, reducing the need for repeated prompts and making complex tasks easier to manage.
6. Expanded Cyber Safety Stack
Finally, GPT-5.4 introduces an expanded cyber safety stack designed to reduce harmful or unsafe outputs. OpenAI has strengthened safeguards against malicious use while improving the model’s ability to refuse inappropriate requests. These upgrades aim to make the system more reliable and secure when deployed across enterprise and developer environments.
With these claims, OpenAI has also shared some strong benchmark performance results of the GPT-5.4. Let’s have a look at them here.
GPT-5.4 – Benchmark Performance
Benchmarks are often where the real story of a new AI model begins to show up. And in the case of GPT-5.4, the numbers suggest that OpenAI’s focus on professional work is not just marketing language. Across several categories, from finance and coding to tool usage and reasoning, the model consistently edges past its predecessors.
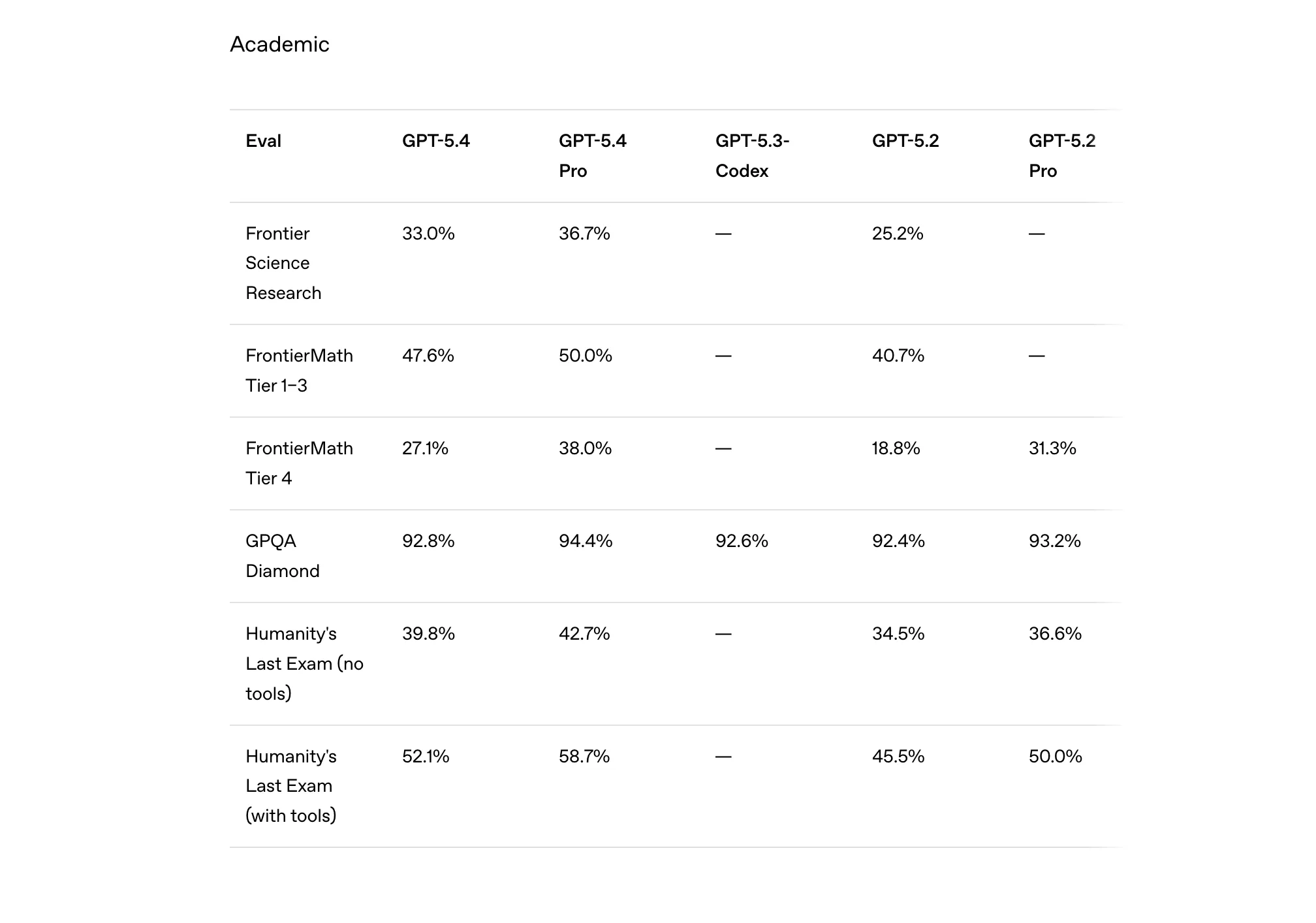
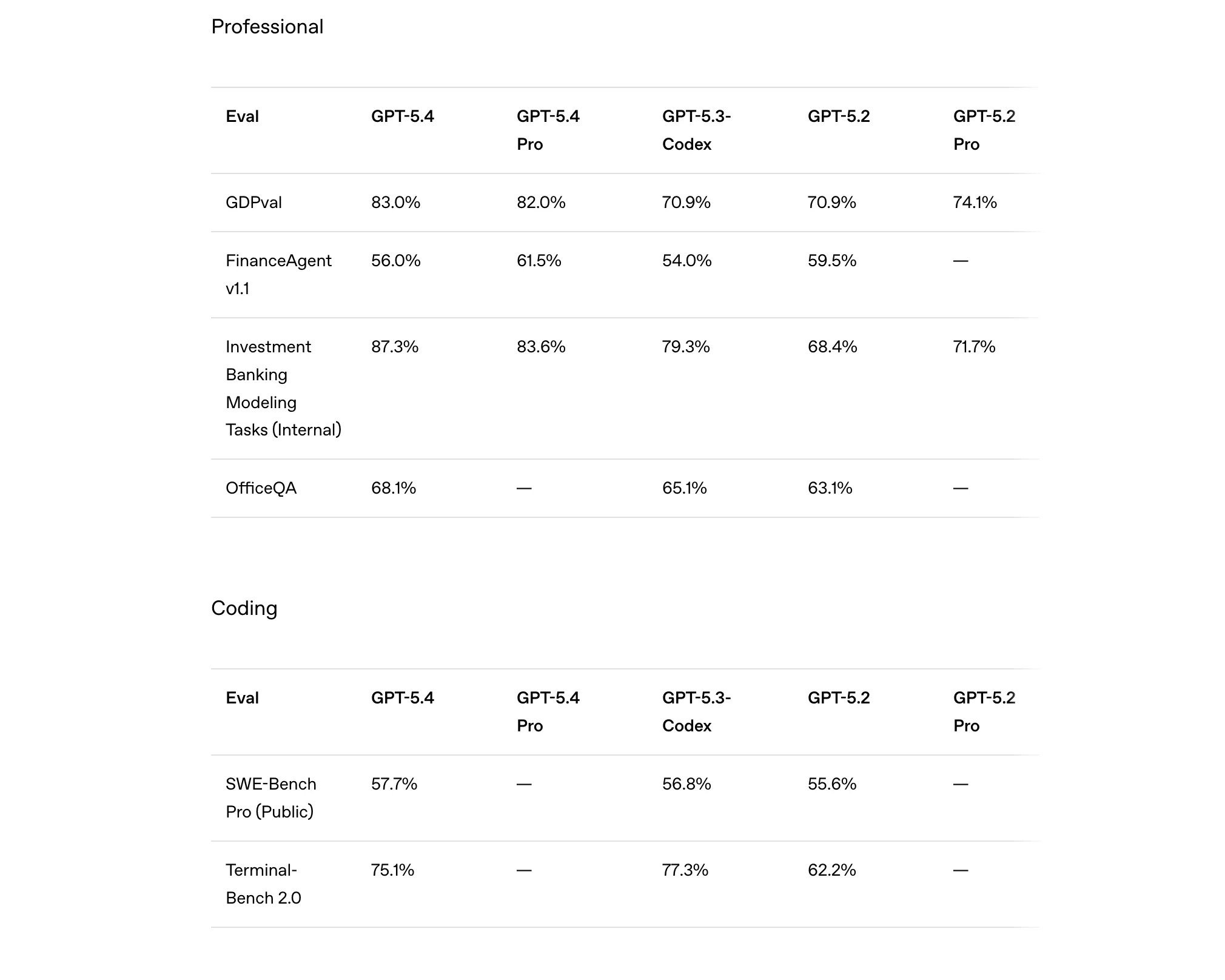
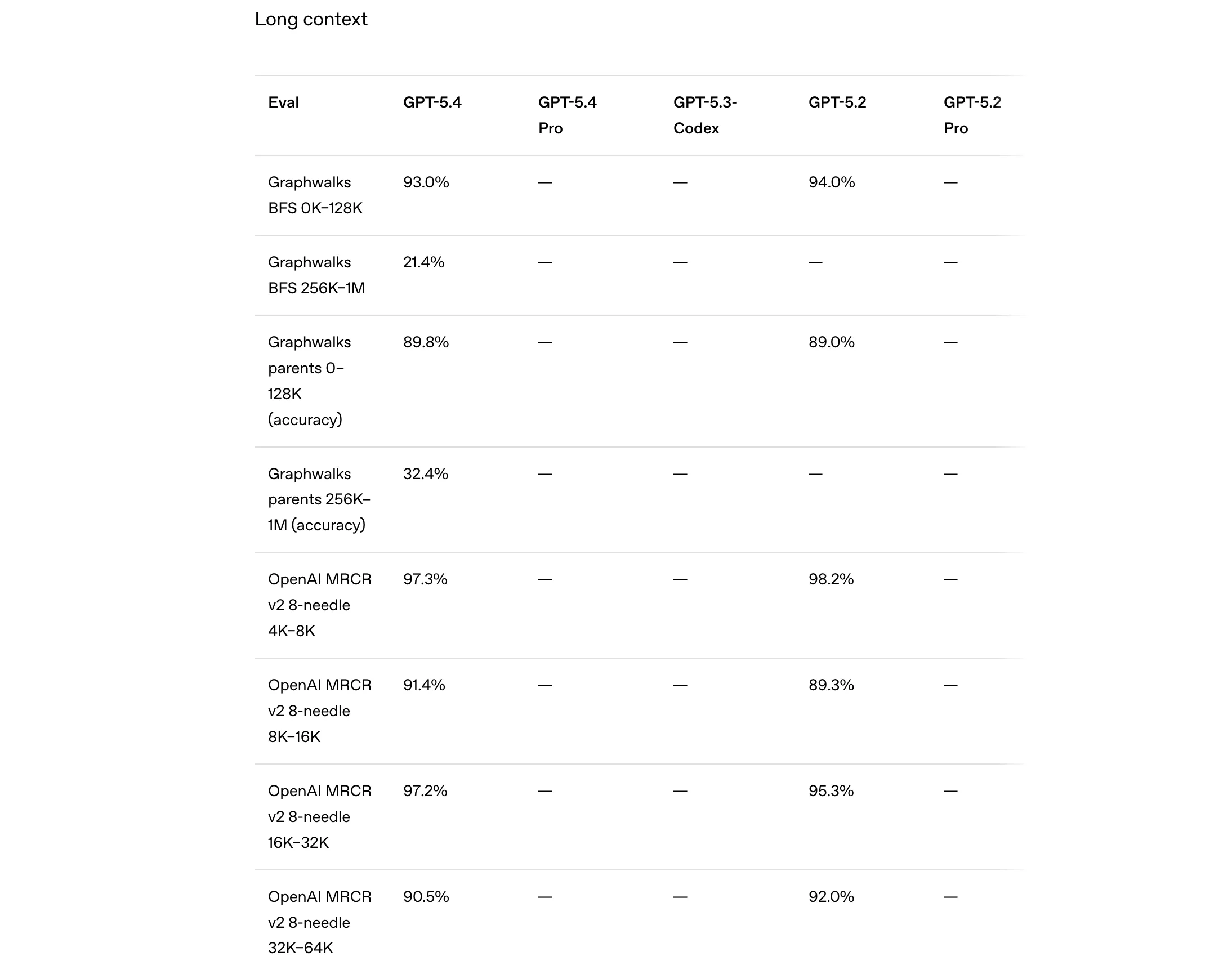
Take professional knowledge tasks, for example. On the GDPval benchmark, GPT-5.4 scores 83%, a noticeable jump from 70.9% for GPT-5.2. A similar trend appears in financial modelling tasks, where GPT-5.4 achieves 87.3% accuracy, compared to 68.4% for GPT-5.2. These benchmarks simulate real-world professional work such as analysing spreadsheets, building financial models, and answering office-related queries. In simpler terms, the model seems far better equipped to handle the kinds of tasks professionals actually deal with daily.
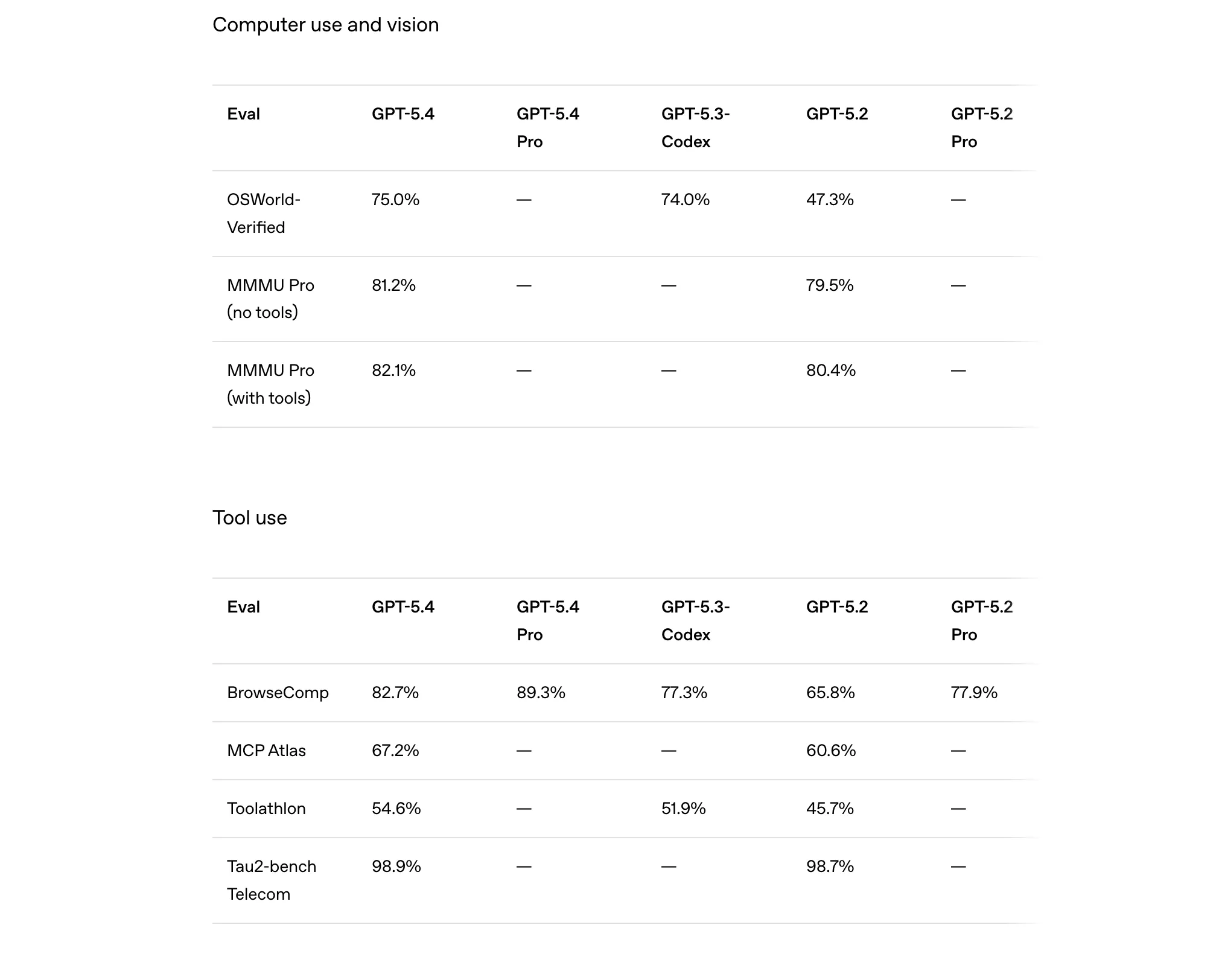
The improvements are not limited to office work. In computer use and vision tasks, GPT-5.4 records a 75% score on the OSWorld-Verified benchmark, dramatically higher than GPT-5.2’s 47.3%. This suggests the model is significantly better at interacting with computer interfaces, understanding visual inputs, and completing workflows across applications. On tool-use benchmarks like BrowseComp, GPT-5.4 reaches 82.7%, indicating stronger performance when the model has to find, select, and use the right tools to complete a task.
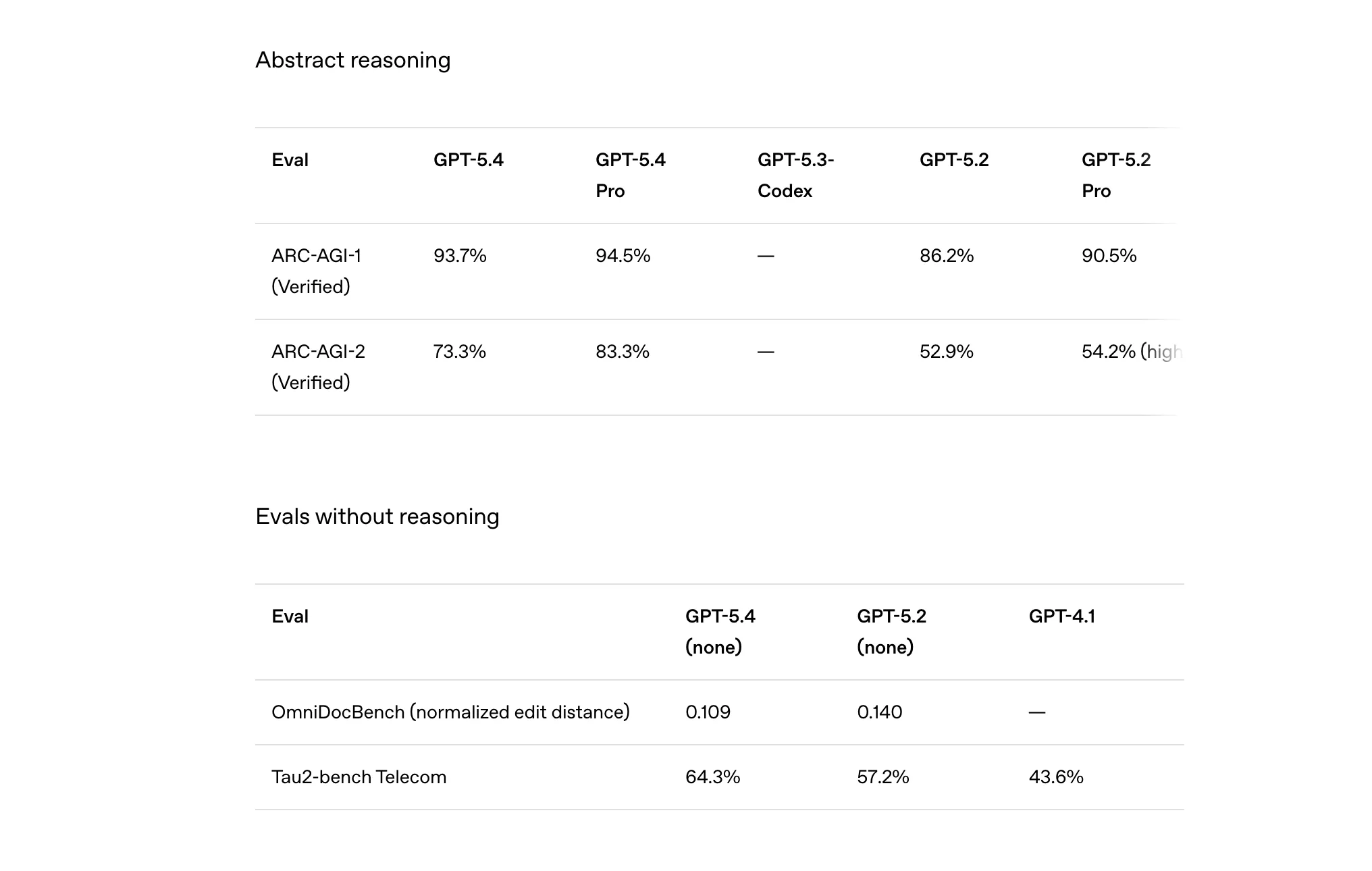
Even in traditional coding and reasoning benchmarks, the gains are steady. GPT-5.4 slightly improves the SWE-Bench Pro score to 57.7%, building on the already strong coding capabilities introduced in GPT-5.3-Codex. Meanwhile, on abstract reasoning tests like ARC-AGI, GPT-5.4 jumps to 93.7%, far ahead of GPT-5.2’s 86.2%. Put together, these numbers reinforce the very reason of GPT-5.4’s being: an AI model designed not just to chat, but to think through complex problems and complete real work across domains.
Now that we know how capable GPT-5.4 is, how do we access it?
GPT-5.4: Availability and Pricing
The good news is that the GPT-5.4 is already rolling out across ChatGPT, the API, and Codex. The not-so-good news for some – it will be limited to the Plus, Team, and Pro users for now. OpenAI says that the new model will appear as GPT-5.4 Thinking under the model picker on ChatGPT.
For developers, GPT-5.4 is already live in the API as gpt-5.4, while the higher-performance gpt-5.4-pro variant is available for workloads that require maximum reasoning power. Meanwhile, Enterprise and Edu users can enable early access through admin settings, and Codex users will see GPT-5.4 integrated into their development workflows as well. Here is a look at its API pricing:
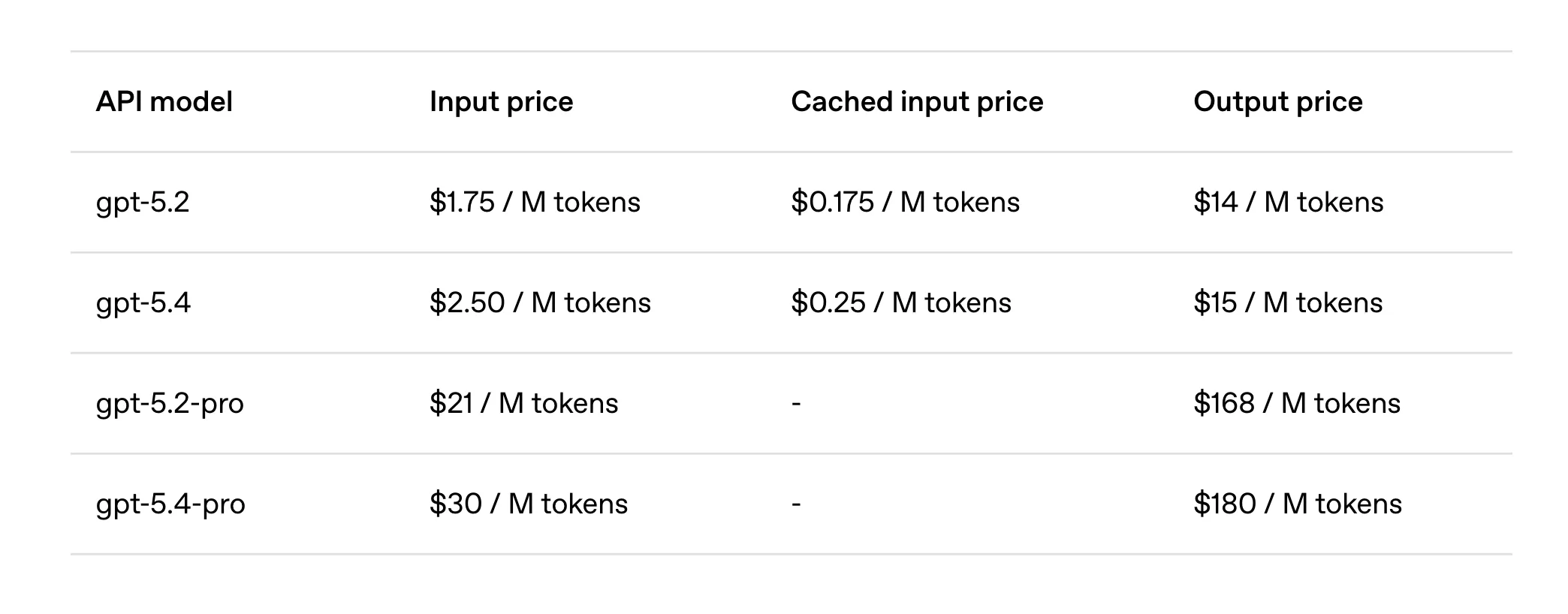
With the arrival of the GPT-5.4, OpenAI is also gearing up to bid farewell to the older one, i.e. GPT-5.2. GPT-5.2 Thinking will remain accessible for paid users under the Legacy Models section for the next three months, after which it will be retired on June 5, 2026.
Now you know where to get it, here is a glimpse of it in real-world action.
Also read: How to Use ChatGPT? A Simple Guide for Beginners
GPT-5.4 Thinking: Hands-on
Since GPT-5.4 is positioned for professional work, I targeted the three areas in my hands-on where it claims the biggest improvements. These are:
- Knowledge work (documents, analysis, structured thinking)
- Coding and technical workflows
- Agentic workflows / tool-based tasks
Check out the outputs for each and experience what GPT-5.4 brings to the table.
1. Knowledge work
Prompt:
I am sharing a report. Your task is to:
– Summarize the document in under 200 words.
– Extract the five most important insights.
– Identify any assumptions or weak arguments in the text.
– Suggest two actionable recommendations based on the analysis.
– Structure your answer clearly under headings.
Output:
As we can see, GPT-5.4 handled the long-document quite well. The summary was concise and reflects the core argument of the paper. I find no unnecessary details whatsoever – a big plus. The key insights were logically extracted and reflected the document’s central themes. In the assumptions section, the model showed good critical thinking, pointing out realistic concerns around battery progress, costs, and public acceptance. Finally, the recommendations – suggesting pilot programmes and ecosystem development rather than unrealistic large-scale deployment – seem practical and directly derived from the analysis.
2. Coding and developer workflow
Prompt:
I want to build a Python script that does the following:
- Scrapes the latest AI news headlines from 3 technology websites.
- Cleans and deduplicates the headlines.
- Uses a simple sentiment classifier to label each headline as positive, neutral, or negative.
- Stores the results in a CSV file.
First outline the architecture of the script. Then write the complete Python code with comments.
Output:
The response performs well on workflow planning because it lays out the pipeline in a logical order: source setup, scraping, cleaning, sentiment tagging, and CSV export. This makes the end-to-end flow easy to follow. On code execution, it is strong for a beginner-to-intermediate use case, with runnable code, error handling, modular functions, and comments, though the scraping layer still depends on fragile CSS selectors and a very basic sentiment method.
I find the architecture cleanliness one of the better parts of the answer. Responsibilities are separated neatly, functions are modular, and the script is easy to extend, even if it stops short of a more production-grade design with config files, logging, and reusable scraper abstractions. All in all, the output demonstrates a strong use-case of GPT-5.4 for coding and developer workflows.
3. Agentic workflow
Prompt:
You are advising a startup deciding between three AI business ideas:
- An AI-powered financial research assistant
- An AI document automation platform for law firms
- An AI agent that automates email workflows
Evaluate these ideas based on:
- market size
- difficulty of execution
- competitive landscape
- monetization potential
Provide a structured comparison table and recommend the best option.
Output:
I personally like the structured reasoning here, because it compares all three ideas through the same four business lenses and then converts that comparison into a clear recommendation. The logic thus becomes easy to follow. Its clarity of thought is strong too: the distinctions between “broad but crowded,” “high value but hard,” and “focused with strong ROI” are communicated cleanly without unnecessary jargon.
The quality of analysis is solid overall, especially in highlighting execution difficulty, buyer willingness to pay, and competitive pressure. What I did note is that it stays at a strategic level and could have been even stronger with sharper startup-stage nuances like go-to-market speed, founder-market fit, or initial wedge strategy. Overall, this is a very good example of GPT-5.4 producing a business answer that feels organised, commercially aware, and immediately useful rather than just generically intelligent.
Conclusion
We are way beyond AI chatbots now. With GPT-5.4, OpenAI is clearly targeting a highly dependable co-worker for all sorts of professional tasks. And the capabilities of the AI model, as we have seen with our tests, are outstanding in these regards.
From long-document analysis to agentic workflows, even in my limited use of GPT-5.4 till now, it feels like a model built for people who want AI to actually help them get work done. It may not change everything overnight, but it does push AI one step closer to what we actually want out of it, to help us with real-world tasks, and not just our questions.






