Feature engineering is the foundation of strong machine learning systems, but the traditional process is often manual, time-consuming, and dependent on domain expertise. While effective, it can miss deeper signals hidden in unstructured data such as text, logs, and user interactions.
Large Language Models change this by helping machines understand language, extract meaning, and generate richer features automatically. This shift opens new ways to build smarter ML pipelines. This article offers a practical guide to feature engineering using LLMs.
Table of contents
- What is Feature Engineering with LLMs?
- The Shift: From Manual Features to Semantic Features
- Core Techniques in Feature Engineering with LLMs
- Hybrid Feature Spaces (Multi-Modal Pipelines)
- End-to-End Flow (Data → LLM → Features → Model)
- Real-World Applications
- Limitations and Challenges
- Conclusion
- Frequently Asked Questions
What is Feature Engineering with LLMs?
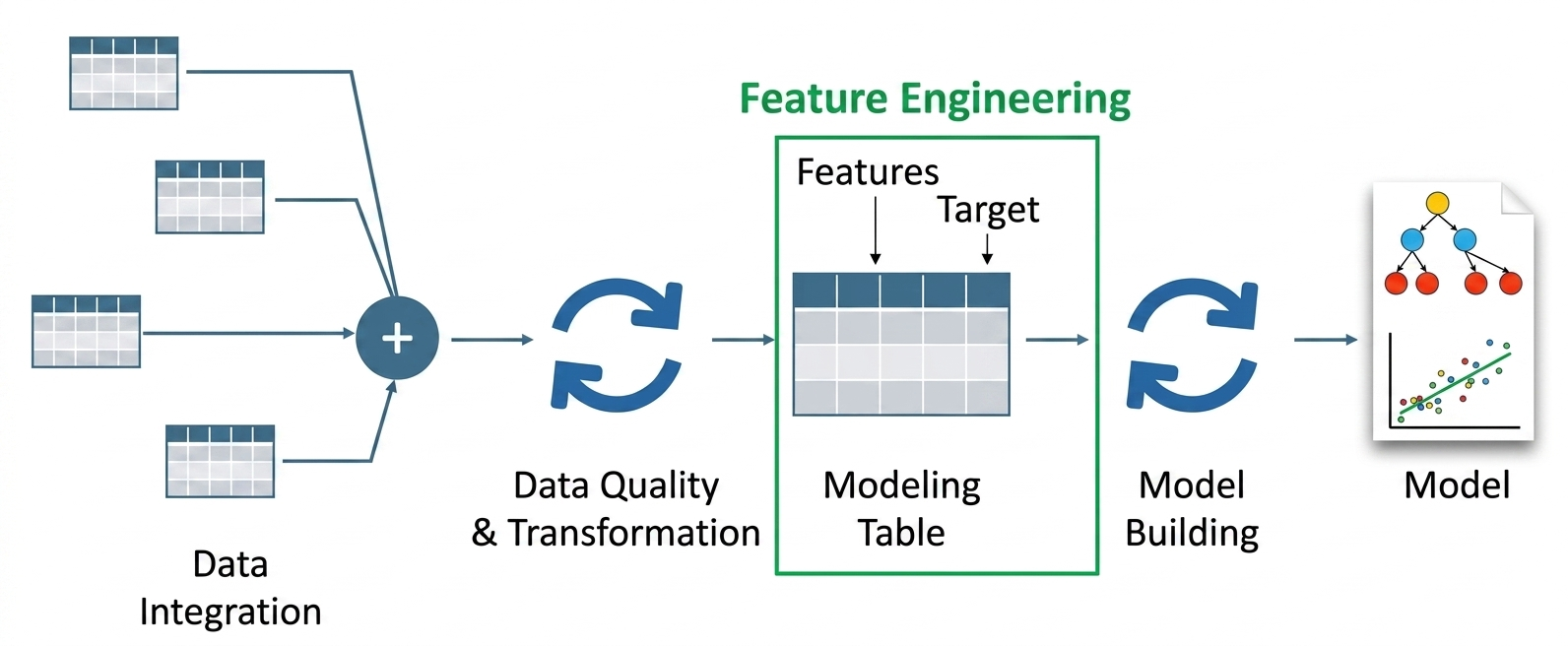
The process of feature engineering with LLMs uses large language models to develop and modify input features that machine learning systems require. Your system extracts semantic meaning and structured signals from raw data through the application of LLMs instead of using only manual transformations.
The new approach to feature engineering enables engineers to develop machine learning models through different methods that include both numeric transformations and context-based representations.
Feature engineering with LLMs uses pretrained language models to transform raw inputs into structured high-dimensional representations which help models achieve better performance. The models use context to determine relationships between elements while creating features that express meaning beyond statistical patterns.
How it Differs from Traditional Feature Engineering
Traditional feature engineering creates rules and uses aggregation and transformation methods to build features. LLM-based feature engineering extracts meaning and user intentions and relationship data which manual encoding fails to capture.
The Shift: From Manual Features to Semantic Features
Machine learning develops models through its use of handmade features which include one-hot vectors and TF-IDF and standardized numerical values. Manual features come with restrictions because they do not consider context and require specialized knowledge and they do not handle subtle differences. The TF-IDF method handles words as separate entities which leads to the loss of word relationships and emotional meaning.
- Limitations of traditional methods: Manual feature creation requires permanent system connections and specific domain expertise. The system fails to include both general knowledge and intricate connections. A bag-of-words model requires more knowledge than “cold food” to recognize negative feelings. Human resources need to spend a lot of time to identify all exceptional situations.
- Role of LLMs in context: LLMs function in their respective contexts through LLMs which employ their training from extensive text databases to acquire knowledge and recognize patterns. The system understands language context through their presence of world knowledge and ability to comprehend hidden messages. The system extracts semantic features from data through LLMs which create automatic features that identify data elements like sentiment and topic and risk categories.
- Why this shift matters: The importance of this transition comes from its ability to show that semantic features deliver better results than human-created features when dealing with complicated tasks. The system needs fewer feature heuristics for its operations which results in faster testing processes.
Core Techniques in Feature Engineering with LLMs
This section will illustrate the key methods with code examples. We generate small sample data and show how features are derived.
Embeddings as Features
LLMs produce dense semantic vectors from text. The extracted embeddings function as numeric features which enable the model to understand meaning that exceeds basic word frequencies. We can use a transformer model to create 384-dimensional sentence embeddings through sentence encoding.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["I love machine learning", "The movie was fantastic"]
embeddings = model.encode(sentences)
print("Embeddings shape:", embeddings.shape)Output:
Embeddings shape: (2, 384)
The output shape (2, 384) shows two sentences mapped into 384-dimensional dense vectors (one per sentence). The vectors represent semantic properties of the text which include related meanings and emotional expressions.
When to use embeddings vs traditional features:
from sklearn.feature_extraction.text import TfidfVectorizer
docs = [
"The cat sat on the mat",
"The dog ate the cat",
]
# Traditional TF-IDF: sparse bag-of-words
tfidf = TfidfVectorizer()
X_tfidf = tfidf.fit_transform(docs)
# LLM embeddings: dense semantic features
X_emb = model.encode(docs)
print("TF-IDF feature shape:", X_tfidf.shape)
print("LLM embedding feature shape:", X_emb.shape)Output:
TF-IDF feature shape: (2, 6)
LLM embedding feature shape: (2, 384)
The TF-IDF features create a (2×6) sparse matrix which contains six unique terms, while the LLM embeddings exist as (2×384) dense vectors. The embeddings present meaning of words in their context because they show how synonyms relate to each other with the example of “cat” and “dog”. Use semantic features from embeddings while traditional features work for simple numeric data and high-frequency categorical data that requires sparse encoding.
Prompt-Based Feature Extraction
We can prompt the LLM to extract specific structured information from text. The model outputs can be parsed into features.
from transformers import pipeline
reviews = [
"The phone battery lasts all day and performance is smooth",
"The laptop overheats and is very slow",
]
extractor = pipeline("text2text-generation", model="google/flan-t5-base")
prompt = """
Extract features: sentiment, product_issue, performance
Text: The laptop overheats and is very slow
"""
result = extractor(prompt, max_length=50)
print(result[0]["generated_text"])Output:
sentiment: negative, product_issue: overheating, performance: slow
We use the LLM prompt which states “Extract sentiment (positive/negative), subject, and urgency (low/medium/high) from this review.” The model returns structured features as a JSON-like dictionary. The features of sentiment, subject, and urgency now exist as separate columns which we can input into our classifier system
Schema-guided extraction
A JSON schema can be enforced in an invocation so that consistent outputs are ensured. For example:
prompt = """
Extract in JSON format:
{
"sentiment": "",
"issue": "",
"performance": ""
}
Text: The phone battery lasts all day and performance is smooth
"""
result = extractor(prompt, max_length=100)
print(result[0]["generated_text"])Output:
{
"sentiment": "positive",
"issue": "none",
"performance": "smooth"
}
Semantic Feature Generation
LLMs generate fresh descriptive attributes which can be applied to both single rows and individual data values.
data = [
{"review": "Great camera quality but battery drains fast"},
{"review": "Affordable and durable, good for daily use"},
]
prompt = """
Generate a new feature called 'user_intent' from this review:
Review: Great camera quality but battery drains fast
"""
result = extractor(prompt, max_length=50)
print(result[0]["generated_text"])Output:
user_intent: photography-focused but concerned about battery
The LLM extracts user intent from the review through its analysis of the text. The system transforms unprocessed text into structured features which show user preference for cameras and their concern about battery life. The system enables users to add new columns which improve model understanding of user activity patterns.
Context-Aware Feature Creation
LLMs can generate text features when they use their knowledge to analyze a feature’s value within specific situations. The LLM uses postal code information to explain the corresponding geographic area.
prompt = """
Infer customer type:
Review: Affordable and durable, good for daily use
"""
result = extractor(prompt, max_length=50)
print(result[0]['generated_text'])Output:
customer_type: budget-conscious practical user
The LLM uses customer review information to determine which customer group the reviewer belongs to. The system transforms input text into a standardized label which displays the user’s two main preferences of affordable and durable products. The system allows users to implement a new feature which enables models to categorize users according to their behavioural patterns and specific preferences.
Hybrid Feature Spaces (Multi-Modal Pipelines)
Combining Tabular, Text, and Embeddings
We start with numeric features and semantic features which we combine into a hybrid vector.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"price": [1000, 500],
"rating": [4.5, 3.0],
"review": [
"Excellent performance and battery life",
"Slow and heats up quickly",
],
})
embeddings = model.encode(df["review"].tolist())
final_features = np.hstack([
df[["price", "rating"]].values,
embeddings,
])
print("Final feature shape:", final_features.shape)Output:
Final feature shape: (2, 386)
The complete dataset now contains 2 rows which contain 386 features. The original tabular data (price and rating) is combined with text embeddings from the reviews. The system develops advanced features through its combination of structured data and semantic text information which results in better model performance.
Multi-Modal Feature Pipelines
We start with numeric features and semantic features which we combine into a hybrid vector.
def feature_pipeline(row):
embedding = model.encode([row['review']])[0]
return list(row[['price', 'rating']]) + list(embedding)
features = df.apply(feature_pipeline, axis=1)
print(features.iloc[0][:5])Output:
[1000, 4.5, 0.023, -0.045, 0.067]
The complete dataset now contains 2 rows which contain 386 features. The original tabular data (price and rating) is combined with text embeddings from the reviews. The system develops advanced features through its combination of structured data and semantic text information which results in better model performance.
End-to-End Flow (Data → LLM → Features → Model)
In this section we’ll go through the workflow demonstration which uses Transformers to extract features for use with a basic classifier. For example, consider a sentiment classification task. For that at first we’ll take a sample dataset.
import pandas as pd
df = pd.DataFrame({
"review": [
"Amazing product, delivery was super fast and packaging was perfect",
"Terrible quality, broke after one use and support was unhelpful",
"Good value for money, does what it promises",
"The product is okay, not great but not bad either",
"Excellent performance, exceeded my expectations completely",
"Very slow delivery and the product quality is disappointing",
"I love the design and build quality, highly recommended",
"Waste of money, stopped working within two days",
"Decent product for the price, but could be improved",
"Customer service was helpful but the product is average",
"Fantastic experience, will definitely buy again",
"The item arrived late and was damaged",
"Pretty good overall, satisfied with the purchase",
"Not worth the price, quality feels cheap",
"Absolutely शानदार product, very happy with it",
"Works fine but nothing exceptional",
"Horrible experience, I want a refund",
"The features are useful and performance is smooth",
"Mediocre quality, expected better at this price",
"Superb build quality and fast performance",
"Product is fine, delivery took too long",
"Loved it, exactly what I needed",
"It’s okay, does the job but has some issues",
"Worst purchase ever, completely useless",
"Very good quality and quick delivery",
"Average product, nothing special",
"Highly durable and reliable, great buy",
"Poor packaging and damaged item received",
"Satisfied with the purchase, decent performance",
"Not happy with the product, quality is subpar",
],
"label": [
1, 0, 1, 1, 1,
0, 1, 0, 1, 1,
1, 0, 1, 0, 1,
1, 0, 1, 0, 1,
0, 1, 1, 0, 1,
1, 1, 0, 1, 0,
],
})Now, we’ll move forward to make an agentic pipeline that will help in feature engineering for a particular task. Like in this case it’ll perform the sentiment analysis.
from transformers import pipeline
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
# Step 1: Initialize models
llm = pipeline("text2text-generation", model="google/flan-t5-base")
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Step 2: Feature Extraction Agent
def extract_features(text):
prompt = f"Extract sentiment (positive/negative): {text}"
result = llm(prompt, max_length=20)[0]["generated_text"]
return 1 if "positive" in result.lower() else 0
# Step 3: Build Feature Set
df["sentiment_feature"] = df["review"].apply(extract_features)
embeddings = embedder.encode(df["review"].tolist())
X = np.hstack([
df[["sentiment_feature"]].values,
embeddings
])
y = df["label"]
# Step 4: Train Model
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2
)
model = LogisticRegression()
model.fit(X_train, y_train)
# Step 5: Evaluate
accuracy = model.score(X_test, y_test)
print("Model Accuracy:", accuracy)Output:
Model Accuracy: 0.95
This shows the complete system operation which functions from beginning to end. The LLM extracts a sentiment feature from each review, which is combined with embeddings to create richer inputs. The agentic feature engineering process of this system enables the model to better understand text, which results in increased accuracy for sentiment prediction.
Real-World Applications
The application of LLMs in feature engineering creates changes that impact various industries. The solution shows ability to perform tasks in different operational areas.
- Classification and NLP Systems: LLMs deliver advanced textual elements which support sentiment analysis, chatbot development, and document classification tasks in classification and NLP systems.
- Tabular Machine Learning: LLMs enable all types of tasks to gain advantages from their capabilities. The LLM technology converts unstructured data from side sources into usable features which a tabular model can understand.
- Domain-Specific Use Cases: LLM features have found innovative applications in various domains which include finance and healthcare and insurance and additional industries. The LLM system in insurance pricing enables actuaries to create automatic features which previously required human specialists. The LLM system uses car model descriptions to determine risk ratings which identify vehicles as “boy racer” models.
Limitations and Challenges
Feature engineering with LLMs provides benefits to users, but it creates multiple obstacles which need to be solved. The implementation process requires all team members to understand the existing constraints. These include:
- Reliability and Reproducibility: The outputs of LLM systems demonstrate inconsistent behavior because model changes and minor prompt alterations require new model evaluation. The system needs prompt logging and zero temperature settings to achieve consistent performance. Organizations face challenges in LLM deployment because they must handle two aspects which include API accessibility and version control.
- Bias and Interpretability: LLM systems make their features difficult to understand because their dense embeddings function as LLM core components. The system might create training data-based bias through its operational procedures. An LLM generates a feature which connects the word “doctor” to a particular gender in an implicit manner. The auditing process must examine features to determine their fairness.
- Over-Reliance on LLM Features: LLMs offer complete automation which leads to dangerous outcomes through their facade of reliability. LLMs generate irrelevant features when users provide incorrect prompts. The LLM features should function as supplementary tools which users should apply together with main domain features.
Conclusion
The field of machine learning development experiences a major transformation through the use of feature engineering with LLMs. The process now shifts its emphasis from manual data transformation work toward creating automated features through semantic comprehension. This method enables researchers to develop new methods for analyzing intricate and disorganized datasets.
The process requires precise implementation and thorough evaluation and validation procedures to achieve success. LLM capabilities combined with human expertise enable practitioners to develop AI systems that operate with greater strength and scalability and effectiveness.
Frequently Asked Questions
Q1. What is feature engineering with LLMs?
A. It uses LLMs to turn raw data into semantic, structured features for machine learning models.
Q2. How do LLM embeddings help?
A. They convert text into dense vectors that capture meaning, context, and relationships beyond simple word frequency.
Q3. What are the main challenges?
A. LLM-based features can be inconsistent, biased, hard to interpret, and risky when used without validation.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.






