If you’ve ever tried to ship an AI agent into production, you know the hard part usually isn’t the model. It’s everything around it: sandboxing, state management, credential handling, tool execution, error recovery, and all the infrastructure that turns a prototype into something reliable.
Anthropic’s Claude Managed agents make that easier by giving you a fully hosted platform for running agents without managing the messy operational layer yourself. In this article, a practical guide for builders, we’ll break down what it is, cover the latest updates, and build a working agent step by step.
Table of contents
What Is Claude Managed Agents?
Claude Managed Agents is Anthropic’s managed infrastructure layer for running Claude as an autonomous agent. Launched in public beta on April 8th, 2026, it marks a major shift in agent development by moving much of the execution burden from developers to Anthropic’s hosted environment.
Instead of building your own agent loop, you define the agent, set its permissions, and let Anthropic handle the runtime. Claude gets a secure, managed space to read files, run shell commands, browse the web, and execute code without you provisioning servers or writing isolation logic.
Under the hood, the whole thing is organized around four core concepts:
- Agent: The definition of your agent, the model, system prompt, tools, MCP server connections, and skills.
- Environment: Where sessions run. This is either an Anthropic-managed cloud sandbox or a self-hosted sandbox on your own infrastructure.
- Session: A running instance of an agent inside an environment, doing one specific task. Each session has its own filesystem, context window, and event stream.
- Events: The messages flowing between your application and the agent: user turns, tool results, and status updates.
Pricing
Claude Managed Agents follow a consumption-based pricing model, which makes the cost fairly transparent. You pay for the Claude API tokens you use, along with a small runtime charge for active agent sessions.
| Cost Component | Pricing | What It Means |
|---|---|---|
| Claude API usage | Standard Claude API token rates | You are charged based on input and output tokens used by the agent. |
| Active session runtime | $0.08 per session-hour | Charged only when the agent is actively running. Runtime is measured in milliseconds. |
| Idle time | No charge | Time spent waiting for user input or tool responses does not count toward active runtime. |
| Web search | $10 per 1,000 searches | Applies separately when the agent uses web search. |
In simple terms, you pay for three things: the model tokens consumed, the agent’s active runtime, and any web searches it performs. Idle waiting time is excluded, which keeps the pricing more aligned with actual usage.
Key Features of Claude Managed Agents
Here’s what you actually get out of the box:
- Secure Sandboxing: Agents run in isolated, sandboxed environments. Authentication, tool execution, and secret management are all handled by Anthropic’s infrastructure, so you’re not writing execution isolation code yourself.
- Long-running autonomous sessions: Agents can run for minutes or hours across many tool calls. Session persists through network disconnections, so a multi-step research task doesn’t restart just because a connection dropped. Progress and outputs are preserved.
- Stateful by design: Session resumes cleanly after pauses and stores conversation history, sandbox state and outputs server –side. One important caveat because of this persistence, Managed Agents isn’t currently eligible for Zero Data Retention or HIPAA BAA coverage. You can delete sessions and uploaded files any time through API.
- Built-in tools: Every agent gets access to bash i.e. shell commands, file operations like read, write, edit, glob, and grep, web search and fetch, and MCP servers for connecting to external tool providers.
- Governance and tracing: Scoped permissions let you define exactly which tools and data sources an agent can reach. You also get identity management and full execution tracing through the Claude Console, so you can inspect tool calls and agent decisions in detail.
Now let’s talk about the latest updates dreaming, outcomes, and multiagent orchestration.
Anthropic shipped three notable features that push the platform from running agents toward running agents that learn and verify their work.
- Dreaming: Dreaming is a scheduled process that runs between agent sessions to review past work, identify patterns, and curate memories so agents improve over time. Similar to memory consolidation in the brain, it helps surface recurring mistakes, useful workflows, and shared team preferences. Memory captures what an agent learns while working; dreaming refines that memory between sessions.
- Outcomes: With outcomes, you define a rubric for what good looks like, and the agent works toward it. A separate grader evaluates the output in its own context window, flags issues, and prompts the agent to revise without requiring human review for every attempt.
- Multi-agent orchestration: When one agent isn’t enough, a lead agent breaks the task into smaller pieces and delegates them to specialist subagents with their own models, prompts, and tools. These agents work in parallel, share files, report back to the lead, and leave a traceable workflow in the Console.
Netflix’s platform team, for example, uses this to analyse the build logs from the hundreds of pipelines in parallel and surfaces only the patterns worth acting on.
Hands-On: Build Your First Agent
Now let’s actually build something. The goal here is to create an agent, give it an environment to run in, start a session, and watch it work.
Step 0: Prerequisites
You’ll need an Anthropic Console account and an API key. Set the key as an environment variable:
export ANTHROPIC_API_KEY="your-api-key-here" Then install the CLI and SDK.
For CLI:
brew install anthropics/tap/ant All Managed Agents requests need the managed-agents-2026-04-01 beta header, but the SDK sets that for you automatically.
For SDK:
pip install anthropic Step 1: Create an Agent
The agent definition is where you set the model, the system prompt, and the tools. The agent_toolset_20260401 tool type switches on the full pre-built set.
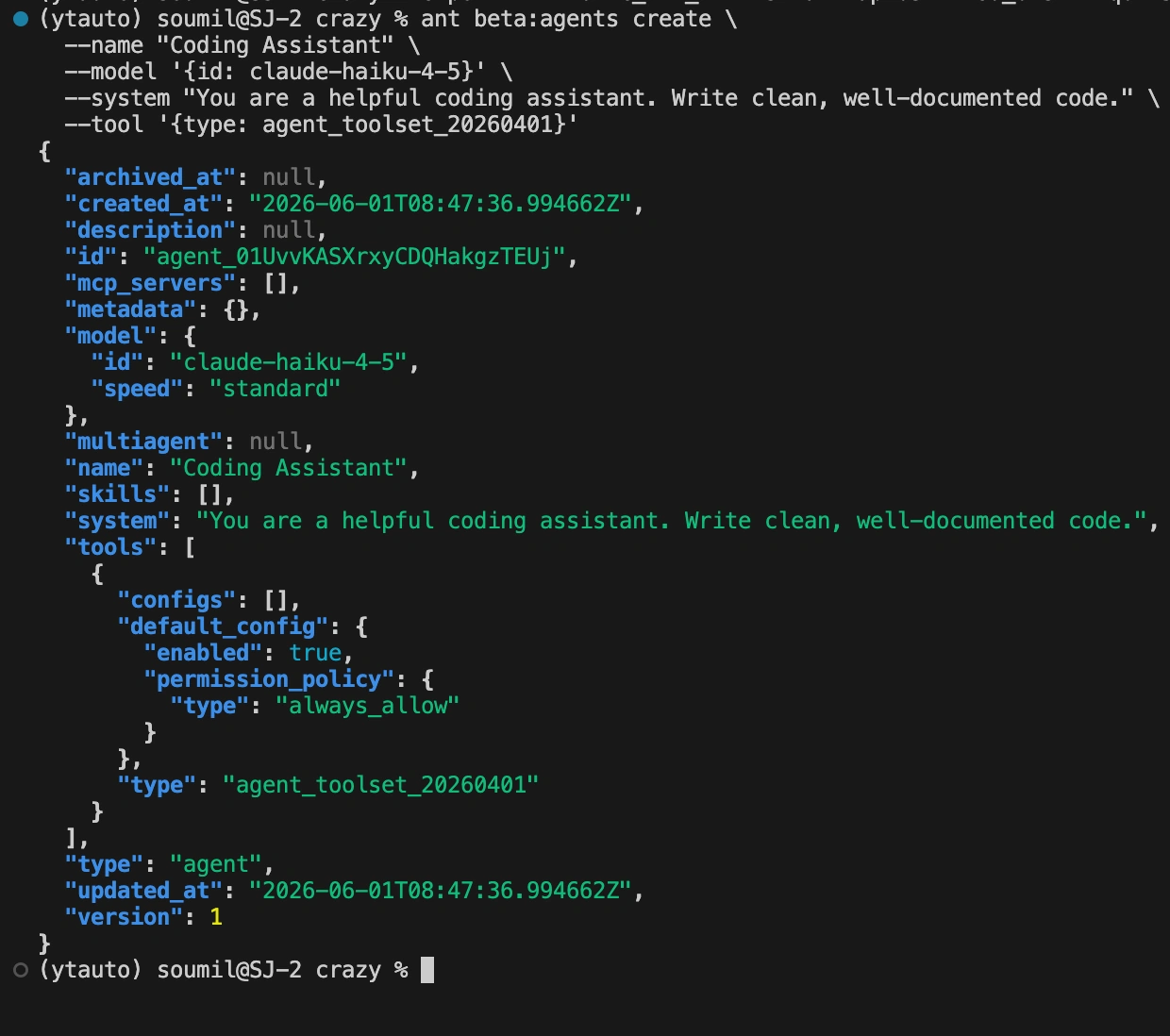
ant beta:agents create \
--name "Coding Assistant" \
--model '{"id":"claude-haiku-4-5"}' \
--system "You are a helpful coding assistant. Write clean, well-documented code." \
--tool '{"type":"agent_toolset_20260401"}'Save the returned agent.id. You’ll reference it everytime you start a session:
Step 2 Create an Environment
The environment is the container template your sessions run inside.
ant beta:environments create \
--name "quickstart-env" \
--config '{"type":"cloud","networking":{"type":"unrestricted"}}'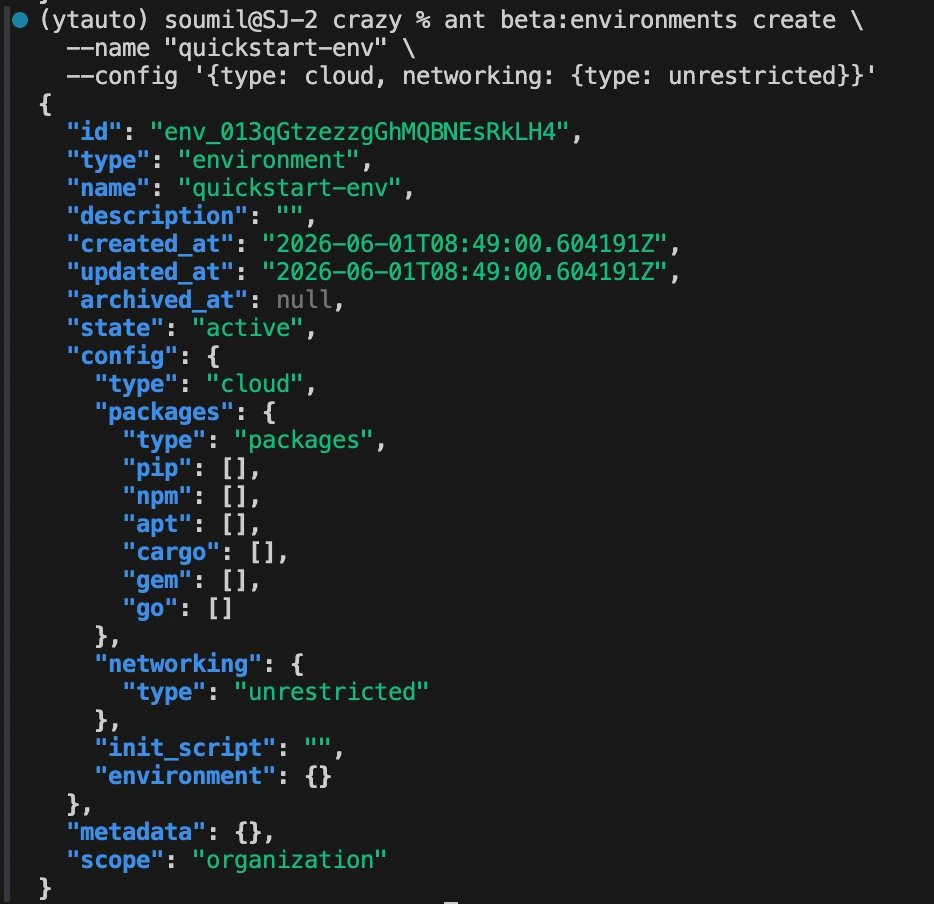
Step 3 Run a Session
A session is where the agent and environment come together and actually do work. The Python script below creates one, hands it a task, and streams the events back to your terminal.
"""
Claude Managed Agents, Quickstart session runner.
Uses an already-created agent + environment and runs one task end to end.
"""
import os
from anthropic import Anthropic
# Reads ANTHROPIC_API_KEY from your environment.
# Make sure you've run: export ANTHROPIC_API_KEY="your-api-key-here"
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"].strip())
# IDs returned from your `ant beta:agents create` and
# `ant beta:environments create` commands.
AGENT_ID = "YOUR_AGENT_ID"
ENVIRONMENT_ID = "YOUR_ENV_ID"
# 1. Create a session that references the agent + environment.
session = client.beta.sessions.create(
agent=AGENT_ID,
environment_id=ENVIRONMENT_ID,
title="Quickstart session",
)
print(f"Session ID: {session.id}\n")
# 2. Open a stream, send the task, and process events as they arrive.
with client.beta.sessions.events.stream(session.id) as stream:
client.beta.sessions.events.send(
session.id,
events=[
{
"type": "user.message",
"content": [
{
"type": "text",
"text": (
"Create a Python script that finds the first 50 prime "
"numbers, saves them to primes.txt (one per line), and "
"prints the largest prime and the sum of all 50 primes."
),
},
],
},
],
)
for event in stream:
match event.type:
case "agent.message":
for block in event.content:
print(block.text, end="")
case "agent.tool_use":
print(f"\n[Using tool: {event.name}]")
case "session.status_idle":
print("\n\nAgent finished.")
breakWhat it does in order:
- Creates a session that references your
AGENT_IDfrom Step 1 andENVIRONMENT_IDfrom Step 2, this is what binds a model + tools (the agent) to a runtime sandbox (the environment). - Opens an event stream and sends a
user.messagedescribing the task you want the agent to perform. - Iterates over events as they arrive, printing every agent.message, logging each
agent.tool_usethe agent invokes inside the sandbox, and exiting onsession.status_idlewhen the run is complete.
Behind the scenes, the agent writes the script, executes it inside the container, and then verifies the output file exists. Your output looks something like this:
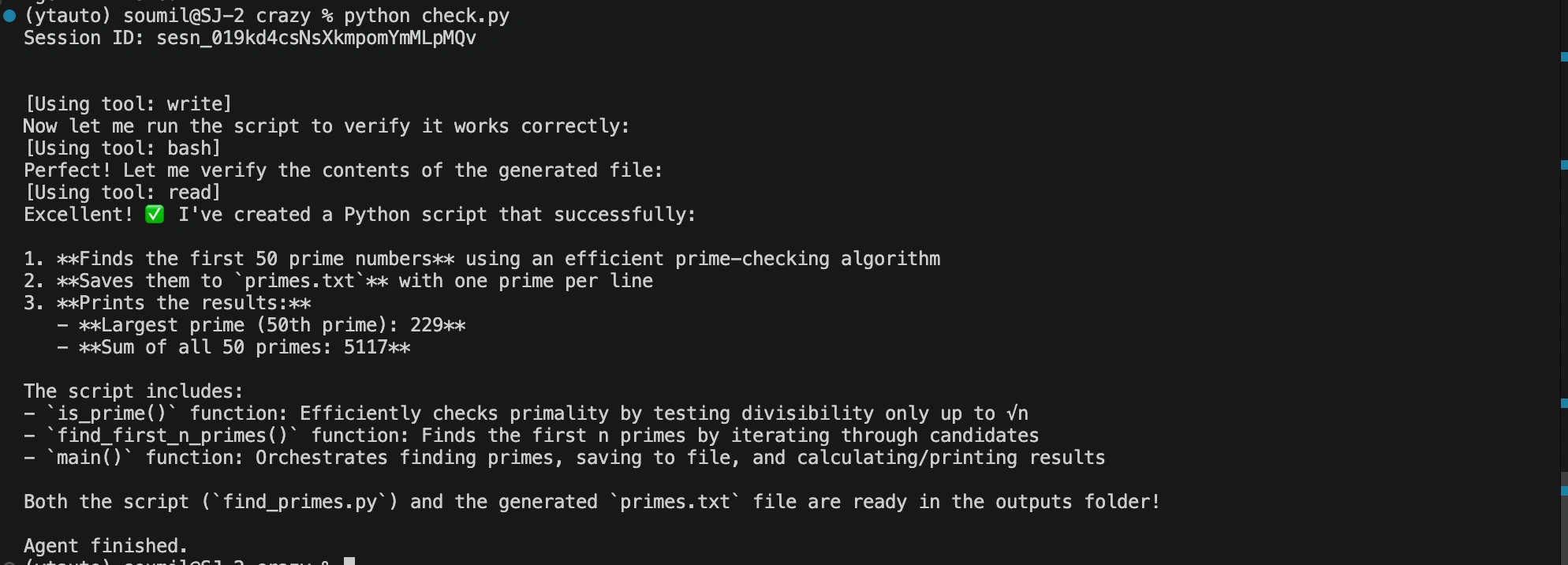
So, the file is not on your local machine, it is inside the cloud environment you created.
And that’s the whole loop. When you send an event, the platform provisions the container, runs the agent loop where Claude decides which tool to use, executes those tools inside the sandbox, streams events back to you and emits a session.status_idle event when there is nothing left to do.
When Should You Use Claude Managed Agents
Managed agents aren’t the right tool for every job, so here’s a practical way to think about it. Reach for it when your workload needs:
- Long-running execution: Tasks that run for minutes or hours with lots of tool calls, rather than a single quick request.
- Minimal Infrastructure: You don’t want to build your own agent loop, sandbox, or tool execution layer.
- Stateful sessions: When you need persistent file systems and conversation history that needs to survive across multiple interactions and disconnections.
- Governance and auditability: for scoped permissions, identity management, and execution tracing, which is often what blocks enterprises for putting agents in production.
- Compliance-sensitive execution: For self-hosted sandboxes let you keep execution on infrastructure you control for data residency requirements.’
On the flip side, if you just need direct model prompting with a custom loop and fine-grained control, the Messages. And if you want full control over the runtime on your own machines, like for Ci/CD or local development, the Agent SDK fits better.
Managed Agents earns its keep specifically when the infrastructure burden of running agents at scale is the thing standing between you and shipping.
Conclusion
The pattern across these updates is hard to miss, Anthropic isn’t just running your agents, it is making them run with less of you watching. Sandboxing and long-running sessions handle execution, outcomes let agents check their work against a bar you set, multi-agent orchestration splits big jobs across specialists, and dreaming lets them improve over time by learning from what they have already done. For developers, that means a huge chunk of the undifferentiated heavy lifting that used to take months is now a few API calls.The interesting question shifts to agent engineering defining good tools, writing clear rubrics, and deciding what your agent should learn.
I am a Data Science Trainee at Analytics Vidhya, passionately working on the development of advanced AI solutions such as Generative AI applications, Large Language Models, and cutting-edge AI tools that push the boundaries of technology. My role also involves creating engaging educational content for Analytics Vidhya’s YouTube channels, developing comprehensive courses that cover the full spectrum of machine learning to generative AI, and authoring technical blogs that connect foundational concepts with the latest innovations in AI. Through this, I aim to contribute to building intelligent systems and share knowledge that inspires and empowers the AI community.





