Most search agents try to handle too many jobs at once. They generate new queries, remember what they have already explored, collect evidence, and decide what is relevant as the search keeps expanding. That can make the whole process messy, expensive, and hard to control.
Harness-1 takes a simpler approach. Built with researchers from UIUC, UC Berkeley, and Chroma, it separates the work of finding search terms from the work of tracking search progress. The result is a compact retrieval agent that feels easier to reason about and performs far above what its size might suggest.
In this article, we take a closer look at Harness-1 and why its approach to retrieval agents matters.
Table of contents
Why Existing Search Agents Plateau?
Most retrieval agents are trained end to end. The model produces queries, reads chunks, decides what matters, and keeps all that context in a growing transcript. The policy learns everything, search strategy, evidence tracking, deduplication, and those stopping conditions too.
The problem is reinforcement learning then tries to improve all of this at once. Semantic search decisions like should I search for “merger date” or “acquisition year” get tangled with the more low-level bookkeeping. Have I seen this chunk before? RL ends up optimizing both, and honestly, they don’t share the same learning dynamics. So, it gets a bit messy.
The researchers call this the core design flaw. Their fix is clean, move state management out of the model and into a harness.
What the Harness Actually Does?
The stateful harness comprises the main breakthrough. The harness runs the model as a state machine. It maintains these four persistent structures throughout each episode:
- A candidate pool consists of all compressed, deduplicated documents from all candidate searches.
- A curated set is the final output with up to 30 documents identified with importance flags (
very_high,high,fair,low). - A full-text store contains every piece of data retrieved, stored outside of the machine prompt.
- An evidence graph is a collection of auto-extracted entities, their bridge documents, and singleton leads.
The evidence graph portion of this structure is quite clever. The regex extractor scans each piece of retrieved data for proper nouns, years, and dates. Bridge documents that contain two or more entities frequently found together are flagged as being of very high priority. Singletons mark potential follow-up searches. At each turn of play, the harness presents this information in an efficient, compact manner.
The Eight-Tool Interface
The eight-tool based on the model function on each turn. Every turn, the model emits exactly one action.
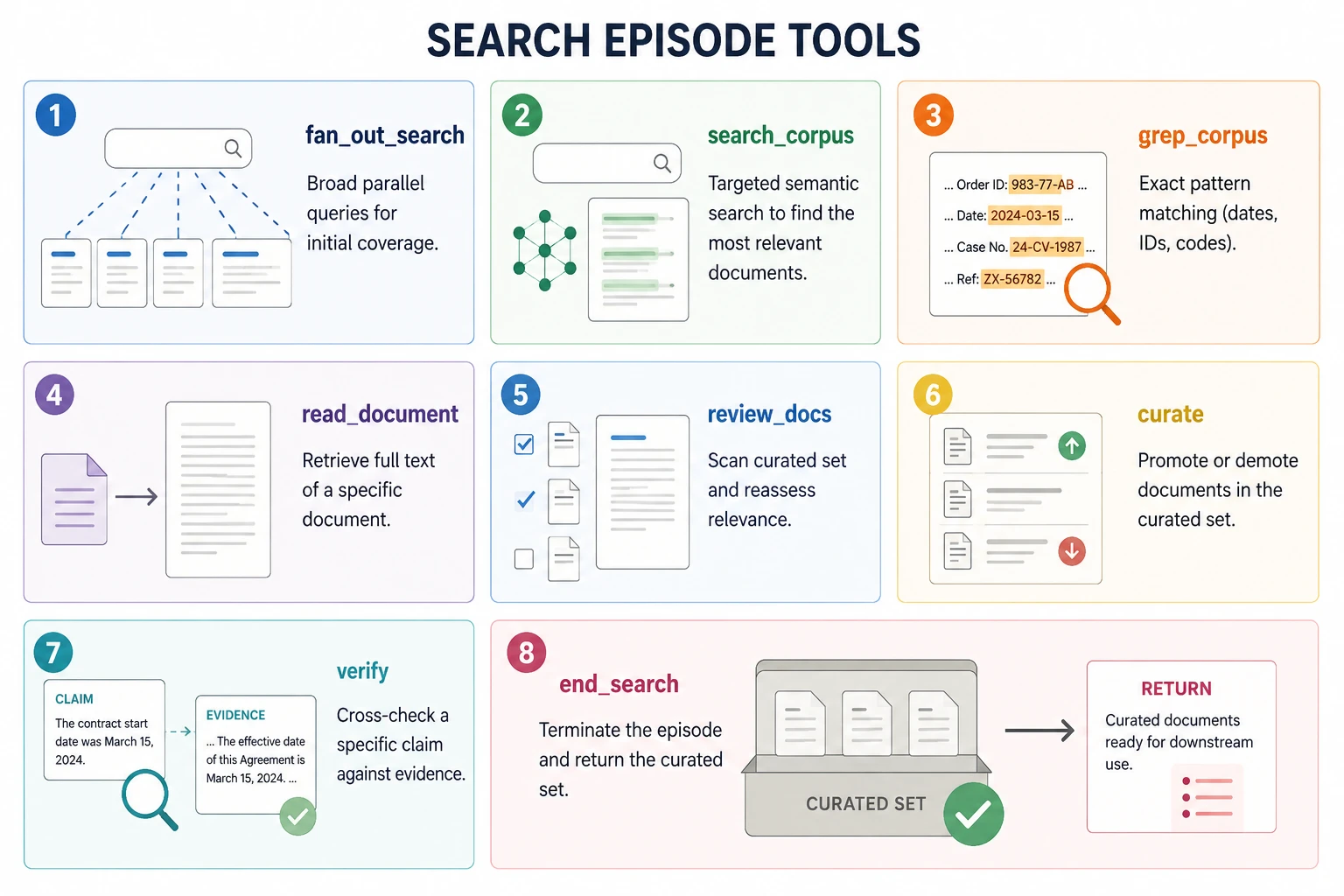
Two phase compression is applied to the output from search phase of retrieval. The first phase of compression uses Sentence-BM25 to rank all sentences and select the top 4 from each chunk. The second phase of compression is accomplished through two-level de-duplication: the first stage is de-duplication by chunk ID, the second stage is de-duplication by content fingerprint. The policy never sees the raw retrieval output prior to the completion of two-phase de-duplication.
The design has paid off, as the model has kept its context clean. The model has only processed signals, and all tokens are not noise.
The Cold Start Problem (And Its Solution)
The first issue in retrieval training is determining how a policy learns to create a curated dataset out of nothing, which leads to randomness in the policy’s first few RL episodes. Because the initial state for the policy does not have a prior to refine from, it doesn’t know how to curate. Therefore, the policy either throws everything into the curated dataset or does not curate any at all.
Harness-1 addresses this issue using warm-start seeding. After the harness has successfully performed a search for the first time, it automatically generates a curated dataset using the top 8 reranked results that were tagged with a fairness rating. Thus, the policy has a remedial function (refinement, increasing the value of quality documents and decreasing the quality of weak documents) instead of a primary function (removing all documents and creating from scratch).
This small change creates a significant amount of stability in training and demonstrates that curation is learned more easily through refinement than it is through creation.
How Training Works: SFT Then RL
There are two stages in the training pipeline that do different kinds of work:
Stage 1: Supervised Fine Tuning
A teacher model (GPT-5.4) is running in the complete harness in a live state and being trained with a large set of diverse queries at this point. After filtering out all of the poorly performing trajectories we were left with a total of 899 episodes that covered the correct use of the interface to train the model how to call tools, structure actions, and update the curated set.
# LoRA configuration for SFT
lora_config = {
"rank": 32,
"target_modules": ["q_proj", "v_proj"],
"base_model": "gpt-oss-20b",
"epochs": 3,
"checkpoint_for_rl": 550, # step-550 initializes RL training
}Stage 2: Reinforcement Learning
At the second stage of Reinforcement Learning, on-policy CISPO is used with a reward function based on terminal rewards only, and has a cap of 40 turns. The training data consisted of SEC (financial document) queries, but the policies learned through training at this stage were generalizable to all 8 benchmark domains. The reward function has two major benefits:
- The first benefit is separation of discovery and selection. The two elements are provided as independent rewards when finding and curating a discovery (i.e., a relevant document is found and then curated).
- The second benefit is the addition of a diversity bonus for tools being used. This bonus is more important than you might think.
Without the diversity bonus, the agent gets stuck in a loop. The agent repeatedly issues the same search query in slightly varying forms, fills the curated set with many similar items, and experiences stalling (0.53 curated recall). The agent learns to utilize grep_corpus, verify, and read_document in addition to search_corpus when a diversity bonus is added, and as a result, the agent’s recall score increases to 0.60 from this one change.
# Simplified reward structure
def compute_reward(episode):
discovery_score = count_newly_found_relevant_docs(episode)
selection_score = curated_recall(episode.final_curated_set)
diversity_bonus = tool_diversity_score(episode.action_sequence)
# Terminal reward only - no intermediate shaping
return selection_score + 0.3 * discovery_score + 0.2 * diversity_bonusHands-On: Running Harness-1 Locally
Let’s try it out.
- At the moment this repo is using
uvfor dependency management and vLLM for serving. You will need to have enough GPU VRAM to run a 20B model. For example, a single A100 (80GB) will work nicely. Alternatively, two A100s (40GB) will work very nicely using tensor parallelism if you have them. - Clone the repository and install it
git clone https://github.com/pat-jj/harness-1.git
cd harness-1
# If you haven't installed uv, do it now
pip install uv
# Pull all dependencies including vLLM
uv sync --extra vllmNote that pulling in vLLM and its CUDA dependencies is done with the --extra vllm flag and may take some time during the first pull of the package. If you do not follow through with this step, the inference script will not run due to its reliance on the vLLM server.
- The first time you run an application with this model installed it will download about 40GB of weights from HuggingFace and setup a local OpenAI compatible server using uvicorn. After uvicorn has started and you can open the server at http://0.0.0.0:8000, you should be able to run your model.
uv run python inference/vllm_local_inference.py serve \
--model pat-jj/harness-1 \
--served-model-name harness-1If you have two GPUs, you can add --tensor-parallel-size 2 to create a split between both GPUs. Without this option, you will hit out of memory issues with one, 40GB, GPU.
- The execution of Step 3 means you can now issue a search request directly to the Harness-1 server. You must format your search request as a structured query directed against a Chroma corpus. Here’s what a minimal test would look like, using the BrowseComp+ benchmark format:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
response = client.chat.completions.create(
model="harness-1",
messages=[
{
"role": "user",
"content": "Search for documents about the 2024 EU AI Act enforcement timeline.",
}
],
max_tokens=512,
temperature=0.0, # deterministic for eval runs
)
# The model emits a structured tool action - parse it
action = response.choices[0].message.content
print(action)In response to your query, you will receive an output that is not narrative in nature. The output will be in the form of a structured action; e.g. fan_out_search(queries=["EU AI Act enforcement 2024", "AI Act timeline implementation"]). This is expected since Harness-1 is a retrieval sub-agent as opposed to a chat model. The output of Harness-1 will then be sent to the harness, which will process the action against your corpus.
- After a full search episode gets completed, you can see the metrics that matters in the log file.
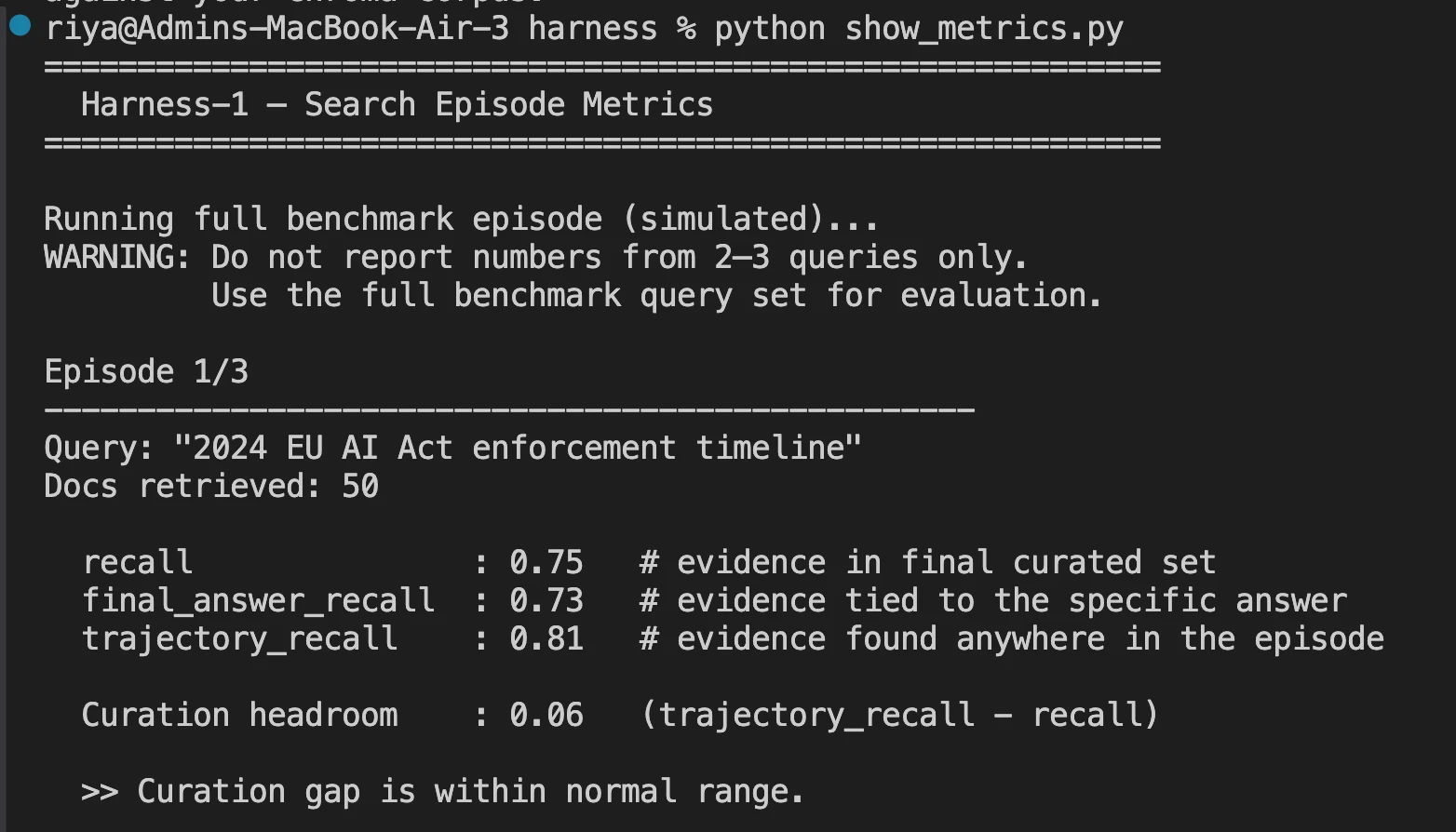
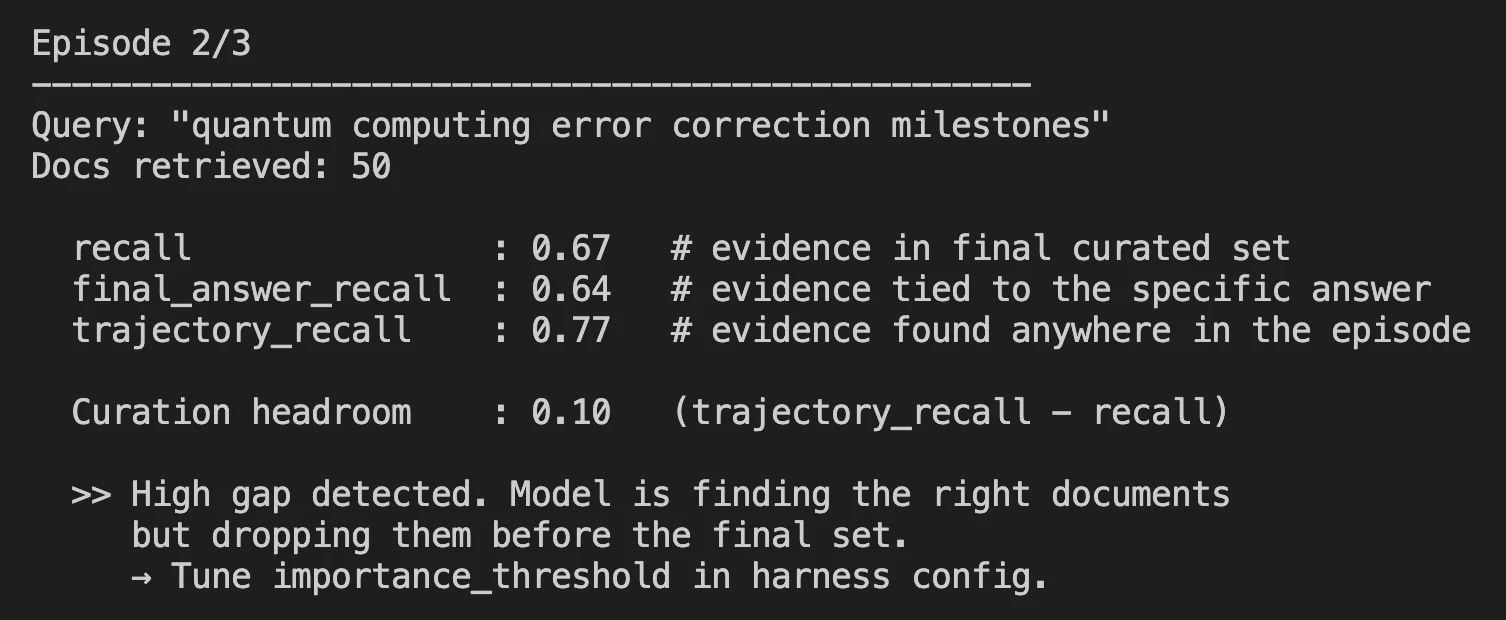
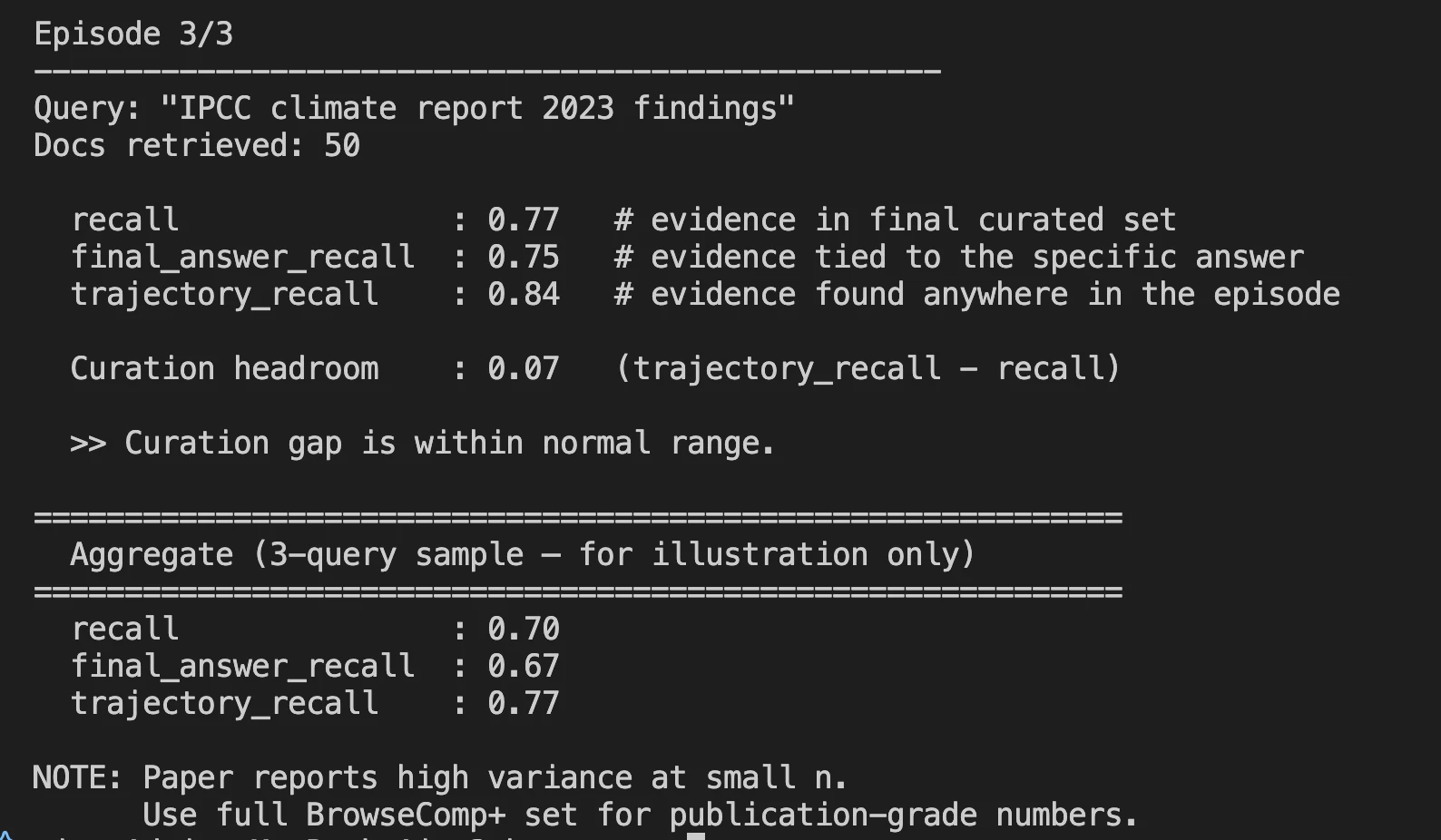
Benchmark Results: Where It Stands
Harness-1 was tested against eight different benchmarks, including web search, SEC financial filings, patents, and multi-hop question answering (QA).
Curated Recall is the core metric used to measure Harness-1 performance, that is, what percentage of all relevant documents created by Harness-1 at the final output of 30 total documents, made it into the output.
| Model | Size | Curated Recall | Trajectory Recall |
|---|---|---|---|
| Harness-1 | 20B open | 0.730 | 0.807 |
| Tongyi DeepResearch | 30B open | 0.616 | 0.673 |
| Context-1 | 20B open | 0.603 | 0.756 |
| Search-R1 | 32B open | 0.289 | 0.289 |
| Opus-4.6 | frontier | 0.764 | 0.794 |
| GPT-5.4 | frontier | 0.709 | 0.752 |
| Sonnet-4.6 | frontier | 0.688 | 0.725 |
| Kimi-K2.5 | frontier | 0.647 | 0.794 |
What Harness-1 Doesn’t Do?
It is a retrieval subagent, which returns a ranked document set and does not perform any reasoning, summarizing, or synthesizing an answer from that document set. Therefore, the downstream answering model is not considered in scope.
The RL training was only conducted on SEC queries, but it is promising to see the transfer performance onto web-based, patent and multi-hop QA queries. However, we did not consider domain generalization as part of the training setup. Financial document structure is fundamentally different than the multi-hop chains of the Wikipedia.
Additionally, 899 SFT trajectories constitute a relatively small dataset. Additionally, the teacher was GPT-5.4, which is expensive. Therefore, it remains an open question as to how to scale the trajectory collection process.
Conclusion
Harness-1 kind of shows that modular AI systems end up stacking up better than the monolithic kind. Like, a 20B model, trained on a narrow task, with a well-designed harness, ends up doing better than frontier models that have 5 times the parameters. It’s not only some architecture victory either, it feels more like a recipe, really.
The weights plus the harness code are public, so if you are building anything with retrieval like RAG pipelines, research agents, document Q/A, all that stuff, this setup is worth a careful look.
Also, there’s a reason the open-weights leaderboard has been pretty much carried by frontier models for the last year. Harness-1 is the most direct counterpoint so far.
Frequently Asked Questions
Q1. What is Harness-1?
A. Harness-1 is a 20B open retrieval subagent designed to improve search and document curation.
Q2. Why does Harness-1 perform well?
A. It separates search from state management, keeping model context cleaner and reducing noisy retrieval signals.
Q3. What does Harness-1 not do?
A. It does not summarize or reason over documents; it only returns a ranked document set.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]






