Most AI agents are weirdly forgetful. They finish a task, wipe the slate clean, and show up tomorrow ready to repeat the same mistake. No memory, no growth.
The self-improving loop breaks that cycle. The agent looks at its own results, learns what worked, and gets a little better each time.
This guide explains the self-improving loop in clear, simple language. You will learn how it works, why it beats traditional agent workflows, and where it adds real value. We also include a runnable code example with dummy data.
Table of contents
- Understanding Traditional Agentic Workflows
- What is the Self-Improving Loop in AI Agents?
- Self-Improving Loop vs Traditional Agent Workflow
- Real-World Example: Research and Analysis Agent
- Key Technologies Behind Self-Improving Agents
- Challenges and Limitations of Self-Improving Agents
- Verdict: Is the Self-Improving Loop the Future of AI Agents?
- Frequently Asked Questions
Understanding Traditional Agentic Workflows
Before we move to self-improving agents, we must understand the systems they upgrade. Traditional agentic workflows power most AI assistants you use today. They are powerful, popular, and good enough for many jobs. Still, they share one big weakness that limits long-term performance. Let us break down how they work.
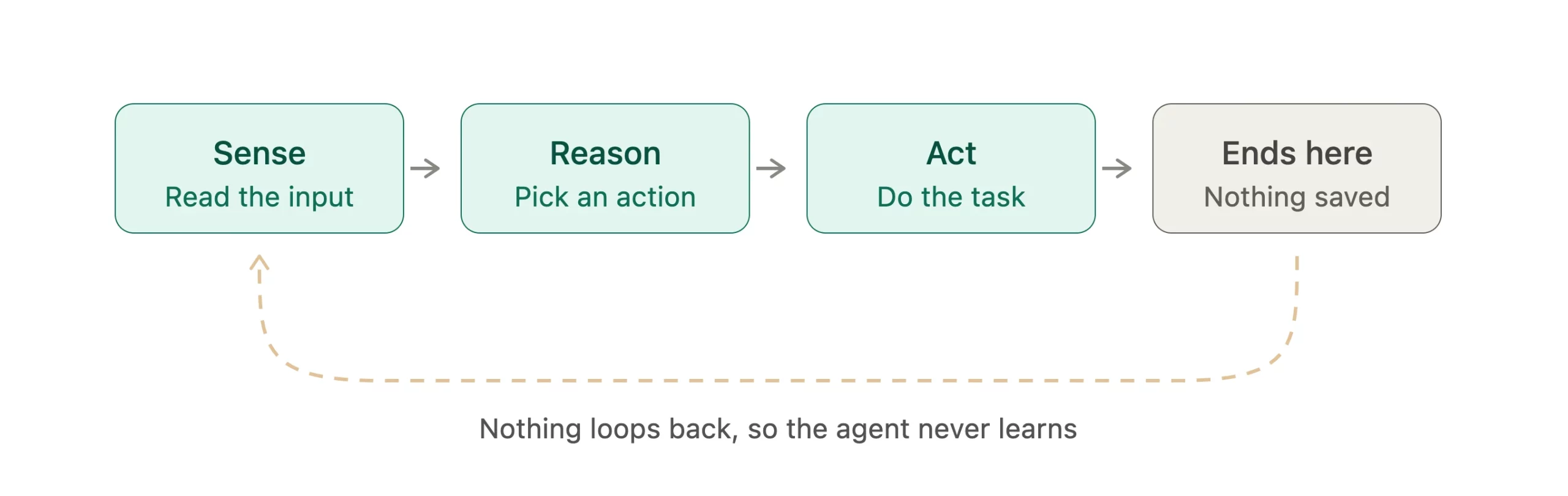
The workflow is linear: sense → reason → act, and then the process ends or moves to a new task without learning from the result.
Typical Agent Architecture
Most traditional agents share a simple, repeatable structure under the hood. Understanding these parts makes the later comparison much easier to follow. Below are the common building blocks of a standard agent.
- The prompt: Fixed instructions that tell the agent what to do and how to behave.
- The reasoning step: The model plans actions, often using a pattern like reason-then-act.
- The tools: Optional helpers such as web search, code runners, or databases.
- The output: The final response delivered back to the user once the task finishes.
Strengths of Traditional Agents
Traditional agents remain popular because they offer clear and reliable benefits. They are not outdated, and many teams rely on them every day. Here are the strengths that keep them relevant.
- Predictable behaviour: The same input usually produces a similar and stable output.
- Fast to build: A capable agent can ship in hours with modern frameworks.
- Easy to audit: Fixed prompts make the agent’s logic simple to review and debug.
- Low complexity: Fewer moving parts mean fewer things can break in production.
Key Limitations of Traditional Agents
Despite their simplicity, traditional agents have important downsides:
- No Long-Term Learning: They do not retain knowledge beyond the immediate task. Each task starts “fresh,” so they repeat the same mistakes repeatedly.
- Static Prompt/Model: The agent’s instructions (prompts) and model weights never change on the fly.
- No Feedback Loop: They lack a built-in feedback or evaluation step. Once an answer is given, the loop stops.
- Repeated Errors: Without review, a mistake (like a bug in reasoning or a wrong fact) can persist indefinitely.
What is the Self-Improving Loop in AI Agents?
The self-improving loop is the upgrade that fixes the weaknesses above. It turns a one-shot worker into a system that learns from experience. This section defines the concept and explains its inner workings step by step. The idea is simpler than it sounds, so let us walk through it.
A self-improving agent does its task, checks its own result, and learns from what happened. It writes down useful lessons, stores them in memory, and applies them next time. With each cycle, the agent gets a little sharper. This continuous loop is the heart of self-improvement.
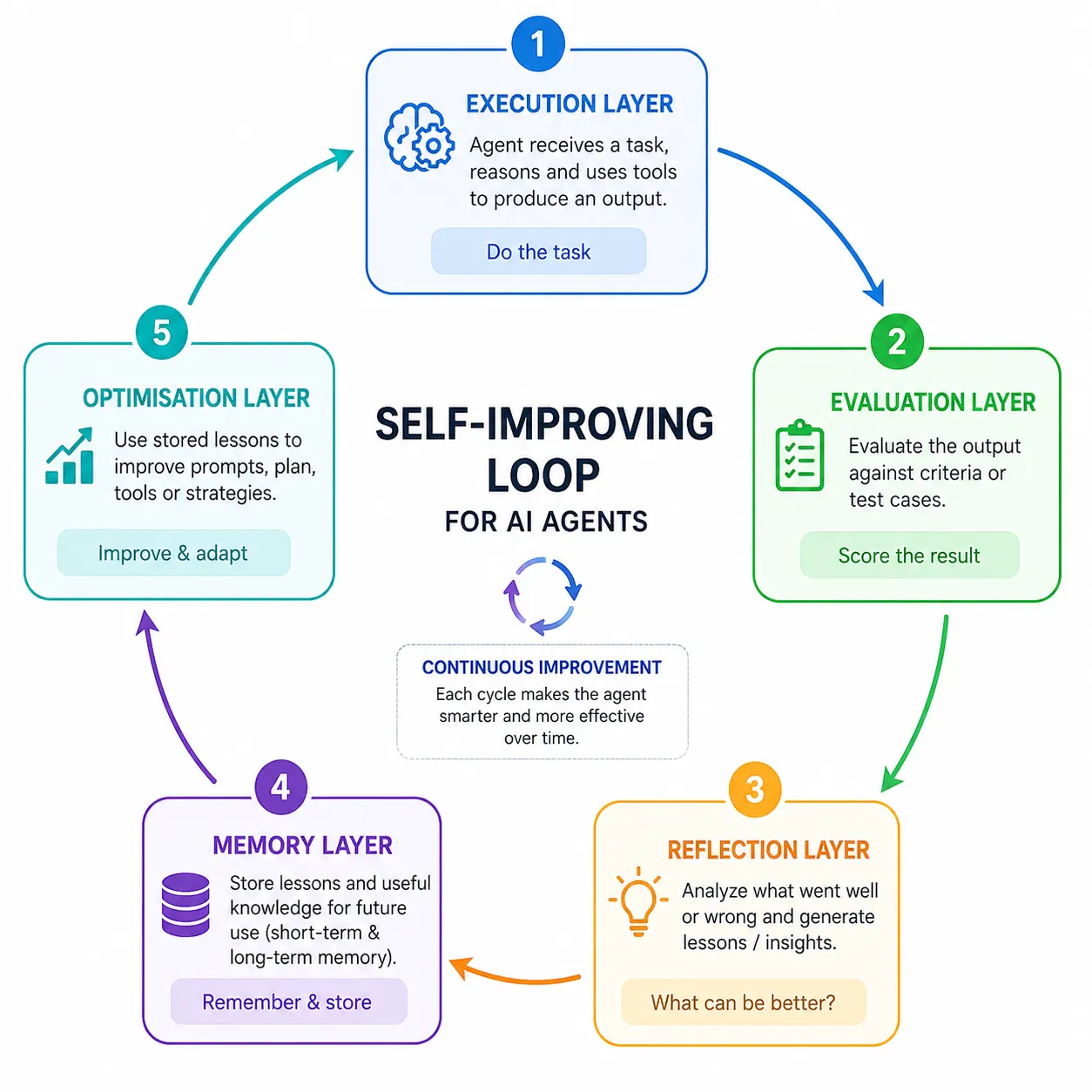
Why Self-Improvement Matters for Agent Performance
Self-improvement matters because it removes the need for constant human observation. The agent learns from real feedback instead of waiting for an engineer to fix it. This section highlights why that shift changes performance so dramatically.
- Fewer repeated errors: Some teams report sharp drops in repeated mistakes once memory is added.
- Higher task completion: Studies suggest memory-equipped agents complete far more multi-step tasks successfully.
- Less manual upkeep: The agent adapts on its own, so engineers spend less time rewriting prompts.
- Compounding gains: Small improvements stack over time, much like interest in a savings account.
Core Components of a Self-Improving Agent
A self-improving agent is built from five working layers. Each layer has one clear job, and together they form the loop. Understanding these five parts makes the whole system easy to picture.
- Execution Layer: The execution layer is the worker that does the task. It reads the request, reasons through a plan, and produces an output. This layer behaves much like a traditional agent on its own. The difference is that the other layers watch and guide it.
- Evaluation Layer: The evaluation layer acts as a strict judge of the output. It scores the result against clear quality checks or test cases.
- Reflection Layer: The reflection layer asks a simple question: what went wrong and why? It turns a low score into plain-language lessons the agent can reuse. This verbal feedback acts like a coach pointing out a specific weakness.
- Memory Layer: The memory layer stores the lessons, so they survive beyond a single task. Short-term memory holds the current conversation, while long-term memory holds lasting knowledge.
- Optimisation Layer: The optimisation layer applies stored lessons to improve future behaviour. It may refine the prompt, reorder steps, or pick better tools. Over many cycles, this layer reshapes how the agent works.
Self-Improving Loop vs Traditional Agent Workflow
Now we place both designs side by side to see the real difference. The contrast is sharpest when you watch how each one handles a mistake. This section compares architecture, workflow, and features in plain terms. The gap will become obvious very quickly.
Architectural Comparison
The two architectures differ mainly in what happens after the output is produced. A traditional agent stops at the output, while a self-improving agent keeps going. That single addition changes everything about long-term performance. Here is the structural difference in simple terms.
- Traditional agent: Prompt to reasoning to tools to output, then it stops.
- Self-improving agent: Prompt to reasoning to output, then evaluate, reflect, remember, and optimize.
- Memory: Traditional agents forget; self-improving agents store lessons across tasks.
- Feedback: Traditional agents have none; self-improving agents grade and correct themselves.
Workflow Comparison: Step-by-Step
Looking at the workflow as a sequence makes the difference very clear. Both start the same way but end very differently. Below are the two workflows written out plainly.
Traditional Agent Workflow: The traditional workflow is short and linear from start to finish. It does the job once and moves on. These are its typical steps.
- Read the prompt and the user request.
- Reason through a plan and call any tools.
- Produce the final output.
- Stop, with no review and no memory saved.
Self-Improving Loop Workflow: The self-improving workflow adds a feedback cycle after the first output. It refuses to settle for a weak result. These are its typical steps.
- Read the prompt and produce a first attempt.
- Evaluate the attempt against quality checks.
- Reflect on failures and write clear lessons.
- Save those lessons into long-term memory.
- Retry with the lessons applied, then reuse them on future tasks.
Feature-by-Feature Comparison Table
The table below summarizes the practical differences immediately. It covers the features that matter most for real projects. Use it as a quick reference when choosing a design.
| Feature | Traditional Agent | Self-Improving Loop Agent |
|---|---|---|
| Learning Capability | No learning after deployment; behaviour remains static. | Continuously learns from outcomes, feedback, and past experiences. |
| Memory Utilization | Forgets context and lessons after task completion. | Stores and retrieves knowledge for future tasks. |
| Error Reduction | Often repeats the same mistakes across similar tasks. | Identifies patterns in failures and reduces recurring errors over time. |
| Adaptability | Requires manual prompt updates or workflow changes. | Adapts automatically based on feedback and new information. |
| Scalability | Growth depends heavily on human maintenance and intervention. | Becomes more effective as its knowledge and experience increase. |
| Operational Efficiency | Performance remains relatively constant over time. | Performance improves and compounds with each iteration. |
Real-World Example: Research and Analysis Agent
Theory is helpful but seeing the loop run makes it click instantly. In this example, a Research and Analysis Agent answer market-research questions. A strong report must include market numbers, the top competitor, the key risk, and a cited source. We run the same tasks through both designs and compare the scores.
This version uses the real gpt-4o-mini model from OpenAI. The traditional agent is a single model call with a fixed prompt. The self-improving agent runs a LangGraph loop that grades and corrects itself. Non-technical readers can simply read the output and watch the scores rise.
Dependencies and API Key
Before running anything, install the libraries and set your OpenAI API key. These steps are the same for both agents shown below. The setup takes about a minute.
First, install the required Python packages from your terminal:
!pip install langgraph langchain-openai langchain-core pydanticNext, set your OpenAI API key as an environment variable:
export OPENAI_API_KEY="sk-your-key-here"Both agents share the same setup: the model, the dummy data, and a strict evaluator. We define that shared foundation once below, then build each agent on top of it. The base prompt is deliberately narrow, which is what the self-improving loop will later expand.
from typing import TypedDict, List, Dict
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
from langgraph.graph import StateGraph, START, END
# One model writes, a SEPARATE model grades.
# This is more reliable than self-grading.
gen_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3)
eval_llm_base = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Dummy data: three similar market-research tasks
TASKS = [
{
"id": "T1",
"question": "Should we launch an electric scooter in Pune in 2026?",
"facts": {
"market_size_units": 240000,
"yoy_growth_pct": 31,
"top_competitor": "Bolt Mobility",
"avg_price_inr": 95000,
"key_risk": "monsoon road flooding reduces ridership",
"source": "Pune Transport Authority 2025 report",
},
},
{
"id": "T2",
"question": "Should we launch an electric scooter in Jaipur in 2026?",
"facts": {
"market_size_units": 180000,
"yoy_growth_pct": 27,
"top_competitor": "Ather Energy",
"avg_price_inr": 102000,
"key_risk": "summer heat shortens battery life",
"source": "Rajasthan EV Council 2025 brief",
},
},
{
"id": "T3",
"question": "Should we launch an electric scooter in Kochi in 2026?",
"facts": {
"market_size_units": 130000,
"yoy_growth_pct": 22,
"top_competitor": "Ola Electric",
"avg_price_inr": 88000,
"key_risk": "limited charging stations outside the city",
"source": "Kerala Mobility Board 2025 survey",
},
},
]
PASS_MARK = 4 # all four checks must pass
MAX_ITERS = 4 # guardrail so the loop can never run forever
# The base brief is intentionally NARROW.
# Learned lessons expand it later.
BASE_SYSTEM = (
"You are a market-research analyst.\n"
"Write a short launch recommendation in 2-3 sentences.\n"
"Cover only the verdict and the market size and growth. Keep it brief."
)
def build_generator_system(lessons: List[str]) -> str:
system = BASE_SYSTEM
if lessons:
system += "\n\nAlways follow these learned rules as well:\n"
system += "\n".join(f"- {rule}" for rule in lessons)
return system
def facts_block(task: dict) -> str:
f = task["facts"]
return (
"FACTS:\n"
f"- Market size: {f['market_size_units']:,} units\n"
f"- Year-over-year growth: {f['yoy_growth_pct']}%\n"
f"- Top competitor: {f['top_competitor']}\n"
f"- Average price: INR {f['avg_price_inr']:,}\n"
f"- Key risk: {f['key_risk']}\n"
f"- Data source: {f['source']}"
)
def generate_report(task: dict, lessons: List[str]) -> str:
system = build_generator_system(lessons)
user = f"QUESTION: {task['question']}\n\n{facts_block(task)}"
response = gen_llm.invoke(
[SystemMessage(content=system), HumanMessage(content=user)]
)
return response.content.strip()
# Evaluation layer: a separate model returns a strict, structured score.
class Evaluation(BaseModel):
has_market_numbers: bool = Field(description="States market size and growth.")
names_competitor: bool = Field(description="Names the top competitor.")
states_key_risk: bool = Field(description="States the key risk.")
cites_source: bool = Field(description="Cites the data source.")
critique: str = Field(description="One short sentence on what to improve.")
evaluator = eval_llm_base.with_structured_output(Evaluation)
def evaluate_report(task: dict, report: str) -> Evaluation:
system = (
"You are a strict QA evaluator for market-research reports.\n"
"Compare the REPORT against the ground-truth FACTS.\n"
"Mark each element true ONLY if it is clearly present in the report."
)
user = (
f"{facts_block(task)}\n\n"
"REQUIRED ELEMENTS: market numbers, top competitor, key risk, cited source.\n\n"
f"REPORT:\n{report}"
)
return evaluator.invoke(
[SystemMessage(content=system), HumanMessage(content=user)]
)
def score_of(ev: Evaluation) -> int:
return (
int(ev.has_market_numbers)
+ int(ev.names_competitor)
+ int(ev.states_key_risk)
+ int(ev.cites_source)
)The Traditional Agent and Its Output
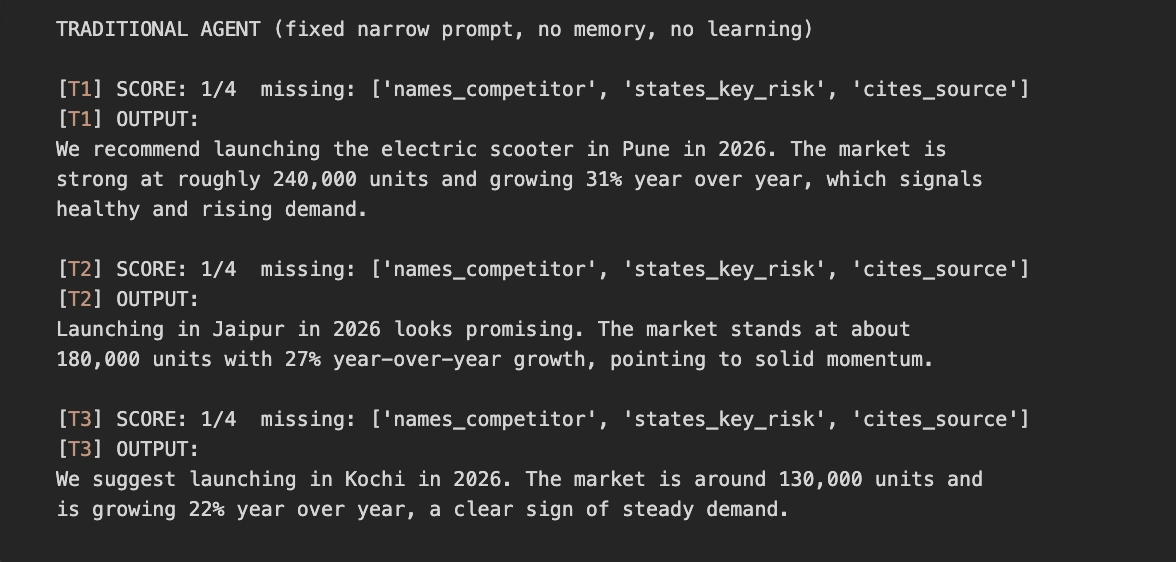
The traditional agent makes one model call per task using the fixed, narrow prompt. It has no loop and no memory, so it never learns. We still score its output, but only to measure quality. The agent itself never sees that feedback.
def run_traditional():
print("TRADITIONAL AGENT (fixed narrow prompt, no memory, no learning)")
for task in TASKS:
report = generate_report(task, lessons=[]) # never learns
ev = evaluate_report(task, report) # scored only to measure
flags = {
"has_market_numbers": ev.has_market_numbers,
"names_competitor": ev.names_competitor,
"states_key_risk": ev.states_key_risk,
"cites_source": ev.cites_source,
}
missing = [k for k, v in flags.items() if not v]
print(f"\n[{task['id']}] SCORE: {score_of(ev)}/4 missing: {missing or 'none'}")
print(f"[{task['id']}] OUTPUT:\n{report}")
run_traditional()Because the prompt only asks for a verdict and market size, the agent always omits the competitor, risk, and source. It repeats this same gap on every task. Here is a representative run, though your exact wording will vary because the model is not deterministic.
The Self-Improving Agent and Its Output
The self-improving agent runs a LangGraph loop instead of a single call. It generates a draft, evaluates it, reflects on the misses, stores lessons in memory, and retries. The lessons persist across tasks, so later tasks start smarter. The loop stops at a perfect score or the safety cap.
# Reflection layer: turn misses into reusable, plain-language lessons.
def reflect(ev: Evaluation) -> List[str]:
lessons = []
if not ev.has_market_numbers:
lessons.append("Always include the market size and year-over-year growth.")
if not ev.names_competitor:
lessons.append("Always name the top competitor and how to beat it.")
if not ev.states_key_risk:
lessons.append("Always state the single biggest risk to the launch.")
if not ev.cites_source:
lessons.append("Always cite the data source at the end of the report.")
return lessons
# LangGraph state shared between the loop nodes
class LoopState(TypedDict, total=False):
task: dict
lessons: List[str] # memory threaded in and out
report: str
score: int
flags: Dict[str, bool]
iterations: int
def node_generate(state: LoopState) -> dict:
attempt = state["iterations"] + 1
report = generate_report(state["task"], state["lessons"])
print(f" - generate (attempt {attempt})")
return {"report": report, "iterations": attempt}
def node_evaluate(state: LoopState) -> dict:
ev = evaluate_report(state["task"], state["report"])
flags = {
"has_market_numbers": ev.has_market_numbers,
"names_competitor": ev.names_competitor,
"states_key_risk": ev.states_key_risk,
"cites_source": ev.cites_source,
}
missing = [k for k, v in flags.items() if not v]
print(f" - evaluate -> score {score_of(ev)}/4, missing: {missing or 'none'}")
return {"score": score_of(ev), "flags": flags}
def node_reflect(state: LoopState) -> dict:
fake_ev = Evaluation(critique="", **state["flags"])
new_lessons = reflect(fake_ev)
merged = state["lessons"] + [
lesson for lesson in new_lessons if lesson not in state["lessons"]
]
print(f" - reflect -> added {len(new_lessons)} lesson(s)")
return {"lessons": merged}
def route(state: LoopState) -> str:
if state["score"] >= PASS_MARK or state["iterations"] >= MAX_ITERS:
return "done"
return "reflect"
# Build the loop: generate -> evaluate -> (reflect -> generate)* -> done
g = StateGraph(LoopState)
g.add_node("generate", node_generate)
g.add_node("evaluate", node_evaluate)
g.add_node("reflect", node_reflect)
g.add_edge(START, "generate")
g.add_edge("generate", "evaluate")
g.add_conditional_edges("evaluate", route, {"reflect": "reflect", "done": END})
g.add_edge("reflect", "generate")
app = g.compile()
def run_self_improving():
print("SELF-IMPROVING AGENT (LangGraph loop: reflect, remember, improve)")
memory: List[str] = [] # long-term memory, persists across tasks
for task in TASKS:
print(f"\n[{task['id']}] {task['question']}")
init: LoopState = {
"task": task,
"lessons": memory,
"report": "",
"score": 0,
"flags": {},
"iterations": 0,
}
final = app.invoke(init)
memory = final["lessons"] # carry lessons to the next task
print(
f"[{task['id']}] FINAL SCORE: {final['score']}/4 "
f"in {final['iterations']} attempt(s)"
)
print(f"[{task['id']}] FINAL OUTPUT:\n{final['report']}")
print("\nMEMORY CARRIED FORWARD:")
for rule in memory:
print(f" - {rule}")
run_self_improving()On the first task, the agent scores low, reflects, and saves three lessons. It then retries and reaches a perfect score. On the next two tasks, it passes on the first attempt because memory already holds the lessons. Here is a representative run, though your exact wording will vary.
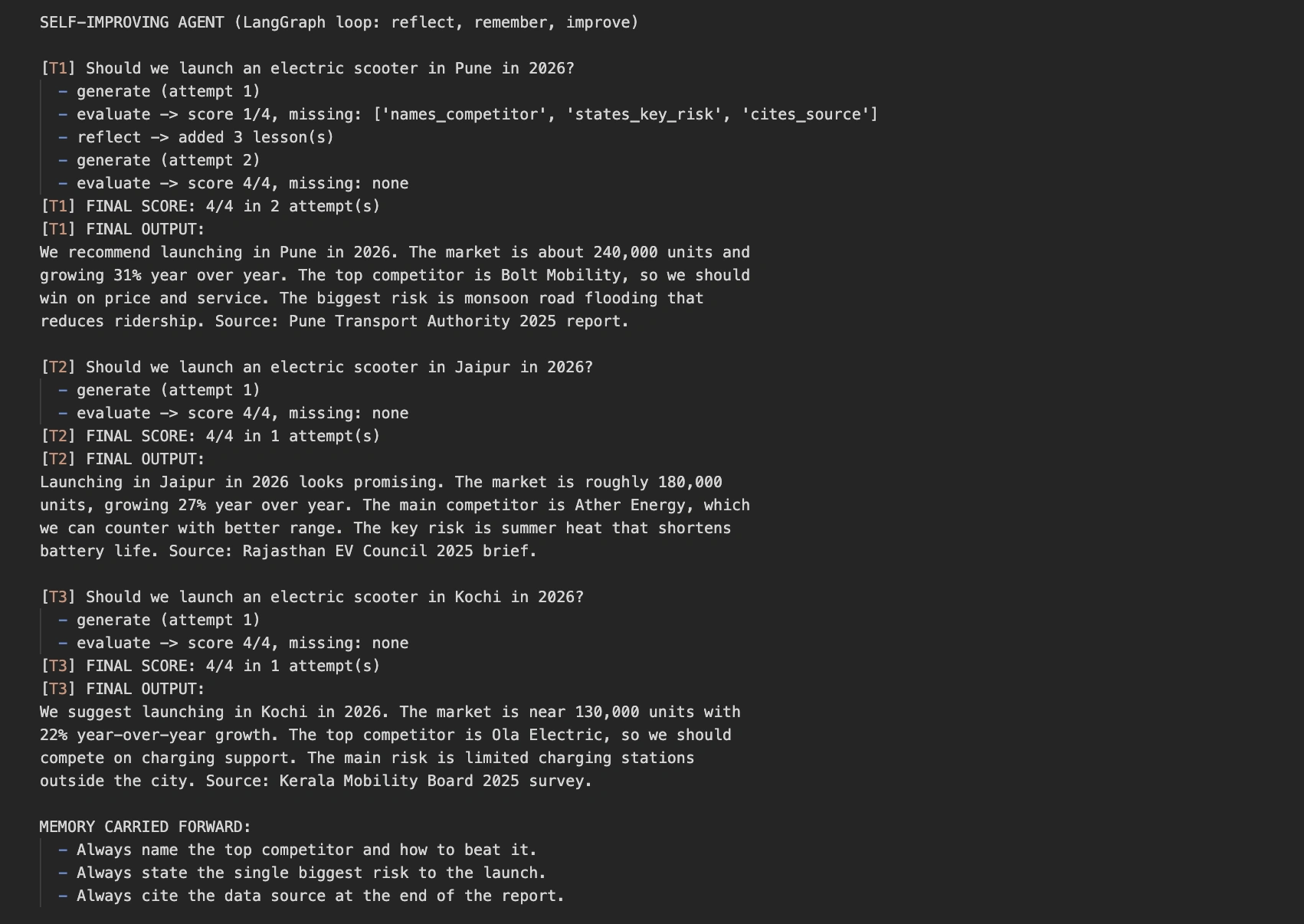
The contrast tells the whole story in two runs. The traditional agent stays stuck at 1 out of 4 on every task. The self-improving agent learns once, then aces every task that follows. That jump from repeated failure to reliable success is the power of the loop.
Key Technologies Behind Self-Improving Agents
Several proven technologies make the self-improving loop possible in real systems. You do not need all of them at once to start. Still, knowing the toolbox helps you design better agents. This section covers the five most important pieces.
- Reflection and Self-Critique Mechanisms: Reflection is the technique that lets an agent critique its own work in words. The agent reads its result, names the flaws, and writes guidance for next time.
- Agent Memory Systems: Memory is what lets reflection lessons survive across tasks and sessions. Without memory, an agent forgets everything the moment a task ends. Modern agents use a few distinct memory types together. Here is how each one works.
- Short-Term Memory: Short-term memory holds the current conversation or the active task details. It usually lives inside the model’s context window during one session.
- Long-Term Memory: Long-term memory stores knowledge that must survive across many sessions. It often uses a database or knowledge store that persists over time.
- Vector Database Memory: A vector database stores past experiences as numerical embeddings for smart recall. It finds memories by meaning, not by exact word matching.
- Evaluation and Feedback Systems: Evaluation systems decide whether the agent’s output is good enough. They use quality checks, test cases, or scoring rubrics to judge results.
- Reinforcement Learning and Agent Optimization: Reinforcement learning teaches an agent through rewards for good outcomes and penalties for bad ones. Over many trials, the agent learns which actions lead to success.
- Multi-Agent Collaboration for Self-Improvement: Sometimes one agent is not enough to catch every weakness. Multi-agent setups split the work among specialists who check each other.
Challenges and Limitations of Self-Improving Agents
Self-improving agents are powerful, but they are not magic. They bring real risks that teams must plan for carefully. Knowing these limits helps you adopt the approach safely. Here are the main challenges to watch.
- Degeneration of thought: An agent may keep defending a flawed answer instead of truly fixing it.
- Infinite loops: Without a stop rule, an agent can keep “improving” forever without converging.
- Bad memory writes: One wrong lesson saved to memory can poison many future tasks.
- Higher cost and latency: Extra evaluation and retries use more compute, time, and money.
- Weak self-evaluation: If the evaluator is poor, the agent learns the wrong lessons confidently.
- Safety and control: Agents that change their own behavior need guardrails and human oversight.
Verdict: Is the Self-Improving Loop the Future of AI Agents?
The honest answer is that both designs have a place in real products. The self-improving loop is not a complete replacement for every task. It shines in some settings and adds needless cost in others. This section gives a balanced verdict to guide your choice.
Where Traditional Agents Still Excel
Traditional agents remain the right tool for many simple, stable jobs. They cost less, run faster, and behave predictably. These are the cases where they still win.
- Simple, one-shot tasks: Quick lookups, short replies, and routine actions need no learning loop.
- Latency-critical apps: When speed is everything, extra evaluation steps only slow things down.
- Tight budgets: Fewer model calls mean lower cost for high-volume, low-complexity work.
- Highly regulated steps: Predictable behavior is easier to certify and audit.
Where Self-Improving Agents Create the Most Value
Self-improving agents earn their keep on hard, repeated, high-stakes work. The learning loop pays off when quality and adaptation truly matter. These are the cases where they shine.
- Complex, multi-step tasks: Research, coding, and analysis benefit from iterative refinement.
- Changing environments: Markets, policies, and data that shift reward an agent that adapts.
- Repeated workflows: Lessons learned once pay off across thousands of similar future tasks.
- Accuracy-critical work: Domains where mistakes are costly justify the extra checks.
If you need help figuring out the right vector database for your needs refer to Choosing the Right Vector Database.
Frequently Asked Questions
Q1. What is the self-improving loop in AI agents?
A. It is an AI agent architecture where agents evaluate outputs, reflect on mistakes, store lessons, and improve future task performance.
Q2. How does self-improving agent architecture work?
A. It uses execution, evaluation, reflection, memory, and optimisation layers to create feedback loops that help AI agents learn from results.
Q3. How is a self-improving agent better than traditional agents?
A. Traditional agents forget past errors, while self-improving agents use memory and feedback to reduce repeated mistakes over time.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.





