Modern AI applications rely on understanding meaning rather than matching keywords. As large language models, semantic search, and RAG systems have become mainstream, vector databases have emerged as critical infrastructure for storing and retrieving high-dimensional embeddings at scale.
Choosing the right vector database can have a major impact on performance, scalability, cost, and developer experience. In this article, we’ll compare six leading vector databases like Pinecone, Weaviate, Qdrant, Milvus, pgvector, and ChromaDB, to help you identify the best fit for your use case.
Table of contents
Understanding Vector Databases
Before looking at particular databases, you have to get what vector databases are, and also why they even matter. Traditional databases keep structured rows and columns. Vector databases, on the other hand, store something that feels way more abstract mathematical patterns of meaning, often called embeddings.
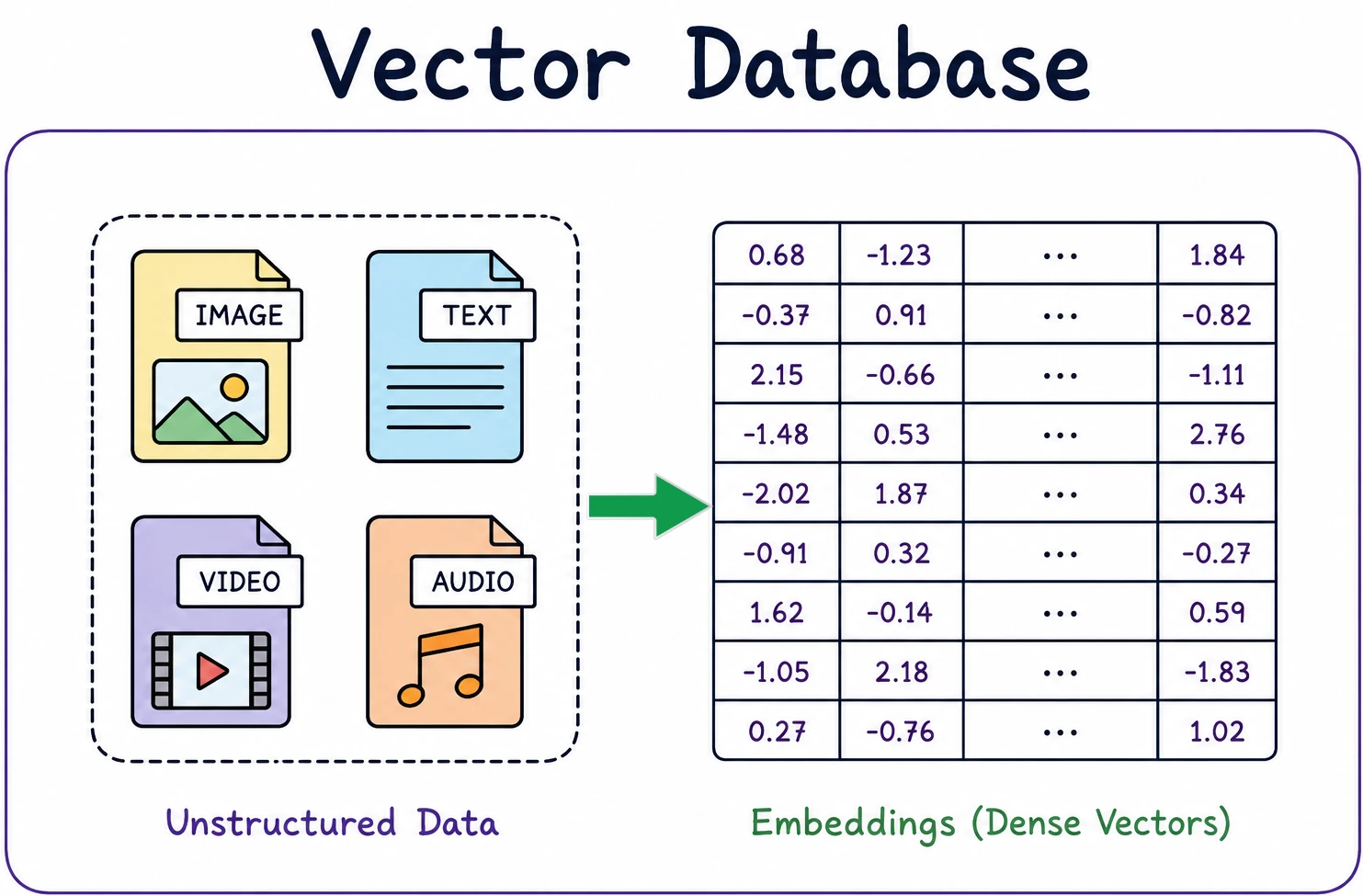
What Is a Vector Database?
A vector database is basically a specialized storage system built to store and also query high-dimensional vector data. Imagine a vector as one long arrangement of numbers. For example, [0.12, -0.45, 0.78, …] , it is encoding the semantic substance of a certain piece of content. One sentence can turn into a vector with 384 values, or sometimes 1536, depending on the model.
Then, when you end up with many, many thousands of those vectors, you can’t just brute force search them every time. You need an efficient method to quickly retrieve the vectors that are most similar to some question or input. And that’s basically what a vector database is for. It arranges vectors so that nearest-neighbor lookups run extremely fast.
What Are Embeddings?
Embeddings are kind of numerical representations of data that are generated by machine learning models, sort of outputs. An embedding model takes in your text image, or audio and then spits out a fixed-size array of floats. Those numbers, they end up reflecting semantic relationships. Like, “king” and “queen” would end up with embeddings that are nearer to each other than “king” and “bicycle”.
Some of the most widely used embedding models are:
- OpenAI text-embedding-3-small: 1536 dimensions, excellent quality
- sentence-transformers/all-MiniLM-L6-v2: 384 dimensions, free and fast
- Cohere embed-v3: 1024 dimensions, great multilingual support
- Google text-embedding-004: 768 dimensions, strong general-purpose model
The embedding model you end up choosing really impacts the quality of your vector search, no joke. For best results always stick with the same model for indexing and also for querying, otherwise things can drift.
How Vector Search Works
Vector search is basically about finding items that are semantically similar to a query. You take your query, convert it into a vector, and then ask the database to look for stored vectors that are “close” to it. The database typically relies on approximate nearest-neighbor algorithms, or ANN, so it can locate good matches without having to scan every single vector one by one
Three main similarity measures power vector search are:
- Cosine Similarity: Cosine similarity looks at the angle between two vectors. A score of 1 means they’re pointing in the same direction, which is close to identical. 0 signals they’re unrelated. -1 they’re opposite, kind of negating each other.
cosine_similarity(A, B) = (A · B) / (||A|| × ||B||) - Euclidean Distance: Euclidean distance measures the straight line distance between two points in a high dimensional space.
euclidean_distance(A, B) = √(Σ(Aᵢ – Bᵢ)²) - Dot Product Similarity: Dot product multiplies corresponding elements, then adds them together. In practice a higher dot product usually suggests stronger resemblance or greater similarity.
dot_product(A, B) = Σ(Aᵢ × Bᵢ)
Why Traditional Databases Struggle with Semantic Search
SQL databases like PostgreSQL and MySQL are pretty great at exact queries: WHERE name = 'John' or WHERE price < 100. But things get weird, when you ask “Find me documents that are conceptually similar to this query.”
A traditional database can’t really grasp that “automobile” and “car” are basically the same vibe. It matches what it sees, characters and symbols, not the actual meaning. Full-text search can help a bit, sure, but it still leans on keyword overlap, and that’s kind of the core issue. For AI apps this becomes a big limitation, like not even close to solved.
Vector databases handle this differently. They index vector embeddings using specialized techniques such as HNSW, (Hierarchical Navigable Small World) and IVF (Inverted File Index). These methods create graph like paths and partitions, so you can locate nearby vectors in milliseconds, even when you’re dealing with billions of entries.
Common Vector Database Use Cases
Vector databases are very versatile and used in powering many of the AI features. Some of the most important use cases are:
- Retrieval-Augmented Generation (RAG)
- Semantic Search
- Recommendation Systems
- AI Agent Memory
- Multimodal Search
Quick Comparison
Each of these databases takes a different approaches. Some are fully managed cloud services, while others are open-source engines you deploy yourself. A few also extend existing databases, not always from scratch. Each one has a distinct philosophy about ease of use, performance and flexibility, and it kinda changes how you experience everything.
| Database | Type | Best For | Hybrid Search | Scalability | Typical Cost |
| Pinecone | Managed Cloud | Production SaaS, managed infrastructure | Native support | Billions of vectors | ~$70–$100/month |
| Weaviate | Open Source / Cloud | Feature-rich AI applications | Native support | Hundreds of millions | Free if self-hosted |
| Qdrant | Open Source / Cloud | Cost-efficient RAG and semantic search | Native support | Billions of vectors | Free if self-hosted |
| Milvus | Open Source / Cloud | Large-scale distributed AI systems | Native support | Billions+ vectors | Free if self-hosted |
| pgvector | PostgreSQL Extension | Existing PostgreSQL-based applications | Partial support | Tens of millions | ~$20–$50/month |
| ChromaDB | Open Source | Local development and prototyping | Not supported | Millions of vectors | Free |
Let’s understand each one by one.
Creating a Sample Dataset
Before jumping into the these vector databases individually. Lets create a sample dataset first.
# Dummy dataset of AI/ML articles
documents = [
{
"id": "doc_001",
"title": "Introduction to Machine Learning",
"text": (
"Machine learning enables computers to learn from data without "
"explicit programming. It uses statistical algorithms to identify "
"patterns and make predictions with minimal human intervention."
),
"category": "ML Basics",
"author": "John Smith",
"year": 2023,
"rating": 4.8,
},
{
"id": "doc_002",
"title": "Deep Learning and Neural Networks",
"text": (
"Deep learning uses multi-layered neural networks to process "
"complex data. It has revolutionized image recognition, natural "
"language processing, and speech synthesis systems."
),
"category": "Deep Learning",
"author": "Sarah Johnson",
"year": 2023,
"rating": 4.7,
},
{
"id": "doc_003",
"title": "Transformer Architecture Explained",
"text": (
"Transformers rely on self-attention mechanisms to process "
"sequential data in parallel. They became the backbone of large "
"language models like GPT-4 and Claude."
),
"category": "NLP",
"author": "Michael Chen",
"year": 2024,
"rating": 4.9,
},
{
"id": "doc_004",
"title": "Retrieval-Augmented Generation (RAG)",
"text": (
"RAG combines retrieval systems with generative models to produce "
"factually accurate responses. It significantly reduces AI "
"hallucination by grounding answers in retrieved source documents."
),
"category": "RAG",
"author": "Emily Davis",
"year": 2024,
"rating": 4.9,
},
{
"id": "doc_005",
"title": "Vector Databases for AI Applications",
"text": (
"Vector databases store high-dimensional embeddings and enable "
"semantic search. They power fast nearest-neighbor lookups across "
"millions of vectors in milliseconds."
),
"category": "Databases",
"author": "Robert Wilson",
"year": 2024,
"rating": 4.6,
},
{
"id": "doc_006",
"title": "Fine-tuning Large Language Models",
"text": (
"Fine-tuning adapts pre-trained LLMs for specific domains or "
"tasks. It requires far less data and compute than training "
"models entirely from scratch."
),
"category": "LLM",
"author": "Lisa Anderson",
"year": 2024,
"rating": 4.7,
},
{
"id": "doc_007",
"title": "Prompt Engineering Best Practices",
"text": (
"Prompt engineering designs effective inputs to guide AI model "
"outputs. Techniques like chain-of-thought reasoning and few-shot "
"examples significantly boost response quality."
),
"category": "Prompting",
"author": "David Brown",
"year": 2024,
"rating": 4.5,
},
{
"id": "doc_008",
"title": "AI Agents and Autonomous Systems",
"text": (
"AI agents autonomously complete tasks by planning and executing "
"multi-step workflows. They combine LLMs with external tools like "
"web search, code execution, and persistent memory."
),
"category": "Agents",
"author": "Jennifer Taylor",
"year": 2024,
"rating": 4.8,
},
{
"id": "doc_009",
"title": "Reinforcement Learning from Human Feedback",
"text": (
"RLHF trains AI models to align with human preferences using "
"reward signals. It played a central role in making ChatGPT "
"helpful and safe for public use."
),
"category": "RL",
"author": "James Martinez",
"year": 2023,
"rating": 4.6,
},
{
"id": "doc_010",
"title": "Multimodal AI Systems",
"text": (
"Multimodal AI processes text, images, audio, and video "
"simultaneously. Models like GPT-4V and Gemini can reason across "
"different types of input data."
),
"category": "Multimodal",
"author": "Rachel Lee",
"year": 2024,
"rating": 4.8,
},
]Now, we’ll use this dataset in each of the database.
Pinecone
Pinecone is a fully managed vector database built specifically for machine learning stuff. Developers typically work with it through a simple REST API or gRPC, and it feels straightforward overall. Pinecone stores your vectors inside indexes, supports rich metadata filtering, and lets you choose serverless deployments deployment modes depending on how you want to operate.
Pinecone was one of the first vector database solutions made for a purpose. The API design is clean, the documentation is strong, and the whole “zero-ops” model is a huge reason it became a go to option for many early RAG projects, plus a bunch of LLM powered products.
Core Architecture
Pinecone’s architecture kind of abstracts away all the infrastructure stuff completely. You end up interacting with indexes and namespaces not really with nodes and shards.
- Managed Infrastructure: Pinecone runs fully on their cloud. So all the hardware provisioning, fault tolerance, replication and scaling happens automatically behind the scenes. When your data starts growing, Pinecone scales without you doing anything. That basically means your team can focus only on application logic rather than on DevOps, or the whole operational grind.
- Serverless Architecture: Also, Pinecone’s serverless tier separates compute from storage. You only pay for the reads and the writes you perform, which makes it cost-effective, especially when the traffic pattern is variable.
- Index Management: A Pinecone index is the main storage unit. Each index keeps vectors of a fixed dimension using a selected similarity metric, like cosine, euclidean, or dot product.
Getting Started with Pinecone
Let’s switch from theory to practice. The code examples below use a consistent dataset of AI and machine learning articles for the whole guide.
Installation and Setup
pip install pinecone sentence-transformers Once you have installed pinecone, follow the below steps to create a pinecone vector database.
from pinecone import Pinecone, ServerlessSpec
# Initialize Pinecone client with your API key
pc = Pinecone(api_key="pcsk_your_api_key_here")
print("Pinecone client initialized successfully")
print(f"Available indexes: {pc.list_indexes().names()}")Output:
Pinecone client initialized successfully
Available indexes: []
Creating an Index
# Create a serverless index with 384 dimensions for all-MiniLM-L6-v2
index_name = "ai-knowledge-base"
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=384,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1",
),
)
print(f"Index '{index_name}' created successfully")
else:
print(f"Index '{index_name}' already exists")
# Connect to the index
index = pc.Index(index_name)
print(f"\nIndex stats: {index.describe_index_stats()}")Storing Embeddings
from sentence_transformers import SentenceTransformer
import time
# Load the embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
# Generate embeddings for all documents
print("Generating embeddings...")
vectors = []
for doc in documents:
embedding = model.encode(doc["text"]).tolist()
vectors.append(
{
"id": doc["id"],
"values": embedding,
"metadata": {
"title": doc["title"],
"category": doc["category"],
"author": doc["author"],
"year": doc["year"],
"rating": doc["rating"],
},
}
)
print(f"Embedded: {doc['id']} — {doc['title']}")
# Upsert vectors into the index in batches
batch_size = 5
for i in range(0, len(vectors), batch_size):
batch = vectors[i : i + batch_size]
index.upsert(vectors=batch)
print(f"\nUpserted batch {i // batch_size + 1} ({len(batch)} vectors)")
# Allow Pinecone to index the vectors
time.sleep(2)
print("\nFinal index stats:")
print(index.describe_index_stats())Output:
Generating embeddings...
Embedded: doc_001 — Introduction to Machine Learning
Embedded: doc_002 — Deep Learning and Neural Networks
Embedded: doc_003 — Transformer Architecture Explained
Embedded: doc_004 — Retrieval-Augmented Generation (RAG)
Embedded: doc_005 — Vector Databases for AI Applications
Embedded: doc_006 — Fine-tuning Large Language Models
Embedded: doc_007 — Prompt Engineering Best Practices
Embedded: doc_008 — AI Agents and Autonomous Systems
Embedded: doc_009 — Reinforcement Learning from Human Feedback
Embedded: doc_010 — Multimodal AI Systems
Upserted batch 1 (5 vectors)
Upserted batch 2 (5 vectors)
Final index stats:
{
"dimension": 384,
"index_fullness": 0.00001,
"namespaces": {
"": {
"vector_count": 10
}
},
"total_vector_count": 10
}
Performing Similarity Search
# Query the index with a natural language question
query_text = "How do large language models work?"
query_embedding = model.encode(query_text).tolist()
results = index.query(
vector=query_embedding,
top_k=3,
include_metadata=True,
)
print(f"Query: '{query_text}'\n")
print("Top 3 Similar Documents:")
print("-" * 60)
for i, match in enumerate(results["matches"], 1):
print(f"Rank {i}:")
print(f" ID : {match['id']}")
print(f" Score : {match['score']:.4f}")
print(f" Title : {match['metadata']['title']}")
print(f" Category : {match['metadata']['category']}")
print(f" Author : {match['metadata']['author']}")
print()Output:
Query: 'How do large language models work?'
Top 3 Similar Documents:
------------------------------------------------------------
Rank 1:
ID : doc_003
Score : 0.7841
Title : Transformer Architecture Explained
Category : NLP
Author : Michael Chen
Rank 2:
ID : doc_006
Score : 0.7134
Title : Fine-tuning Large Language Models
Category : LLM
Author : Lisa Anderson
Rank 3:
ID : doc_001
Score : 0.6523
Title : Introduction to Machine Learning
Category : ML Basics
Author : John SmithWeaviate
Weaviate is this cloud-native, open-source vector database that is written in Go. It mixes vector similarity lookup with structured filtering and also does hybrid search (vector + BM25), plus there is optional built-in ML inference tucked in there. You can run it yourself using Docker, or straight up Kubernetes, or you can go with the managed Weaviate Cloud Services (WCS) instead.
In Weaviate, data is arranged into classes, kind of like tables, and each class has a defined schema. Every object inside a class can hold properties, like text, numbers, or dates, together with its vector. This whole setup gives you the flexibility of a document storage model with the power of vector search, not just one or the other.
Core Architecture
Weaviate has this kind of modular setup, not just a single box. You can extend it with vectorizer modules, generative modules, and reranker modules, all kinda plug-in-ish. The core engine stays responsible for storage and retrieval, while the modules then layer on top the ML stuff, so yeah.
- Object-Based Storage Model: In practice Weaviate keeps each item as a data object with a UUID, some properties, and a vector. Those objects are grouped into classes too. This feels different from Pinecone or Qdrant, where you often store raw vectors and metadata, kinda more straight forward. With Weaviate’s object model you can do richer data queries, mixing structured constraints with semantic matching in the same go.
- Built-In Vectorization: The vectorizer modules in Weaviate, like text2vec-openai, text2vec-cohere, text2vec-transformers, can generate embeddings automatically when you insert data. So you don’t have to pre-compute the embeddings yourself ahead of time. That alone is a real productivity boost especially for teams juggling multiple data types and formats.
- Hybrid Search Engine: And there’s the search part. Weaviate natively blends vector search with BM25 keyword search. When you run hybrid queries, results come back scored by both approaches, then they get merged using a fusion algorithm, sorta like a combined ranking. The result is usually: semantic relevance plus keyword precision, without having to choose only one.
Getting Started with Weaviate
Installation and Setup
pip install weaviate-client sentence-transformers Once you have installed weaviate, follow the below steps to create a pinecone vector database.
# Run Weaviate locally via Docker
docker run -d \
--name weaviate \
-p 8080:8080 \
-p 50051:50051 \
-e QUERY_DEFAULTS_LIMIT=25 \
-e AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED=true \
-e PERSISTENCE_DATA_PATH=/var/lib/weaviate \
cr.weaviate.io/semitechnologies/weaviate:1.26.1import weaviate
import weaviate.classes as wvc
# Connect to local Weaviate instance
client = weaviate.connect_to_local()
print(f"Weaviate connected: {client.is_ready()}")
print(f"Weaviate version: {client.get_meta()['version']}")Output:
Weaviate connected: True
Weaviate version: 1.26.1
Defining Schemas
from weaviate.classes.config import Property, DataType, Configure, VectorDistances
# Delete collection if it already exists for a clean demo
if client.collections.exists("AIArticle"):
client.collections.delete("AIArticle")
# Create the AIArticle collection with a custom schema
articles_collection = client.collections.create(
name="AIArticle",
description="A collection of AI and ML educational articles",
vectorizer_config=Configure.Vectorizer.none(), # We supply our own vectors
vector_index_config=Configure.VectorIndex.hnsw(
distance_metric=VectorDistances.COSINE,
),
properties=[
Property(name="doc_id", data_type=DataType.TEXT),
Property(name="title", data_type=DataType.TEXT),
Property(name="text", data_type=DataType.TEXT),
Property(name="category", data_type=DataType.TEXT),
Property(name="author", data_type=DataType.TEXT),
Property(name="year", data_type=DataType.INT),
Property(name="rating", data_type=DataType.NUMBER),
],
)
print("Collection 'AIArticle' created successfully")
print(
"Collection properties:",
[p.name for p in articles_collection.config.get().properties],
)Output:
Collection 'AIArticle' created successfully
Collection properties: ['doc_id', 'title', 'text', 'category', 'author', 'year', 'rating']
Inserting Data
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Use the same document dataset as before
collection = client.collections.get("AIArticle")
print("Inserting documents into Weaviate...\n")
with collection.batch.dynamic() as batch:
for doc in documents:
embedding = model.encode(doc["text"]).tolist()
batch.add_object(
properties={
"doc_id": doc["id"],
"title": doc["title"],
"text": doc["text"],
"category": doc["category"],
"author": doc["author"],
"year": doc["year"],
"rating": doc["rating"],
},
vector=embedding,
)
print(f"Inserted: {doc['id']} — {doc['title']}")
total_count = collection.aggregate.over_all(total_count=True).total_count
print(f"\nTotal objects in collection: {total_count}")Output:
Inserting documents into Weaviate...
Inserted: doc_001 — Introduction to Machine Learning
Inserted: doc_002 — Deep Learning and Neural Networks
Inserted: doc_003 — Transformer Architecture Explained
Inserted: doc_004 — Retrieval-Augmented Generation (RAG)
Inserted: doc_005 — Vector Databases for AI Applications
Inserted: doc_006 — Fine-tuning Large Language Models
Inserted: doc_007 — Prompt Engineering Best Practices
Inserted: doc_008 — AI Agents and Autonomous Systems
Inserted: doc_009 — Reinforcement Learning from Human Feedback
Inserted: doc_010 — Multimodal AI Systems
Total objects in collection: 10
Running Vector Searches
from weaviate.classes.query import MetadataQuery
query = "How do transformer models use attention mechanisms?"
query_vec = model.encode(query).tolist()
results = collection.query.near_vector(
near_vector=query_vec,
limit=3,
return_metadata=MetadataQuery(distance=True),
return_properties=["doc_id", "title", "category", "author", "rating"],
)
print(f"Query: '{query}'\n")
print("Top 3 Results:")
print("-" * 60)
for i, obj in enumerate(results.objects, 1):
print(f"Rank {i}:")
print(f" Title : {obj.properties['title']}")
print(f" Category : {obj.properties['category']}")
print(f" Author : {obj.properties['author']}")
print(f" Rating : {obj.properties['rating']}")
print(f" Distance : {obj.metadata.distance:.4f}")
print()Output:
Query: 'How do transformer models use attention mechanisms?'
Top 3 Results:
------------------------------------------------------------
Rank 1:
Title : Transformer Architecture Explained
Category : NLP
Author : Michael Chen
Rating : 4.9
Distance : 0.1823
Rank 2:
Title : Deep Learning and Neural Networks
Category : Deep Learning
Author : Sarah Johnson
Rating : 4.7
Distance : 0.3241
Rank 3:
Title : Fine-tuning Large Language Models
Category : LLM
Author : Lisa Anderson
Rating : 4.7
Distance : 0.3789
Qdrant
Qdrant (pronounced “quadrant”) is an open-source vector similarity search engine, built in Rust. In it, vectors get stored in collections, and each vector point also comes with JSON payloads. It can do filtering really well, supports quantization, also lets you keep named vectors per point, and overall it has one of the most expressive filtering systems you’ll find in the vector database world, at least among the usual suspects.
You can run Qdrant as a single node, or spread it across a cluster in distributed mode, or simply use Qdrant Cloud if you want the managed path. The Rust foundation makes it extremely memory-efficient and fast, like, in a practical sense.
Core Architecture
Qdrant’s architecture is kinda elegant, on purpose, like it really leans into fast search and not wasting resources. I mean every design choice seems to be aimed at that, speed first, then efficiency, pretty consistently.
- HNSW-Based Search: Under the hood, Qdrant builds HNSW (Hierarchical Navigable Small World) graphs for quick approximate nearest-neighbor search. The HNSW approach arranges vectors inside a layered graph, where the top levels keep longer-range connections, while the lower levels focus on tighter neighborhood links. Because of that layering, searching can stay around logarithmic-time even when you’re dealing with billions of vectors, which is kind of the whole point.
- Payload Storage and Filtering: Also, every vector point in Qdrant carries a JSON payload. Those payloads are indexed separately, and they enable filtering conditions that feel pretty flexible. Qdrant can filter before the vector search step (pre-filtering) or afterward (post-filtering), so you get sharp control over what results come back. The filtering features cover nested JSON, arrays, geo-coordinates, and range queries, not just the basic stuff.
- Quantization Support: On top of that Qdrant supports scalar quantization (SQ), product quantization (PQ), and binary quantization. These methods compress vectors in memory while aiming to keep recall high. Binary quantization can cut memory usage by 32x, with only minimal accuracy drop, which matters a lot when you’re pushing a big-scale production setup, where every byte counts.
Getting Started with Qdrant
Installation and Setup
pip install qdrant-client sentence-transformers Once you have installed weaviate, follow the below steps to create a Qdrant vector database.
# Run Qdrant locally via Docker
docker run -d \
--name qdrant \
-p 6333:6333 \
-p 6334:6334 \
-v qdrant_storage:/qdrant/storage \
qdrant/qdrant:latestfrom qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
# Connect to local Qdrant instance
client = QdrantClient(url="http://localhost:6333")
# Or use in-memory mode for quick prototyping
# client = QdrantClient(":memory:")
info = client.get_collections()
print("Qdrant connected successfully")
print(f"Existing collections: {[c.name for c in info.collections]}")Output:
Qdrant connected successfully
Existing collections: []
Creating Collections
from qdrant_client.models import Distance, VectorParams, OptimizersConfigDiff
collection_name = "ai_knowledge_base"
# Delete collection if it already exists for a clean demo
if client.collection_exists(collection_name):
client.delete_collection(collection_name)
# Create collection with HNSW index and cosine distance
client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(
size=384,
distance=Distance.COSINE,
on_disk=False, # Keep in memory for fastest search
),
optimizers_config=OptimizersConfigDiff(
indexing_threshold=10_000, # Build HNSW after 10k vectors
),
)
collection_info = client.get_collection(collection_name)
print(f"Collection '{collection_name}' created")
print(f" Vector size : {collection_info.config.params.vectors.size}")
print(f" Distance : {collection_info.config.params.vectors.distance}")
print(f" Status : {collection_info.status}")
print(f" Point count : {collection_info.points_count}")Output:
Collection 'ai_knowledge_base' created
Vector size : 384
Distance : Distance.COSINE
Status : CollectionStatus.GREEN
Point count : 0
Inserting Vectors
from qdrant_client.models import PointStruct
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Build PointStruct objects with payload
print("Generating embeddings and preparing points...\n")
points = []
for i, doc in enumerate(documents):
embedding = model.encode(doc["text"]).tolist()
points.append(
PointStruct(
id=i + 1, # Qdrant IDs must be integers or UUIDs
vector=embedding,
payload={
"doc_id": doc["id"],
"title": doc["title"],
"text": doc["text"],
"category": doc["category"],
"author": doc["author"],
"year": doc["year"],
"rating": doc["rating"],
},
)
)
print(f"Prepared point {i + 1}: {doc['title']}")
# Upload all points in a single batch
operation_info = client.upsert(
collection_name=collection_name,
wait=True,
points=points,
)
points_count = client.get_collection(collection_name).points_count
print(f"\nUpsert status : {operation_info.status}")
print(f"Points in DB : {points_count}")Output:
Generating embeddings and preparing points...
Prepared point 1: Introduction to Machine Learning
Prepared point 2: Deep Learning and Neural Networks
Prepared point 3: Transformer Architecture Explained
Prepared point 4: Retrieval-Augmented Generation (RAG)
Prepared point 5: Vector Databases for AI Applications
Prepared point 6: Fine-tuning Large Language Models
Prepared point 7: Prompt Engineering Best Practices
Prepared point 8: AI Agents and Autonomous Systems
Prepared point 9: Reinforcement Learning from Human Feedback
Prepared point 10: Multimodal AI Systems
Upsert status : UpdateStatus.COMPLETED
Points in DB : 10
Running Searches
query = "How do neural networks learn from training data?"
query_vec = model.encode(query).tolist()
# Basic vector search
results = client.search(
collection_name=collection_name,
query_vector=query_vec,
limit=3,
with_payload=True,
score_threshold=0.3,
)
print(f"Query: '{query}'\n")
print("Top 3 Results:")
print("-" * 60)
for i, hit in enumerate(results, 1):
print(f"Rank {i}:")
print(f" Title : {hit.payload['title']}")
print(f" Category : {hit.payload['category']}")
print(f" Author : {hit.payload['author']}")
print(f" Year : {hit.payload['year']}")
print(f" Score : {hit.score:.4f}")
print()Output:
Query: 'How do neural networks learn from training data?'
Top 3 Results:
------------------------------------------------------------
Rank 1:
Title : Deep Learning and Neural Networks
Category : Deep Learning
Author : Sarah Johnson
Year : 2023
Score : 0.8124
Rank 2:
Title : Introduction to Machine Learning
Category : ML Basics
Author : John Smith
Year : 2023
Score : 0.7891
Rank 3:
Title : Reinforcement Learning from Human Feedback
Category : RL
Author : James Martinez
Year : 2023
Score : 0.6734
Milvus
Milvus is this open-source, cloud-native vector database that’s built for billion-scale similarity search. At first it was developed by Zilliz, then donated to the Linux Foundation as an open-source effort. Milvus kinda splits storage and compute, it relies on a message queue for durability, and it supports a bunch of different index types so you can match different performance tradeoffs.
There’s also a lighter variant called Milvus Lite, it runs embedded in Python, no server setup really, which makes it pretty convenient for local development and smaller datasets.
Core Architecture
- Distributed Storage Layer: When you compare the databases in this guide, Milvus has the most sophisticated architecture. It’s also built on the same distributed systems mindset you see in Apache Kafka or Kubernetes.
- Query Nodes: In Milvus, storage is separated from compute in a pretty strict way. The raw vector data lives in an object storage system like MinIO or Amazon S3. Meanwhile, the metadata and coordination information is stored in etcd. With this split, you can scale compute, like query nodes, and scale storage, like the object store, independently, instead of scaling everything together.
- Index Management: Milvus also supports more index types than any other database in this guide:
- HNSW: Best recall, higher memory usage
- IVF_FLAT: Good balance of speed and accuracy
- IVF_SQ8: Quantized for lower memory usage
- DiskANN: Disk-based index for very large datasets that don’t fit in RAM
- GPU_IVF_FLAT: GPU-accelerated for massive throughput
Getting Started with Milvus
Installation and Setup
pip install pymilvus sentence-transformersfrom pymilvus import MilvusClient
# Use Milvus Lite for local development; no server needed
client = MilvusClient("ai_knowledge_base.db")
print("Milvus Lite connected successfully")
print(f"Existing collections: {client.list_collections()}")Output:
Milvus Lite connected successfully
Existing collections: []
Creating Collections
from pymilvus import MilvusClient
COLLECTION_NAME = "ai_articles"
VECTOR_DIM = 384
# Drop collection if it already exists
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
print(f"Dropped existing collection: {COLLECTION_NAME}")
# Create collection with schema
client.create_collection(
collection_name=COLLECTION_NAME,
dimension=VECTOR_DIM,
metric_type="COSINE",
auto_id=False,
primary_field_name="id",
vector_field_name="embedding",
)
print(f"Collection '{COLLECTION_NAME}' created successfully")
print(f" Dimension : {VECTOR_DIM}")
print(" Metric type : COSINE")
print(f" Collections : {client.list_collections()}")Output:
Collection 'ai_articles' created successfully
Dimension : 384
Metric type : COSINE
Collections : ['ai_articles']
Storing Vectors
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Prepare data for insertion
print("Preparing data for insertion...\n")
data = []
for i, doc in enumerate(documents):
embedding = model.encode(doc["text"]).tolist()
data.append(
{
"id": i + 1,
"embedding": embedding,
"doc_id": doc["id"],
"title": doc["title"],
"text": doc["text"],
"category": doc["category"],
"author": doc["author"],
"year": doc["year"],
"rating": doc["rating"],
}
)
print(f"Prepared: {doc['id']} — {doc['title']}")
# Insert all documents
result = client.insert(
collection_name=COLLECTION_NAME,
data=data,
)
print("\nInsert result:")
print(f" Insert count : {result['insert_count']}")
print(f" IDs inserted : {result['ids']}")Output:
Preparing data for insertion...
Prepared: doc_001 — Introduction to Machine Learning
Prepared: doc_002 — Deep Learning and Neural Networks
Prepared: doc_003 — Transformer Architecture Explained
Prepared: doc_004 — Retrieval-Augmented Generation (RAG)
Prepared: doc_005 — Vector Databases for AI Applications
Prepared: doc_006 — Fine-tuning Large Language Models
Prepared: doc_007 — Prompt Engineering Best Practices
Prepared: doc_008 — AI Agents and Autonomous Systems
Prepared: doc_009 — Reinforcement Learning from Human Feedback
Prepared: doc_010 — Multimodal AI Systems
Insert result:
Insert count : 10
IDs inserted : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Querying Data
query = "What are the best practices for training AI models?"
query_vec = model.encode(query).tolist()
results = client.search(
collection_name=COLLECTION_NAME,
data=[query_vec],
limit=3,
output_fields=["doc_id", "title", "category", "author", "year", "rating"],
)
print(f"Query: '{query}'\n")
print("Top 3 Results:")
print("-" * 60)
for i, hit in enumerate(results[0], 1):
entity = hit["entity"]
print(f"Rank {i}:")
print(f" Title : {entity['title']}")
print(f" Category : {entity['category']}")
print(f" Author : {entity['author']}")
print(f" Year : {entity['year']}")
print(f" Score : {hit['distance']:.4f}")
print()Output:
Query: 'What are the best practices for training AI models?'
Top 3 Results:
------------------------------------------------------------
Rank 1:
Title : Reinforcement Learning from Human Feedback
Category : RL
Author : James Martinez
Year : 2023
Score : 0.7923
Rank 2:
Title : Fine-tuning Large Language Models
Category : LLM
Author : Lisa Anderson
Year : 2024
Score : 0.7612
Rank 3:
Title : Introduction to Machine Learning
Category : ML Basics
Author : John Smith
Year : 2023
Score : 0.7234
pgvector
pgvector is this open-source extension for PostgreSQL, it kind of adds vector similarity search powers. you install it once, and then PostgreSQL gets this new column type called vector, plus three distance operators, and also two index types, IVFFlat and HNSW. So basically you can keep vectors right next to regular table columns and then do hybrid queries where the vector results get joined with SQL filters in one single query, not two steps or anything.
pgvector is on all the big managed PostgreSQL platforms too, like Amazon RDS, Google Cloud SQL, Azure Database, Supabase, Neon, and a bunch of others.
Core Architecture
- Vector Data Types: With pgvector you also get the vector(n) data type , where n is the number of dimensions. you can store that in any table column alongside normal PostgreSQL types like TEXT, INTEGER, JSONB and TIMESTAMP
- Similarity Operators: And pgvector adds three distance operators you can use straight inside SQL , so you don’t need extra tooling or weird workarounds.
| Operator | Distance Type | Use When |
| <-> | L2 (Euclidean) | Raw distance matters |
| <=> | Cosine | Direction matters more than magnitude |
| <#> | Inner product (negative) | Vectors are normalized |
- Vector Indexes: On top of that, pgvector supports two index types for speeding up similarity queries:
- IVFFlat: it cuts the vector space into cells and searches only in nearby ones. it’s quicker to build, but you usually get slightly lower recall.
- HNSW: it’s a graph based index with better recall and typically faster queries. it takes longer to build, and it tends to use more memory.
Getting Started with pgvector
Installing the Extension
pip install psycopg2-binary pgvector sentence-transformers import psycopg2
from pgvector.psycopg2 import register_vector
# Connect to PostgreSQL
conn = psycopg2.connect(
host="localhost",
port=5432,
database="vector_demo",
user="postgres",
password="postgres",
)
cur = conn.cursor()
# Register the vector type
register_vector(conn)
# Enable the pgvector extension
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
conn.commit()
print("Connected to PostgreSQL")
print("pgvector extension enabled")
# Check PostgreSQL and pgvector versions
cur.execute("SELECT version();")
pg_version = cur.fetchone()[0]
cur.execute("SELECT extversion FROM pg_extension WHERE extname = 'vector';")
pgv_version = cur.fetchone()[0]
print(f"PostgreSQL: {pg_version.split(',')[0]}")
print(f"pgvector : v{pgv_version}")Output:
Connected to PostgreSQL
pgvector extension enabled
PostgreSQL: PostgreSQL 16.2 on x86_64-pc-linux-gnu
pgvector: v0.7.2
Creating Vector Columns
# Create the articles table with a vector column
cur.execute("DROP TABLE IF EXISTS ai_articles;")
cur.execute(
"""
CREATE TABLE ai_articles (
id SERIAL PRIMARY KEY,
doc_id TEXT NOT NULL,
title TEXT NOT NULL,
body TEXT NOT NULL,
category TEXT,
author TEXT,
year INTEGER,
rating FLOAT,
embedding vector(384)
);
"""
)
# Create an HNSW index on the embedding column
cur.execute(
"""
CREATE INDEX ON ai_articles
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
"""
)
conn.commit()
print("Table 'ai_articles' created with vector(384) column")
print("HNSW index created on embedding column with cosine distance")Output:
Table 'ai_articles' created with vector(384) column
HNSW index created on embedding column (cosine distance)
Inserting Embeddings
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
print("Inserting documents into PostgreSQL...\n")
for doc in documents:
embedding = model.encode(doc["text"]) # Returns a NumPy array
cur.execute(
"""
INSERT INTO ai_articles (
doc_id,
title,
body,
category,
author,
year,
rating,
embedding
)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
""",
(
doc["id"],
doc["title"],
doc["text"],
doc["category"],
doc["author"],
doc["year"],
doc["rating"],
embedding.tolist(),
),
)
print(f"Inserted: {doc['id']} — {doc['title']}")
conn.commit()
# Verify count
cur.execute("SELECT COUNT(*) FROM ai_articles;")
count = cur.fetchone()[0]
print(f"\nTotal rows inserted: {count}")Output:
Inserting documents into PostgreSQL...
Inserted: doc_001 — Introduction to Machine Learning
Inserted: doc_002 — Deep Learning and Neural Networks
Inserted: doc_003 — Transformer Architecture Explained
Inserted: doc_004 — Retrieval-Augmented Generation (RAG)
Inserted: doc_005 — Vector Databases for AI Applications
Inserted: doc_006 — Fine-tuning Large Language Models
Inserted: doc_007 — Prompt Engineering Best Practices
Inserted: doc_008 — AI Agents and Autonomous Systems
Inserted: doc_009 — Reinforcement Learning from Human Feedback
Inserted: doc_010 — Multimodal AI Systems
Total rows inserted: 10
Running Similarity Queries
# Vector similarity search using the <=> operator for cosine distance
query = "What is the role of attention in deep learning models?"
query_vec = model.encode(query).tolist()
cur.execute(
"""
SELECT
doc_id,
title,
category,
author,
year,
rating,
1 - (embedding <=> %s::vector) AS similarity_score
FROM ai_articles
ORDER BY embedding <=> %s::vector
LIMIT 3;
""",
(query_vec, query_vec),
)
results = cur.fetchall()
print(f"Query: '{query}'\n")
print("Top 3 Similar Documents:")
print("-" * 60)
for i, row in enumerate(results, 1):
doc_id, title, category, author, year, rating, score = row
print(f"Rank {i}:")
print(f" Title : {title}")
print(f" Category : {category}")
print(f" Author : {author}")
print(f" Year : {year}")
print(f" Score : {score:.4f}")
print()Output:
Query: 'What is the role of attention in deep learning models?'
Top 3 Similar Documents:
------------------------------------------------------------
Rank 1:
Title : Transformer Architecture Explained
Category : NLP
Author : Michael Chen
Year : 2024
Score : 0.7923
Rank 2:
Title : Deep Learning and Neural Networks
Category : Deep Learning
Author : Sarah Johnson
Year : 2023
Score : 0.7412
Rank 3:
Title : Fine-tuning Large Language Models
Category : LLM
Author : Lisa Anderson
Year : 2024
Score : 0.6891
ChromaDB
ChromaDB is this open-source embedding database meant for AI work. It’s kind of the default vector store that shows up in a lot of LangChain and LlamaIndex tutorials. And yeah it can run in two modes, embedded mode where everything stays inside your Python process, so you don’t really need a server. Or client-server mode, where you run a persistent server so multiple processes can access it at once.
ChromaDB will handle the embedding generation automatically if you give it an embedding function. For storage it leans on SQLite and DuckDB locally, and for the vector indexing side it uses HNSW.
Core Architecture
The overall architecture of ChromaDB feels like it puts simplicity ahead of sheer scale. It basically targets the developer experience problem first, like, before everything else.
- Lightweight Design: It also ships as a single Python package. In embedded mode it creates local files inside your project directory. There are no annoying external dependencies, no Docker containers, and usually no extra configuration files you have to babysit . So this setup makes it pretty nice for experimenting, demos, and small production workloads that don’t need a huge infrastructure.
- Local Storage: ChromaDB uses DuckDB for metadata and SQL storage, plus its own HNSW implementation for vector indexing. Everything persists into a directory on your local filesystem, so you can back up the whole vector store just by copying a folder. Pretty straightforward.
- Developer-Focused Experience: And you can insert raw documents using strings. If you set an embedding function, ChromaDB takes care of the embedding step internally, no extra step from you. Alternatively you can use ChromaDB out of the box with a default embedding model, Sentence Transformers, without having to write embedding code at all.
Getting Started with ChromaDB
Installation and Setup
pip install chromadb sentence-transformers langchain langchain-community Code:
import chromadb
from chromadb.utils import embedding_functions
# Create a persistent ChromaDB client that saves to disk
client = chromadb.PersistentClient(path="./chroma_ai_db")
# List existing collections
print(f"ChromaDB version: {chromadb.__version__}")
print(f"Existing collections: {[c.name for c in client.list_collections()]}")Output:
ChromaDB version: 0.5.3
Existing collections: []
Creating Collections
from sentence_transformers import SentenceTransformer
from chromadb import EmbeddingFunction, Documents, Embeddings
# Define a custom embedding function using SentenceTransformers
class SentenceTransformerEF(EmbeddingFunction):
def __init__(self, model_name="all-MiniLM-L6-v2"):
self.model = SentenceTransformer(model_name)
def __call__(self, input: Documents) -> Embeddings:
return self.model.encode(input).tolist()
# Initialize embedding function
ef = SentenceTransformerEF()
# Delete collection if it already exists
try:
client.delete_collection("ai_knowledge_base")
print("Deleted existing collection")
except Exception:
pass
# Create collection with the custom embedding function
collection = client.create_collection(
name="ai_knowledge_base",
embedding_function=ef,
metadata={
"description": "AI and ML educational articles",
"hnsw:space": "cosine",
},
)
print(f"Collection '{collection.name}' created")
print(f"Collection count: {collection.count()}")Output:
Collection 'ai_knowledge_base' created
Collection count: 0
Inserting Documents
# ChromaDB lets you insert raw text and embeds it automatically
print("Inserting documents into ChromaDB...\n")
collection.add(
ids=[doc["id"] for doc in documents],
documents=[doc["text"] for doc in documents],
metadatas=[
{
"title": doc["title"],
"category": doc["category"],
"author": doc["author"],
"year": doc["year"],
"rating": doc["rating"],
}
for doc in documents
],
)
print(f"Inserted {collection.count()} documents")
print("\nSample entries:")
sample = collection.get(
ids=["doc_001", "doc_002"],
include=["metadatas", "documents"],
)
for i, doc_id in enumerate(sample["ids"]):
metadata = sample["metadatas"][i]
document = sample["documents"][i]
print(f" [{doc_id}] {metadata['title']}")
print(f" Category : {metadata['category']}")
print(f" Preview : {document[:60]}...")
print()Output:
Inserted 10 documents
Sample entries:
[doc_001] Introduction to Machine Learning
Category : ML Basics
Preview : Machine learning enables computers to learn from data...
[doc_002] Deep Learning and Neural Networks
Category : Deep Learning
Preview : Deep learning uses multi-layered neural networks to process...
Querying Similar Data
# Basic similarity search
query = "How does attention mechanism work in NLP models?"
results = collection.query(
query_texts=[query],
n_results=3,
include=["metadatas", "documents", "distances"],
)
print(f"Query: '{query}'\n")
print("Top 3 Results:")
print("-" * 60)
for i in range(len(results["ids"][0])):
doc_id = results["ids"][0][i]
metadata = results["metadatas"][0][i]
distance = results["distances"][0][i]
document = results["documents"][0][i]
print(f"Rank {i + 1}:")
print(f" ID : {doc_id}")
print(f" Title : {metadata['title']}")
print(f" Category : {metadata['category']}")
print(f" Author : {metadata['author']}")
print(f" Similarity : {1 - distance:.4f} (distance={distance:.4f})")
print(f" Preview : {document[:70]}...")
print()Output:
Query: 'How does attention mechanism work in NLP models?'
Top 3 Results:
------------------------------------------------------------
Rank 1:
ID : doc_003
Title : Transformer Architecture Explained
Category : NLP
Author : Michael Chen
Similarity : 0.7934 (distance=0.2066)
Preview : Transformers rely on self-attention mechanisms to process sequential...
Rank 2:
ID : doc_002
Title : Deep Learning and Neural Networks
Category : Deep Learning
Author : Sarah Johnson
Similarity : 0.7012 (distance=0.2988)
Preview : Deep learning uses multi-layered neural networks to process complex...
Rank 3:
ID : doc_006
Title : Fine-tuning Large Language Models
Category : LLM
Author : Lisa Anderson
Similarity : 0.6723 (distance=0.3277)
Preview : Fine-tuning adapts pre-trained LLMs for specific domains or tasks...
Performance Comparison
Performance benchmarks really hinge on dataset size, hardware, network latency, and query patterns, so even “the same” test can look different if the setup wobbles a bit. This table sort of reflects outcomes from commonly published benchmarks and some real world notes for moderate scale workloads, like 1M–10M vectors.
| Metric | Pinecone | Weaviate | Qdrant | Milvus | pgvector | ChromaDB |
| Indexing Speed (1M vectors) | Fast | Moderate | Very Fast | Fast | Moderate | Fast (small) |
| Query Latency (p50) | ~5–10 ms | ~10–20 ms | ~3–8 ms | ~5–15 ms | ~10–30 ms | ~5–15 ms (local) |
| Query Latency (p99) | ~20–50 ms | ~50–100 ms | ~15–30 ms | ~20–60 ms | ~50–200 ms | ~30–100 ms |
| Recall@10 (HNSW, ef=100) | ~98% | ~97% | ~99% | ~98% | ~97% | ~96% |
| Max Scale (practical) | Billions | ~500M | Billions | Billions+ | ~50M | ~5M |
| Memory per 1M vectors (384d) | Managed | ~2.5 GB | ~1.8 GB | ~2.0 GB | ~1.5 GB | ~1.2 GB |
| Throughput (QPS, single node) | ~500–1000 | ~300–600 | ~700–1500 | ~500–2000 | ~200–400 | ~100–300 |
| Filtering Overhead | Low | Moderate | Very Low | Low | Very Low (SQL) | Moderate |
| Cold Start | ~100 ms | ~500 ms | ~50 ms | ~200 ms | None | None |
Conclusion
Vector databases have kind of become foundational infrastructure for modern AI apps. Each of the six databases in this guide does its own thing in a different way. Pinecone and ChromaDB land on opposite ends, fully managed “easy mode” on one side, embedded local storage on the other. Qdrant, Weaviate, Milvus, and pgvector kinda fill the middle ground, with varied strengths around performance, adaptability, and how deep they integrate.
The right selection really hinges on your current scale, and where you think you’ll land in the next 12–18 months. Keep it simple to start out. No matter what you pick, putting effort into vector search will end up paying back across every AI feature you build, later on.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.






