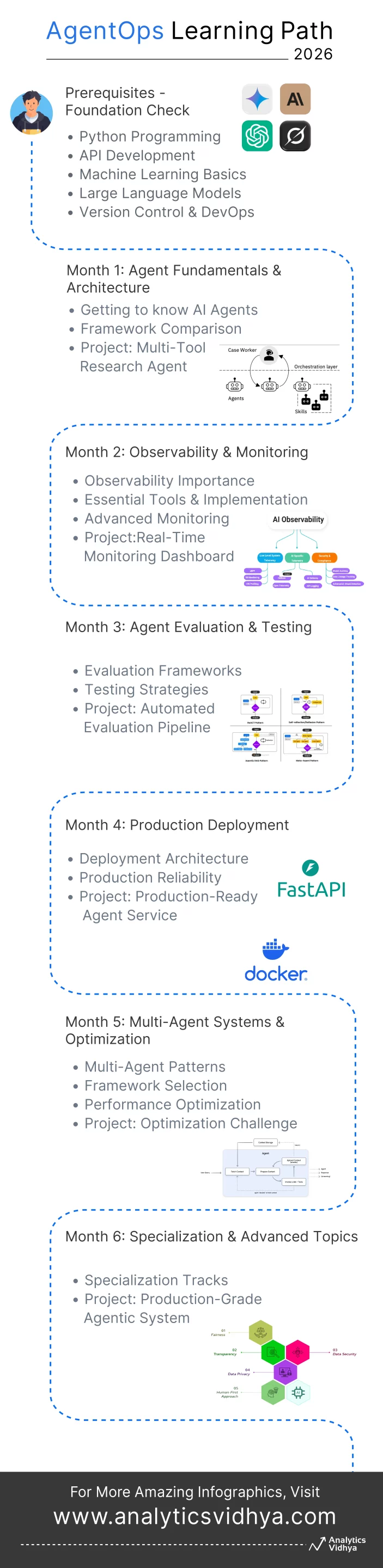
AI agents are reshaping how we build intelligent systems. AgentOps is quickly becoming a core discipline in AI engineering. With the market expected to grow from $5B in 2024 to $50B by 2030, the demand for production-ready agentic systems is only accelerating. Unlike simple chatbots, agents can sense their environment, reason through complex tasks, plan multi-step actions, and use tools without constant supervision. The real challenge starts after they’re created: making them reliable, observable, and cost-efficient at scale.
In this article, we’ll walk through a structured six-month roadmap that takes you from fundamentals to full mastery of the agent lifecycle and prepares you to build systems that can operate confidently in the real world.
Table of contents
- Month 0: Prerequisites – Foundation Check
- Month 1: Agent Fundamentals & Architecture
- Month 2: Observability & Monitoring
- Month 3: Agent Evaluation & Testing
- Month 4: Production Deployment
- Month 5: Multi-Agent Systems & Optimization
- Month 6: Specialization & Advanced Topics
- Skills Progression Matrix
- Conclusion
- Frequently Asked Questions
If you feel overwhelmed by the road, feel free to check out the visual roadmap at the end of the article.
Month 0: Prerequisites – Foundation Check
Before you begin with AgentOps, check your readiness first in these fundamental areas. Perfection is not the case here, rather having a firm ground to start with is what is being implied.

Technical Foundation
- Python Programming: You need to be well-acquainted with functions, classes, decorators, and async/await patterns. Error handling and modular code structure are particularly important as complex agent systems will be built around these and clean architecture along with proper exception management will be necessary.
- API Development: At least an introductory understanding of FastAPI or Flask is very important as the agents communicate with the outside world through APIs.
- Machine Learning Basics: Knowing ML concepts to a certain level is a boon for you in grasping the decision-making process of the agents.
- Large Language Models: Hands-on experience with GPT models, Claude, or the like via their APIs is non-negotiable. The LLMs are the source of power for the modern agents, thus, understanding the prompt engineering basics is essential.
- Version Control & DevOps: Hands-on experience with Git workflows, Docker containerization, and basic familiarity with cloud platforms (AWS, Azure, or GCP) enable you to collaborate effectively and deploy agents to production environments easily.
Quick Self-Assessment
After end of this module, you can go through the following list to see how good your fundamentals are:
- Are you able to produce neat Python code with proper error handling?
- Are you capable of both building and consuming RESTful APIs?
- Do you have a firm grasp of ML inference and model evaluation?
- Have you carried out any successful experiments using LLM APIs?
- Are Git and Docker basics something you can handle easily?
If you answered yes to most of the above questions, then proceed to the next level. Otherwise, spend a few weeks more trying to strengthen your weak areas.
Month 1: Agent Fundamentals & Architecture
In this month, your aim would be to get acquainted with Agent architectures, evaluate different frameworks, and create your very first working agent.

Getting to know AI Agents (Weeks 1-2)
AI agents are the independent systems that can do much more than the most advanced and sophisticated chatbots. They utilize various inputs to sense their environment, and to reason about the information they have using LLMs, they plan the actions to take and perform them using tools and APIs. The major difference from the rest of the software is that the AI can make the decision and take the action without the human being there all the time to guide.
Basic Elements of the Agent:
- Perception: Analyzing inputs (text, structured data, images)
- Memory: Short-term (interlocutor history) and long-term (vector databases)
- Reasoning: LLM-driven decision making
- Action: Performing with tools and interacting with APIs
Agent Types:
- ReAct (Reasoning + Acting): Looping through reasoning, acting, and observing repeatedly.
- Planning Agents: Formulate a series of steps that need to be taken before the actual execution takes place.
- Multi-Agent Systems: Cooperation among various agents with different specialties.
Framework Comparison (Weeks 3-4)
Different frameworks are built for different purposes. Knowing their capabilities makes it easier to pick the right tool for every job.
- LangChain: It brings in chains that are modifiable and an extensive variety of tools, thus, making it the best for prototyping and experimenting quickly.
- LangGraph: It is the expert in graph-type workflows that are stateful with amazing management of the state and support for the workflows that are cyclic.
- CrewAI: It is a company that center’s its research on role-based multi-agent cooperation, combining it with hierarchical structures and process orchestration.
- Microsoft’s AutoGen: It allows for the conversation-based agent frameworks having group chat and code execution capabilities.
- OpenAI Agents SDK: It delivers direct input with the OpenAI ecosystem which includes tools, responses of streaming, and structured outputs.
Quick Self-Assessment
The agent should be ready for the production stage with the following abilities:
- Performing web search and getting data extracted
- Reading documents and their summarizing
- Maintaining conversation memory across different sessions
- Handling errors well and degrading gracefully
- Managing token budget
If you are able to confidently perform most of the aforementioned tasks, then you are well prepped for the net phase.
Month 2: Observability & Monitoring
The objective is to acquire the capability to monitor, rectify, and comprehend the conduct of the agents in real-time.
Observability Importance (Weeks 1-2)
Agents behave unpredictably and can get into trouble in unforeseeable manners. The outputs of LLMs might differ with every call, and the usage of a tool might intermittently fail, leading to unexpected high costs unless the usage is monitored properly. The debugging process demands a full view of the making of a decision, which is not possible with the conventional logging method.
The Four Key Elements of Agent Observability:
- Tracing not only logs, but also tracks every aspect of an agent’s functioning, i.e., from tool calls to LLM prompts to responses.
- Logging makes it easier across asynchronous operations to keep the context with the use of structured formats that allow searching and filtering.
- Metrics give numbers to performance (latency, throughput), costs (token usage, API calls), quality (success rates, user satisfaction), and system health (error rates, timeouts).
- Session Replay allows you to recreate exact agent behavior for debugging.
Essential Tools & Implementation
AgentOps is perfect for monitoring agents with session replay, cost tracking, and framework integrations specifically designed for that purpose. The observability of LangChain is made possible with the help of LangSmith through prompt versioning and trace visualization in great detail. On the other hand, Langfuse is an open-source tool offering the possibility of self-hosting for data privacy and defining custom metrics as among its features.
Start with Month 1 agent and superimpose holistic observability. Every LLM call will be embedded with trace IDs; request-wise token consumption will be tracked; a dashboard reflecting success/failure rates will be created; and budget alerts will be set up. This groundwork will prevent a lot of debugging time being wasted later on.
Advanced Monitoring (Weeks 3-4)
Adopt OpenTelemetry to the extent of implementing distributed tracing that can give the production-grade observability level. Determine custom spans for agent activities, transmit context across the asynchronous calls, and make a connection with the standard APM tools such as Datadog or New Relic.
Key Metrics Framework:
- Performance: Latency percentiles (P50, P95, P99), token generation speed
- Quality: Task success rate, hallucination detection, user corrections
- Cost: Per-request cost, daily burn rate, budget efficiency
- Reliability: Error rates by type, timeout frequency, retry patterns
Project: Real-Time Monitoring Dashboard
Construct a great monitoring system that not only displays the live agent traces but also shows the cost burn rate along with the projections, the success/failure trends, the tool performance metrics, and the distribution of errors. The stack for the construction is Grafana for visualization, Prometheus for metrics, and your selected agent observability platform for telemetry.
Month 3: Agent Evaluation & Testing
The central aim of the month is to learn how to enforce a gradual assessment and to have quality testing done through the use of agents.

Evaluation Frameworks (Week 1-2)
The Evaluation Frameworks will be created during the first two weeks of the project. Normal testing would not be enough for agents since they are not deterministic, the same input can give different outputs. The agent’s success is often based on the user’s perspective and the context, thus making automated evaluation difficult but necessary for large-scale use.
The evaluation will be based on the following parameters:
- The agent will be considered successful if it has done the intended task with outputs that are factually correct and that meet all requirements. This metric is the main success measure but should be very clear for every case.
- The consumption of resources in terms of steps taken and tokens used is what will be looked at during efficiency evaluation. An agent that helps achieve the target but at the same time wastes resources is not the right one to be used. Detect the types of tools that are used appropriately and depending on that, try to find the resource-saving opportunities.
- The aspect of safety & reliability will check if the agents stay within the guardrails, do not produce harmful outputs, and manage the rare cases gracefully. This would be very important for a production environment, especially in regulated industries.
- User Experience evaluates response quality, latency, and overall user satisfaction. It does not matter much if the agent’s output is technically correct, but the users experience the agent as being very slow or it is frustrating to them.
Evaluation Methods
Human evaluation means that domain experts will review the outputs done by another human and give scores using scoring rubrics. It is a costly process, but it is the source of very good ground truth, and it brings up very subtle issues that are overlooked by automated methods.
- LLM-as-Judge leverages either GPT models or Claude to decide on agent outputs by comparing them to the preset criteria. Provide clear rubrics and few-shot examples for consistency. The method has good scaling properties but necessitates validation against human judgment.
- The metrics based on rules have automated checks for criteria like format validation, length constraints, required keywords, and structural requirements. They are fast and deterministic but are limited to measurable criteria.
- Benchmark datasets offer the standard test suites for keeping track of the progress over time, comparing to the baselines, and spotting regressive developments resulting from changes made in the process.
Testing Strategies (Weeks 3-4)
Create a testing pyramid that includes unit tests for individual components using simulated LLM responses, integration tests for the agent-plus-tools using smaller models, and end-to-end tests with real APIs for critical workflows. Besides, add regression tests that will compare outputs with the baseline and block deployment of the output whenever there is a drop in quality.
Agent-Specific Testing Challenges:
- Non-determinism means that several iterations of the tests should be done and the pass rates should be calculated
- The expensive nature of the API calls requires very intelligent mocking and caching strategies
- The slowness of the execution means that parallel test runs, and selective testing should be employed
CI/CD Pipeline Design
The pipeline that you design should start with the execution of code quality checks (linting, type checking, security scanning), then proceed to the execution of unit tests with mocked responses taking less than 5 minutes, next execution of integration tests with cached responses in 10-15 minutes, then benchmarking with quality blocking and quality being the criterion for staging and production, followed by smoke tests and gradual rollout to production with continuous monitoring.
Project: Automated Evaluation Pipeline
Design a full CI/CD pipeline that is triggered on every commit, performs extensive testing, assesses quality on more than 50 benchmark cases, prevents the release of any corresponding metrics, produces full reports, and notifies on errors. Such a pipeline ought to be done in less than 20 minutes and to offer useful feedback.
Month 4: Production Deployment
Our objective for this month is to introduce the agents into production with the needed infrastructure, reliability, and security.
Deployment Architecture (Weeks 1-2)
Pick a strategy for deployment through an analysis of the users and their needs. The Serverless (AWS Lambda, Cloud Functions) type performs well for infrequent use with auto-scaling and billing only for usage, though cold starts and not being stateful could be disadvantages. Container-based deployment (Docker + Kubernetes) is perfect for high-volume, always-on agents with detailed control, but it takes more overhead for managing the operation.
Ready-made AI platforms such as AWS Bedrock or Azure AI Foundry are great for security and governance which comes along with the cost of being tied to the platform and it might not be suitable for all companies. Edge deployment, on the other hand, allows for applications that are latency-free and privacy-focused and can work offline but have limited resources.
1. Necessary Infrastructure Parts
Your API Gateway oversees routing and rate limiting, transforms requests, and authenticates. A message queue (RabbitMQ, Redis) separates system components and handles traffic spikes with the added benefit of a delivery guarantee. Vector databases (Pinecone, Weaviate) offer support for conducting semantic search for RAG-based agents. State management with Redis or DynamoDB saves sessions and conversation history.
2. Scaling Consideration
Horizontal scaling with more than one instance sharing a load balancer necessitates a design that is stateless and has a shared state storage. The plan for LLM API dealing limits should consist of request queuing, multiple API keys and fallback providers.
Deliver your agent using the FastAPI backend with async endpoints, Redis for caching, PostgreSQL for persistent state, Nginx as reverse proxy and proper health check endpoints, Docker containerization.
Production Reliability (Weeks 3-4)
The infrequent API failures will be managed in a much gentler manner through the application of retries with exponential backoff. In case of any service outages, circuit breakers will be deployed to not only prevent further failures but also to effectively fail very quickly. Alongside the tool’s downtime, the use of strategies such as cached responses or graceful degradation should be considered.
A limit should be imposed on sessions such that they do not get frozen and thereby allow for quick recovery of the resources. It is very important that your operations are idempotent so that the retries do not lead to duplicate actions; this is especially critical for payment or transaction agents.
Best Security Practices
Storing of API keys must be done always in environment variables or secret managers, and including them in the code is a big no-no. The implementation of input validation has to be done as a countermeasure against prompt injection attacks. Outputs should have PII and inappropriate content masked. There must be the availability of authentication (API keys, OAuth) and role-based access control. Audit trails must be kept for compliance with laws such as GDPR and HIPAA.
Project: Production-Ready Agent Service
The complete service will be deployed with Docker/Kubernetes infrastructure, load balancing and health checks, Redis caching and PostgreSQL state, thorough monitoring with Prometheus and Grafana, retries, circuit breakers, and timeouts, API authentication and rate limiting, input validation and output filtering, and security audit compliance.
Your system will be capable of processing over 100 concurrent requests while ensuring a 99.9% uptime ratio throughout its operation.
Month 5: Multi-Agent Systems & Optimization
In this month, we’ll understand multi-agent architectures thoroughly and upgrade agent’s performance to the maximum level.

Multi-Agent Patterns (Weeks 1-2)
The application of single agents leads to complications very soon. The main benefits of multi-agent systems are mostlysubject specialization where every agent takes up one task and becomes an expert, faster results through parallel execution, robustness due to redundancy, and the ability to manage complex workflows.
The architectural forms of multi-agent systems that are commonly used include:
- The Hierarchical (Manager-Worker) architecture assigns a manager agent that delegate responsibilities to professional workers and thus, everybody knows their roles nicely and it is cleaner.
- The Sequential Pipeline is a conduit of results that conducts the flow one after another, where the input of one agent corresponds to the output of the next agent. This workflow is a good fit for document processing and content generation where the latter depends on the former.
- Parallel Collaboration has a number of agents working at the same time and their results are combined at the end. Independent task execution makes this perfect for research and comparison tasks where different opinions are required.
Framework Selection
Selecting the correct framework for the task is essential. Here are some pointers to help you with the choice:
- AutoGen is able to support conversation-based cooperation with adaptable agent roles and group chat patterns.
- CrewAI works with role-based teams to provide processing and task management at different levels.
- LangGraph has a clear advantage in dealing with complex state machines using conditional routing and cyclic workflows.
Assemble a research group composed of a planner agent who is responsible for breaking down questions, three researcher agents who conduct searches in various sources, an analyst who brings together the findings, a writer who is in charge of producing the reports in a structured manner, and a reviewer who is responsible for checking the quality of the report.
This is a clear example of the three aspects of task delegation, parallel execution, and quality control working together.
Performance Optimization (Weeks 3-4)
- Prompt Optimization consists of A/B testing different versions, choosing few-shot examples that work well, reducing the size of prompts to cut down the number of tokens by 30-50%, and finding a balance between depth of reasoning and speed.
- Tool Optimization is about giving priority to caching of the most frequent results along with their expiration period based on time, conducting independent tools in parallel, intelligent tool selection that prevents unplanned calls, and drawing knowledge from previous accomplishments.
- Model Selection involves choosing GPT-5.2 for advanced reasoning but GPT-4o for simple questions, practice of model cascading where fast/cheap models are tried first and then the escalation happens only if necessary, and investigation of open-source options for up to moderate use cases.
Project: Optimization Challenge
Use a currently existing agent to get a 50% latency reduction, 40% cost reduction, and at the same time keep the quality within ±2%. Prepare the whole optimization process with before/after metrics that consist of precise performance comparisons, cost breakdowns, and recommendations for further improvements.
Month 6: Specialization & Advanced Topics
The aim of the whole month is to pick a specialization and then build a portfolio-defining capstone project.

Specialization Tracks (Weeks 1-2)
In the first two weeks, you will have to select one specialization track that matches your interests and career goals.
- Enterprise AgentOps is for the most complex and largest system deployments with Kubernetes orchestrated cloud, enterprise security and compliance, multi-tenancy, and SLA management.
- Agent Safety & Alignment talks about the deployment of guardrails, red-teaming and adversarial testing, content filtering and bias detection, and safety evaluation frameworks as the main domains of research. These are critical for healthcare agents (HIPAA), financial agents (regulatory compliance), and any consumer-facing applications.
- Agentic AI Research will be covering agent planning algorithms, reinforcement learning integration, novel cognitive architectures, and benchmark creation.
- Domain-Specific Agents will be relying heavily on the industry knowledge of the most important areas like healthcare (medical diagnosis), finance (trading analysis), legal (contract review), or software engineering (code review). It will be great if someone combines his/her domain expertise with AgentOps skills for specialized high-value applications.
Capstone Project: Production-Grade Agentic System (Week 3-4)
The objective is to create a complete system based on multi-agent architecture (comprising at least 3 specialized agents), full observability through real-time dashboards, comprehensive evaluation suite (50+ test cases), production deployment on cloud infrastructure, cost and performance optimization, safety guardrails, security measures, and full documentation with setup guides.
Possible Project Ideas:
- The automated customer support system can classify, perform knowledge search, generate responses, and escalate issues.
- The research assistant can do planning, search in multiple sources, perform analysis, and generate reports.
- A DevOps automation suite monitors systems, diagnoses issues, performs remediation, and maintains documentation.
- A content generation pipeline plans, researches, writes, edits, and optimizes content.
Your capstone project should be able to deal with complexities of the real world, be available through API, showcase code quality of production-ready standards, and be able to operate in a cost-effective manner with performance metrics duly documented.
Skills Progression Matrix
| Month | Core Focus | Key Skills | Tools | Deliverable |
|---|---|---|---|---|
| 0 | Prerequisites | Python, APIs, LLMs | OpenAI API, FastAPI | Foundation validated |
| 1 | Fundamentals | Agent architecture, frameworks | LangChain, LangGraph, CrewAI | Multi-tool agent |
| 2 | Observability | Tracing, metrics, debugging | AgentOps, LangSmith, Grafana | Monitoring dashboard |
| 3 | Testing | Evaluation, CI/CD | Testing frameworks, GitHub Actions | Automated pipeline |
| 4 | Deployment | Infrastructure, reliability | Docker, Kubernetes, cloud | Production service |
| 5 | Optimization | Multi-agent, performance | AutoGen, profiling tools | Optimized system |
| 6 | Specialization | Advanced topics, domain | Track-specific tools | Capstone project |
Conclusion
AgentOps is positioned at the crossroads of software engineering, ML engineering, and DevOps, which are applied to the specific difficulties posed by autonomous AI systems. This 6-month roadmap outlines and guarantees a clear way for the learner moving from basics to mastery in production.
Frequently Asked Questions
Q1. What exactly is AgentOps and why does it matter?
A. AgentOps is the discipline of building, deploying, monitoring, and improving autonomous AI agents. It matters because agents behave in unpredictable ways, interact with tools, and run long workflows. Without proper observability, testing, and deployment practices, they can become expensive, unreliable, or unsafe in production.
Q2. How much technical background do I need before starting this roadmap?
A. You don’t need to be an expert, but you should be comfortable with Python, APIs, LLMs, Git, and Docker. A basic understanding of ML inference helps, and some cloud exposure makes the later months easier.
Q3. What kind of project will I be able to build after six months?
A. By the end, you’ll be able to ship a full production-grade multi-agent system: real-time monitoring, automated evaluation, cloud deployment, cost controls, safety guardrails, and strong documentation.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]





