Obtaining the text in a messy PDF file is more problematic than it is helpful. The problem does not lie in the ability to transform pixels into text, but rather, in maintaining the structure of the document. Tables, headings, and images should be in the right sequence. When using Mistral OCR 3, it is no longer the text conversion, but the production of business usable information. The new AI-powered document extraction tool will be intended to enhance complicated file extraction.
This guide discusses the Mistral OCR 3 model. We’ll also discuss its new features and their methods of usage, and finally, conclude with a comparison with the open-weights DeepSeek-OCR model as well.
Table of contents
Understanding Mistral OCR 3
Mistral presents its new tool OCR 3 as a general-purpose one. It deals with the large number of documents present in organizations, and isn’t limited to OCRing clean scans of invoices. Mistral gives the most important improvements that solve some of the frequent failures of OCR.
- Handwriting: The model gets improved work on printing and handwriting of text on printers.
- Forms: It processes complicated structures of boxes, labels, and mixed types of texts. It is typical of invoices, receipts, and government documents.
- Scanned Documents: The system is less affected by scanning artifacts such as skew, distortion, low resolution, etc.
- Complex Tables: It provides an improved table of reconstruction. This will encompass a combination of cells, as well as multi-rows. The output is in HTML tags in order to maintain the original layout.
Mistral says that it tested the model against internal benchmarks, which mean real business cases.
What is New in OCR 3?
The final release offers two significant modifications to developers: quality of the output and control. These characteristics amplify organized extraction powers of the model.
1. New Controls for Document Elements: The changelog of the Mistral OCR 3 associates the new model with novel parameters and outputs. Tableformat is now able to select between markdown and HTML. Extractheader, extractfooter, and hyperlinks will also help in the handling of special document sections. This is one of the foundations of its document AI system.
2. A UI Playground for Fast Testing: Mistral OCR 3 has its OCR API and a “Document AI Playground” in Mistral AI Studio. A playground allows you to test challenging scenarios expediently, e.g. faulty scans or scribbles. Before automating your process, you can modify such parameters as table format and check outputs. Successful OCR projects should have a feedback loop that is fast.
3. Backward Compatibility: Mistral confirms that OCR 3 is compatible with the rest of its previous version. This will enable teams to modernize their systems over time without re-writing their pipeline.
Models and Pricing
The OCR 3 is said to be mistral-ocr-2512. The documentation also refers to a mistral-ocr-latest alias. Pricing will be done on a page basis.
- $2 per 1000 pages
- $3 per 1000 annotated pages
The second price would be when you are using annotations to do structured extraction. This cost should be put in the budget early by the teams.
Hands-on with the Document AI Playground
You can access Mistral OCR 3 through the Document AI Playground in Mistral AI Studio. This allows for quick, practical testing.
- Open the Document AI Playground in Mistral AI Studio. Head over to console.mistral.ai/build/document-ai/ocr-playground
If you see “Select a plan”, then sign up using your number and you will be able to see the following
- Upload a PDF or image file. Start with a tricky document, like a scanned form with a table.
Why this image?
A clean invoice with a table (great first test for OCR 3 table reconstruction)

Use this to check:
- reading order (header fields vs line items)
- table extraction (rows/columns, totals)
- header/footer extraction
- Select the OCR 3 model, which may be
mistral-ocr-2512or latest. - Choose a table format. Use html for structural accuracy or markdown if your pipeline uses it.

- Run the process and inspect the output. Check the reading order and table structure.
Output:
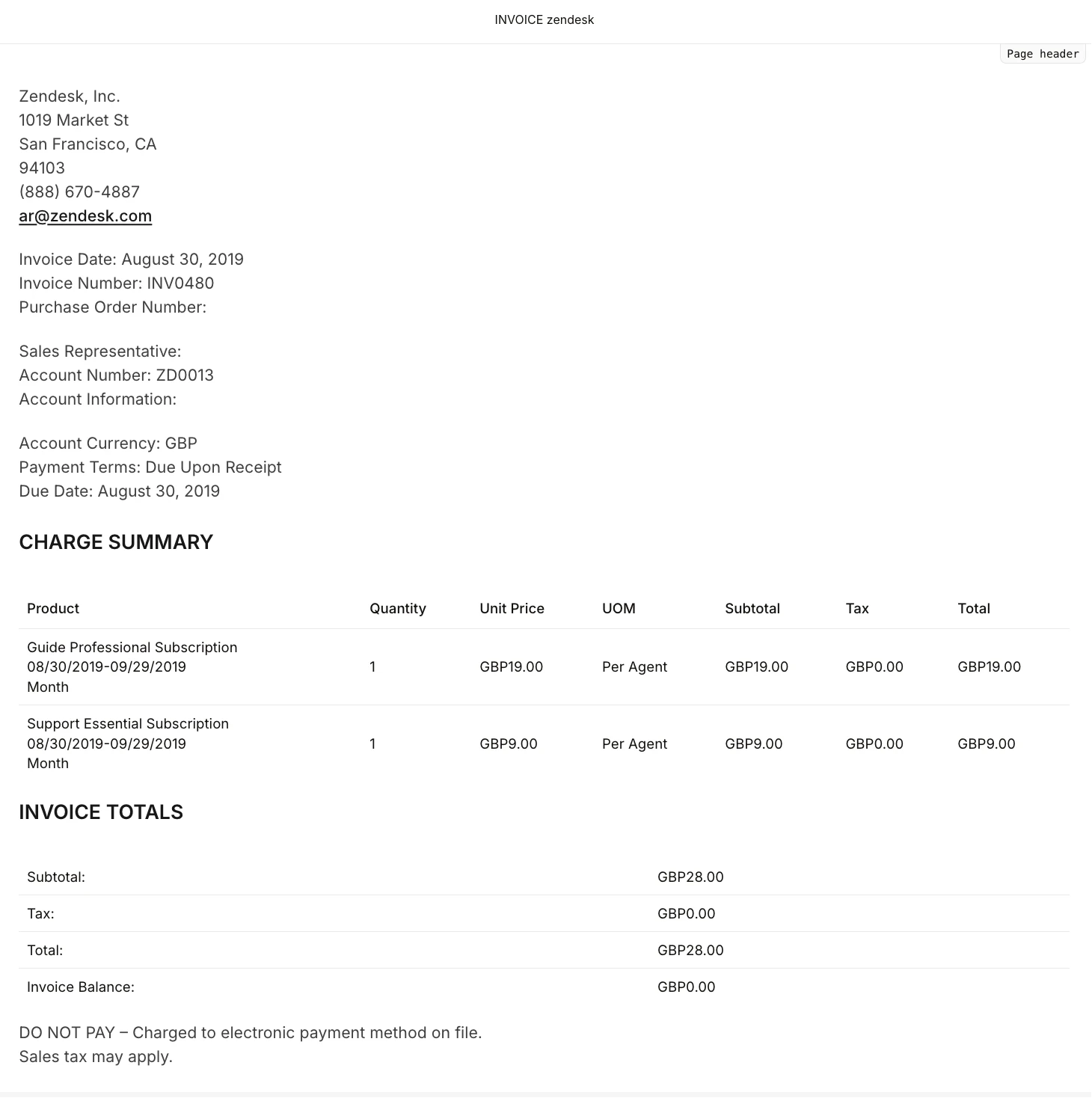
- This first OCR 3 run is essentially flawless for a clean digital invoice.
- All key fields, layout sections, and the charge summary table are captured correctly with no text errors or hallucinations.
- Table structure and numeric consistency are preserved, which is critical for financial automation.
- It shows OCR 3 is production-ready out of the box for standard invoices.
Hands-on with the OCR API
Option A: OCR a Document from a URL
The OCR API supports document URLs. It returns text and structured elements.
Here is a Python example using the official SDK.
import os
from mistralai import Mistral, DocumentURLChunk
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
resp = client.ocr.process(
model="mistral-ocr-2512",
document=DocumentURLChunk(document_url="https://arxiv.org/pdf/2510.04950"),
table_format="html",
extract_header=True,
extract_footer=True,
)
print(resp.pages[0].markdown[:1000])Output:

Option B: Upload Files and OCR by file_id
This method works for private documents, not on a public URL. Mistral’s API has a /v1/files endpoint for uploads.
First, upload the file using Python.
import os
from mistralai import Mistral
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
uploaded = client.files.upload(
file={"file_name": "doc.pdf", "content": open("/content/Resume-Sample-1-Software-Engineer.pdf", "rb")},
purpose="ocr",
)
resp = client.ocr.process(
model="mistral-ocr-2512",
document={"file_id": uploaded.id},
table_format="html",
)
print(resp.pages[0].markdown[:1000])Output:
Handling Images and Tables
Images and tables in the markdown are characterised by placeholders used by OCR output of Mistral. The real content that is extracted is given back in different arrays. This layout gives you an option to have the markdown as the primary document view. The picture and table resources can then be stored in the required location.
Structured Extraction with Annotations
Simple OCR is the first step. Structured Extraction gives the real value. The feature of idea annotations is provided in the document AI platform by Mistral. It allows you to create a schema and unstructure documents with JSON. That is how you come up with dependable extraction pipelines which cannot be broken by changing an invoice layout by a vendor. One solution is more practical which is to use OCR 3 to enter text and annotations to the particular fields you require, e.g. invoice numbers or totals.
Scaling Up with Batch Inference
In high volume processing, a batching is required. The batch system by Mistral allows you to submit a large number of API requests in a file with a.jsonl extension. They can then be run as one job. The documentation indicates that /v1/ocr is one of the supported batch jobs endpoints.
How to Choose the Right Model
The best choice depends on your documents and constraints. Here is a clean way to evaluate.
What to Measure
- Text Accuracy: Use character or word error rates on sample pages.
- Structure Quality: Score table reconstruction and reading order correctness.
- Extraction Reliability: Measure field accuracy for your target data points.
- Operational Performance: Track latency, throughput, and failure modes.
Let’s Compare
Use the following image as the reference to compare the both models. We selected this image as it is:

A hard stress-test form with boxed fields + mixed handwriting + printed text (great for comparing OCR 3 vs DeepSeek-OCR).
We will use this to compare:
- handwriting accuracy (cursive + digits)
- box/field alignment (numbers inside little squares)
- robustness to dense layouts and small text
Mistral OCR 3
Output:
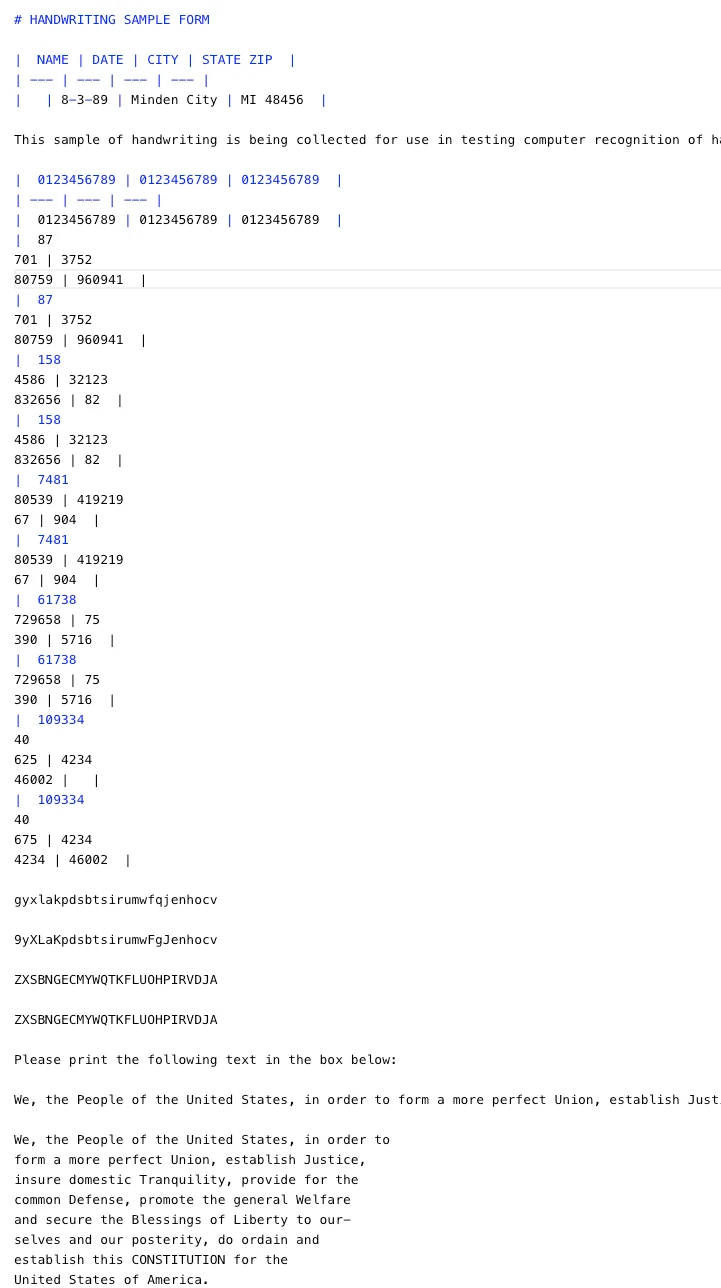
This result is impressive given the difficulty of the input.
- Mistral OCR 3 correctly identifies the document structure, headers, and most handwritten digits and text, converting a dense handwriting form into usable markdown.
- Some duplication and minor alignment issues appear in the tables, which is expected for heavy handwriting grids.
- Overall, it demonstrates strong handwriting recognition and layout awareness, making it suitable for real-world form digitization with light post-processing
Deepseek OCR
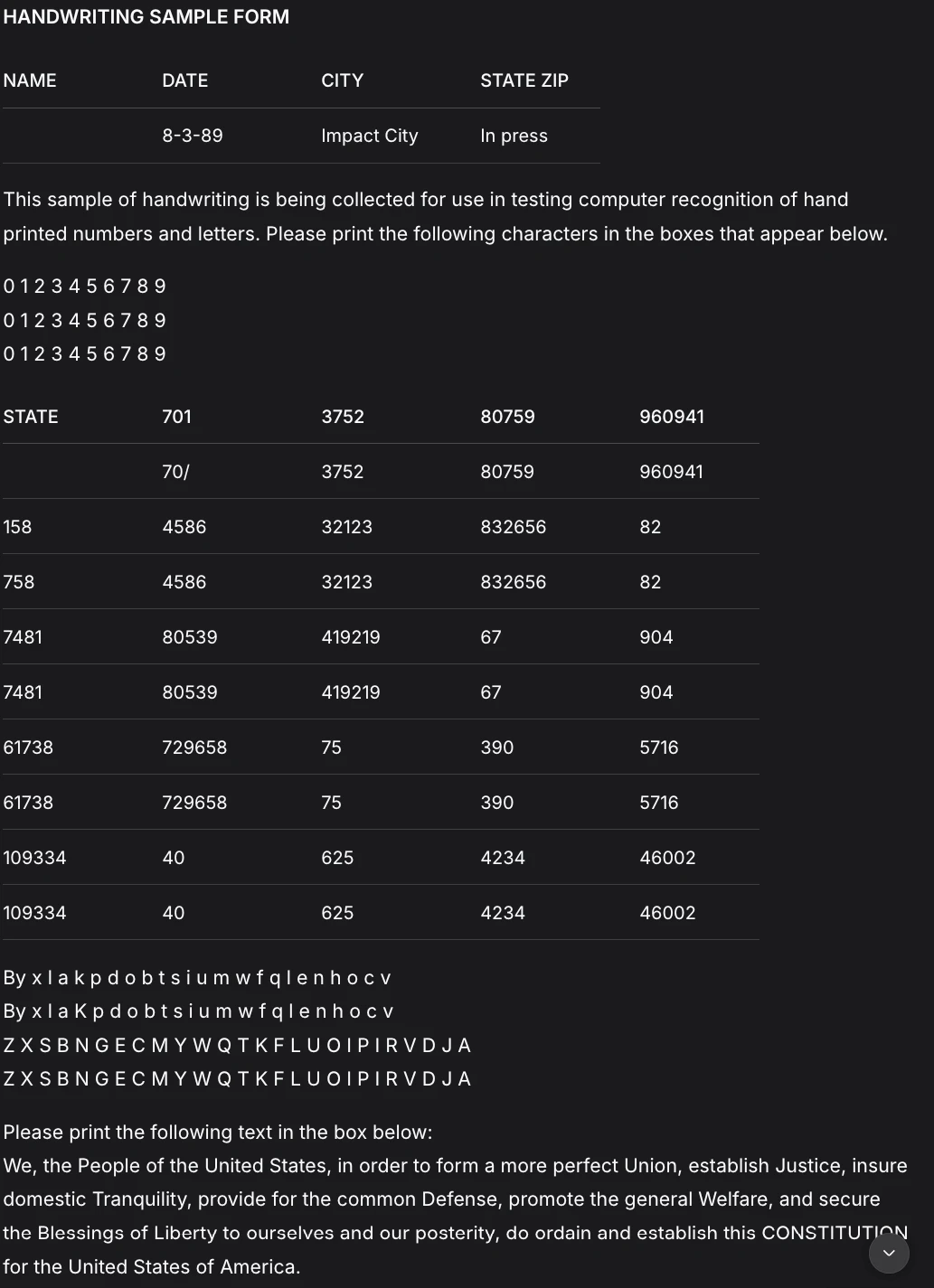
The result has been beautified which makes it easier to go through than the previous response. Here are few other things that I noticed about the :
- DeepSeek OCR shows solid handwriting recognition but struggles more with semantic accuracy and layout fidelity.
- Key fields are misinterpreted, such as “City” and “State ZIP”, and table structure is less faithful with incorrect headers and duplicated rows.
- Character-level recognition is decent, but spacing, grouping, and field meaning degrade under dense handwriting.
Result:
Mistral OCR 3 clearly outperforms DeepSeek OCR on this handwriting-heavy form. It preserves document structure, field semantics, and table alignment far more accurately, even under dense handwritten grids. DeepSeek OCR reads characters reasonably well but breaks on layout, headers, and field meaning, leading to higher cleanup effort. For real-world form digitization and automation, Mistral OCR 3 is the clear winner.
Which One Should You Choose?
Select Mistral OCR 3 in case you require a full OCR product that includes a UI and a clear OCR API. It is optimal in case of high-fidelity and predictable SaaS cost and valuation of table reconstruction.
Select DeepSeek-OCR when it is required to be hosted on-premises or self-hosted. It gives the flexibility and control of the inference process to the teams that are willing to control the operations. It is possible that many teams will resort to the both: Mistral as the primary pipeline and DeepSeek as a backup of sensitive documents.
Conclusion
The structure and workflow become major concerns due to the changes in Mistral OCR 3. The table controls, JSON extraction annotations, and a playground have features such as UI and can reduce development time. It is one of the powerful productizations of document intelligence. DeepSeek-OCR provides another way. It considers OCR a compression problem that is concerned with LLM, and provides users with freedom of infrastructure. These two models demonstrate the future separation of OCR technology.
Frequently Asked Questions
Q1. What is the significant benefit of Mistral OCR 3?
A. Its key strength is that it concentrates on maintaining document structure including complicated tables and reading sequences, converting scanned documents to useful information.
Q2. Table processing in Mistral OCR 3?
A. It has the capability of generating tables in HTML format, which has the added advantage of maintaining complex data such as merged cells and multi-row headers ensuring greater data integrity.
Q3. Is it possible to test Mistral OCR 3 prior to making use of the API?
A. Yes, Doc AI Playground in the AI Studio of Mistral offers you upload documents and experiment with the OCR features.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






