Introduction
While searching for things over internet, I always wondered, what kind of algorithms might be running behind these search engines which provide us with the most relevant information? How do they decide which result to show for which set of search keywords.
This might be a no brainer for a few people, but definitely an interesting problem for some of the best brains around the world. To find the answer, I read every guide, tutorial, learning material that came my way. Eventually, I learnt about the Information Retrieval System.
What is Information Retrieval System?
Information retrieval system is a network of algorithms, which facilitate the search of relevant data / documents as per the user requirement. It not only provides the relevant information to the user but also tracks the utility of the displayed data as per user behaviour, i.e. Is the user finding the results useful or not?
In this article, I have explained the basic techniques used for Information Retrieval. The algorithms used by Yahoo and Google are much more complex compared to the ones mentioned in this article, but still you will get a sense of what goes on in the background when you make these searches.
Let’s understand more about information retrieval system algorithm using the activity and a business case below:
Activity – Information Retrieval in Web search:
Try to search for the queries below and notice the differences in search engine results :
- blogs on analytics
- blogs analytics
- blogs on analytic
- books on analytics
- blogs on big data
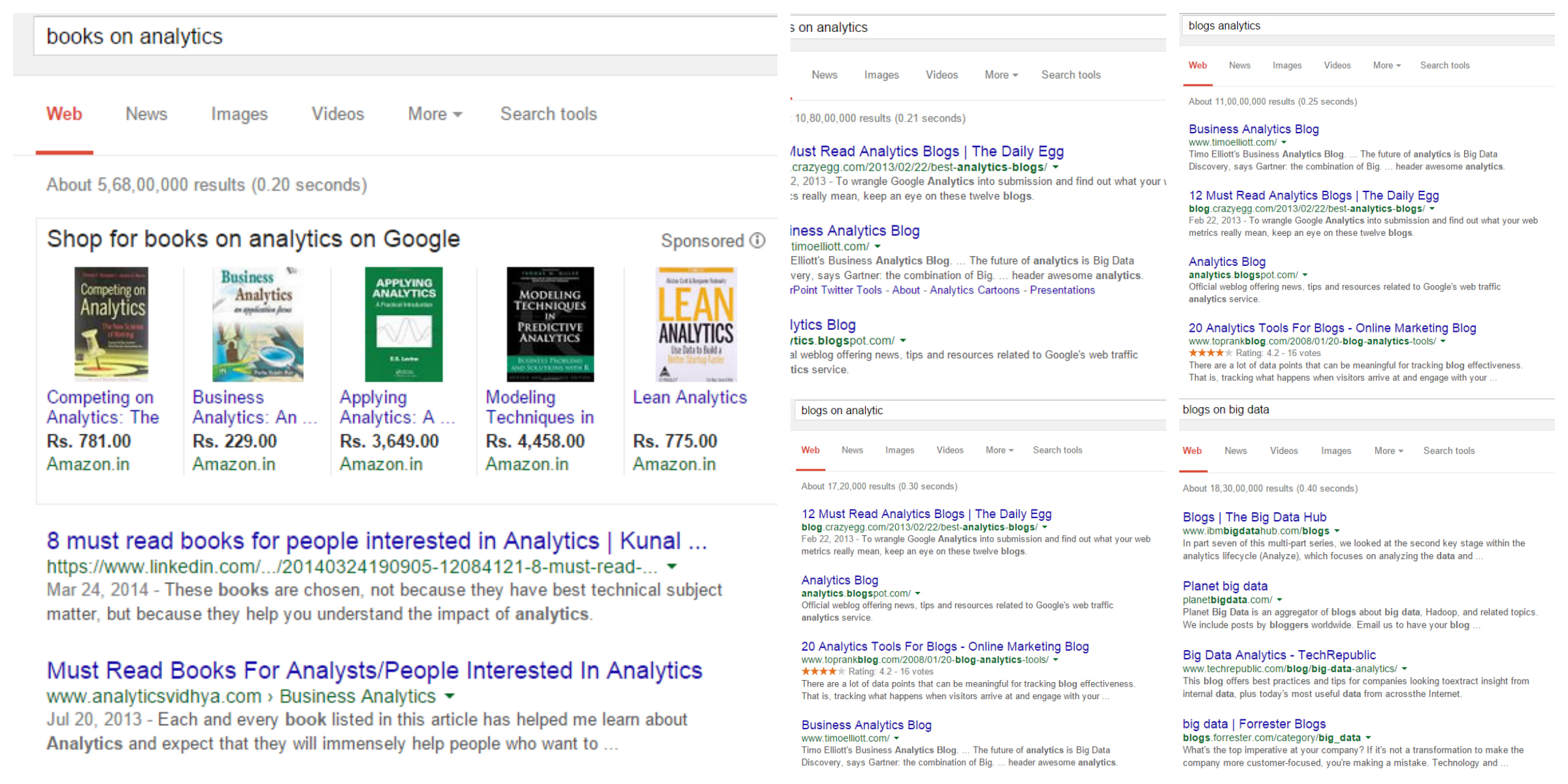
Inference: You will notice that the first 3 searches gave similar results while 4th and the 5th search result displayed a different result. This is expected because what we are asking in the first 3 queries is quite similar. Hence, the result.
That is interesting! But, the question remains:-
“How does an algorithm catch the similarity and retrieve the right set of web pages for us?”
This was just one part of information retrieval (IR) . IR is no way limited to web searches. Below are the few more cases where IR is used in one form or the other:
- Library / Online book store: where a simple query can match multiple books based on the match with the query.
- E-Commerce store: where you can match multiple items using a query.
- Search Tabs: Any search tab on different websites use IR to retrieve related pages.
- Banks: Try to retrieve the right product, given a set of queries.
Business Case
Let’s take a simple example of an online library.We have more than 10,000 books from which we need to search for a book as per the query entered by customer. In addition, we need to create an information retrieval system which can call out all the books which resembles the customer query. Here are a few names of books :
- Analytics and Big-Data
- The Hanging Tree
- Broken Dreams
- Blessed kid
- Girl with a Dragon Tattoo
The query entered by customer is : Book for Analytics newbie. Let’s solve this case.
Solving the puzzle using Text Mining
Imagine if you were a librarian of 70’s and a customer comes to you to borrow a book. Given that you have been handling such queries for a long time, you can match the context of the query to the books in the rack. Now imagine, how would this process be, if done by an algorithm.
Obviously machines can handle much bigger data with higher accuracy. Let’s look at few techniques which will make the work of the machine easier:
Term Frequency (TF) Matrix :
This is the most obvious technique to find out the relevance of a word in a document. The more frequent a word is, the more relevance the word holds in the context. Here is a frequency count of a set of words in the 5 books :
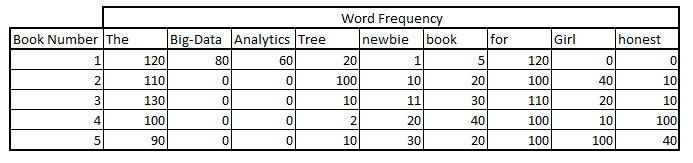
One way to check Term Frequency (TF) is to just count the number of occurrence. But it has been observed that if a word X occurs in document A 1 time and in B 10 times, its generally not true that the word X is 10 times more relevant in B than in A. The difference is generally lesser as compared to the actual ratio. Hence it is good to apply following transformation on TF :
TF = 1 + log (TF) if TF > 0
0 if TF = 0
Let’s do the same calculation here :
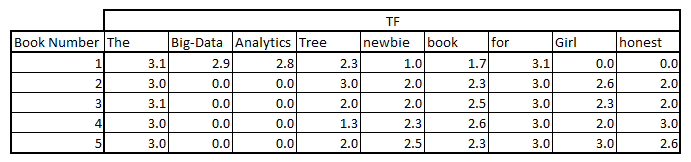
Now to find the relevance of document in the query, you just need to sum up the values of words in the query.
Document 1 : 1.7 + 3.1 + 2.8 + 1 = 8.6
Document 2 :2.3 + 3.0 + 0 + 2 = 7.3
Document 3 : 2.5 + 3.0 + 0 + 2 = 7.5
Document 4 : 2.6 + 3.0 + 0 + 2.3 = 7.9
Document 5 : 2.3 + 3.0 + 0 + 2.5 = 7.8
Result shows, Document 1 will be more relevant to display for the query, but we still make a concrete conclusion . Since, document 4 and 5 are not far away from Document 1. They might turn out to be relevant too. This is because of the stopwords which elevates all the scores with similar magnitude.
Inverse Document Frequency Matrix(IDF) :
IDF is another parameter which helps us find out the relevance of words. It is based on the principle that less frequent words are generally more informative.
IDF = log (N/DF)
where N represents the number of documents and DF represents the number of documents in which we see the occurrence of this word.

We now can clearly see that the words like “The” “for” etc. are not really relevant as they occur in almost all the document. Whereas, words like honest, Analytics Big-Data are really niche words which should be kept in the analysis.
TF-IDF Matrix :
As we now know the relevance of words (IDF) and the occurrence of words in the documents (TF), we now can multiply the two. Then, find the subject of the document and thereafter the similarity of query with the document.

Now it clearly comes out that document 1 is most relevant to the query “Book for Analytics newbie”.
End Notes
This article is an over simplified version of what really happens in an information retrieval system. In actual, we represent each document as a vector on an n-dimension plane, where n is the count of words in a dictionary built by relevant words in all target documents. Then the query is plotted on the same plane.
The document which makes the least angle with the query is given out as the most relevant document. We will cover this rule (cosine rule) and a simple solved example using Python in the next article.
Thinkpot: Can you think of more strategies to find the relevance of a query in a document? Share with us useful links of related video or article to do information retrieval.
Did you find the article useful? Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.







Informative article Tavish Thumbs up
Wonderful article bhai. I need more of like this. It was really awesome. Hats off to u.
Nice and clear treatment of content-based rec systems. Thanks for sharing