This article was published as a part of the Data Science Blogathon.
INTRODUCTION
Stock prediction is the act of forecasting the future value of stock under predefined conditions. It is important to successfully predict the future values of stocks as it would be beneficial to the investors to help them make decisions on whether to invest in a stock or not.
To predict the same, we have collected past existing data from secondary sources in samples of five sectors with 4 stocks in each sector divided between large, medium, and small-cap stocks. Data on various financial factors were collected for this. Techniques like regression, factor analysis, and correspondence analysis have been used to create the model.
SAMPLING DESIGN
The Indian stock market lists thousands of stocks and so it is essential to apply sampling techniques to represent all types to firms.
The sampling method used is Quota Sampling.
In quota sampling, we first segmented our data into mutually exclusive sub-groups, and then judgment was used to select the stocks from each sector based on a specified proportion.
We took five sectors namely IT, textile, FMCG, auto ancillary, and Pharma which are a mix of aggressive and defensive sectors. For each sector stocks were selected in such a way that we have an equal number of stocks from Large Cap, Medium Cap, and Small Cap.
DATA REQUIREMENT
We were required to collect the following data for 4 stocks in the 5 sectors that were selected. Yearly data starting from FY 1996 was extracted for:
- Historical market cap
- Price Earnings Ratio (P/E)
- Price to Book Ratio (P/B)
- Last Price
- Dividends per share
- Net Profit Margin
- Current Ratio
- Return on Assets
- Return on Common Equity
- Retention Ratio
These will act as predictors of price in the model. It is a good practice to take as many predictors as possible so that model has a higher probability of having a better set of predictors.
Sample for P&G India:
DATA ANALYSIS
The model is used to calculate the theoretical values of stocks of companies in the various sectors. The main use of this model is to predict or determine the future market price of the stock or in general the potential market price and help the investors to profit from price movement as it determines whether the stocks that are judged undervalued(compared to their theoretical value) are bought and the stocks that are judged overvalued are sold. It is expected that the undervalued stocks will rise in value while overvalued stocks will generally decrease in value over time.
METHODOLOGY
1. FACTOR ANALYSIS
Factor analysis is a statistical method used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors.
Factors are the underlying or unstated predictors that are formed by a combination of the observed predictors.
Following results were observed in SPSS-
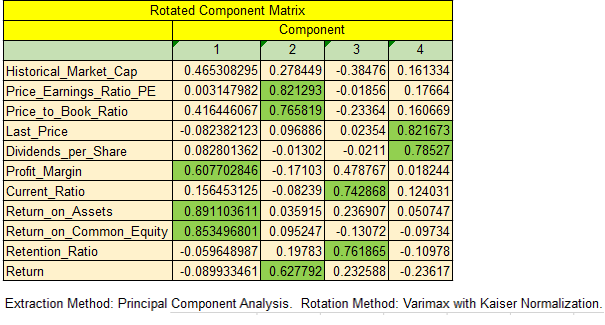
The rows represent predictors and columns are factors. The numerical values indicate the weight-age or loading of predictors onto factors.
The highest weight- age of each predictor(highlighted in green) is assigned to the corresponding factor.
Following are the prominent factors for each factor
A) Factor 1
- Return_on_Assets, Return_on_Common_Equity & Profit_Margin are the variables corresponding to this factor
- This factor consists of the Profitability ratios
B) Factor 2
- P/E ratio, P/B.V & Return
- Consists of Price ratios
C) Factor 3
- The current ratio, Retention ratio
- Consists of Efficiency ratios
B) Factor 4
- Last Price, Dividend per share
- Comprises of latest price and dividends issued by the companies
The 4 factors explain 66.56% of the variance in the data
Applying some tests-
- The hypothesis of KMO and Bartlett’s test- The covariance matrix of predictors is identity(Covariance matrix is the matrix of correlation of each predictor with every other predictor)
- KMO>0.5 results in the rejection of the hypothesis
- P<alpha(sig. level) in Bartlett’s test also rejects the hypothesis
2. REGRESSION MODEL
Here, the focus is on the linear relationship between a dependent variable and one or more independent variables (or ‘predictors’). A function of the independent variables, called the regression function is to be estimated.
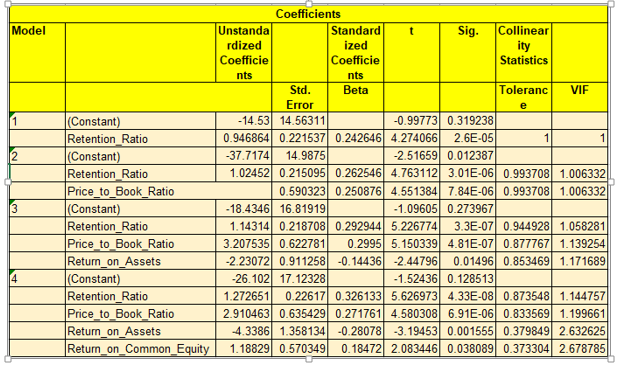
- Step-wise regression technique is used to add predictors one by one
- Model 4 is the most appropriate as per this result
- VIF(variable inflation factor) value < 4 indicates the absence of multicollinearity in the variables
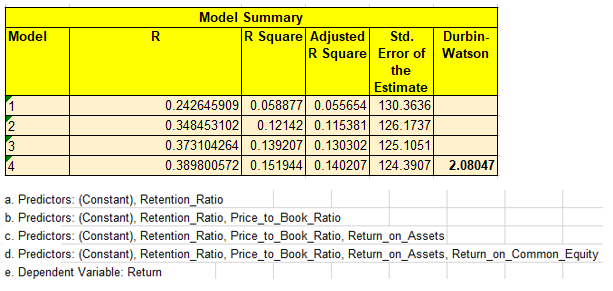
Durbin Watson value close to 2 signifies the absence of auto-correlation(correlation in error terms)
3. CORRESPONDENCE ANALYSIS
Correspondence analysis is a statistical technique that provides a graphical representation of cross-tabulations (which are also known as cross tabs, or contingency tables). Cross tabulations arise whenever it is possible to place events into two or more different sets of categories
Correspondence analysis was conducted between market capitalization with the ratios and results were-
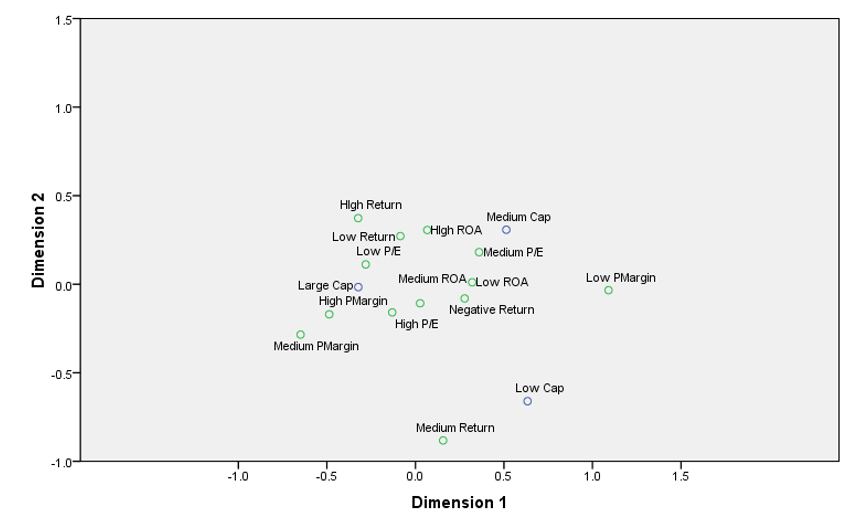
Large-cap is related to low P/E and high P margin
The medium cap is related to high ROA and medium P/E
Low Cap is related to Medium return
The correspondence analysis gives an idea to further improve the model and to create separate models for small, mid, and large-cap stocks
CONCLUSION
Thus we conclude that Ratios like Retention ratio, Price to Book Value, P/E, Return on Equity, Return on assets, etc. have a significant effect on the valuations of stocks.
At the same time, due to the unpredictable nature of stocks due to a large no. of macroeconomic factors, the model can be further improved by including more relevant factors and repeating the above process
About the Author
Gaurav Khatri received his MBA(IB) from IIFT in 2019 and working with the Collections-Strategy and Modelling team at Home Credit
Linkedin: https://www.linkedin.com/in/gauravkhatri7524
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





