This article was published as a part of the Data Science Blogathon.
Overview
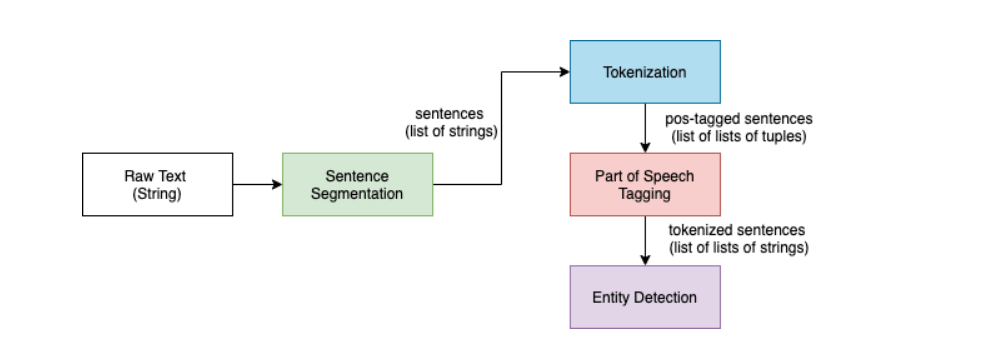
According to the internet, OpenNLP is a machine learning-based toolbox for processing natural language text. It has many features, including tokenization, lemmatization, and part-of-speech (PoS) tagging. Named Entity Extraction (NER) is one feature that can assist us to comprehend queries.
Introduction to Named Entity Extraction
TO Build a model using OpenNLP with TokenNameFinder named entity extraction program, which can detect custom Named Entities that apply to our needs and, of course, are similar to those in the training file. Job titles, public school names, sports games, music album names, apply musician names, music genres, etc. if you understand, you will get my drift.
What is Apache OpenNLP?
OpenNLP is free and open-source (Apache license), and it’s already implemented in our preferred search engines, Solr and Elasticsearch, to varying degrees. Solr’s analysis chain includes OpenNLP-based tokenizing, lemmatizing, sentence, and PoS detection. An OpenNLP NER update request processor is also available. On the other side, Elasticsearch includes a well-maintained Ingest plugin based on OpenNLP NER.
Setup and Basic Usage
To begin, we must add the primary dependency to our XML file. It has an API for Named Entity Recognition, Sentence Detection, POS Tagging, and Tokenization.
org.apache.opennlp opennlp-tools 1.8.4
Sentence Detection
Let’s start with a definition of sentence detection.
Sentence detection is determining the beginning and conclusion of a sentence, which largely depends on the language being used. “Sentence Boundary Disambiguation” is another name for this (SBD).

Sentence detection can be difficult in some circumstances because of the ambiguous nature of the period character. A period marks the conclusion of a phrase, but we can also find it in an email address, an abbreviation, a decimal, and many other places.
For sentence detection, like with most NLP tasks, we’ll require a trained model as input, which we expect to find in the /resources folder.
Tokenizing
We may begin examining a sentence in greater depth now that we have divided a corpus of text into sentences.
Tokenization is breaking down a sentence into smaller pieces known as tokens. These tokens are typically words, numbers, or punctuation marks.
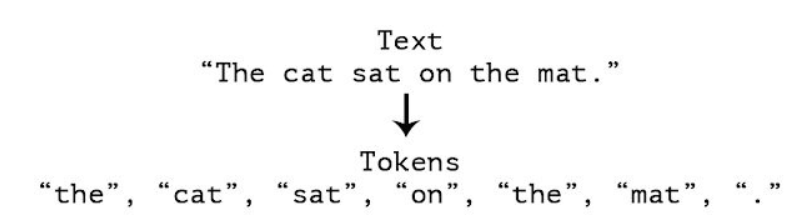
In OpenNLP, there are three types of tokenizers,
1) TokenizerME.
2) WhitespaceTokenizer.
3) SimpleTokenizer.
TokenizerME:
We must first load the model in this situation. Download the pre-trained models for the OpenNLP 1.5 series from the URLs, save them to the /resources folder, and load them from there.
Next, we’ll use the loaded model to create an instance of TokenizerME and use the tokenize() function to perform tokenization on any String:
@Test
public void givenEnglishModel_whenTokenize_thenTokensAreDetected()
throws Exception {
InputStream inputStream = getClass()
.getResourceAsStream("/models/en-token.bin");
TokenizerModel model = new TokenizerModel(inputStream);
TokenizerME tokenizer = new TokenizerME(model);
String[] tokens = tokenizer.tokenize("GitHub is a version control system.");
assertThat(tokens)
.contains( "GitHub, "is", "a", "version", "control"," system", ".");
}
The tokenizer has identified all words and the period character as individual tokens. We can also use this tokenizer with a model that has been custom trained.
WhitespaceTokenizer:
The White Space tokenizer divides a sentence into tokens by using white space characters as delimiters:
@Test
public void WhitespaceTokenizer_whenTokenize_thenTokensAreDetected()
throws Exception {
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;
String[] tokens = tokenizer.tokenize("GitHub is a version control system.");
assertThat(tokens)
.contains( "GitHub, "is", "a", "version", "control"," system", ".");
}
White spaces have broken the sentence, resulting in “Resource.” (with the period character at the end) being treated as a single token rather than two separate tokens for the word “Resource” and the period character.
SimpleTokenizer:
Simple tokenizer breaks the sentence into words, numerals, and punctuation marks, and is a little more complicated than White space Tokenizer. It is the default behavior and does not cause the use of a model.
@Test
public void SimpleTokenizer_whenTokenize_thenTokensAreDetected()
throws Exception {
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
String[] tokens = tokenizer.tokenize("GitHub is a version control system.");
assertThat(tokens)
.contains( "GitHub, "is", "a", "version", "control"," system", ".");
}
Part-of-Speech Tagging
Part-of-speech tagging is another application that requires a list of tokens as input.
They identify this kind of word by a part-of-speech (POS). For the various components of speech, OpenNLP employs the following tags:

NN–singular or plural noun
DT stands for determiner.
VB stands for verb, base form.
VBD – past tense verb
IN–preposition or subordinating conjunction
VBZ–verb, third-person singular present
NNP–singular proper noun.
“TO” – the word “to”
JJ–adjective
These are the same tags that the Penn Tree Bank uses.
We load the proper model and then use POSTaggerME and its method tag() on a group of tokens to tag the phrase,
@Test
public void givenPOSModel_whenPOSTagging_thenPOSAreDetected() throws Exception {
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
String[] tokens = tokenizer.tokenize("Ram has a wife named Lakshmi.");
InputStream inputStreamPOSTagger = getClass() .getResourceAsStream("/models/en-pos-maxent.bin");
POSModel posModel = new POSModel(inputStreamPOSTagger);
POSTaggerME posTagger = new POSTaggerME(posModel);
String tags[] = posTagger.tag(tokens);
assertThat(tags).contains("NNP", "VBZ", "DT", "NN", "VBN", "NNP", ".");
}
We map the tokens into a list of POS tags via the tag() method. Here, the outcome is:
- “Ram” – NNP (proper noun)
- “has” – VBZ (verb)
- “a” – DT (determiner)
- “Wife” – NN (noun)
- “named” – VBZ (verb)
- “Lakshmi” – NNP (proper noun)
- “.” – period
Download the Apache OpenNLP:
One of the best use-cases of TOKENIZER is named entity recognition (NER).
After you’ve downloaded and extracted OpenNLP, you may test and construct models using the command-line tool (bin/opennlp). However, you will not use this tool in production for two reasons:
- If you’re using the Name Finder Java API in a Java application (which incorporates Solr/Elasticsearch), you’ll probably prefer it. It has additional features than the command-line utility.
- Every time you run bin/opennlp, the model is loaded, which adds latency. If you use a REST API to expose NER functionality, you only need to load the model once. The existing Solr/Elasticsearch implementations accomplish this.
We’ll continue to use the command-line tool because it makes it easy to learn about OpenNLP’s features. With bin/opennlp, you can create models and use them with the Java API.
To begin, we’ll use bin/standard opennlp’s input to pass a string. The class name (TokenNameFinder for NER) and the model file will then be passed as parameters:
echo "introduction to solr 2021" | bin/opennlp TokenNameFinder en-ner-date.bin
You’ll almost certainly need your model for anything more advanced. For example, if we want “twitter” to return as a URL component. We can try to use the pre-built Organization model, but it won’t help us:
$ echo "solr elasticsearch twitter" | bin/opennlp TokenNameFinder en-ner-organization.bin
We need to create a custom model for OpenNLP to detect URL chunks.
Building a new model:
For our model, we’ll need the following ingredients:
- some data with the entities we want to extract already labeled (URL parts in this case)
- Change how OpenNLP collects features from the training data if desired.
- Alter the model’s construction algorithm.
Training the data:
elasticsearch solr comparison on twitter solr docker tradeoffs on twitter
elasticsearch introduction demo on twitter solr docker tutorial on twitter
The following are the most important characteristics:
1) Tags must enclose entities. We’re looking for a way to recognize Twitter as a URL.
2) between tags (START/END) and labeled data, add spaces.
3) Use only one label per model (here, URL). It is possible to use multiple labels, although it is not encouraged.
4) having a large amount of data, a minimum of 15000 sentences is recommended by documentation.
5) Each line represents a “sentence.” Some features (which we’ll go into later) Examine the entity’s placement in the sentence. Is it more likely to happen at the start or the end? When performing entity extraction on queries (as we do here), the query is typically one line long. You could have many phrases in a document for index-time entity extraction.
Documents are delimited by empty lines: This is especially important for index-time entity extraction since there is a distinction between documents and sentences. Document limits are important for feature generators at the document level and those influenced by past document outcomes (usually feature generators extending AdaptiveFeatureGenerator)
package opennlp.tools.util.featuregen;
import java.util.List;
public interface AdaptiveFeatureGenerator {
void createFeatures(List features, String[] tokens, int index, String[] previousOutcomes);
default void updateAdaptiveData(String[] tokens, String[] outcomes) {};
default void clearAdaptiveData() {};
}
Generation of features:
The training tool analyses the data extracts some features and feeds them to the machine learning algorithm. Whether a token is a number or a string could be a feature. Alternatively, if the previous tokens were strings or numbers, feature generators in OpenNLP generate such features. Here you will find all of your options. You can always create your feature generators, though.
Put the feature generators and their parameters in an XML file once you’ve decided which ones to use.
Selection and tuning of algorithms:
OpenNLP has classifiers based on maximum entropy (default), perceptron-based, and naive Bayes out of the box. You’d use a parameters file to select the classifier. Here you’ll find examples of all the algorithms that are supported.
There are at least three crucial aspects to look at in the parameters file:
Choice of the algorithm: Naive Bayes will train the model faster, but it will operate as if the provided features are unrelated. This could be the case or it could not. Maximum entropy and perceptron-based classifiers are more costly to execute, but they produce superior results. Especially when features are interdependent.
The number of iterations: The longer you read through the training data, the more influence provided characteristics will have on the result. On the one hand, there is a trade-off between they can learn how much and over-fitting on the other. And, of course, with more iterations, training will take longer.
cutoff: To decrease noise, features that are encountered less than N times are ignored.
Model training and testing:
Now it’s time to put everything together and construct our model. This time, we’ll use the TokenNameFinderTrainer class:
bin/opennlp TokenNameFinderTrainer -model urls.bin -lang ml -params params.txt -featuregen features.xml -data queries -encoding UTF8
The following are the parameters:
–model filename: The name of the output file for our model
–lang language: It is only necessary if you wish to use various models for different languages.
–params params.txt: It is a parameter file for selecting algorithms.
–featuregen features.xml – It contains XML files for feature generation.
–data queries: File containing labeled training data.
–UTF8 encoding. The training data file’s encoding.
Finally, the new model may ensure that “youtube” is recognized as a URL component:
$ echo "solr elasticsearch youtube" | bin/opennlp TokenNameFinder urls.bin
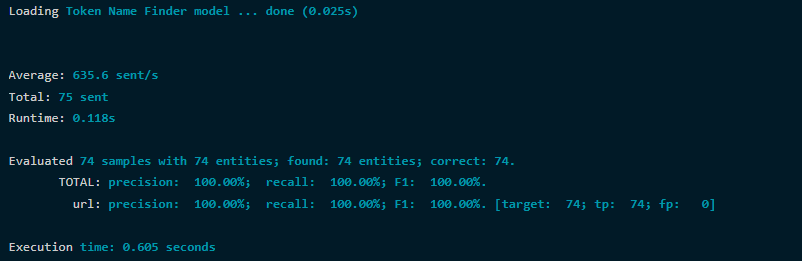
We may use the Evaluation Tool on another labeled dataset to test the model (written in the same format as the training dataset). We’ll use the TokenNameFinderEvaluator class, which takes the same parameters as the TokenNameFinderTrainer command (model, dataset, and encoding):
$ bin/opennlp TokenNameFinderEvaluator -model urls.bin -data test_queries -encoding UTF-8
Goals of Named Entity Recognition
Composite Entities:
When we talk about composite entities, we’re talking about entities that comprise other entities. Here are two unique examples:
Person name: Jaison K White | Dr. Jaison White | Jaison White, jr | Jaison White, PhD
Street Address: 10th main road, Suite 2210 | Havourr Bldg, 20 Mary Street
The vertical bar separates entity values in each example.
Multi-token entities are a significant subset of composite entities. We’ve organized the content this way since delving into composite entities in depth will help us understand multi-token entities later. When the reader has had “enough” of the current section, they should scroll down to the section on multi-token entities.
It is useful to distinguish between two computational issues when working with composite entities.
Decomposition:
Break a composite entity down into its component entities.
Dr. Jaison K White ⇒ {salutation =Dr., first_name = Jaison, middle_name = K, last_name = White}
Recognition:
We embedded the composite item in some unstructured text in this case. The goal is to recognize the entity’s boundaries and its type. Also, it’s possible to parse, or breakdown, it into its elements. Here’s an illustration.
I looked up Dr. Jaison K White. His street address came up as 10th Main road, Suite 2210 in California.
We’d like to see the following outcomes because of our recognition:
Dr. Jaison K White⇒ person_name
10th Main road, Suite 2210 in California ⇒ street_address
One justification for separating parsing and recognition is that original use cases correspond to one. For example, suppose we have a database of entire person names and want to break each one down into its constituent pieces (first name, last name, etc). There is no recognition involved with this. All I’m doing is parsing.
The “divide-and-conquer” strategy is another factor. Assume our job is to recognize and parse composite items in unstructured text. It makes appropriate to take a two-stage approach: first, recognize the entity boundaries and types, then parse for the recognized entity.
Use Cases of Named Entity Recognition
Search Engine and Documents Indexing:
NER is a textual document indexing and cataloging technology that may show and catalog textual document datasets, such as online reports, news, and articles. It may extract relevant entities from them, which will then classify the reports into the right categories. We can use these detected entities to index documents, which will aid search engines in providing appropriate document recommendations based on the search query.
Sentimental analysis:
Sentiment analysis, also known as Opinion Mining, entails developing an algorithm to gather and categorize opinions on a particular entity. Products, individuals, services, and other entities can describe the entity. Because it is used to extract relevant features of items or entities, NER is one of the most crucial components in opinion mining. We can do the opinion analysis over time using these extracted data to see if the product sentiment classification rises or lowers (positive or negative).

Chatbots:
Chatbots: The goal of implementing NER in the chatbot is to identify responses to a variety of fact-based inquiries, and these answers are the entities that NER can identify. Using natural language processing (NER) in chatbot systems makes seeking answers much more efficient because it eliminates the need to engage with customer service representatives.

Problems with Named Entity Extraction
There are a few difficulties that need to be addressed.
‘ambiguity’ in segmentation(detection):
Consider the word ‘New Zealand.’ As separate entities, ‘New’ and ‘Zealand’ can be detected. As a result, selecting whether to view ‘New Zealand’ as a single entity or ‘New’ and ‘York’ as two separate entities are critical.
‘ambiguity’ in tag assignment(Recognition):
We have a girl’s name (PERSON) and a cosmetics brand called ‘Meera’ (Organization in India). Here are a few additional ambiguities. This may create an ambiguity in identifying and recognizing the right word tag.
Lack of Resources and Foreign Words:
When there is a paucity of textual information resources, the named entity extraction technique can be difficult to detect words entities.
Some languages, like Arabic, Mongolian, and Indonesian, as well as Indian languages like Hindi, Punjabi, Bengali, and Urdu, are resource-poor, making the work of recognizing Name entities more difficult.
Another difficult aspect of this subject is learning words that aren’t commonly used these days or that many people did not use today.
Word Abbreviations:
If we abbreviate abbreviations, versions of words. We would reduce words to make it easier for us to write and grasp the meaning of the words. However, in NLP, word abbreviations are regarded as the most difficult problem to solve since they entail a tedious process that causes the use of a label for identification before they can expand it to its original terms. It will certainly impair named entity extraction performance since we cannot categorize truncated words, it must handle properly to their correct entity and during the text pre-processing step.
Image: Source
About Myself:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Science Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and chemistry to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
End Notes
1) Named Entity Extraction is a Natural Language Processing (NLP) subtask that is important in automated information extraction. The NER has recently gained a lot of importance in extracting meaningful insights because of the large amount of textual content available on the web. Because of its key role in many NLP applications, named entity extraction is emerging as a discipline that will continue to improve.
2) We reviewed a few keys Named Entity Extraction components in this article. Starting with an explanation of what NER is and how it works, we move on to discuss real-world use cases that use named entity extraction and the difficulties that named entity extraction applications to encounter.
I hope you found this topic interesting!
If you have questions, please leave them in the comments area.
Thank you for reading.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.





{kind=link}
{kind=link}
{kind=link}