Using a large language model for the first time often feels like you are holding raw intelligence in your hands. They tend to write, summarize, and reason extremely well. However, you build and ship a real product, and all of the cracks in the model show themselves. It doesn’t remember what you said yesterday, and it starts to make things up when it runs out of context. This isn’t because the model isn’t intelligent. It is because the model is isolated from the outside world, and it is constrained by context windows that act like a little whiteboard. This can’t be overcome with a better prompt – you need an actual context around the model. This is where context engineering comes to the rescue. This article acts as the comprehensive guide on context engineering, defining the word and describing the processes involved.
Table of contents
The problem no one can escape
LLMs are brilliant but limited in their scope. This is in part due to them having:
- No access to private documents
- No memory of past conversations
- Limited context window
- Hallucination under pressure
- Degradation when the context window gets too big

While some of the limitations are necessary (lacking access to private documents), in the case of limited memory, hallucination and limited context window, it is not. This posits context engineering as the solution, not an add-on.
What is Context Engineering?
Context engineering is the process of structuring the entire input provided to a large language model to enhance its accuracy and reliability. It involves structuring and optimizing the prompts in a way that an LLM gets all the “context” that it needs to generate an answer that exactly matches the required output.
Read more: What is Context Engineering?
What does it offer?
Context engineering exists as the practice of feeding the model exactly the right info, in the right order, at the right time, using an orchestrated architecture. It’s not about changing the model itself, but about building the bridges that connect it to the outside world, retrieving external data, connecting it to live tools, and giving it a memory to ground its responses in facts, not just its training data. This isn’t limited to the prompt, hence making it different from prompt engineering. It’s implemented at a system design level.
Context engineering has less to do with what the user can put inside the prompt, and more with the architecture choice of the model used by the developer.
The Building Blocks
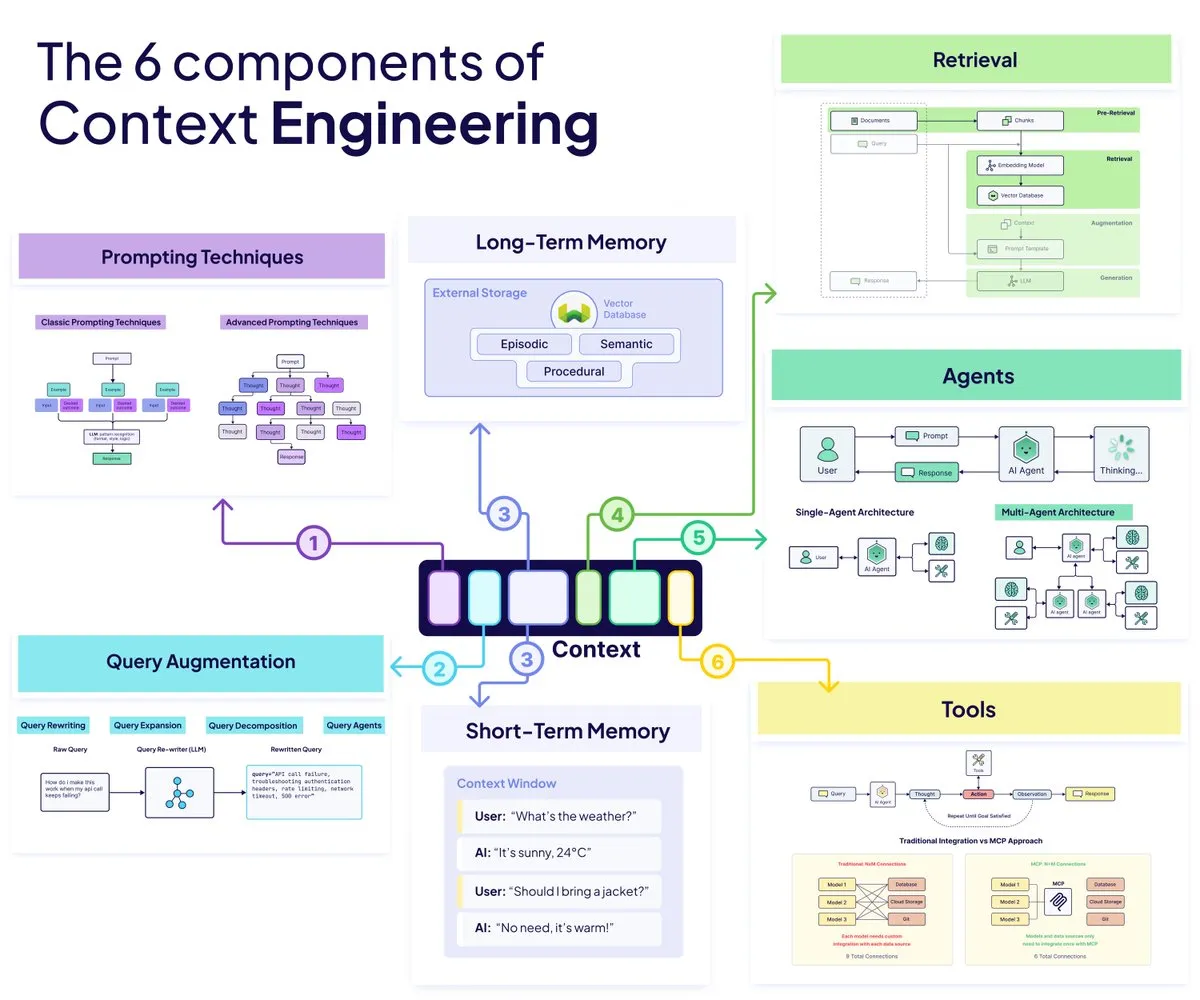
Here are the 6 building blocks of Content Engineering framework:
1. Agents
AI Agents are the part of your system that decides what to do next. They read the situation, pick the right tools, adjust their approach, and make sure the model is not guessing blindly. Instead of a rigid pipeline, agents create a flexible loop where the system can think, act, and correct itself.
- They break down tasks into steps
- They route information where it needs to go
- They keep the whole workflow from collapsing when things change
2. Query Augmentation
Query augmentation cleans up whatever the user throws at the model. Real users are messy, and this layer turns their input into something the system can actually work with. By rewriting, expanding, or breaking the query into smaller parts, you ensure the model is searching for the right thing instead of the wrong thing.
- Rewriting removes noise and adds clarity
- Expansion broadens the search when intent is vague
- Decomposition handles complex multi question prompts
3. Retrieval
Data Retrieval via. Retrieval Augmented Generation, is how you surface the single most relevant piece of information from a huge knowledge base. You chunk documents in a way the model can understand, pull the right slice at the right time, and give the model the facts it needs without overwhelming its context window.
- Chunk size affects both accuracy and understanding
- Pre chunking speeds things up
- Post chunking adapts to tricky queries
4. Prompting Techniques
Prompting techniques steer the model’s reasoning once the right information is in front of it. You shape how the model thinks, how it explains its steps, and how it interacts with tools or evidence. The right prompt structure can turn a fuzzy answer into a confident one.
- Chain of Thought encourages stepwise reasoning
- Few shot examples show the ideal outcome
- ReAct pairs reasoning with real actions
5. Memory
Memory gives your system continuity. It keeps track of what happened earlier, what the user prefers, and what the agent has learned so far. Without memory, your model resets every time. With it, the system becomes smarter, faster, and more personal.
- Short term memory lives inside the context window
- Long term memory stays in external storage
- Working memory supports multi step flows
6. Tools
Tools let the model reach beyond text and interact with the real world. With the right toolset, the model can fetch data, execute actions, or call APIs instead of guessing. This turns an assistant into an actual operator that can get things done.
- Function calling creates structured actions
- MCP standardizes how models access external systems
- Good tool descriptions prevent mistakes
How do they work together?
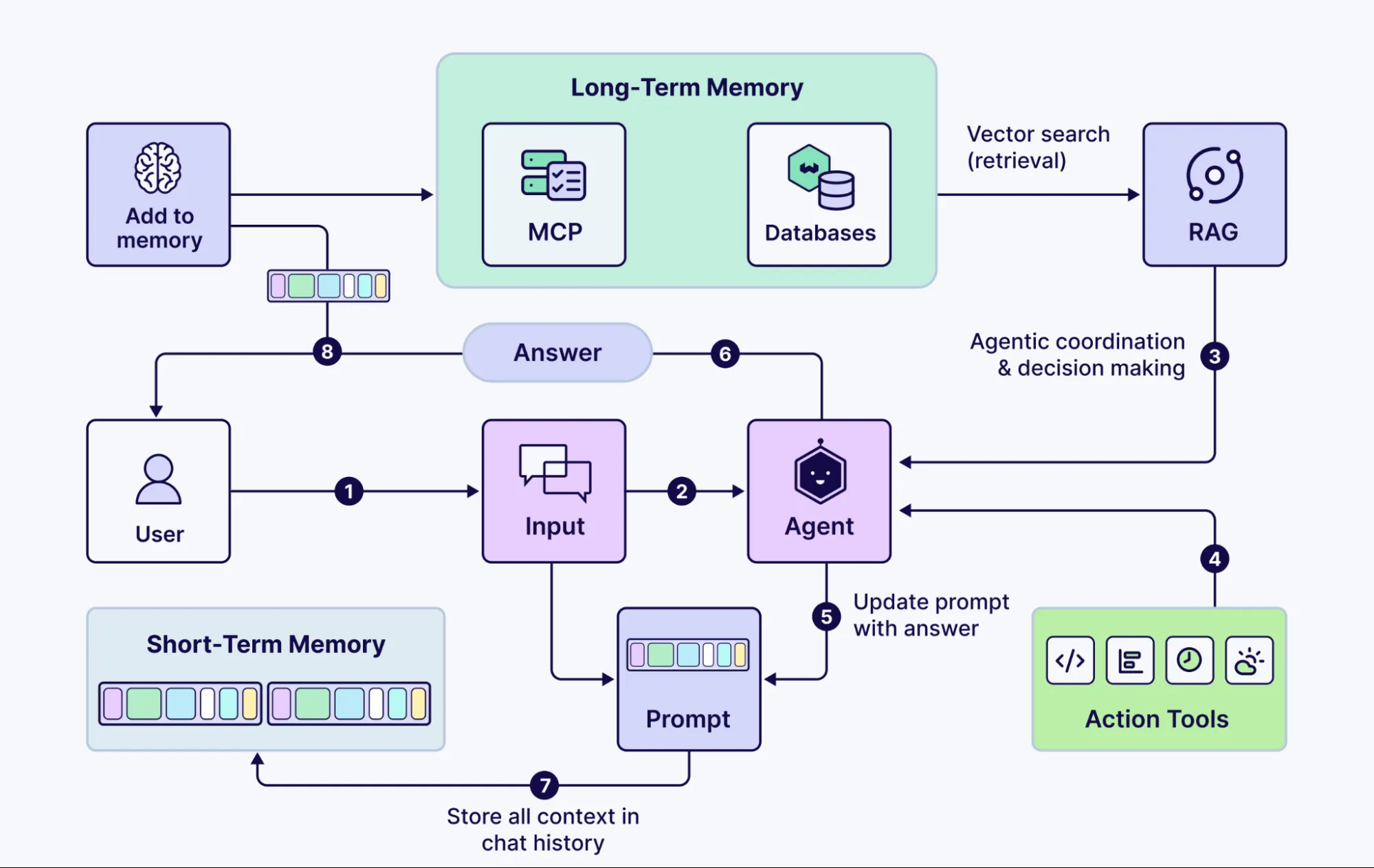
Paint a picture of a modern AI app:
- User sends a messy query
- Query agent rewrites it
- Retrieval system finds evidence via smart chunking
- Agent validates info
- Tools pull real-time external data
- Memory stores and retrieves context
Picture it like this:
The user sends a messy query. The query agent receives it and rewrites it for clarity. The RAG system finds evidence within the query via smart chunking. The agent receives this information and checks its authenticity and integrity. This information is used to make appropriate calls via MCP to pull real-time data. The memory stores information and context obtained during this retrieval and cleaning.
This information can be retrieved later on to get back on track, in-case relevant context is required. This saves redundant processing and allows processed information retrieval for future use.
Real-world examples
Here are some real world applications of a context engineering architecture:
- Helpers for Customer Support: Agents revise vague customer inquiries, extract product-specific documents, check past tickets in long-term memory, and use tools to fetch order status. The model doesn’t guess; it responds with known context.
- Internal Knowledge Assistants for Teams: Employees ask messy, half-formed questions. Query augmentation cleans them up, retrieval finds the proper policy or technical document, and memory recalls past conversations. Now, the agent serves as a trustworthy internal layer of searching and reasoning to help.
- AI Research Co-Pilots: The system breaks down complex research inquiries into its component parts, retrieves relevant papers using semantic or hierarchical chunking, and synthesizes the results. Tools are able to access live datasets while memory will keep track of previous hypotheses, notes, etc.
- Workflow Automation Agents: The agent plans a task with many steps, calls APIs, checks calendars, updates databases, and uses long-term memory to personalize the action. Retrieval brings appropriate rules or SOPs into the workflow to keep it legal or accurate.
- Domain-Specific Assistants: Retrieval pulls in verified documents, guidelines, or regulations. Memory stores previous cases. Tools access live systems or datasets. Query rewriting reduces user ambiguity to keep model grounded and safe.
What this means for the future of AI engineering
With context engineering, the focus is no longer on an ongoing conversation with a model, but instead on designing the ecosystem context that will enable the model to perform intelligently. This is not just about prompts, retrieval tricks, or cobbled together architecture. It’s a tightly coordinated system where agents decide what to do, queries get cleaned up, the right facts show up at the right time, memory carries past context forward, and tools let the model act in the real world.
These elements will continue to develop and evolve, though. What will define the more successful models, apps, or tools are the ones built on intentional, deliberative context design. Bigger models alone won’t get us there, but better engineering will. The future will belong to the builders, those who thought about the environment just as much as they thought about the models.
Frequently Asked Questions
Q1. What problem does context engineering actually solve?
A. It fixes the disconnect between an LLM’s intelligence and its limited awareness. By controlling what information reaches the model and when, you avoid hallucination, missing context, and the blind spots that break real-world AI apps.
Q2. How is context engineering different from prompt engineering?
A. Prompt engineering shapes instructions. Context engineering shapes the entire system around the model, including retrieval, memory, tools, and query handling. It’s an architectural discipline, not a prompt tweak.
Q3. Why isn’t a larger context window enough?
A. Bigger windows still get noisy, slow, and unreliable. Models lose focus, mix unrelated details, and hallucinate more. Smart context beats sheer size.
Q4. Is context engineering only for RAG systems?
A. No. It improves any AI application that needs memory, tool use, multi-step reasoning, or interaction with private or dynamic data.
Q5. What skills do developers need to build context-engineered systems?
A. Strong system design thinking, familiarity with agents, RAG pipelines, memory stores, and tool integration. The goal is orchestrating information, not just calling an LLM.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






