The core idea behind Chain of Thought (CoT) is to encourage an AI model to reason step by step before producing an answer. While the concept itself is not new and is essentially a structured way of asking models to explain their reasoning, it remains highly relevant today. Interest in CoT increased again after OpenAI released a preview of its o1 model, which renewed focus on reasoning-first approaches. In this article, I will explain what CoT is, explore the different techniques that are publicly available, and test whether these methods actually improve the performance of modern AI models. Let’s dive in.
Table of contents
- The Research Behind Chain of Thought Prompting
- Baseline Score of LLMs: How Model Performance Is Measured
- High-Level View of Chain of Thought (CoT)
- Understanding Zero-Shot Prompting
- Understanding Few-Shot Prompting
- Understanding Chain of Thought (CoT)
- Automatic Chain-of-Thought (Auto-CoT)
- Conclusion
- Frequently Asked Questions
The Research Behind Chain of Thought Prompting
Over the last 2 years, many research papers have been published on this topic. What recently caught my eye is this repository that brings together key research related to Chain of Thought (CoT).
The different step-by-step reasoning techniques discussed in these papers are illustrated in the image below. A large portion of this influential work has come directly from research groups at DeepMind and Princeton.
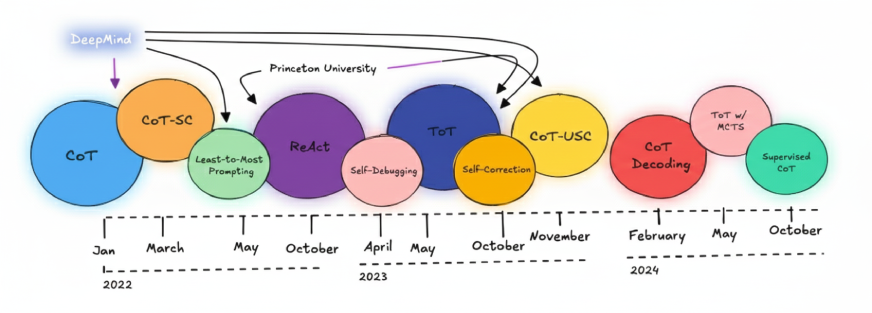
The idea of COT was first introduced by DeepMind in 2022. Since then, newer research has explored more advanced techniques, such as combining Tree of Thoughts (ToT) with Monte Carlo Search, as well as using CoT without any initial prompt, commonly referred to as zero-shot CoT.
Baseline Score of LLMs: How Model Performance Is Measured
Before we talk about improving Large Language Models (LLMs), we first need a way to measure how well they perform today. This initial measurement is called the baseline score. A baseline helps us understand a model’s current capabilities and provides a reference point for evaluating any improvement techniques, such as Chain-of-Thought prompting.
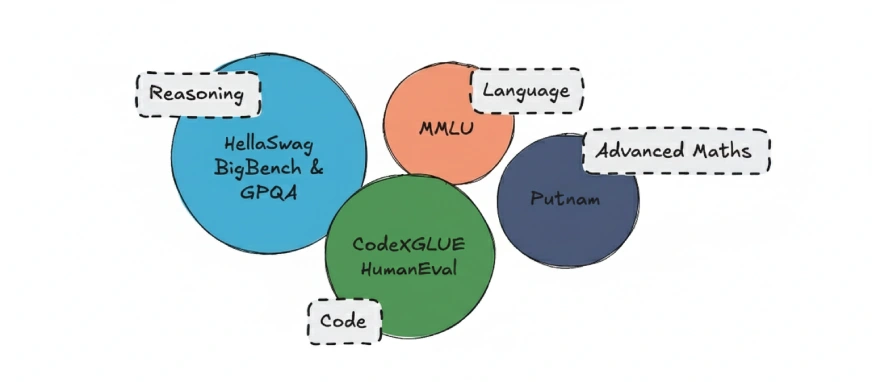
LLMs are usually evaluated using standardized benchmarks. Some commonly used ones include:
- MMLU: Tests language understanding
- BigBench: Evaluates reasoning abilities
- HellaSwag: Measures commonsense reasoning
However, not all benchmark scores should be taken at face value. Many popular evaluation datasets are several years old and may suffer from data contamination, meaning models may have indirectly seen parts of the test data during training. This can inflate reported scores and give a misleading picture of true model performance.
To address this, newer evaluation efforts have emerged. For example, Hugging Face released an updated LLM leaderboard that relies on fresher, less-contaminated test sets. On these newer benchmarks, most models score noticeably lower than they did on older datasets, highlighting how sensitive evaluations are to benchmark quality.
This is why understanding how LLMs are evaluated is just as important as looking at the scores themselves. In many real-world settings, organizations choose to build private, internal evaluation sets tailored to their use cases, which often provide a more reliable and meaningful baseline than public benchmarks alone.
Also Read: 14 Popular LLM Benchmarks to Know in 2026
High-Level View of Chain of Thought (CoT)
Chain of Thought was introduced by the Brain Team at DeepMind in their 2022 paper Chain of Thought Prompting Elicits Reasoning in Large Language Models.
While the idea of step-by-step reasoning is not new, CoT gained renewed attention after the release of OpenAI’s o1 model, which brought reasoning-first approaches back into focus. The DeepMind paper explored how carefully designed prompts can encourage large language models to reason more explicitly before producing an answer.
Chain of Thought is a prompting technique that activates a model’s inherent reasoning ability by encouraging it to break a problem into smaller, logical steps instead of answering directly. This makes it especially useful for tasks that require multi-step reasoning, such as math, logic, and commonsense understanding.
At the time this research was introduced, most prompting approaches relied mainly on one-shot or few-shot prompting without explicitly guiding the model’s reasoning process.
Understanding Zero-Shot Prompting
Zero-shot prompting means asking a model to perform a task without providing any examples or prior context. For example, you open ChatGPT or another reasoning model and directly ask a question. The model relies entirely on its existing knowledge to generate an answer.
In this setup, the prompt does not include any examples, yet the LLM can still understand the task and produce a meaningful response. This ability reflects the model’s zero-shot capability. A natural question then arises: can we improve zero-shot performance? The answer is yes, through a technique called instruction tuning. Find more abut it here.
Instruction tuning involves training a model not only on raw text but also on datasets formatted as instructions and corresponding responses. This helps the model learn how to follow instructions more effectively, even for tasks it has never explicitly seen before. As a result, instruction-tuned models perform significantly better in zero-shot settings.
Reinforcement Learning from Human Feedback (RLHF) further enhances this process by aligning model outputs with human preferences. In simple terms, instruction tuning teaches the model how to respond to instructions, while RLHF teaches it how to respond in ways humans find useful and appropriate.
Popular models such as ChatGPT, Claude, Mistral, and Phi-3 use a combination of instruction tuning and RLHF. However, there are still cases where zero-shot prompting may fall short. In such situations, providing a few examples in the prompt, known as few-shot prompting, can lead to better results.
Also Read: Base LLM vs Instruction-Tuned LLM
Understanding Few-Shot Prompting
Few-shot prompting is useful when zero-shot prompting produces inconsistent results. In this approach, the model is given a small number of examples within the prompt to guide its behavior. This enables in-context learning, where the model infers patterns from examples and applies them to new inputs. Research by Kaplan et al. (2020) and Touvron et al. (2023) shows that this capability emerges as models scale.
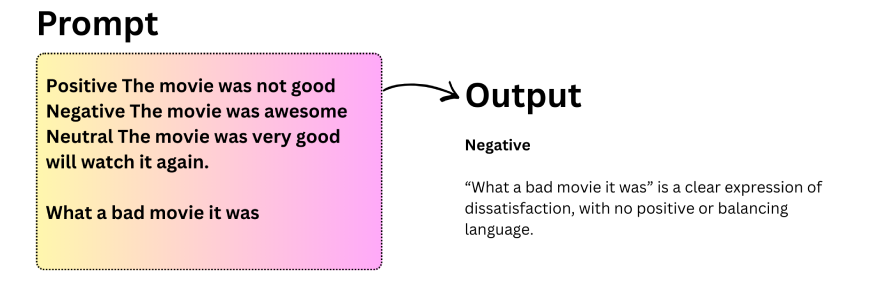
Key observations about few-shot prompting:
- LLMs can generalize well even when example labels are randomized.
- Models remain robust to changes or distortions in input format.
- Few-shot prompting often improves accuracy compared to zero-shot prompting.
- It struggles with tasks requiring multi-step reasoning, such as complex arithmetic.
When zero-shot and few-shot prompting are not sufficient, more advanced techniques like Chain of Thought prompting are required to handle deeper reasoning tasks.
Understanding Chain of Thought (CoT)
Chain of Thought (CoT) prompting enables complex reasoning by encouraging a model to generate intermediate reasoning steps before arriving at a final answer. By breaking problems into smaller, logical steps, CoT helps LLMs handle tasks that require multi-step reasoning. It can also be combined with few-shot prompting for even better performance.
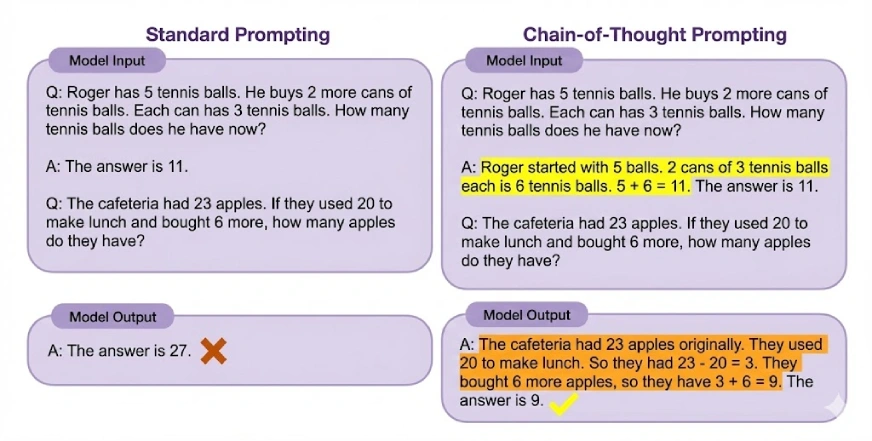
Let’s experiment with Chain of Thought prompting:
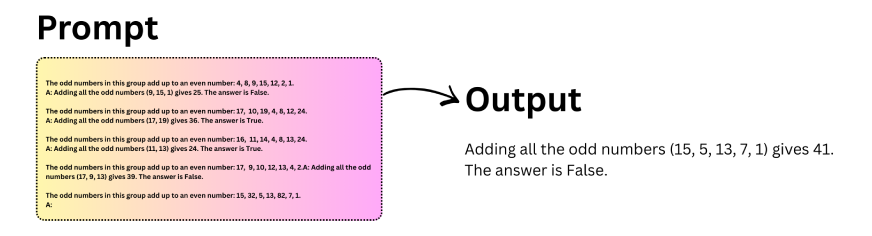
A widely used variant of this approach is zero-shot Chain of Thought. Instead of providing examples, you simply add a short instruction such as “Let’s think step by step” to the prompt. This small change is often enough to trigger structured reasoning in the model.

Let’s understand this with the help of an example:
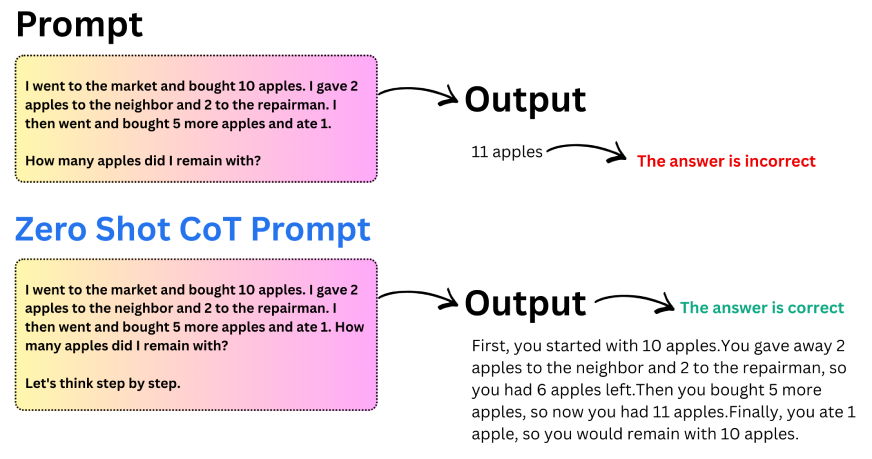
Key takeaways from Zero-Shot CoT:
- Adding a single reasoning instruction can significantly improve accuracy.
- Models produce more structured and logical answers.
- Zero-shot CoT is useful when examples are unavailable.
- It works especially well for arithmetic and logical reasoning tasks.
This simple yet powerful technique demonstrates how minor changes in prompting can lead to meaningful improvements in model reasoning.
Automatic Chain-of-Thought (Auto-CoT)
Standard Chain-of-Thought prompting requires humans to manually create reasoning examples, which is time-consuming and prone to errors. Earlier attempts to automate this process often struggled with noisy or incorrect reasoning. Auto-CoT addresses this problem by emphasizing diversity in the reasoning examples it generates, reducing the impact of individual mistakes.
nstead of relying on carefully written prompts, Auto-CoT automatically selects representative questions from a dataset and generates reasoning chains for them. This makes the approach more scalable and less dependent on human effort.
Auto-CoT works in two stages:
- Stage 1 – Clustering: Questions from the dataset are grouped into clusters based on similarity. This ensures coverage across different types of problems.
- Stage 2 – Sampling: One representative question is selected from each cluster, and a reasoning chain is generated for it. Simple heuristics, such as preferring shorter questions, are used to maintain reasoning quality.

By focusing on diversity and automation, Auto-CoT enables scalable Chain-of-Thought prompting without the need for manually crafted examples.
Also Read: 17 Prompting Techniques to Supercharge Your LLMs
Conclusion
Chain-of-Thought prompting changes how we work with large language models by encouraging step-by-step reasoning instead of one-shot answers. This is important because even strong LLMs often struggle with tasks that require multi-step reasoning, despite having the necessary knowledge.
By making the reasoning process explicit, Chain-of-Thought consistently improves performance on tasks like math, logic, and commonsense reasoning. Automatic Chain-of-Thought builds on this by reducing manual effort, making structured reasoning easier to scale.
The key takeaway is simple: better reasoning does not always require larger models or retraining. Often, it comes down to better prompting. Chain-of-Thought remains a practical and effective way to improve reliability in modern LLMs.
Frequently Asked Questions
Q1. What is Chain of Thought prompting?
A. Chain of Thought prompting is a technique where you ask an AI model to explain its reasoning step by step before giving the final answer. This helps the model break complex problems into smaller, logical steps.
Q2. What is Chain of Thought prompting TCS answers?
A. In TCS-style answers, Chain of Thought prompting means writing clear intermediate steps to show how a solution is reached. It focuses on logical reasoning, structured explanation, and clarity rather than jumping directly to the final answer.
Q3. Why is Chain of Thought prompting effective?
A. Chain of Thought prompting is effective because it guides the model to reason step by step. This reduces mistakes, improves accuracy on complex tasks, and helps the model handle math, logic, and multi-step reasoning problems better.
Q4. What is the difference between Chain of Thought and prompt chaining?
A. Chain of Thought shows reasoning steps within a single response, while prompt chaining splits a task into multiple prompts. CoT focuses on internal reasoning, whereas prompt chaining manages workflows across multiple model calls.
Q5. What are the key steps in Chain of Thought?
A. The key steps in Chain of Thought include understanding the problem, breaking it into smaller parts, reasoning through each step logically, and then combining those steps to reach a final, well-justified answer.
Q6. What are the benefits of using CoT?
A. Using CoT improves reasoning accuracy, reduces logical errors, and makes AI responses more transparent. It works especially well for complex tasks like arithmetic, logical puzzles, and decision-making problems that require multiple reasoning steps.
Growth Hacker | Generative AI | LLMs | RAGs | FineTuning | 62K+ Followers https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/





