If you’ve been watching the open-source LLM space, you already know it has turned into a full-blown race. Every few months, a new model comes out claiming to push the boundary and some genuinely do. Chinese labs especially have been moving fast, with models like GLM 4.6, Kimi K2 Thinking, Qwen 3 Next, ERNIE-4.5-VL and more. So when DeepSeek dropped V3.2, the obvious question wasn’t “Is this the new king?” The real question was:
Does this update actually move the open-source world forward, or is it just another model in the mix?
To answer that, let’s walk through the story behind V3.2, what changed, and why people are paying attention.
Table of contents
What is DeepSeek V3.2?
DeepSeek V3.2 is an upgraded version of DeepSeek-V3.2-Exp which was released back in October. It is designed to push reasoning, long-context understanding, and agent workflows further than previous versions. Unlike many open models that simply scale parameters, V3.2 introduces architectural changes and a much heavier reinforcement-learning phase to improve how the model thinks, not just what it outputs.
DeepSeek also released two variants:
- V3.2 (Standard): The practical, deployment-friendly version suitable for chat, coding, tools, and everyday workloads.
- V3.2 Speciale: A high-compute, reasoning-maximized version that produces longer chains of thought and excels at Olympiad-level math and competitive programming.
Performance and Benchmarks for DeepSeek V3.2
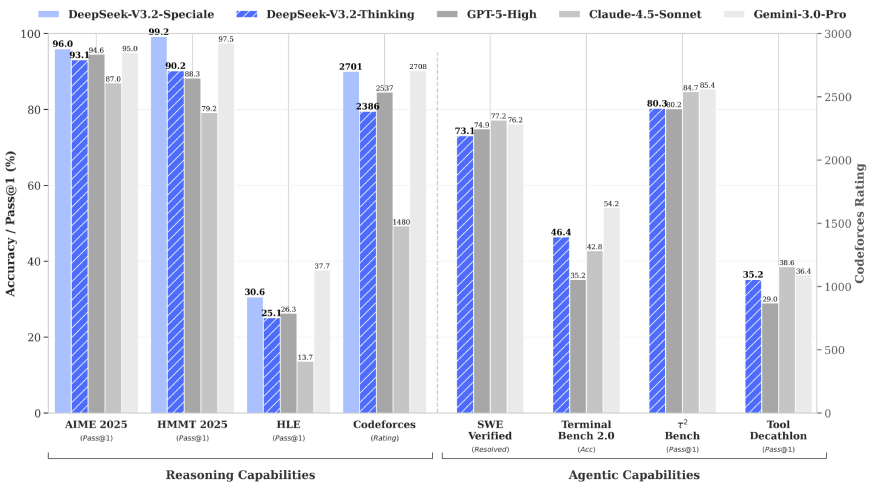
DeepSeek V3.2 comes with some of the strongest benchmark results we’ve seen from an open-source mode.
- In math-heavy tests like AIME 2025 and HMMT 2025, the Speciale variant scores 96% and 99.2%, matching or surpassing models like GPT-5 High and Claude 4.5.
- Its Codeforces rating of 2701 places it firmly in competitive-programmer territory, while the Thinking variant still delivers a solid 2386.
- On agentic tasks, DeepSeek holds its own with 73% on SWE Verified and 80 percent on the τ² Bench, even if top closed models edge ahead in a few categories.
The Big Idea: Smarter “Skimming”
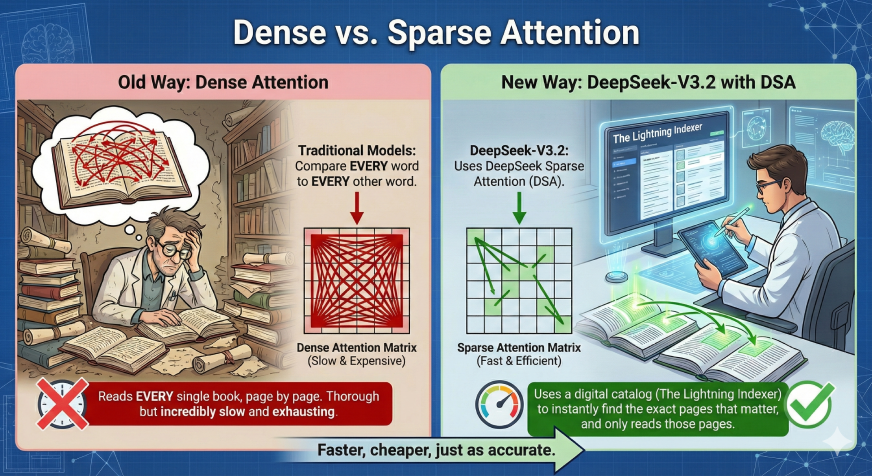
Most powerful AI models suffer from a common problem: as the document gets longer, the model gets much slower and more expensive to run. This is because traditional models try to compare every single word to every other word to understand context.
DeepSeek-V3.2 solves this by introducing a new method called DeepSeek Sparse Attention (DSA). Think of it like a researcher in a library:
- Old Way (Dense Attention): The researcher reads every single book on the shelf, page by page, just to answer one question. It is thorough but incredibly slow and exhausting.
- New Way (DeepSeek-V3.2): The researcher uses a digital catalog (The Lightning Indexer) to instantly find the exact pages that matter, and only reads those pages. It is just as accurate, but much faster.
DeepSeek V3.2 Architecture
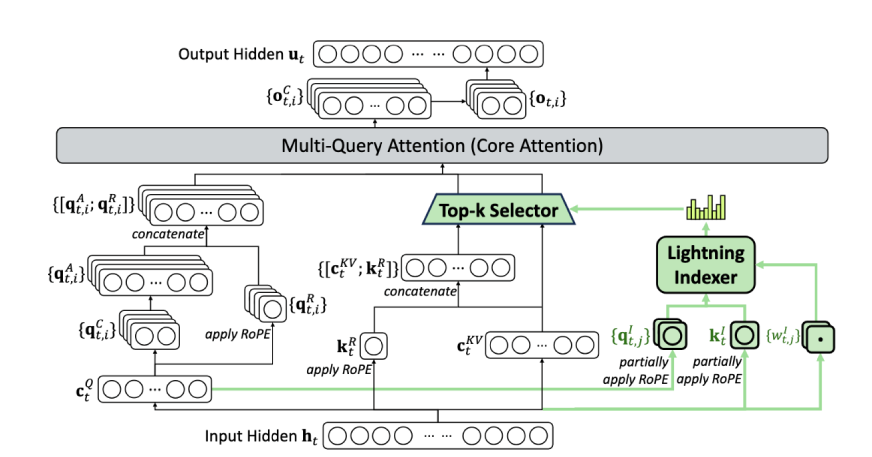
The core innovation is DSA (DeepSeek Sparse Attention), which has two main steps:
1. The Lightning Indexer (The Scout)
Before the AI tries to understand the text, a lightweight, super-fast tool called the “Lightning Indexer” scans the content. It gives every piece of information a “relevance score.” It asks: “Is this piece of info useful for what we are doing right now?”
2. The Top-k Selector (The Filter)
Instead of feeding everything into the AI’s brain, the system picks only the “Top-k” (the highest scoring) pieces of information. The AI ignores the irrelevant fluff and focuses its computing power strictly on the data that matters.
Does It Actually Work?
You might worry that “skimming” makes the AI non-accurate. According to the data, it does not.
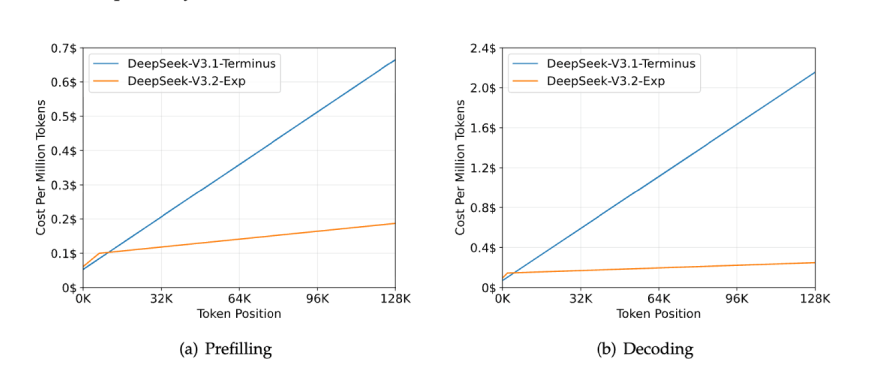
- Same Intelligence: DeepSeek-V3.2 performs just as well as its predecessor (DeepSeek-V3.1-Terminus) on standard tests and human preference charts (ChatbotArena).
- Better at Long Tasks: Surprisingly, it actually scored higher on some reasoning tasks involving very long documents.
- Training: It was taught to do this by first watching the older, slower model work (Dense Warm-up) and then practicing on its own to pick the right information (Sparse Training).
What This Means for Users?
Here is the “What can it do for others” value proposition:
- Massive Speed Boost: Because the model isn’t bogging itself down processing irrelevant words, it runs significantly faster, especially when dealing with long documents (like legal contracts or books).
- Lower Cost: It requires less computing power (GPU hours) to get the same result. This makes high-end AI more affordable to run.
- Long-Context Mastery: Users can feed it massive amounts of data (up to 128,000 tokens) without the system slowing to a crawl or crashing, making it perfect for analyzing big datasets or long stories.
Thinking in Tool-Use
DeepSeek now retains its internal reasoning context while using tools rather than restarting its thought process after every step, which makes completing complex tasks significantly faster and more efficient.
- Previously, every time the AI used a tool (like running code), it forgot its plan and had to “re-think” the problem from scratch. This was slow and wasteful.
- Now, the AI keeps its thought process active while it uses tools. It remembers why it is doing a task and doesn’t have to start over after every step.
- It only clears its “thoughts” when you send a new message. Until then, it stays focused on the current job.
Result: The model is faster and cheaper because it doesn’t waste energy thinking about the same thing twice.
Note: This works best when the system separates “tool outputs” from “user messages.” If your software treats tool results as user chat, this feature won’t work.

You can read more about DeepSeek V3.2 here. Let’s see how the model performs in the section given below:
Task 1: Create a Game
Create a cute and interactive UI for a “Guess the Word” game where the player knows a secret word and provides 3 short clues (max 10 letters each). The AI then has 3 attempts to guess the word. If the AI guesses correctly, it wins; otherwise, the player wins.
My Take:
DeepSeek created an intuitive game with all the requested features. I found this implementation to be excellent, delivering a polished and engaging experience that met all requirements perfectly.
Task 2: Planning
I need to plan a 7-day trip to Kyoto, Japan, for mid-November. The itinerary should focus on traditional culture, including temples, gardens, and tea ceremonies. Find the best time to see the autumn leaves, a list of three must-visit temples for ‘Momiji’ (autumn leaves), and a highly-rated traditional tea house with English-friendly services. Also, find a well-reviewed ryokan (traditional Japanese inn) in the Gion district. Organize all the information into a clear, day-by-day itinerary.
Output:

Find full output here.
My Take:
The V3.2 response is excellent for a traveler who wants a clear, actionable, and well-paced plan. Its formatting, logical geographic flow, and integrated practical advice make it ready to use almost directly out of the box. It demonstrates strong synthesis of information into a compelling narrative.
Also Read: DeepSeek Math V2 Guide: Smarter AI for Real Math
Conclusion
DeepSeek V3.2 isn’t trying to win by size, it wins by thinking smarter. With Sparse Attention, lower costs, long-context strength, and better tool-use reasoning, it shows how open-source models can stay competitive without massive hardware budgets. It may not dominate every benchmark, but it meaningfully improves how real users can work with AI today. And that’s what makes it stand out in a crowded field.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.





