Large AI models are scaling rapidly, with bigger architectures and longer training runs becoming the norm. As models grow, however, a fundamental training stability issue has remained unresolved. DeepSeek mHC directly addresses this problem by rethinking how residual connections behave at scale. This article explains DeepSeek mHC (Manifold-Constrained Hyper-Connections) and shows how it improves large language model training stability and performance without adding unnecessary architectural complexity.
Table of contents
The Hidden Problem With Residual and Hyper-Connections
Residual connections have been a core building block of deep learning since the release of ResNet in 2016. They allow networks to create shortcut paths, enabling information to flow directly through layers instead of being relearned at every step. In simple terms, they act like express lanes in a highway, making deep networks easier to train.
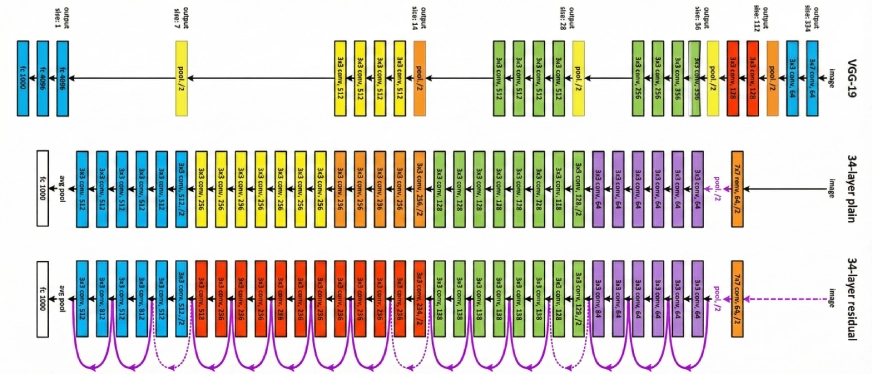
This approach worked well for years. But as models scaled from millions to billions, and now hundreds of billions of parameters, its limitations became clear. To push performance further, researchers introduced Hyper-Connections (HC), effectively widening these information highways by adding more paths. Performance improved noticeably, but stability did not.
Training became highly unstable. Models would train normally and then suddenly collapse around a specific step, with sharp loss spikes and exploding gradients. For teams training large language models, this kind of failure can mean wasting massive amounts of compute, time, and resources.
What Is Manifold-Constrained Hyper-Connections (mHC)?
It is a general framework that maps the residual connection space of HC to a certain manifold to reinforce the identity mapping property, and at the same time involves strict infrastructure optimization to be efficient.
Empirical tests show that mHC is good for large-scale training, delivering not only clear performance gains but also excellent scalability. We expect mHC, being a versatile and accessible addition to HC, to aid in the comprehension of topological architecture design and to propose new paths for the development of foundational models.
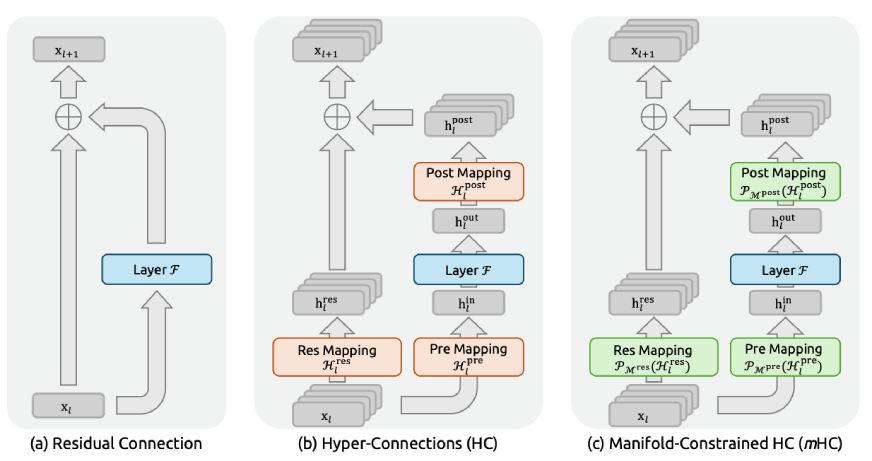
What Makes mHC Different?
DeepSeek’s strategy is not just smart, it is brilliant because it causes you to think “Oh, why has no one ever thought of this before?” They still kept Hyper-Connections but limited them with a precise mathematical method.
This is the technical part (don’t give up on me, it’ll be worth your while to understand): Standard residual connections allow what is known as “identity mapping” to be carried out. Picture it as the law of conservation of energy where signals are traveling through the network do so at the same power level. When HC increased the width of the residual stream and combined it with learnable connection patterns, they unintentionally violated this property.
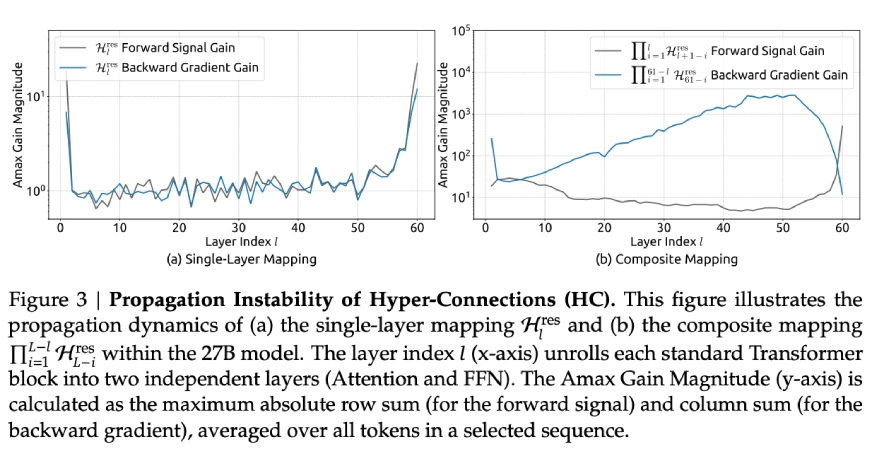
DeepSeek’s researchers comprehended that HC’s composite mappings, essentially, when you keep stacking these connections layer upon layer, were boosting signals by multipliers of 3000 times or even more. Picture it that you stage a dialog and every time someone communicates your message, the whole room at once yells it 3000 times louder. That’s nothing but chaos.
mHC solves the problem by projecting these connection matrices onto the Birkhoff polytope, an abstract geometric object in which each row and column has a sum equal to 1. It may appear theoretical, but in reality, it makes the network to treat signal propagation as a convex combination of features. No more explosions, no more signals disappearing completely.
The Architecture: How mHC Actually Works
Let’s explore the details of how DeepSeek changed the connections within the model. The design depends on three major mappings that determine the direction of the information:
The Three-Mapping System
In Hyper-Connections, three learnable matrices perform different tasks:
- H_pre: Takes the information from the extended residual stream into the layer
- H_post: Sends the output of the layer back to the stream
- H_res: Combines and refreshes the information in the stream itself
Visualize it as a freeways system where H_pre is the entrance ramp, H_post is the exit ramp, and H_res is the traffic flow manager among the lanes.
One of the findings of DeepSeek’s ablation studies is very interesting – H_res (the mapping applied to the residuals) is the main contributor to the performance increase. They turned it off, allowing only pre and post mappings, and performance dramatically dropped. This is logical: the highlight of the process is when features from different depths get to interact and swap information.
The Manifold Constraint
This is the point where mHC starts to deviate from regular HC. Rather than allowing H_res to be picked arbitrarily, they impose it to be doubly stochastic, which is a characteristic that every row and every column sums to 1.
What is the importance of this? There are three key reasons:
- Norms are kept intact: The spectral norm is kept within the limits of 1, thus gradients cannot explode.
- Closure under composition: Doubling up on doubly stochastic matrices results in another doubly stochastic matrix; hence, the whole network depth is still stable.
- An illustration in terms of geometry: The matrices are in the Birkhoff polytope, which is the convex hull of all permutation matrices. To put it differently, the network learns weighted combinations of routing patterns where information flows differently.
The Sinkhorn-Knopp algorithm is the one used for enforcing this constraint, which is an iterative method that keeps normalizing rows and columns alternately till the desired accuracy is reached. In the experiments, it was established that 20 iterations yield an apt approximation with no excessive computation.
Parameterization Details
The execution is smart. Instead of working on single feature vectors, mHC compresses the whole n×C hidden matrix into one vector. This allows for the complete context information to be used in the dynamic mapping’s computation.
The last constrained mappings apply:
- Sigmoid activation for H_pre and H_post (thus guaranteeing non-negativity)
- Sinkhorn-Knopp projection for H_res (thereby enforcing double stochasticity)
- Small initialization values (α = 0.01) for gating factors to begin with conservative
This configuration stops signal cancellation caused by interactions between positive-negative coefficients and at the same time keeps the very important identity mapping property.
Scaling Behavior: Does It Hold Up?
One of the most amazing things is how the benefits of mHC scale. DeepSeek conducted their experiments in three different dimensions:
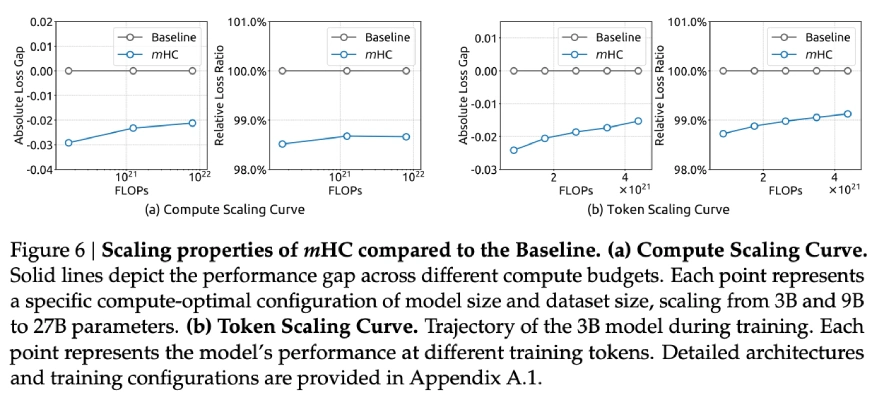
- Compute Scaling: They trained to 3B, 9B, and 27B parameters with proportional data. The performance advantage remained the same and even slightly increased at higher budgets for the compute. This is incredible because usually, many architectural tricks which work at small-scale do not work when scaling up.
- Token Scaling: They monitored the performance throughout the training of their 3B model trained on 1 trillion tokens. The loss improvement was stable from very early training to the convergence stage, indicating that mHC’s benefits are not limited to the early-training period.
- Propagation Analysis: Do you recall those 3000x signal amplification factors in vanilla HC? With mHC, the maximum gain magnitude was reduced to around 1.6 being three orders of magnitude more stable. Even after composing 60+ layers, the forward and backward signal gains remained well-controlled.
Performance Benchmarks
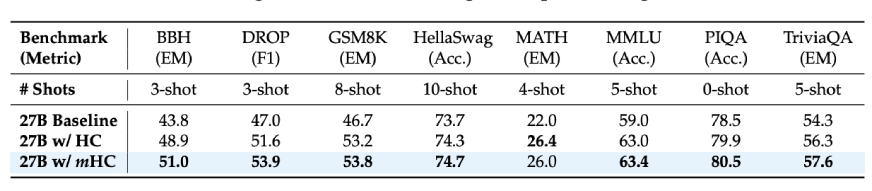
DeepSeek evaluated mHC on different models with parameter sizes varying from 3 billion to 27 billion and the stability gains were particularly visible:
- Training loss was smooth during the whole process with no sudden spikes
- Gradient norms were kept in the same range, in contrast to HC, which displayed wild behaviour
- The most significant thing was that the performance not only improved but also shown across several benchmarks
If we consider the results of the downstream tasks for the 27B model:
- BBH reasoning tasks: 51.0% (vs. 43.8% baseline)
- DROP reading comprehension: 53.9% (vs. 47.0% baseline)
- GSM8K math problems: 53.8% (vs. 46.7% baseline)
- MMLU knowledge: 63.4% (vs. 59.0% baseline)
These don’t represent minor improvements but in fact, we are talking about 7-10 point increases on difficult reasoning benchmarks. Additionally, these improvements were not only seen up to the larger models but also during longer training periods, which was the case with the scaling of the deep learning models.
Also Read: DeepSeek-V3.2-Exp: 50% Cheaper, 3x Faster, Maximum Value
Conclusion
If you are working on or training large language models, mHC is an aspect that you should definitely consider. It is one of those papers that rare, which identifies a real issue, presents a mathematically valid solution, and even proves that it works at a large scale.
The major revelations are:
- Increasing residual stream width leads to better performance; however, naive methods cause instability
- Limiting interactions to doubly stochastic matrices retain the identity mapping properties
- If done right, the overhead can be barely noticeable
- The advantages can be reapplied to models with a size of tens of billions of parameters
Moreover, mHC is a reminder that the architectural design is still a crucial factor. The issue of how to use more compute and data cannot last forever. There will be times when it is necessary to take a step back, comprehend the reason for the failure at the large scale, and fix it properly.
And to be honest, such research is what I like most. Not little changes to be made, but rather profound changes that will make the entire field a little more robust.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]






