This article was published as a part of the Data Science Blogathon.
Overview
- Here is a listing of the Top 10 Datasets for 2021 that we believe every data scientist should study.
- The article comprises ten open-source datasets for object detection in machine learning with hyperlinks.
- By no means is this listing exhaustive. Feel frank to add other datasets in the remarks section of the article.

Introduction
Understanding a model itself is less challenging than knowing where data scientists should implement it as its utilisation differs from dataset to dataset.
Therefore, we must follow the end-to-end Machine Learning method on distinctive kinds of data and datasets. The more diverse datasets we use to construct our models, the further we understand the design. This is additionally a magnificent way to continue questioning yourself and investigate some exciting information being collected globally!
One of the challenging subjects in computer vision, object detection, helps organisations understand and recognise real-time objects with the help of digital pictures as inputs. Here, we have posted the complete open-source datasets one can use for object detection projects.
I have also prepared some great resources as you learn and get more datasets to examine.
(The record is in no appropriate order)
CIFAR-10:
CIFAR-10 is a comprehensive dataset that consists of 60,000 colour images in 10 different categories. The dataset holds 10,000 test images and 50,000 training images split into five training groups.
Learn more about the dataset here. And here is a link to the Classification on CIFAR-10/100 and ImageNet with PyTorch.

LISA Traffic Sign Detection Dataset:
LISA or Laboratory for Intelligent & Safe Automobiles Traffic Sign Dataset is a set of annotated frames and videos that comprises US traffic signs. The dataset includes images collected from different cameras, 47 US sign types, and 7855 annotations on 6610 boundaries. LISA is published in two stages, i.e. one with photos and one with both videos and pictures.
Learn more about the dataset here. Here is a link for the LISA Traffic Sign Detection Code Discussion on Kaggle.

Open Images:
Open Image is a dataset of approximately 9 million pictures annotated with image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localised narratives.
The dataset includes 16 million bounding boxes for 600 object types on 1.9 million images, making it the most significant current dataset with object location annotations. The boxes have essentially been manually outlined by expert annotators to ensure efficiency and consistency.
Open Images also grants visual relationship annotations, indicating pairs of objects in relevant relations, object properties and human activities.
Learn more about the dataset here. A link to the repository contains the code, in Python scripts and Jupyter notebooks, for building a convolutional neural network machine learning classifier based on a custom subset of the Google Open Images dataset.

MS Coco:
MS COCO is a large-scale object detection dataset that approaches three core analysis problems in scene recognition. Detecting non-iconic scenes (or non-canonical perspectives) of objects, contextual reasoning within objects, and accurate 2D localisation of objects.
The dataset has specific characteristics, such as object segmentation, recognition in the circumstances, superpixel stuff segmentation, 1.5 million object instances, 80 object classes and more.
Learn more about the dataset here. Here is a link to the tutorial that will walk you through preparing this MS COCO for GluonCV.

Exclusively Dark (ExDark) Image Dataset:
The Exclusively Dark (ExDARK) is a unique low-light image dataset that presents a staple set of images for benchmarking low-light analysis works and bring mutually different fields of expertise to concentrate on low-light conditions, for example, image understanding, image enhancement, object detection, etc.
The dataset is a combination of 7,363 low-light photographs from very low-light conditions to twilight (i.e. ten different states) with 12 object categories (related to PASCAL VOC) annotated on both image classification level and the local target is bounding boxes.
Learn more about the dataset here. Here is a link to a project that implements a Faster R-CNN model using TensorFlow’s Object Detection API to identify objects in images taken from the ExDark dataset.

The 20BN-SOMETHING-SOMETHING Dataset V2:
The 20BN-SOMETHING-SOMETHING is a massive scale dataset. The dataset assembles labelled video clips that show individuals performing pre-defined basic movements with numerous objects. 20BN-SOMETHING-SOMETHING allows machine learning patterns to exhibit a granular knowledge of necessary actions in the day-to-day material world.
Learn more about the dataset here. Here is a link to the tutorial that will go through the steps of preparing this dataset for GluonCV.

ImageNet:
ImageNet is an image dataset classified according to the WordNet hierarchy. In this dataset, each link of the system is depicted by hundreds and thousands of pictures.
The dataset is produced from two fundamental needs in computer vision investigation. The first was the requirement to build a North Star difficulty in computer vision. Second, there was a significant need for more extra data to facilitate more generalisable machine learning techniques.
Learn more about the dataset here. And here is a link to the Classification on CIFAR-10/100 and ImageNet with PyTorch.

BDD100K:
BDD100K is a driving dataset for independent multitask learning. The dataset comprises ten tasks and 100K videos to estimate the progress of image recognition algorithms on autonomous driving.
The functions on this dataset include multi-object segmentation tracking, image tagging, road object detection, semantic segmentation, lane detection, drivable area segmentation, instance segmentation, multi-object detection tracking, domain adoption, and imitation training.
Learn more about the dataset here. Here is a link to attack the task by collecting Berkeley DeepDrive Video Dataset by proposing an FCN+LSTM model and implementing TensorFlow.

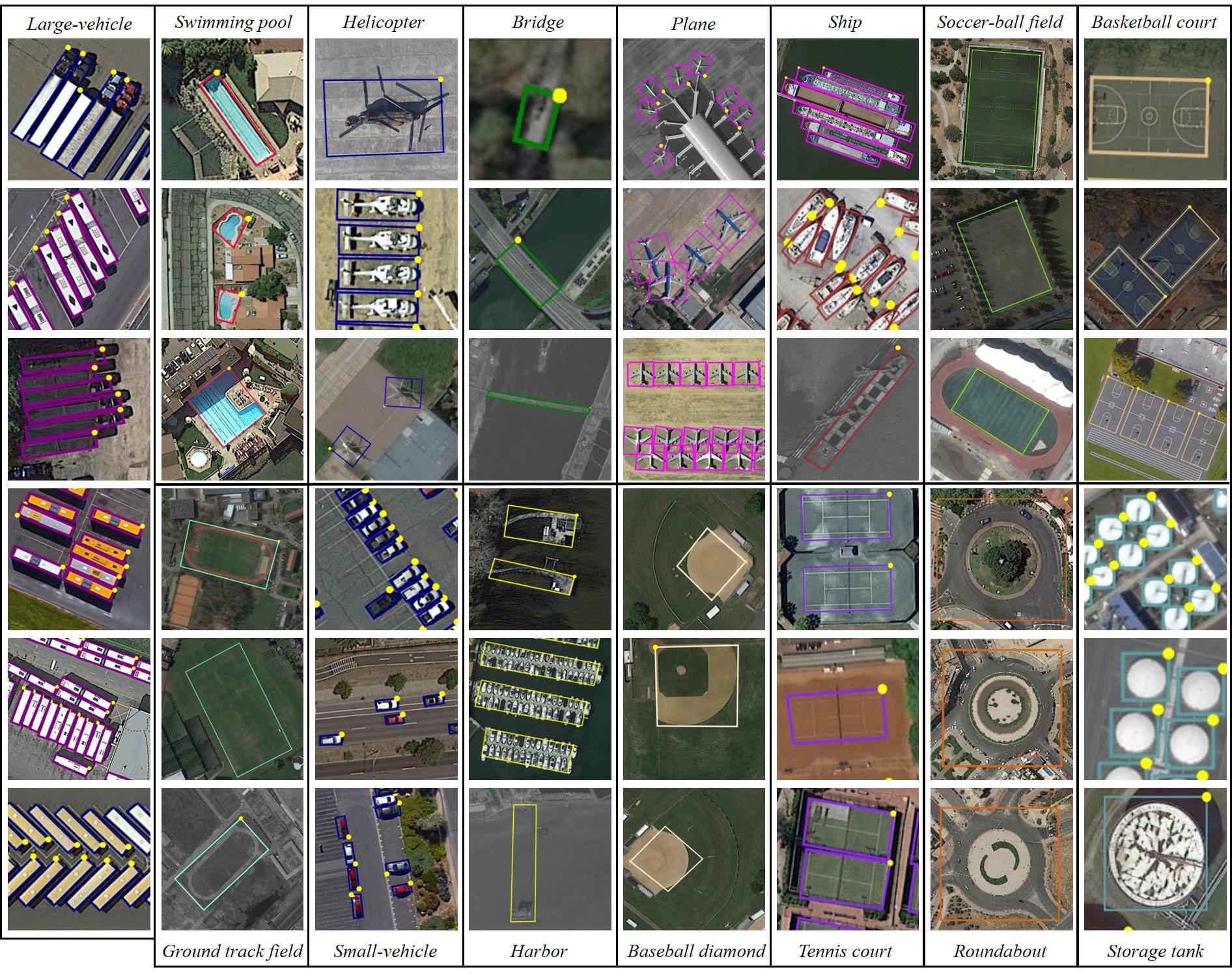
DOTA:
DOTA is a massive dataset for object detection in aerial visions. It can be practised to develop and estimate object detectors in aerial photos. The pictures are collected from various sensors and stages. Each print is of the dimension from 800 × 800 to 20,000 × 20,000 pixels and includes objects presenting a wide variety of scales, orientations, and patterns.
Specialists annotate DOTA illustrations in aerial image interpretation.
Learn more about the dataset here. Here is a link to the code library of models trained on DOTA.
MaskedFaceNet:
It is not unexpected that COVID-related data highlights in the Computer Vision class as well. For this goal, one of one standard helpful datasets that are promptly available is the MaskedFace-Net dataset.
This well-annotated dataset consists of almost 60K images, each of the people using masks correctly and incorrectly. Even the incorrectly masked faces are classified into types such as the exposed nose, chin, etc. This unique global source shows realistic faces and provides further classification on how the mask is being worn.
Learn more about the dataset here.

EndNotes
Today, we saw fascinating object-detection datasets of 2021 so far. Nevertheless, these datasets prove that researchers, data scientists beyond all domains, have presented efforts to assemble and maintain user data that would develop the analysis in AI for ages to proceed.
I inspire all of you to investigate these datasets and improve your data cleaning, feature engineering, and model-building skills. Each dataset describes its inclination of challenges. By training with them, we can get an impression of how datasets genuinely are in the business.
If there is any dataset that you got to know approximately in 2021? Do mention them below!
If you have any questions, you can reach out to me on my LinkedIn @mrinalwalia.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus


