This article was published as an entry for the Data Science Blogathon.
Introduction
Markov Chains are exceptionally useful in order to model a discrete-time, discrete space Stochastic Process of various domains like Finance (stock price movement), NLP Algorithms (Finite State Transducers, Hidden Markov Model for POS Tagging), or even in Engineering Physics (Brownian motion).
Considering the immense utility of this concept in various domains and its pivotal importance to a significant number of algorithms in data science, we shall cover in this article the following aspects of the Markov Chain :
- Markov Chain formulation and intuitive explanation
- Aspects & characteristics of a Markov Chain
- Application & Use cases
Table of contents
What is Markov Chain?
A Markov chain is a mathematical system that describes a sequence of events where the probability of transitioning from one state to another depends only on the current state, not on the sequence of events that preceded it. It’s a way to model random processes where the future states are determined solely by the present state, making it a memoryless process.
Markov Chain Formulation and intuitive explanation
In order to understand what a Markov Chain is, let’s first look at what a stochastic process is, as Markov chain is a special kind of a stochastic process.
A stochastic process is defined as a collection of random variables X={Xt:t∈T} defined on a common probability space, taking values in a common set S (the state space), and indexed by a set T, often either N or [0, ∞) and thought of as time (discrete or continuous respectively) (Oliver, 2009). It means that we have observations at a certain time and the outcome is a random variable. Simply put, a stochastic process is any process that describes the evolution in time of a random phenomenon.
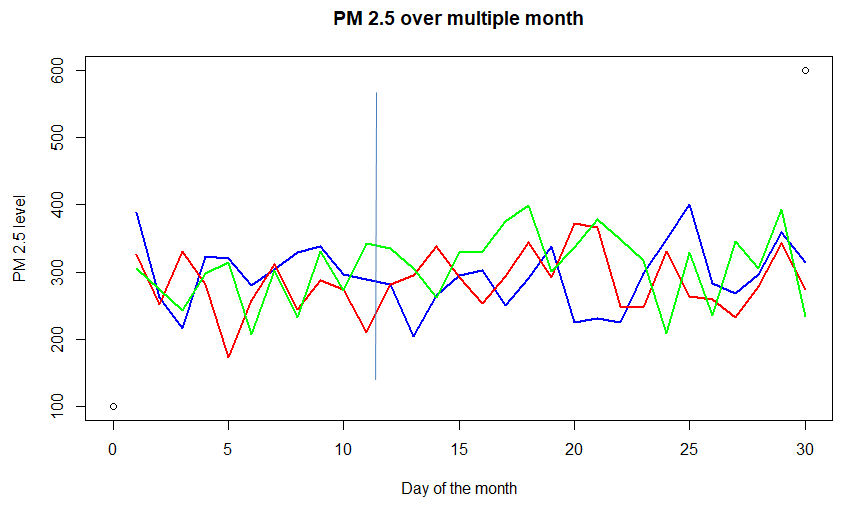
Consider the graph above of concentration of PM (particulate matter) 2.5 in the air over a city for different months. Each of the colored lines -red, blue, and green – (called sample-path) represents a random function of time. Also, consider any day (say 15th of every month), it represents a random variable. Thus it can be considered as a Stochastic process, i.e a process that takes different functional inputs at different times. This particular example is a case for discrete-time (as time is not continuous, observed once a day) with a continuous state (it can take any positive value, not necessarily an integer).
Mathemaical Concepts
Now that we have a basic intuition of a stochastic process, let’s get down to understand one of the most useful mathematical concepts for Data Science: Markov Chains!
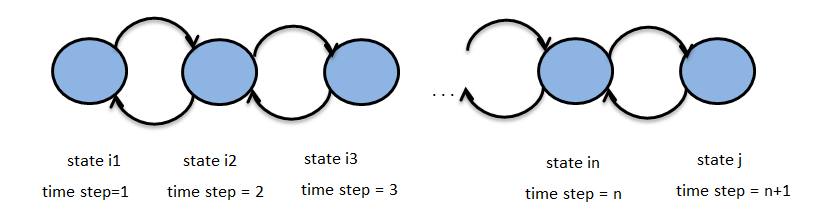
The above figure represents a Markov chain, with states i1, i2 ,… , in , j for time steps 1, 2, .., n+1. Let {Zn}n∈N be the above stochastic process with state space S. N here is the set of integers and represents the time set and Zn represents the state of the Markov chain at time n. Suppose we have the property :
P(Zn+1 = j | Zn = in , Zn-1 = in-1 , … , Z1 = i1) = P(Zn+1 = j | Zn = in)
then {Zn}n∈N is called a Markov Chain.
This term P(Zn+1 = j | Zn= in) is called transition probability. Thus we can intuitively see that in order to describe Markov Chain probabilistically, we need (a) the initial state distribution and (b) transition probabilities.
Let’s take the Markov Chain shown below to understand these two terms more formally,
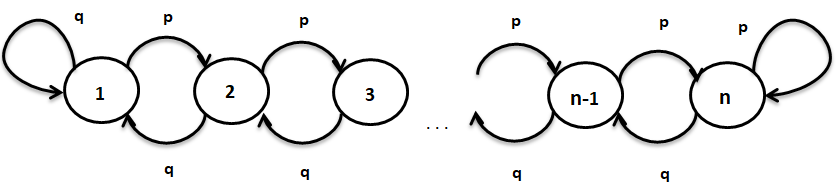
In the Markov chain above, states are 1, 2, …, n and the probability of going from any state k to k+1 (for k =1, 2, …, n-1) is p and going from state k to k-1 is q, where q = 1-p.
- The initial state distribution is defined as
π(0) = [P(X0=1), P(X0=2), … , P(X0 = n)]
The above expression is a row vector with element denoting the probability of the markov chain having the state i, where i = 1, 2, … , n. All the elements of this vector sum to 1 .
- The transition probability matrix is as shown below :
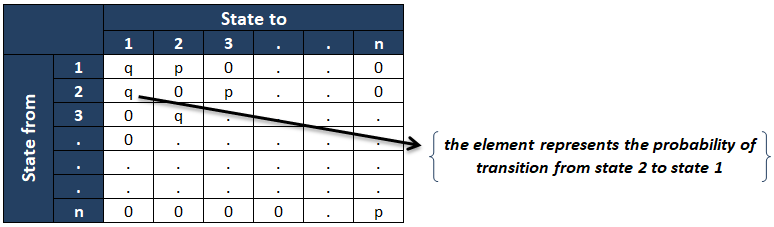
The ijth element of the transition probability matrix represents the conditional probability of the chain is in state j given that it was in state i at the previous instance of time. If the transition probability matrix doesn’t depend on “n” (time), then the chain is called the Homogeneous Markov Chain.
How to Represent Markov Chain?
To represent a Markov chain, you can think of it like a game where you move between different states. Here’s how you do it simply:
- Draw Pictures: Imagine you’re drawing pictures of different states. Each state could be a circle, and you connect them with arrows to show how you can move between states. These arrows represent the chances of going from one state to another.
- Use Numbers: Instead of writing out probabilities, you can use numbers to show how likely it is to move from one state to another. You might use a scale from 0 to 1, where 0 means it never happens, and one means it always happens.
- Keep it Simple: Try to make it simple enough. Stick to just a few states and simple transitions between them. This makes it easier to understand and work with.
Aspects and Characteristics of Markov Chain
In this section we will look at the following major aspects of a Markov Chain:
- First Hitting Time: gl(k)
- Mean Hitting Time (Absorption time): hA(k)
The purpose of the above two analyses is that if we have a set of desired states (say A), and we want to compute how long will it take to reach the desired state.
First Hitting Time
Imagine, if we want to know the (conditional) probability that our Markov Chain starting at some initial state k, would reach the state l (one of the many desired states in A) whenever it reaches any state in A. How would we do that?
Let’s understand by defining a few basic terms. Let TA be the earliest time it takes to reach any one of the states in the set A and k be some state in the state space but not in A.
Let gl(k) be defined as the conditional probability of reaching the state l in time TA starting from state k.
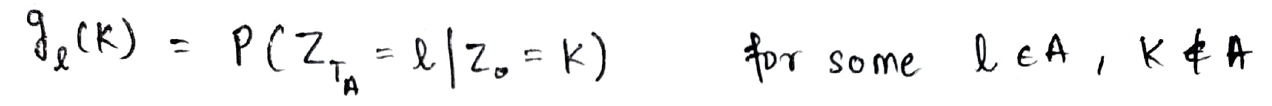
Now using the Markov property, let’s consider going from the state at time =0 to state at time = TA as going from the state at time = 0 to state at time = 1 and then going from state at time = 1 to state at time = TA. The same is represented below:
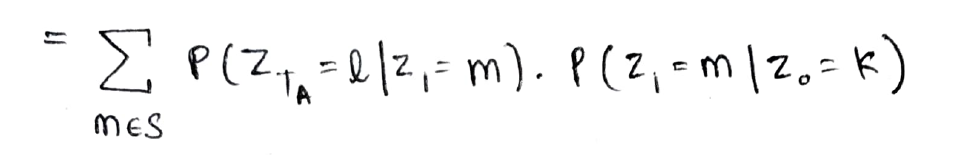
The above equation can be interpreted graphically as well as shown below, i.e in the first step it can go from state k to any one of the states m in one step and then go in TA-1 step from state m to the desired state l.
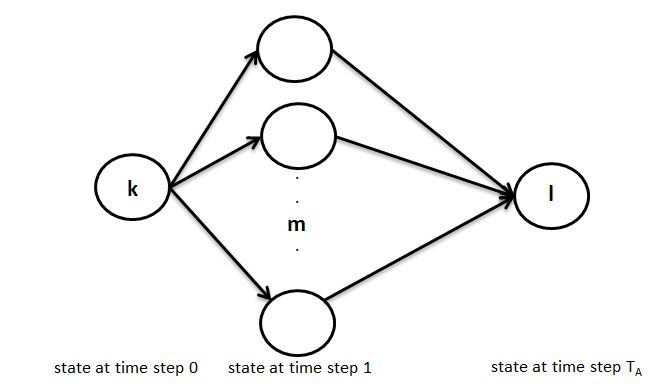
Now the first term can be represented as gl(m) and the second term represents the transition probability from state k to state m
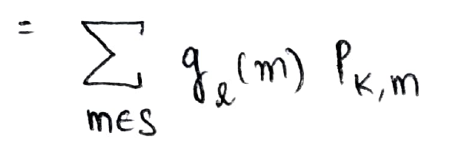
This is the recursive manner in which we compute the desired probability and the approach used above is called the First Step Analysis (as we analyzed it in terms of the first step that it takes from the state at time = 0 to state at time = 1)
Mean Hitting Time
Using a similar approach as above, we can also calculate the average (expected) time to hit a desired set of states (say A) starting from a state k outside A.
Let us define hA(k) as the expected time required to reach a set A starting from state k. This is defined as shown below:

Now, that we know what the First step analysis is, why not use it again?
So, we now write the expectation term in terms of the first step (i.e reach the state Z1) as shown below:
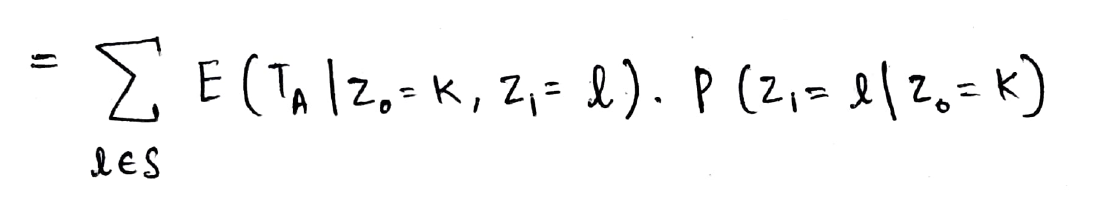
Now using the Markov property, we can drop the Z0 term as we know the state at Z1. The second term in the above product is the transition probability from state k to state l (we have seen this concept so much that it now feels like a 2+2=4 calculation 🙂 )
Note that the expectation term below is in terms of Z1 (and not Z0) and thus we can’t directly write it as hA(k). Thus we use a mathematical trick, add 1 in the expectation and subtract 1 as well so that we can mathematically write the state as Z0 = l
And now we can write it as hA(k).
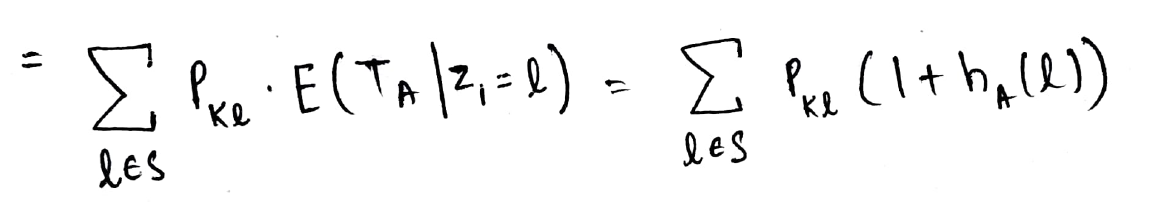
This is the recursive manner in which we compute the desired Expectation!
Now we know the fundamental approach to derive any Markov property with the two new tools that we now possess: Understanding of transition probability matrix and First Step Analysis approach.
Application & Use cases
Since we are now comfortable with the concept and the aspects of a Markov Chain, Let us explore and intuitively understand the following application and Use-cases of Markov Chains
- NLP: Hidden Markov Model for POS Tagging
- Random Walk as a Markov Chain
NLP: Hidden Markov Model for POS Tagging
Part of Speech (POS) Tagging is an important NLP application. The objective in such problems is to tag each word in a given sentence with an appropriate POS (noun, verb, adverb, etc.). In the model, we have tag transition probabilities, i.e. given that the tag of the previous word is said ti-1, the ti will be the tag of the current word. And the second concept of the model is the probability that given the tag of the current word is ti, the word will be wi. To state more clearly: Hidden Markov Model is a type of Generative (Joint) Models in which the hidden states (here POS tags) are considered to be given and observed data is considered to be generated.
The ti in the figure below refers to the POS tags of the state and wi refers to the words emitted by the states.
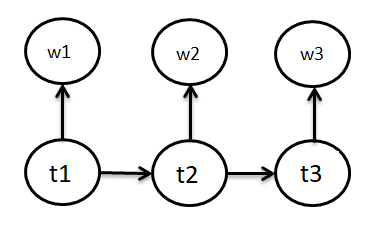
Now, let’s see the element of the model minutely to see the Markov process in it even more clearly. The elements of the Hidden Markov Model are:
- A set of states: here POS Tags
- The output from each state: here ‘word’
- Initial state: here beginning of the sentence
- State transition probability: here P(tn | tn-1)
Apart from being very useful in this aspect of NLP, Finite State Transducers and multiple other algorithms are based on Markov Chains.
Random Walk
Another interesting phenomenon is that of Random walk, which again is a Markov Chain.

Let’s consider the random walk, as shown above, i.e one-step forward movement from any state can happen with a probability p and one-step backward movement can happen with probability q. Here the forward movement from state k to k+1 depends only on the state k and therefore Random Walk is a Markov chain.
Now, let’s take a step forward and understand the Random Walk as a Markov Chain using simulation. Here we consider the case of the 1-dimensional walk, where the person can take forward or backward steps of any size (size>=1) with equal probability.
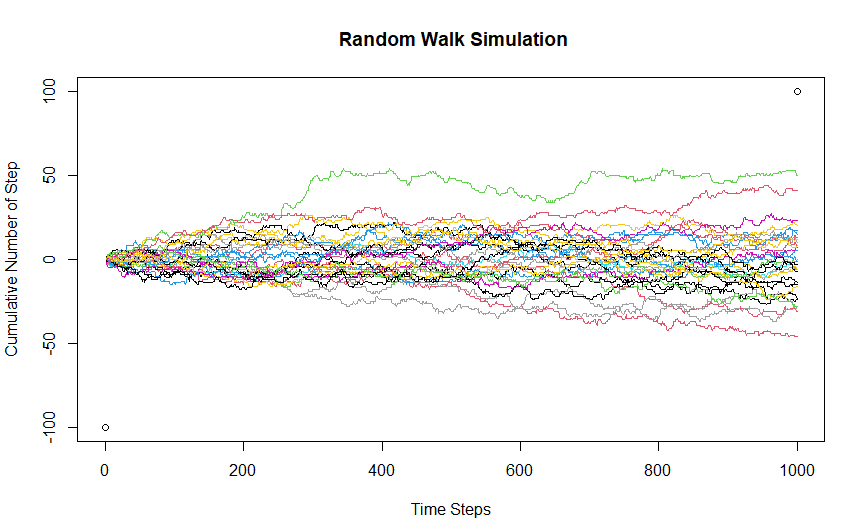
Random Walks of Markov Chain
Here, I have plotted 30 random walks to build intuition around the phenomenon. Here the initial state of the Markov Chain is 0 (zero cumulative steps initially). The things to note are:
- The state-space and the time set are both discrete (integer)
- It is visually clear that at any given time step, the next state is determined by the current state only and the time steps behind the current time step do not aid the prediction of where the state of the chain will be in the next time step.
- Since the forward movement probability is the same as backward movement, the expected value of the Cumulative number of steps is 0.
The code to simulate a basic random walk in R is given below:
plot(c(0,1000),c(-100,100), xlab = "Time Steps", ylab = "Cumulative Number of Step" , main = " Random Walk Simulation")
for (i in 1:30) {
x <- as.integer(rnorm(1000))
lines(cumsum(x), type = "l", col=sample(1:10,1))
}Markov Chain is a very powerful and effective technique to model a discrete-time and space stochastic process. The understanding of the above two applications along with the mathematical concept explained can be leveraged to understand any kind of Markov process.
Note about the author: I am a student of PGDBA (Postgraduate Diploma in Business Analytics) at IIM Calcutta, IIT Kharagpur & ISI Kolkata, and have completed my B.TECH from IIT DELHI and have work experience of ~3.5 years in Advanced Analytics.
Conclusion
Markov chains are probabilistic models where transitions between states depend solely on the current state. Represented by transition matrices or state diagrams, they model various systems and behaviors. Properties like first hitting time and mean hitting time help analyze their dynamics. Markov chains find applications in diverse fields, including NLP, like using Hidden Markov Models for POS tagging.
Frequently Asked Questions
Q1.What is Markov chain used for?
Markov chains are used for predicting future states based on current conditions. They find applications in predictive modeling, simulation, quality control, natural language processing (NLP), economics, genetics, and game theory. They help analyze complex systems and make informed decisions in diverse fields.
Q2.What are examples for Markov chains?
Examples of Markov chains include weather forecasting, board games, web page ranking, language modeling, and economics. They model processes where future events depend only on the current state, making them useful for prediction and analysis in various fields.
Q3.How are Markov chains used in real life?
Markov chains are used in real life for weather forecasting, finance, healthcare, natural language processing, genetics, manufacturing, and game theory. They help predict outcomes, analyze systems, and make informed decisions in various fields.
Q4.Where do we apply the Markov chain?
Identify the system to model.
Define states.
Determine transition probabilities.
Create a transition matrix.
Analyze properties and apply in real-life scenarios.
Feel free to reach out for any discussion on the topic on Parth Tyagi | LinkedIn or write a mail to me at [email protected]
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Very lucid and nicely written..
"Note that the expectation term below is in terms of Z1 (and not Z0) and thus we can’t directly write it as hA(k). Thus we use a mathematical trick, add 1 in the expectation and subtract 1 as well so that we can mathematically write the state as Z0 = l And now we can write it as hA(k)." Where is the Expectation Operator gone? The mathematical trick, how exactly does it allow substitution z1 z0?