Objective
- Parts of speech tagging and dependency parsing are widely used techniques in text processing.
- Understand parts of speech tags and grammars with their respective use cases in Natural language processing
Introduction
Natural language processing is a branch of machine learning that deals with how machines understand human languages. Text data is a widely available problem domain for NLP tasks.
In order to work with text data, it is important to transform the raw text into a form that can be understood and used by machine learning algorithms, this is called text preprocessing. We have various techniques for text preprocessing like stemming, lemmatization, POS tagging, and dependency parsing.
Note: If you are more interested in learning concepts in an Audio-Visual format, We have this entire article explained in the video below. If not, you may continue reading.
In this article, we are going to discuss the structure-related properties of text data. Here, we will be talking about the Parts of speech and dependency grammars that will lead us to understand how they work.
Parts Of Speech Tags
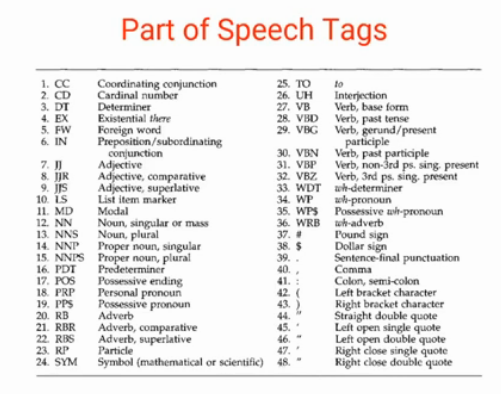
Parts of speech tags are the properties of the words, which define their main context, functions, and usage in a sentence. Some of the commonly used parts of speech tags are

Nouns: Which defines any object or entity
Verbs: That defines some action.
Adjectives and Adverbs: This acts as a modifier, quantifier, or intensifier in any sentence.
In a sentence, every word will be associated with a proper part of the speech tag. For example, consider the sentence below

In this sentence, every word is associated with a part of the speech tag which defines their functions. Here, David has an NNP tag which means it is a proper noun. Further, Has and purchased belong to the verb indicating that they are the actions. The Laptop and Apple store are the nouns. New is the adjective whose role is to modify the context of the laptop.
Parts of speech tags are defined by the relationship of words with the other words in the sentence.
We can apply machine learning models and rule-based models to obtain the parts of speech tags of a word. The most commonly used parts of speech tag notations are provided by the Penn Treebank corpus. In which, a total of 48 P.O.S tags are defined according to their usage.
Use cases of POS Tags
Parts of speech tags have a large number of applications and they are used in a variety of tasks such as
- Text Cleaning
- Feature Engineering tasks
- Word sense disambiguation
For example, consider these sentences

In both sentences, the keyword book is used, but in sentence one, it is used as a verb. While in sentence two it is used as a noun.
Constituency Grammar
Now let’s discuss grammar.
The first type of grammar is constituency grammar. Any word/ group of words/Phrase can be termed as constituents. The goal of constituency grammar is to organize any sentence into its constituents using their properties. These properties are generally driven by their parts of speech tags, noun or verb phrase identification.
For example, constituency grammar can define that any sentence can be organized into three constituents a subject, a context, or an object. These constituents can take different values and accordingly can generate different sentences.

Another way to look at constituency grammar is to define them in terms of their parts of speech tags say a grammar structure containing a <determiner, noun><adjective, verb> <preposition determiner noun>. This corresponds to the same sentence, The dogs are barking in the park.

Dependency Grammar
We also have a different type of grammar i.e dependency grammar, which states that ” The words of a sentence depends on the other words of the sentence.”
For example, in the last sentence, a barking dog was mentioned and the dog was modified by barking as the dependency adjective- modifier exists between the two.
Dependency grammar organizes the words of a sentence according to their dependency. One of the words in the sentence act as a root and all the other words are directly or indirectly linked to the root using their dependencies. These dependencies represent the relationship among the words in a sentence.
The dependency grammar is used to understand the structure and semantic dependencies between the words. Let’s consider an example.

The dependency tree of this sentence looks something like this.

In this tree the root word is “community”, having NN as the part of speech tag and every other word of this tree is connected to the root directly or indirectly with dependency relation such as direct object/ direct subject, modifiers, etc.
These relationships define their roles and functions of each word in the sentence and how multiple words are connected together. Here, every dependency can be represented in a form of a triplet which contains a relation, a Governor, and a dependent. This means that a dependent is connected to the governor by a relation. In other words, they are subject-verb or object.
As in the last example Analytics Vidhya is the subject or governor, the largest data science community is the dependent or the object.

Use cases Of Dependency Grammar
Dependency grammar have multiple use cases, for instance
- In Named Entity Recognition
- Question- Answering system
- In co-reference resolutions, where the task is to map the pronouns with the respective noun phrases.
- In-text summarization problems.
- Features for Text Classification problems
End Notes
To summarize, in this article we saw Parts of speech tags and two types of grammar i.e constituency grammar and dependency grammar. We also saw some of the examples and important use cases of them.
If you are looking to kick start your Data Science Journey and want every topic under one roof, your search stops here. Check out Analytics Vidhya’s Certified AI & ML BlackBelt Plus Program
If you have any queries let me know in the comment section!
Shipra is a Data Science enthusiast, Exploring Machine learning and Deep learning algorithms. She is also interested in Big data technologies. She believes learning is a continuous process so keep moving.




