This article was published as a part of the Data Science Blogathon
Introduction on NLP
Have you ever imagined how mails are classified into spam and ham or how the tweets are classified into good or bad?.. All these are happened because of the advancement in the field of NLP or Natural Language Processing. With the help of NLP several models are created for accomplishing many tasks like spam classifier mobile, chatbots, recommendation systems etc. NLP is now one of fastest growing field and several companies are invested in this for acquiring valuable insights.
In todays article we are going to discuss about the analysis and creation of a disaster tweet classification. After this article you will get familiar with the text preprocessing concepts and LSTM model creation.
So let’s understand dataset.
Dataset
The dataset we’re used here is Disaster tweet data. It contains 5 columns out of which we only concerned about “text” column that contains the tweet data and “target” column that show whether the given tweet is disaster or not. We need to perform some text preprocessing techniques tweet data for getting good results.
Implementation
First of all, let’s import all the required libraries for our project
import warnings
warnings.simplefilter(action='ignore', category=Warning)
import pandas as pd
import numpy as np
import re
import nltk
from nltk.corpus import stopwords
from tqdm import tqdm
import seaborn as sns
sns.set_style("darkgrid")
import matplotlib.pyplot as plt
%matplotlib inline
Now let’s import our disaster tweet dataset using pandas
data = pd.read_csv("train.csv")
We’re analyzing few rows and columns,
data.head()
Using seaborn, we’re plotting the count of disaster and non-disaster tweets.
sns.countplot(data["target"])
Calculating the normalized value counts
data["target"].value_counts(normalize = True) #normalized value counts
0 0.57034 1 0.42966 Name: target, dtype: float64
As an important step of data analysis we’re going to calculate the length of each tweets and creating a function for plotting an histogram based on the length data.
def length_plot(data, name): length = [len(sentence.split()) for sentence in data] plt.hist(length) plt.title(name) length_plot(data[data["target"]==0]["text"], "Not Disaster") length_plot(data[data["target"]==1]["text"], "Disaster")
Now let’s separate the dependent and independent features
X = data["text"] # indpendent feature y = data["target"] # dependent feature y = np.array(y) # converting to array
Calculating the number of unique words present in the disaster tweets.
def unq_words(sentence):
unq_words_list = []
for sent in tqdm(sentence):
for word in sent.split():
if word.lower() not in unq_words_list:
unq_words_list.append(word.lower())
else:
pass
return unq_words_list
unique_words = unq_words(X)
print("Total unique words present :",len(unique_words))
Total unique words present : 27983
Some of the words are
unique_words[:20]
Output
['our', 'deeds', 'are', 'the', 'reason', 'of', 'this', '#earthquake', 'may', 'allah', 'forgive', 'us', 'all', 'forest', 'fire', 'near', 'la', 'ronge', 'sask.', 'canada']
As you know that this is a twitter dataset, so it might contains several words starting with ‘#’ and ‘@’. So let’s find these words words starting with “#”
SYMBOL_1 = "#" sym1_words = [word for word in unique_words if word.startswith(SYMBOL_1)] len(sym1_words) #1965
Some of the words starting with “#” are
sym1_words[100:120]
['#az:', '#wildhorses', '#tantonationalforest!', '#saltriverwildhorses', '#sciencefiction', '#internetradio', '#collegeradix89û_', '#warmbodies', '#etcpb', '#storm', '#apocalypse', '#pbban', '#doublecups', '#armageddon', '#love', '#truelove', '#romance', '#voodoo', '#seduction', '#astrology']
words starting with “@”
SYMBOL_2 = "@" sym2_words = [word for word in unique_words if word.startswith(SYMBOL_2)] len(sym2_words) #2264
Some of the words starting with “@” are
sym2_words[100:120]
['@cloudy_goldrush', '@arsonistmusic', '@safyuan', '@local_arsonist', '@diamorfiend', '@casper_rmg', '@veronicadlcruz', '@58hif', '@pcaldicott7', '@_doofus_', '@slimebeast', '@bestcomedyvine', '@pfannebeckers', '@dattomm', '@etribune', '@acebreakingnews', '@darkreading', '@caixxum5sos', '@blazerfan', '@envw98']
While analyzing the words with “#” and “@” we can reach a conclusion that words starting with ‘@’ is completely useless it doesn’t give any impact on the accuracy of the model, so we want to remove it.
In the dataset there are several urls are present ,so let’s write a function to remove the urls present in it.
def url_remover(text):
url_patterns = re.compile(r'https?://S+|www.S+')
return url_patterns.sub(r'', text)
Now let’s start the actual preprocessing so we are writing a function for it.
from nltk.stem import WordNetLemmatizer
wl = WordNetLemmatizer()
def preprocessing(text):
tweets = []
for sentence in tqdm(text):
sentence = sentence.lower() # converting the words to lower case
sentence = url_remover(sentence) # removing the url from the sentence
sentence = re.sub(r'@w+', '', sentence).strip() # removing the words starts with "@"
sentence = re.sub("[^a-zA-Z0-9 ']", "", sentence) # removing symbols
sentence = sentence.split()
sentence1 = [wl.lemmatize(word) for word in sentence if word not in set(stopwords.words("english"))] #lemmatization and stopwrds removal from tweets
sentence1 = " ".join(sentence1)
tweets.append(sentence1)
return tweets
tweets = preprocessing(X)
As of now, we removed un necessary symbols stopwords and also lemmatized it. Before feeding into the model all these tweets needs to be converted into numerical features. So we need to perform onehot encoding. So before that we are importing tensorflow library and its parts
from tensorflow.keras.layers import (Embedding,
LSTM,
Dense,
Dropout,
GlobalMaxPool1D,
BatchNormalization)
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import one_hot
Now performing onehot encoding
VOC_SIZE = 30000 onehot_vector = [one_hot(words, VOC_SIZE) for words in tweets] onehot_vector[110:120]
.png)
Let’s find the word length each for each tweets.
word_length = [] for i in onehot_vectors: word_length.append(len(i))
len(word_length)#7613
Finding the maximum word length
max(word_length) #25
As you know that length of each words are of different size, this will cause while training the model, since model requires data of same size. So we are performing zero padding in order to make equal length sequences.
SENTENCE_LENGTH = 15 embedded_docs = pad_sequences(onehot_vectors, padding="post", maxlen=SENTENCE_LENGTH) embedded_docs
Next is the main important step, model creation step. The first layer is a word embedding layer followed LSTM model.
def model():
VECTOR_FEATURES = 32
lstm_model = Sequential()
lstm_model.add(Embedding(VOC_SIZE,
VECTOR_FEATURES,
input_length=SENTENCE_LENGTH))
lstm_model.add(LSTM(100, return_sequences = True))
lstm_model.add(GlobalMaxPool1D())
lstm_model.add(BatchNormalization())
lstm_model.add(Dropout(0.5))
lstm_model.add(Dense(10, activation="relu"))
lstm_model.add(Dropout(0.25))
lstm_model.add(Dense(1, activation = "sigmoid"))
return lstm_model
Creating the model and getting the model summary
lstm_model = model() lstm_model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"]) lstm_model.summary() #summary
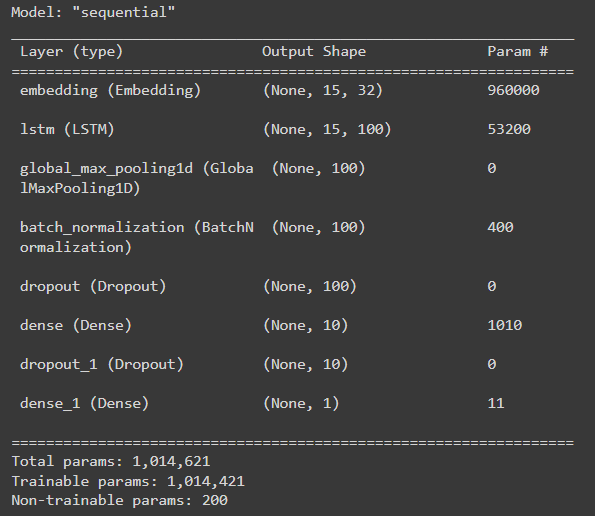
Training the model
history = lstm_model.fit(embedded_docs, y, epochs=8, batch_size=32)
.png)
Now let’s analyze our model by plotting the graph of model accuracy and loss
For accuracy
plt.plot(history.history["accuracy"])
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.title("Accuracy")
For Loss
plt.plot(history.history["loss"])
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss")
.png)
From the graph of Loss and Accuracy it is clear that, as the epochs proceeds loss reduces and accuracy increases more than 95%.
We can save our model as a pickle file for future use.
pickle.dump(lstm_model, open("model.pkl", "wb"))
We can load this saved pickle file using pickle for using in web apps.
Conclusion
In this article we are gone through the implementation of a disaster tweet classification. You may got the idea behind text preprocessing and LSTM model implementation. Also text analysis. The key takeaways from this article are.
Text analysis : Analyzing the text to find the sentence structure, symbols used in there, and length of sentences etc.
Text preprocessing: Analyzed text data is then subjected to done some preprocessing techniques like stopwords removal, lemmatization, symbols remover etc.
Model creation: created the LSTM model and passed the data through it after onehot encoding and wordembedding.
This is all about the text classification project. Hope you all understand the concepts taught here.
Try the same type questions with other datasets in order to get deep understanding.
Connect with me on LinkedIn.
Master Text Classification with LSTM—learn text preprocessing, build LSTM models, and get hands-on with text analysis!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Python Developer, ML Enthusiast, Blogger and an Electronics and Communication Engineering aspirant determined and motivated to finish tasks with atmost sincerity and dedication.I'am a good learner who ready to accept challenges to bring up my best even in the worst. Wish for a world with enough advancements and opportunities for the people.






