This article was published as a part of the Data Science Blogathon.

Source: Arxiv|Search Engine Journal
Introduction
As it is common knowledge that natural language processing is one of the most popular and competitive in the current global IT sector. All of the top organizations and budding startups are on the lookout for candidates with strong NLP-related skills.
Natural Language Processing (NLP) is the field at the intersection of Linguistics, Computer Science, and Artificial Intelligence. It is the technology that allows machines to understand, analyze, manipulate, and interpret human languages.
Given the demand, popularity, and wide usage of NLP in companies, startups, and academia to build new solutions, it is imperative to have a crystal clear understanding of NLP fundamentals to bag a position for yourself in the industry. So in this blog, I have compiled a list of eleven imperative questions on Classical NLP that you could use as a guide to get more familiar with the topic and also devise an effective answer to succeed in your next interview!
So, let’s begin!
Interview Questions on Classical NLP
Following are some of the questions with detailed answers on Classical NLP.
Question 1: What is Stemming?
Answer: Stemming is the process of reducing a word to its word stem, which often includes the removal of derivational affixes.
Many variations of words carry the same meaning, and with the help of stemming, the lookup table can be shortened, and the sentences can be normalized, which helps in Natural Language Processing (NLP) and Natural Language Understanding.

Figure 1: Examples of Stemming
Source: Analytics Vidhya
So, from the above example, we can see that the words “history” and historical have the same root, “history”; however, the output of stemming is “histori.” This is one example that highlights the stemming approach’s incapability. In the following questions, we will take a look at this in more detail.
Applications: Information Retrieval Systems like Search Engines, Indexing, Tagging systems, Sentiment Analysis, Spam Classification, Document Clustering, etc.
Question 2: Could you name two very prominent errors in Stemming?
Considering that Stemming relies on heuristics, hence it is far from perfect. The two most common errors in stemming are:
a) Over-stemming
b) Under-Stemming
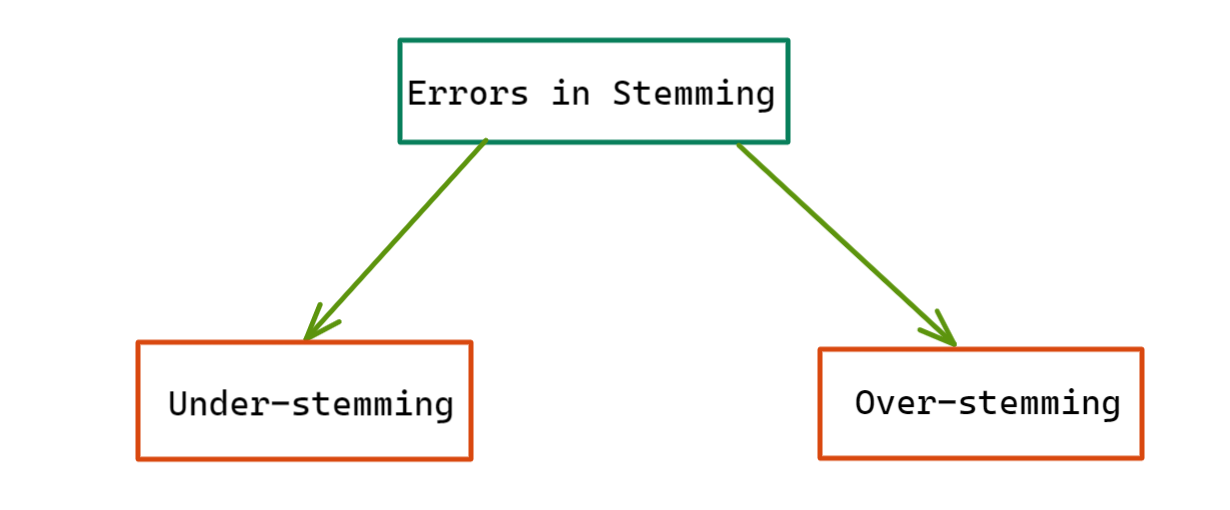
Figure 2: Types of Errors in Stemming
Source: Author)
Let’s take a look at these in more detail.
a) Overstemming: As the name itself suggests, in this, the word gets over-stemmed, i.e., too much of a word is chopped off that it results in nonsensical stems. As a result, the meaning of the word often gets completely lost or muddled. Alternatively, it can result in words being resolved to the same stem, which shouldn’t happen.
For example: Suppose we have four words universal, the universe, university, and universities. If a stemming algorithm chops off these words to the stem “univers”, it means that the algorithm has over-stemmed.
While the better approach would be to resolve the first two words to “univers” and the latter two words to “universi”. But implementing these rules can cause more issues.
b) Under-stemming: As the name itself suggests, under-stemming means we have “under-stemmed.” It happens when we have several words that are forms of one another.
For example: When we use a stemming algorithm that stems the word data and datum to “dat” and “datu”. Perhaps these can be resolved to “dat”. But then the question arises what would we do for the word “date”? Or are we merely enforcing a very specific rule for a very specific example?
When it comes to Stemming, these questions become burning issues. New rules and heuristics implementation can easily spiral out of control. The resolution of one or two over/under-stemming problems can lead to the emergence of new issues. It takes effort to create a good stemming algorithm.
Question 3: What are the Types of Stemmer in NLTK?
Answer: In this guide, we will be discussing the most used stemmers, which are: i) Porter Stemmer, ii) Snowball Stemmer, iii) Lancaster Stemmer, and iv) Regexp Stemmer.
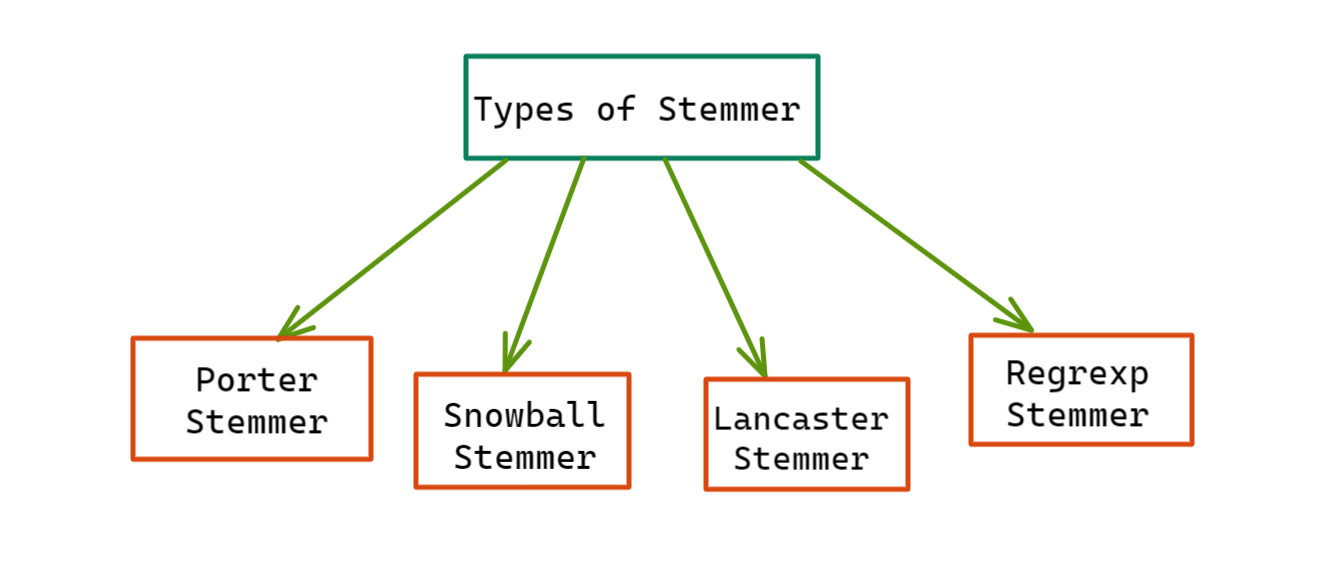
Figure 3: Types of Stemmers in NLTK
Source: Author
Now, let’s take a look at each of these in detail.
1. Porter Stemmer: Porter stemmer is based on the Porter Stemming Algorithm, which employs five steps of word reduction (a suffix-stemming approach), each with its own set of mapping rules to produce stems. This stemming algorithm is quite seasoned, as it is from the 1980s. It is quite renowned for its ease of use and rapidity.
Its goal is to eliminate the common word endings so that they can be resolved to a common form. Generally speaking, it’s a good stemmer for beginners, but it’s not really suggested to use it for any production or complex applications. Instead, it functions as a nice, straightforward stemming algorithm in research that helps ensure reproducibility. In comparison to other stemming algorithms, it is quite gentle.
NLTK has a PorterStemmer() module that implements the Porter Stemming algorithm. Let’s take a look at this with the help of an example:
Example:
#Importing the Porter Stemmer module from nltk.stem import PorterStemmer
#Instantiating porter_stemmer = PorterStemmer() #Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
for w in words: print(w + " -----> " + porter_stemmer.stem(w))
>> Output:
eating —–> eat
eats —–> eat
eatery —–> eateri
eateries —–> eateri
eaten —–> eaten
writing —–> write
writes —–> write
writer —–> writer
programming —–> program
programmer —–> programm
programs —–> program
programmed —–> program
congratulations —–> congratul
history —–> histori
historical —–> histor
2. Snowball Stemmer: Snowball Stemmer is also called Porter2 Stemmer or “English Stemmer.” It is an improved and better version of basic Porter Stemmer, which supports many languages (like Arabic, Danish, Finnish, French, German, Spanish, Swedish, etc.). Moreover, it is a little faster, more accurate, and more logical than the original version of Porter Stemmer. But in addition, it is a lot more aggressive than the original Porter Stemmer.
NLTK has a SnowballStemmer() module that implements the Snowball stemming approach. Let’s take a look at this with the help of an example.
Example:
#Importing the SnowballStemmer module from nltk.stem import SnowballStemmer
#Instantiating
snowball_stemmer = SnowballStemmer("english", ignore_stopwords = False)
#Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
for w in words: print(w + " -----> " + snowball_stemmer.stem(w))
>> Output:
eating —–> eat
eats —–> eat
eatery —–> eateri
eateries —–> eateri
eaten —–> eaten
writing —–> write
writes —–> write
writer —–> writer
programming —–> program
programmer —–> programm
programs —–> program
programmed —–> program
congratulations —–> congratul
history —–> histori
historical —–> histor
3. Lancaster Stemmer: Compared to other stemming algorithms, Lancaster Stemmer employs an aggressive approach as it implements over-stemming for many words. In this, a word is chopped off to the shortest stem possible, which can be non-linguistic and meaningless stems too. However, we can easily add our own custom rules to this algorithm. Regardless, while using this, we need to make sure that it does what it’s aimed for before this option is selected.
NLTK also has LancasterStemmer() module that implements Lancaster stemming approach. Let’s take a look at this with the help of an example.
Example:
#Importing the LancasterStemmer module from nltk.stem import LancasterStemmer
#Instantiating lancaster_stemmer = LancasterStemmer()
#Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
for w in words: print(w + " -----> " + lancaster_stemmer.stem(w))
> Output:
eating —–> eat
eats —–> eat
eatery —–> eatery
eateries —–> eatery
eaten —–> eat
writing —–> writ
writes —–> writ
writer —–> writ
programming —–> program
programmer —–> program
programs —–> program
programmed —–> program
congratulations —–> congrat
history —–> hist
historical —–> hist
As we can see from the outputs, Lancaster does employ an aggressive lemmatization approach!
4. Regexp Stemmer: Regex stemmer uses regular expressions to identify morphological affixes. In this, the sub-strings which match certain regular expressions are discarded.
NLTK has RegexpStemmer() module for implementing the Regrx stemming approach. Let’s understand this with the help of the following example:
#Importing the RegexpStemmer module from nltk.stem import RegexpStemmer
#Instantiating
regexp_stemmer = RegexpStemmer("ing$|s$|es$|able$|e$|cal$|ing$|$ing", min=8)
#Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
for w in words: print(w + " -----> " + regexp_stemmer.stem(w))
>> Output:
eating —–> eat
eats —–> eats
eatery —–> eatery
eateries —–> eateri
eaten —–> eaten
writing —–> writ
writes —–> writ
writer —–> writer
programming —–> programm
programmer —–> programmer
programs —–> program
programmed —–> programmed
congratulations —–> congratulation
history —–> history
historical —–> histori
Question 4: What is Lemmatization?
Answer: Lemmatization is the process of reducing a word to its word root (lemma) with the use of vocabulary and morphological analysis of words, which has correct spellings and is usually more meaningful. To reduce a word to its lemma, the lemmatization algorithm needs to know its part of speech (POS). This, in turn, calls for more computational linguistics power, like a part of a speech tagger.
For lemmatization to resolve a word to its lemma, it needs to know its part of speech. That needs extra computational and is usually more meaningful. When working with English, we can quickly use lemmatization. However, for the lemmatizer to reduce all of the words to the desired lemmas, you must feed it with the part of speech tags. Moreover, since it is based on the WordNet database (which works a bit like a web of synonyms or a thesaurus), if there isn’t a strong link there, we won’t get the correct lemma anyway.

Figure 4: Examples of Lemmatization
Source: blog.bitext.com
Application: Information Retrieval, Chatbots, Question Answering, Sentiment Analysis, Document Clustering, etc.
Question 5: What is the word lemmatization?
Answer: NLTK has WordNetLemmatizer class which is a wrapper around wordnet corpus. This class uses morphy() function in the WordNet CorpusReader class to find a lemma. Now, let’s look at an example to understand more about this class.
Example 1: When the pos tag is not explicitly defined.
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')
#Importing the WordNetLemmatizer module from nltk.stem import WordNetLemmatizer
#Instantiating lemmatizer = WordNetLemmatizer()
#Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
Output:
eating —–> eating
eats —–> eats
eatery —–> eatery
eateries —–> eatery
eaten —–> eaten
writing —–> writing
writes —–> writes
writer —–> writer
programming —–> programming
programmer —–> programmer
programs —–> program
programmed —–> programmed
congratulations —–> congratulation
history —–> history
historical —–> historical
Example 2: When the pos tag is explicitly defined!
import nltk
nltk.download(‘wordnet’)
nltk.download(‘omw-1.4’)
#Importing the WordNetLemmatizer module from nltk.stem import WordNetLemmatizer
#Instantiating lemmatizer = WordNetLemmatizer()
#Example_words words = ["eating", "eats", "eatery", "eateries", "eaten", "writing", "writes", "writer", "programming", "programmer", "programs", "programmed", "congratulations", "history", "historical"]
Notice in the following piece of code, we will be explicitly defining the pos tag as “v” (verb, just for demonstration).
> Output:
eating —–> eat
eats —–> eat
eatery —–> eatery
eateries —–> eateries
eaten —–> eat
writing —–> write
writes —–> write
writer —–> writer
programming —–> program
programmer —–> programmer
programs —–> program
programmed —–> program
congratulations —–> congratulations
history —–> history
historical —–> historical
From the above output, we can notice that this lemmatizer worked nicely for verbs since we had defined the POS tag as a verb, which suggests that if we apply lemmatization on certain groups at a time, it can be a very effective method as compared to stemming!
Question 6: Differentiate between Stemming and Lemmatization.
Answer:
| Stemming | Lemmatization | |
| Stemming is the process of reducing a word to its word stem, which often includes the removal of derivational affixes, often leading to incorrect meanings and spellings. | Lemmatization is the process of reducing a word to its word root, which has correct spellings and is more meaningful. | |
| Stemming commonly collapses derivationally related words. And a stem may or may not be an actual word. | Lemmatization commonly only collapses the different inflectional forms of a lemma. And a lemma is an actual language word. | |
| Rule-baed Approach: Stemmers employ language-specific rules and need less knowledge than Lemmatizer. Moreover, certain domains might also need special/domain-specific rules. |
|
|
| When language is important while developing a language application, stemming is usually not preferred. | While developing a language-specific application, Lemmatization is favored as it scans a corpus to match root forms. However, in comparison to stemming, it’s difficult to create a lemmatizer for a new language as it needs a lot more knowledge about the structure of a language. | |
| When speed is a concern, then Stemming is preferred as it chops off words without understanding the context. | When speed is important, then Lemmatization is usually not preferred since it scans the entire corpus, which takes time. | |
| It is less accurate. | It is more accurate than Stemming. | |
| It is computationally less expensive. That’s why it can be chosen for large datasets if budget is a concern. | It is computationally more expensive as it involves a look-up table and also scans the entire corpus. | |
| Example: When confronted with the token “caring,” it might just output “car,” which is incorrect. | Example: When it is confronted with the word “caring,” lemmatization might just output “care,” which is correct. |
![Stemming [Porter Stemmer] Vs. Lemmatization [WordNet Lemmatizer]](https://editor.analyticsvidhya.com/uploads/21509hh.PNG)
Figure 5: Stemming [Porter Stemmer] Vs. Lemmatization [WordNet Lemmatizer]
Source: baeldung.com
Question 7: What are Token and Tokenization?
Answer: Tokenization is breaking up a phrase, sentence, paragraph, or one or multiple text docs into smaller units.
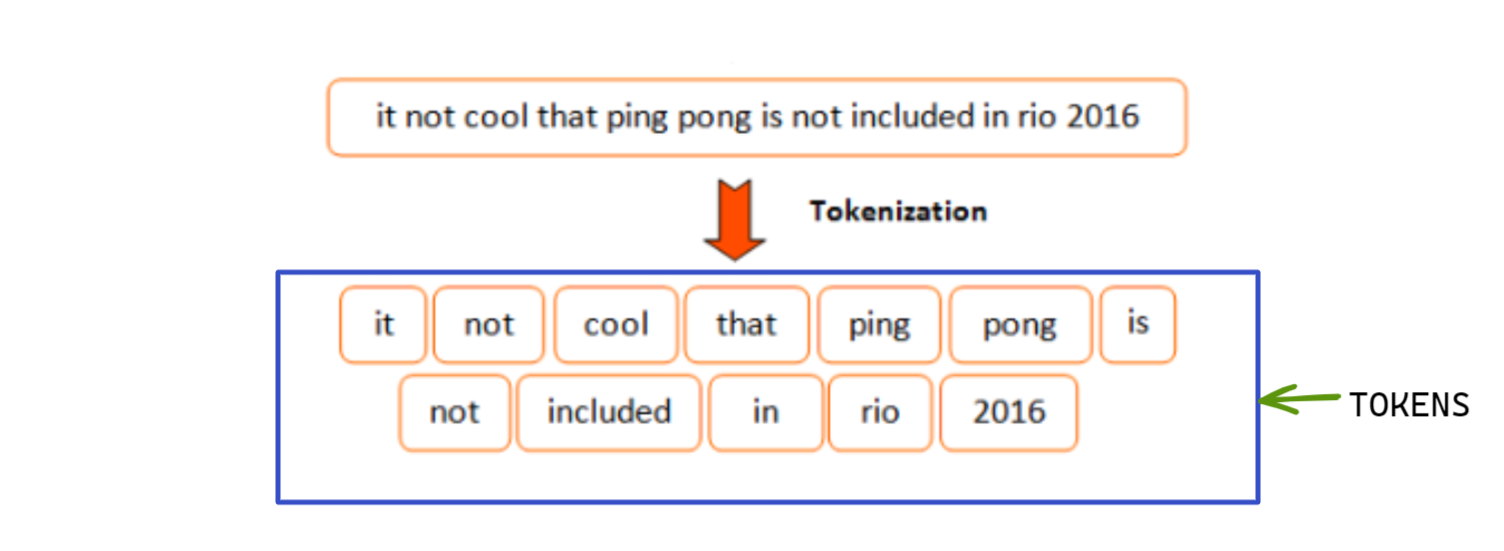
Figure 6: Diagram illustrating tokens and tokenization; for simplicity, word tokenization has been shown here
Source: Analytics Vidhya
Each of the small units is termed a token. These tokens could be anything, i.e., a character, word, sub-word, sentence, etc. Different algorithms use different types of tokenization. The following examples will give you a general sense of different types of tokenizers.
Take a look at the following sentence:
Sentence: "We are learning about Tokenization."
1) Word-based Tokenization: In this, the sentence is split into words based on a delimiter. The most common delimiter is space.
Word-based Tokenizer Output: [“We”, “are”, “learning”, "about", “Tokenization.”]
2) Subword-based Tokenizer: In this, the sentence is split into subwords.
Subword-based Tokenizer Output: [“We”, “are”, “learning,” "about," "Token," "ization."]
3) Character-based Tokenization: In this, the sentence is split into characters.
Character-based Tokenizer Output: ["W", "e", "a", "r", "e", "l", "e", "a", "r", "n", "i", "n", "g", "a", "b", "o", "u", "t", "T", "o", "k", "e", "n", "i", "z", "a", "t", "i", "o", "n", "."]
4) Sentence-based Tokenization: In this, the text is split into individual sentences.
example_text = “India is a country in South Asia. It is the seventh-largest country by area.”
Sentence-based Tokenizer Output: ["India is a country in South Asia.", "It is the seventh-largest country by area."]
Tokens are the foundation of NLP, as all NLP models process raw text at the token level. These tokens form the vocabulary, which is a collection of unique tokens in a corpus/dataset. Then this vocabulary is converted into numbers (IDs), which facilitates modeling.
Question 8: What is White Space Tokenizer? What are its advantages and disadvantages?
Answer: The whitespace tokenizer splits the text/sentence/paragraph whenever the whitespace delimiter is encountered.
It can be implemented using a string’s .split() method since the default separator in split() is whitespace.
example_sentence = "Catch the Sun before it's gone."' print(example_sentence.split())
>> Output: [‘Catch’, ‘the’, ‘Sun’, ‘before’, “it’s”, ‘gone.’]
Disadvantages of Whitespace Tokenizer: As we can see from the above example, the whitespace tokenizer produces tokens with punctuation. Moreover, it splits even those expressions that need to be considered collectively. e.g., compound geographic locations (“Andhra Pradesh”, “Uttar Pradesh”), language-specific expressions (“por favor”), collocations (fast food), etc. [Refer to the following examples for reference]
geo_location = "Andhra Pradesh" print(geo_location.split())
>> Output: [‘Andhra’, ‘Pradesh’]
expression = "por favor" print(expression.split())
>> Output: [‘por’, ‘favor’]
collocation = "fast food" print(collocation.split())
>> Output: [‘fast’, ‘food’]
Advantages of Whitespace Tokenizer: It is the simplest and fastest tokenization approach. It preserves hyphens (e.g., sign-in) and apostrophes (e.g., can’t). Let’s solidify this with the help of the following examples:
example2 = "sign-in" print(example2.split())
>> Output: [‘sign-in’]
example3 = "can't" print(example3.split())
>> Output: [“can’t”]
Hence, the whitespace tokenizer preserves the hyphens and apostrophes.
Question 9: What is the specialty of the WhitespaceTokenizer()? Could you produce an example for the same?
Answer: Using the WhitespaceTokenizer() offered by the nltk we can extract the tokens from a string of words or sentences without whitespaces, new lines, and tabs.
Example:
# importing WhitespaceTokenizer() from nltk from nltk.tokenize import WhitespaceTokenizer # Creating a variable for Class WhitespaceTokenizer tk = WhitespaceTokenizer() # Example example_case = "This pizza nist good." # Tokenizing output = tk.tokenize(example_case) #Output print(output)
>> Output: [‘This’, ‘pizza’, ‘is’, ‘good.’]
Question 10: What is NLTK’s word_tokenize()? How would you use it for tokenization?
Answer: The Natural Language Tool Kit provides a tokenizer called word_tokenize() that splits the text into words.
It leverages regular expression to a) split standard English contractions, b) treat most of the punctuation as separate tokens, c) splits quotes and single commas when they are followed by whitespace, and d) separate periods (punctuation) that come at the end of a line (EoL).
Let’s take a look at the following example to have a better understanding:
import nltk
nltk.download("punkt")
word_data = "I can't do without the Sun."
nltk_word_tokens = nltk.word_tokenize(word_data)
print(nltk_word_tokens)
>> Output: [‘I’, ‘ca’, “n’t”, ‘do’, ‘without’, ‘the’, ‘Sun’, ‘.’]
Question 11: What is NLTK’s sent_tokenize()? How would you use it for tokenization?
Answer: The Natural Language Tool Kit has a tokenizer called sent_tokenize() that splits the text (paragraph/doc, etc.) into sentences. Following is an example of the same:
import nltk
nltk.download("punkt")
example_sentence = "Sunny mornings are my favorite in winter. The golden Sun makes me happy."
sent_nltk_tokens = nltk.sent_tokenize(example_sentence)
print(sent_nltk_tokens)
>> Output: [‘Sunny mornings are my favorite in winter.’, ‘The golden Sun makes me happy.’]
Conclusion
This article covers some of the most imperative interview-winning questions on Classical NLP that could be asked in data science interviews. Using these interview questions, you can improve your understanding of the different concepts of NLP and formulate effective answers and present them to the interviewer.
To sum it up, some of the key takeaways from Classical NLP interview questions are:
1. Stemming is the process of reducing a word to its word stem, which often includes the removal of derivational affixes.
2. Considering that Stemming relies on heuristics; hence it is far from perfect. The two most common errors in stemming are a) Over-stemming and b) Under-Stemming.
3. Most commonly used stemmers are i) Porter Stemmer, ii) Snowball Stemmer, iii) Lancaster Stemmer, and iv) Regexp Stemmer. Lancaster is the most aggressive stemmer, meaning over-stemming is quite prominent in this one.
4. Stemming and Lemmatization can be used for Information Retrieval Systems like Search Engines, Indexing, Tagging systems, Sentiment Analysis, Spam Classification, Document Clustering, etc.
5. Tokenization is breaking up a phrase, sentence, paragraph, or one or multiple text docs into smaller units. Each of these units is termed a token. These tokens could be anything, i.e., a character, word, sub-word, sentence, etc.
6. The whitespace tokenizer splits the text/sentence/paragraph whenever the whitespace delimiter is encountered.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





