Introduction
When it comes to data preparation using Python, the term which comes to our mind is Pandas. No, not the one whom you see happily munching away on bamboo and lazily somersaulting.
Well, a library for prepping up the data for further analysis. Be it finding out which columns need to be removed or which features are to be created from the existing features. Pandas help us with all these questions. Everything and anything which requires your data to be prepped up for future analyzing steps, Pandas comes up as a handy tool.

All of the functions we’ll discuss now fall under the data preprocessing step. The preprocessing step is an essential step, be it from the view of data preprocessing or the building of a machine learning model over the data. It helps clean, transform and prepare the data for further analysis. In many cases, the raw(un-processed) data might be incomplete and have some errors, which is well addressed when data preprocessing is done.
Here, in this article, we’ll quickly see some of the basic Pandas functions, which are not much used but can be very useful and convenient, especially if you’re a newbie or noob 😛
Let’s dive in!
Learning Objectives
- Understanding some rarely used python data analysis functions.
- Illustrating how to use these pandas functions effectively with examples of real world-scenarios and understanding it better with code snippets.
- To show the benefits of these pandas functions and how they help in data preprocessing and analysis.
- Hands-on examples and code snippets for the readers to practice and implement.
Table of Contents
- Ffill and Bfill Function
- Shift Function
- Select_Dtypes Function
- Clip Function
- Query Function
- Melt Function
- Where Function
- Iat Function
- Conclusion
Ffill and Bbfill Function
There are many instances where data in certain places don’t get captured, resulting in missing values. We need to treat the missing values so that it doesn’t lead to incorrect results in the long run when building a machine learning model on the same data. So, we would substitute the missing values which is called Missing Value Imputation. There are many ways to impute the missing values, but we’ll be discussing the functions ffill(forward fill) and bfill(backward fill). Let’s quickly see them. But what’s the basis on which we are imputing the values? In general, it’s a good idea to use forward fill (ffill) or backward fill (bfill) when the data has a temporal ordering and you want to propagate the last known value forward or backward in time, respectively, to fill in missing values.
Important to Note:
Missing Values Imputation using ffill() and bfill() is useful when the data has a temporal ordering, or if there is a trend or pattern which we wish to maintain. If our data is not of the above type, then it may be more appropriate to use the mean, median, or mode values to fill in missing values. Still, this might cause the loss of some information. It’s also important to note that, in any case, the choice of imputation method will depend on the specific characteristics of the dataset, so it’s often best to try different methods and see which one gives the best results.
The ffill method example,
We have the following dataframe. And we want to fill in the missing values.
Here, we’ll be taking an example of a time series dataset and imputing the missing values with the ffill function. If we observe carefully, we can see an increasing trend in the dataset. Let’s have a quick look at the dataset.

We’ll be imputing the following missing values using the forward fill function.

After applying the following code, the values will get imputed in such a way that the previous value to the missing value would get forwarded.
df1 = df1.ffill(axis=0) df1
After applying the code, we get the following output. If we observe carefully, then we can see that only one observation has not been replaced. Why? Because we don’t have a value preceding the first observation.

Notice how the value in the 4th row, 2nd column has a value that it has copied from its previous cell. Forward cells are filled with the value of its previous observation.
Although there are many ways to impute this particular value(0th row, 1st column), here we’ll be using the bfill method to impute this value.
Let’s take the same dataset and perform the bfill function.
df1 = df1.bfill(axis=0) df1

Observe the above output, where the missing values are imputed with the value following it. The value in the 1st observation(0th row) and 2nd column has been imputed with the value of the 2nd observation(1st row) and 2nd column and the same has happened in the following rows.
The ffill (forward fill) and bfill (backward fill) functions are commonly used in real-life scenarios for data pre-processing and handling missing values. Some use cases are:
- Financial Data Analysis: Financial data often contain missing values due to various reasons, such as stock market holidays or delayed data releases. bfill can be used to backward-fill missing values with the next available value.
- Climate Data Analysis: Climate data often contains missing values, such as when a weather station is not functioning or data is lost. ffill and bfill can be used to fill missing values with the nearest available data, allowing for continuous analysis.
- Energy Consumption Data Analysis: Energy consumption data can contain missing values due to meter reading errors or equipment failure. Both ffill and bfill can be used to fill in missing values in energy consumption data, allowing for accurate analysis of energy consumption patterns.
Shift Function
This pandas function shifts the element to a desired location as per the desired number of periods we enter as a parameter. This function can work on both columns and also on rows.
Let’s see an example, where we can see the working of the shift function. Let’s say we have a weather dataset, and we wish to create new columns which contain the weather measurements from the previous day. We have the following weather data with us.

And now, we wish to create a new feature, such as the previous day’s temperature. These kinds of features would, in turn, be helpful as input features for the machine learning model to predict future weather.
So in order to fill the new features with values, we would shift the original features such as the temperature column by one 1 day.
df[‘prev_day_temp’] = df[‘temperature’].shift(1) # we’ll remove the first row as it has a null value df = df.dropna() df

Some real-life scenarios where we use the shift function are as follows.
- Seasonality Analysis: The shift function can be used in seasonality analysis to shift data by one seasonal cycle. This allows for the comparison of data across different seasons and can be useful for identifying seasonal trends and patterns.
- Time-series Data Analysis: In time-series data, the shift function can be used to shift data by a specified number of periods, allowing for data to be compared across different time frames. This can be useful for analyzing trends and patterns in data.
- Data Alignment: The shift function can be used to align data from different sources, such as data collected at different times or locations. This can be useful for ensuring that data is comparable and suitable for analysis.
Select_Dtypes Function
This function includes or excludes columns of specific datatypes. Let’s take the example of the students’ health dataset, which contains information(name, age, class roll no) about the college students and their bmi.

Now, let’s include only integer datatypes from our dataset.
We run the following code:
df.select_dtypes(include='int')

Let’s exclude the object(string) datatype from our dataset.
df.select_dtypes(exclude='object')

A few examples where we can get to see the use of the select_dtypes function are as follows:
- A dataframe containing information about employees in a company, with columns like “employee_name”, “hire_date”, “salary”, and “department”. You want to analyze the salary data, so you use select_dtypes to filter the dataframe and select only the “salary” column, which is of float data type.
- A dataframe containing customer reviews for different products, with columns like “reviewer_name”, “review_date”, “star_rating”, and “review_text”. You want to analyze the star rating data, so you use select_dtypes to select only the “star_rating” column, which is of int data type.
- A large dataframe containing information about various customers and their purchases. The dataframe has columns like “customer_name”, “purchase_date”, “purchase_amount”, and “product_category”. You want to analyze only the numerical columns, like “purchase_amount”, to understand spending patterns.
Clip Function
In this pandas function, we trim the values when it reaches a certain level. This pandas function applies lower and upper bounds as parameters to have the required set of observations. Suppose we only want those observations whose range lies between 20.0 to 50.0. The highlighted values in the red box would be trimmed from the given range.
We’ll be running the following code.

sub_data.clip(20.0, 50.0)
If we look at the output, we can see that all the values in the Weight column are greater than 50.0, which is the upper bound. Hence, all the values are replaced by the upper bound limit.

A few examples of the clip function, where we can see its real-life usage.
- A dataframe containing employee salaries, with a column “salary”. The company has a policy of capping the maximum salary at a certain value. You can use the clip function to set all salaries above the cap to the cap value.
- A dataframe containing energy consumption data for different households, with a column “energy_consumption”. You want to clip the values below a certain minimum to 0, to represent that the minimum amount of energy used in a household is 0.
- A dataframe containing stock prices for different companies, with a column “stock_price”. You want to clip the stock prices so that any value above a certain threshold is set to the threshold value. You can use the clip function to achieve this.
Query Function
As the name suggests, the query method helps in querying the dataset. This method takes a query expression as a string parameter which evaluates either True or False. The return type of this pandas function is a Dataframe. A dataframe is returned if the results turn out to be true depending on the given query expression.
Let’s take an example of a dataset and understand how this works. So, we have a dataset where we have details about customers visiting a hotel, their total_bill, tip_given, and time of ordering(lunch or dinner). I have used the tips.csv file over here. You can download the same from this link.
import pandas as pd
df = pd.read_csv('tips.csv')
df.head(10)
Let’s say I only want to view those observations which have details of female customers who have ordered Lunch or Dinner and have sizes more than or equal to 2.

We can use the query function to get those observations.
food_time = ['Lunch','Dinner'] # the query result should include both dinner and lunch
sub_df = df.query('sex=="Female" & size>=2 & time==@food_time') # Using @ would take the variable
sub_df.tail(10)

Here are some real-life examples to better understand the usage of the query function.
- A dataframe containing information about different countries, with columns like “country_name”, “population”, “area”, and “continent”. You want to analyze the data for countries with a population greater than 100 million. Based on this condition, you can use the query function to filter the dataframe.
- A dataframe containing information about different sports teams, with columns like “team_name”, “sport”, “wins”, and “losses”. You want to analyze the data for teams with a win-loss ratio greater than 0.5. You can use the query function to filter the dataframe based on this condition.
- A dataframe containing information about different movies, with columns like “movie_title”, “release_date”, “rating”, and “genres”. You want to analyze the data for movies with a rating greater than 8.0. You can use the query function to filter the dataframe based on this condition.
Melt Function
To put it more easily, in this pandas function, the dataset is changed from being broader to being taller. The columns are transposed into rows. Let’s understand this with an example. We have the following dataset, where students’ marks(in percentage) in their two semesters have been given.
So, we will use the melt function.

df_mark=df_mark.melt(id_vars='Name', var_name='Sem_Month', value_name = 'Percentage') # id_vars - the column's name to be used as identifier variables. # var_name - the name to be used for the 'variable' column # value_name - the name to be used for the values under the previous columns df_mark
The above output seems a bit different than what we had expected. Just observe the Sem_Month column. Let’s just sort the values based on the Name and Sem_Month columns.

df_mark = df_mark.sort_values(['Name','Sem_Month']) df_mark
We’ll just reset the index of our dataset to make it look better.

df_mark.reset_index(drop=True)

Real-life examples where we use the melt function.
- A dataframe containing exam scores for different students in different subjects, with columns like “Math”, “Science”, “English”, and so on. You want to analyze the exam scores, but the current format makes it difficult to do so. You can use the melt function to reshape the dataframe into a “long” format, with columns for “subject” and “score”, making it easier to perform analysis.
- A dataframe containing the number of apples and bananas sold at a fruit stand, with columns like “Apples Sold” and “Bananas Sold”. You want to analyze the sales data, but the current format makes it difficult to do so. You can use the melt function to reshape the dataframe into a “long” format, with columns for “fruit” and “sold”, making it easier to perform analysis.
- A dataframe containing the number of books read by different people, with columns like “Person A”, “Person B”, “Person C”, and so on. You want to analyze the book reading data, but the current format makes it difficult to do so. You can use the melt function to reshape the dataframe into a “long” format, with columns for “person” and “books_read”, making it easier to perform analysis.
Where Function
This function comes in handy when we wish to replace certain values in our dataframe. This checks one or more conditions and returns the result accordingly. In the following example, we have certain values as ‘Select,’ and we wish to replace them with the NaN values.

df_sub=df.where(cond=(df!='Select'), other='NaN') #keep the dataframe values as it is, if not equal to ‘Select’, otherwise replace it with ‘NaN’ df_sub
So what exactly is happening in the above code? We use the cond parameter to filter the dataframe or series based on a given boolean condition. Here, the condition is that replace the ‘Select’ string values with ‘NaN’ values, and if there’s anything other than the ‘Select’ value, then keep it as it is. For example, in the 2nd row, BMI column, the condition is true (20 is not equal to ‘Select’), this value won’t be replaced.
Note that, by default, even if we don’t specify the value to be replaced with, then it would replace it by NaN itself. Otherwise, if we want to replace the existing value with some value as per our needs, then that needs to be mentioned in the other parameter.
Once the above code is run, we get the following output. Notice how the values which were ‘Select’ earlier have been replaced with ‘NaN’ values.

A few real-life scenarios where the Pandas function can be used are as follows:
- A DataFrame with customer data, and you want to replace all customers ages less than 18 with the value “minor”.
- A dataframe having employee data. You want to highlight all employees who have been with the company for less than two years in red.
- Analyzing sales data and want to identify all sales that are below the average sale amount.
Iat Function
Last but not least, let’s just quickly discuss the iat function. So let’s say that in the above Pandas function we replaced all occurrences of Select with NaN. But now, let’s say we wish to replace a particular occurrence of Select with some different value. So, here, comes the need for the iat
function.Let’s understand this with the same dataset.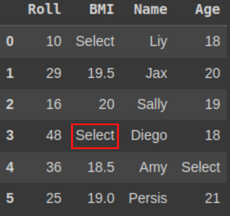 We’ll replace only a single occurrence(marked by the red box) of the Select value with NaN in the above dataset.
We’ll replace only a single occurrence(marked by the red box) of the Select value with NaN in the above dataset.
We’ll run the following code.
df.iat[3, 1] = ‘NaN’ # replacing the 3rd row, 1st column value by NaN df
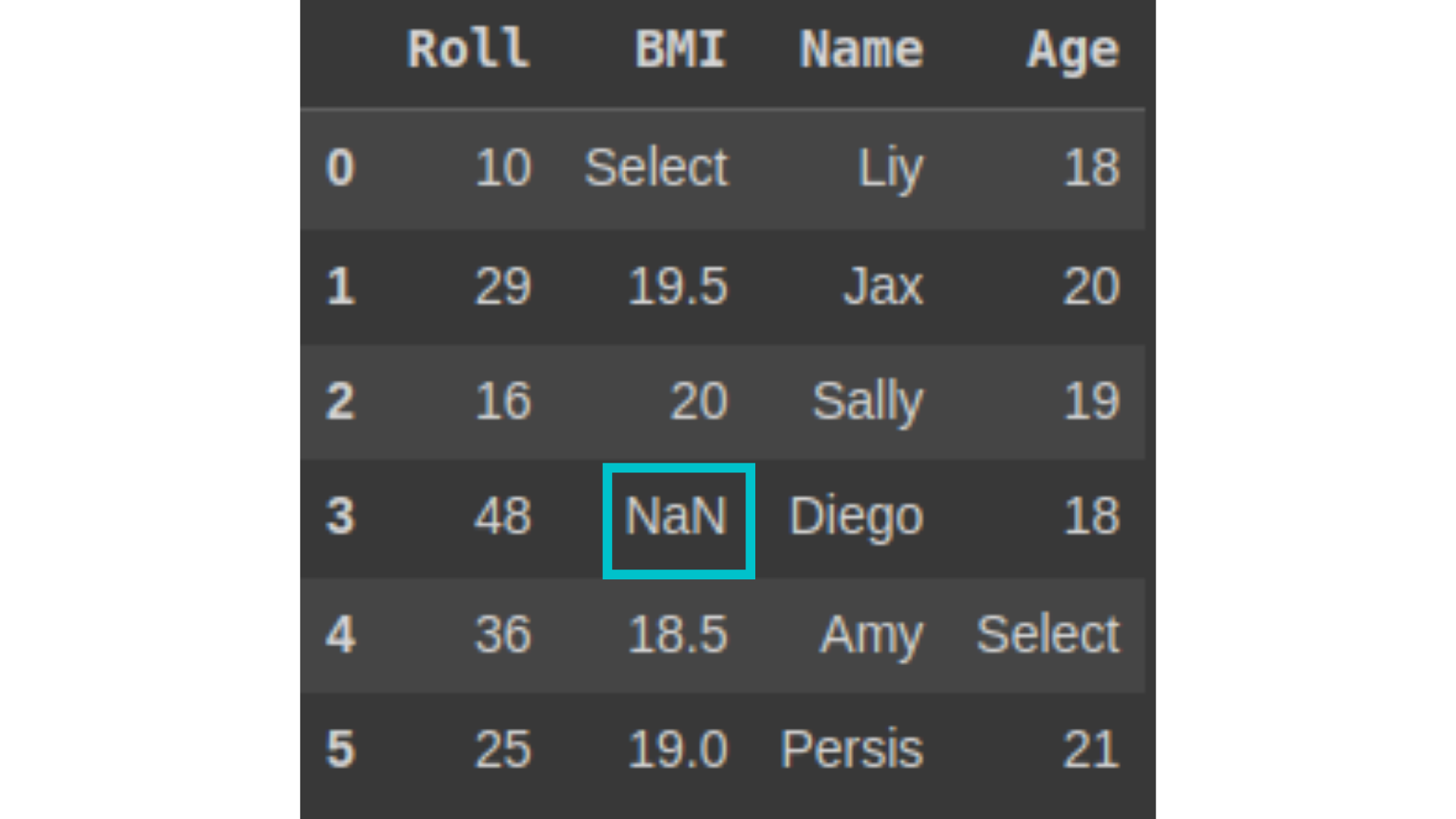
The iat function is specific to the Pandas library in Python and is used to access a scalar value in a DataFrame or Series.
Conclusion
In this article, we learned about some of the Pandas functions used while working with Pandas to make our work easier and more efficient. These functions are some which save a lot of our time. These functions might not be as widely used as compared to other functions, but they should also be known to anyone, be it even a beginner.
- Recap of key takeaways: So in this article, we learned about the importance of preprocessing. How is it important to prepare the data for further analysis? There might be various other functions that might help preprocess the data, but the functions discussed are some that are not known much but can be very useful.
- Usefulness: The data on which we work is obtained from real-world scenarios, hence would contain missing values and would be dirty in most cases. Working with unprocessed or dirty data might bring inaccurate results, which can be dangerous in the long run when decisions are made based on that. Hence, preprocessing is important.
- We understood the functions with code snippets, which would better our understanding and be very useful to someone starting off in their data analysis journey.






