Introduction
This article will look at a computer vision technique of Image Semantic Segmentation. Although this sounds complex, we’re going to break it down step by step, and we’ll introduce an exciting concept of image semantic segmentation, which is an implementation using dense prediction transformers or DPTs for short from the Hugging Face collections. Using DPTs introduces a new phase of computer vision with unusual capabilities.
Learning Objectives
- Comparison of DPTs vs. Conventional understanding of distant connections.
- Implementing semantic segmentation via depth prediction with DPT in Python.
- Explore DPT designs, understanding their unique traits.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Image Semantic Segmentation?
Imagine having an image and wanting to label every pixel in it according to what it represents. That’s the idea behind image semantic segmentation. It could be used in computer vision, distinguishing a car from a tree or separating parts of an image; this is all about smartly labeling pixels. However, the real challenge lies in making sense of the context and relationships between objects. Let us compare this with the, allow me to say, the old approach to handling images.
Convolutional Neural Networks (CNNs)
The first breakthrough was to use Convolutional Neural Networks to tackle tasks involving images. However, CNNs have limits, especially in capturing long-range connections in images. Imagine if you’re trying to understand how different elements in an image interact with each other across long distances — that’s where traditional CNNs struggle. This is where we celebrate DPT. These models, rooted in the powerful transformer architecture, exhibit capabilities in capturing associations. We will see DPTs next.
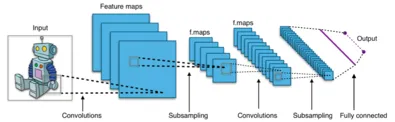
What are Dense Prediction Transformers (DPTs)?
To understand this concept, imagine combining the power of Transformers which we used to know in NLP tasks with image analysis. That’s the concept behind Dense Prediction Transformers. They are like super detectives of the image world. They have the ability to not only label pixels in images but predict the depth of each pixel — which kind of provides information on how far away each object is from the image. We will see this below.
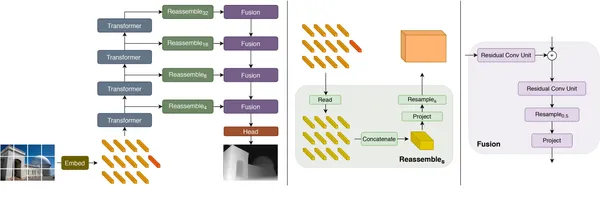
DPT Architecture’s Toolbox
DPTs come in different types, each with its “encoder” and “decoder” layers. Let’s look at two popular ones here:
- DPT-Swin-Transformer: Think of a mega transformer with 10 encoder layers and 5 decoder layers. It’s great at understanding relationships between elements at levels in the image.
- DPT-ResNet: This one’s like a clever detective with 18 encoder layers and 5 decoder layers. It excels at spotting connections between faraway objects while keeping the image’s spatial structure intact.
Key Features
Here’s a closer look at how DPTs work using some key features:
- Hierarchical Feature Extraction: Just like traditional Convolutional Neural Networks (CNNs), DPTs extracts features from the input image. However, they follow a hierarchical approach where the image is divided into different levels of detail. It is this hierarchy that helps to capture both local and global context, allowing the model to understand relationships between objects at different scales.
- Self-Attention Mechanism: This is the backbone of DPTs inspired by the original Transformer architecture enabling the model to capture long-range dependencies within the image and learn complex relationships between pixels. Each pixel considers the information from all other pixels, giving the model a holistic understanding of the image.
Python Demonstration of Image Semantic Segmentation using DPTs
We will see an implementation of DPTs below. First, let’s set up our environment by installing libraries not preinstalled on Colab. You can find the code for this here or at https://github.com/inuwamobarak/semantic-segmentation
First, we install and set up our environment.
!pip install -q git+https://github.com/huggingface/transformers.gitNext, we prepare the model we intend to train on.
## Define model
# Import the DPTForSemanticSegmentation from the Transformers library
from transformers import DPTForSemanticSegmentation
# Create the DPTForSemanticSegmentation model and load the pre-trained weights
# The "Intel/dpt-large-ade" model is a large-scale model trained on the ADE20K dataset
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")Now we load and prepare an image we would like to use for the segmentation.
# Import the Image class from the PIL (Python Imaging Library) module
from PIL import Image
import requests
# URL of the image to be downloaded
url = 'https://img.freepik.com/free-photo/happy-lady-hugging-her-white-friendly-dog-while-walking-park_171337-19281.jpg?w=740&t=st=1689214254~exp=1689214854~hmac=a8de6eb251268aec16ed61da3f0ffb02a6137935a571a4a0eabfc959536b03dd'
# The `stream=True` parameter ensures that the response is not immediately downloaded, but is kept in memory
response = requests.get(url, stream=True)
# Create the Image class
image = Image.open(response.raw)
# Display image
image
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
# Set the desired height and width for the input image
net_h = net_w = 480
# Define a series of image transformations
transform = Compose([
# Resize the image
Resize((net_h, net_w)),
# Convert the image to a PyTorch tensor
ToTensor(),
# Normalize the image
Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])The next step from here will be to apply some transformation to the image.
# Transform input image
pixel_values = transform(image)
pixel_values = pixel_values.unsqueeze(0)Next is we forward pass.
import torch
# Disable gradient computation
with torch.no_grad():
# Perform a forward pass through the model
outputs = model(pixel_values)
# Obtain the logits (raw predictions) from the output
logits = outputs.logitsNow, we print out the image as bunch of array. We will convert this next to the image with the semantic prediction.
import torch
# Interpolate the logits to the original image size
prediction = torch.nn.functional.interpolate(
logits,
size=image.size[::-1], # Reverse the size of the original image (width, height)
mode="bicubic",
align_corners=False
)
# Convert logits to class predictions
prediction = torch.argmax(prediction, dim=1) + 1
# Squeeze the prediction tensor to remove dimensions
prediction = prediction.squeeze()
# Move the prediction tensor to the CPU and convert it to a numpy array
prediction = prediction.cpu().numpy()We carry out the semantic prediction now.
from PIL import Image
# Convert the prediction array to an image
predicted_seg = Image.fromarray(prediction.squeeze().astype('uint8'))
# Apply the color map to the predicted segmentation image
predicted_seg.putpalette(adepallete)
# Blend the original image and the predicted segmentation image
out = Image.blend(image, predicted_seg.convert("RGB"), alpha=0.5)
There we have our image with the semantics being predicted. You could experiment with your own images. Now let us see some evaluation that has been applied to DPTs.
Performance Evaluations on DPTs
DPTs have been tested in a variety of research work and papers and have been used on different image playgrounds like Cityscapes, PASCAL VOC, and ADE20K datasets and they perform well than traditional CNN models. Links to this dataset and research paper will be in the link section below.
On Cityscapes, DPT-Swin-Transformer scored a 79.1% on a mean intersection over union (mIoU) metric. On PASCAL VOC, DPT-ResNet achieved a mIoU of 82.8% a new benchmark. These scores are a testament to DPTs’ ability to understand images in depth.
The Future of DPTs and What Lies Ahead
DPTs are a new era in image understanding. Research in DPTs is changing how we see and interact with images and bring new possibilities. In a nutshell, Image Semantic Segmentation with DPTs is a breakthrough that’s changing the way we decode images, and will definitely do more in the future. From pixel labels to understanding depth, DPTs are what’s possible in the world of computer vision. Let us take a deeper look.
Accurate Depth Estimation
One of the most significant contributions of DPTs is predicting depth information from images. This advancement has applications such as 3D scene reconstruction, augmented reality, and object manipulation. This will provide a crucial understanding of the spatial arrangement of objects within a scene.
Simultaneous Semantic Segmentation and Depth Prediction
DPTs can provide both semantic segmentation and depth prediction in a unified framework. This allows a holistic understanding of images, enabling applications for both semantic information and depth knowledge. For instance, in autonomous driving, this combination is vital for safe navigation.
Reducing Data Collection Efforts
DPTs have the potential to alleviate the need for extensive manual labelling of depth data. Training images with accompanying depth maps can learn to predict depth without requiring pixel-wise depth annotations. This significantly reduces the cost and effort associated with data collection.
Scene Understanding
They enable machines to understand their environment in three dimensions which is crucial for robots to navigate and interact effectively. In industries such as manufacturing and logistics, DPTs can facilitate automation by enabling robots to manipulate objects with a deeper understanding of spatial relationships.
Dense Prediction Transformers are reshaping the field of computer vision by providing accurate depth information alongside a semantic understanding of images. However, addressing challenges related to fine-grained depth estimation, generalisation, uncertainty estimation, bias mitigation, and real-time optimization will be vital to fully realise the transformative impact of DPTs in the future.
Conclusion
Image Semantic Segmentation using Dense Prediction Transformers is a journey that blends pixel labelling with spatial insight. The marriage of DPTs with image semantic segmentation opens an exciting avenue in computer vision research. This article has sought to unravel the underlying intricacies of DPTs, from their architecture to their performance prowess and promising potential to reshape the future of semantic segmentation in computer vision.
Key Takeaways
- DPTs go beyond pixels to understand the spatial context and predict depths.
- DPTs outperform traditional image recognition capturing distance and 3D insights.
- DPTs redefine perceiving images, enabling a deeper understanding of objects and relationships.
Frequently Asked Questions
Q1: Can DPTs be applied beyond images to other forms of data?
A1: While DPTs are primarily designed for image analysis, their underlying principles can inspire adaptations for other forms of data. The idea of capturing context and relationships through transformers has potential applications in domains.
Q2: How do DPTs influence the future of augmented reality?
A2: DPTs hold the potential in augmented reality via more accurate object ordering and interaction in virtual environments.
Q3: How does DPT differ from traditional image recognition methods?
A3: Traditional image recognition methods, like CNNs, focus on labelling objects in images without fully grasping their context or spatial layout but DPTs models take this further by both identifying objects and predicting their depths.
Q4: What are the practical applications of Image Semantic Segmentation using DPTs?
A4: The applications are extensive. They can enhance autonomous driving by helping cars understand and navigate complex environments. They can progress medical imaging through accurate and detailed analysis. Beyond that, DPTs have the potential to improve object recognition in robotics, improve scene understanding in photography, and even aid in augmented reality experiences.
Q5: Are there different types of DPT architectures?
A5: Yes, there are different types of DPT architectures. Two prominent examples include the DPT-Swin-Transformer and the DPT-ResNet where the DPT-Swin-Transformer has a hierarchical attention mechanism that allows it to understand relationships between image elements at different levels. And the DPT-ResNet incorporates residual attention mechanisms to capture long-range dependencies while preserving the spatial structure of the image.
Links:
- Article GitHub repo: https://github.com/inuwamobarak/semantic-segmentation
- https://huggingface.co/docs/transformers/main/model_doc/dpt
- https://huggingface.co/docs/transformers/main/tasks/semantic_segmentation
- Ranftl, R., Bochkovskiy, A., & Koltun, V. (2021). Vision Transformers for Dense Prediction. ArXiv. /abs/2103.13413
- https://paperswithcode.com/dataset/ade20k
- https://huggingface.co/docs/transformers/main/model_doc/vit
- https://arxiv.org/abs/2103.13413
- https://huggingface.co/nielsr
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an AI Engineer with a deep passion for research, and solving complex problems. I provide AI solutions leveraging Large Language Models (LLMs), GenAI, Transformer Models, and Stable Diffusion.





