Imagine trying to renovate the foundation of a towering skyscraper without asking its occupants to leave or pause their work. That’s exactly what MoonshotAI’s Checkpoint Engine does for AI models. It allows massive language models to update their brains, the weights, while still running, so there’s no downtime. This breakthrough lets developers improve their AI quickly and efficiently, even on models with over a trillion parameters running on thousands of GPUs. It’s fast, reliable, and designed to keep AI systems running smoothly while evolving in real-time, making it a vital tool for cutting-edge AI applications. This article goes over what it is, how it works, and why it matters for the future of large-scale AI systems.
Table of contents
What is Moonshot AI’s Checkpoint engine?
Moonshot AI’s Checkpoint Engine is a specialized middleware designed to update the weights of large language models (LLMs) in real-time during inference without interrupting ongoing operations. This capability is critical in Reinforcement learning scenarios where model weights need to be updated frequently. The Checkpoint Engine currently integrates seamlessly with vLLM inference frameworks and offers optimized performance through pipelining and memory management techniques. It also provides features like reusing weights from existing instances to reduce overhead in scaling scenarios.
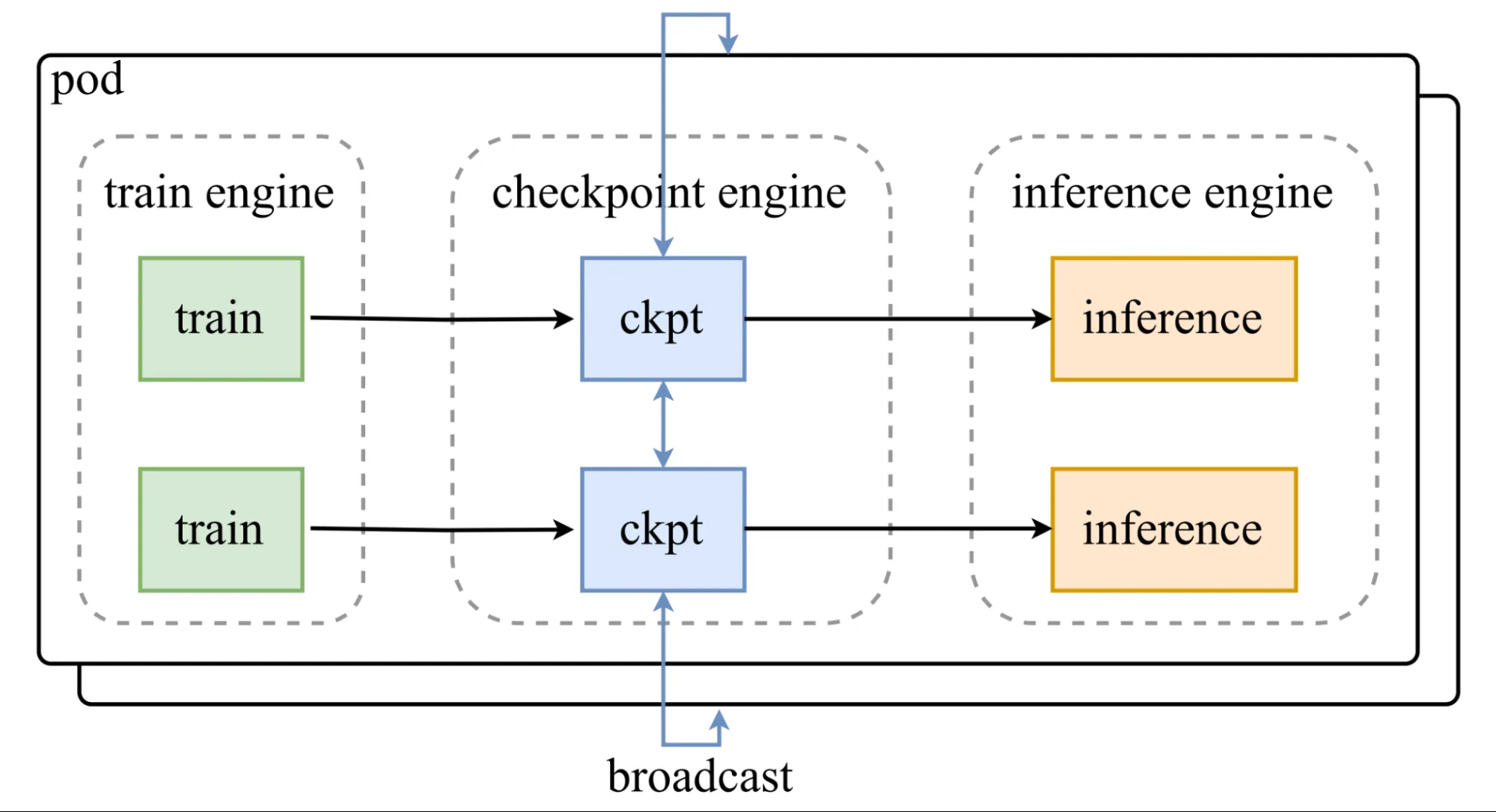
Architecture
The core of the Checkpoint is the ParameterServer class, which handles the weight update logic and orchestrates the data flow.
- H2D(Host to Device): Moves updated weights from CPU memory or storage to GPU memory, using optimized transfer pipelines.
- Broadcast: Distributes the weight across all inference engine instances efficiently, leveraging CUDA IPC buffers for shared memory communication.
- Reload: Each inference engine then selectively reloads relevant weight shards from the broadcasted data according to its sharding pattern.
These three-stage pipelines ensure efficient, overlapping communication and copying for speed.
When GPU memory is limited, the system can fall back to serial execution to maintain reliability.
Methods Used
The Checkpoint Engine uses two main methods to update model weights during inference.
- Broadcast Method: This is the fastest and the default approach. This is ideal when a large number of inference instances need to be updated simultaneously. It broadcasts the updated weights from CPU memory to all inference GPUs synchronously, ensuring all instances stay perfectly in sync with minimal delay.
- P2P (Peer-to-Peer) Method: It is used when inference instances are added or removed dynamically during runtime. It avoids disrupting existing inference workloads by sending weights directly from CPUs in existing instances to GPUs in new instances through a peer-to-peer transfer system, allowing smooth and flexible updates.
Working
The Checkpoint Engine orchestrates the entire transfer process. It first gathers necessary metadata to create a plan, including deciding the proper bucket size for data transfer. Then, it executes the transfer, controlling the inference engine through a ZeroMQ socket to maximize performance. It organizes data transfer into pipelines with overlapped communication and copy, enabling fast and efficient weight updates even under heavy workload.
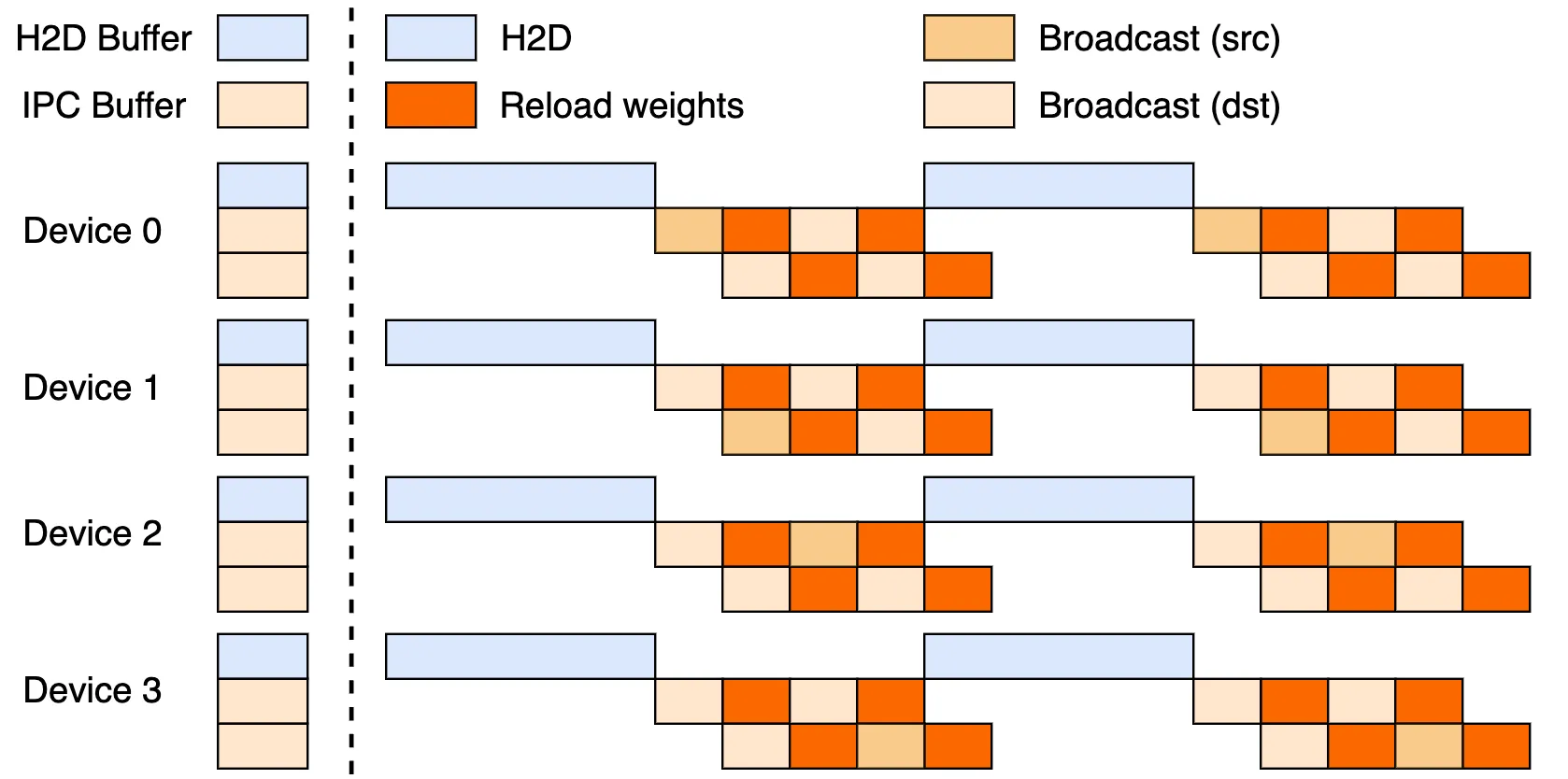
By implementing the above-mentioned methods and architecture, the Checkpoint Engine enables live weight updates for LLMs across thousands of GPUs with minimum latency and service disruption.
Installation and Usage
Installation
To use the fastest broadcast
Use Code:
pip install checkpoint-engineTo use the flexible P2P implementation:
Use Code:
pip install 'checkpoint-engine[p2p]'This will install mooncake-transfer-engine to support RDMA transfer between different ranks.
Example Use case
Step 1:
Prepare an H800 or H20 machine with 8 GPUs with the latest vLLM. Be sure to include /collective_rpc API endpoint commit (available in the main branch) since checkpoint-engine will use this endpoint to update weights.
Step 2:
install checkpoint-engineCode:
uv pip install 'checkpoint-engine[p2p]'Step 3:
For our use case, we are gonna use Qwen/Qwen3-235B-A22B-Instruct-2507 as the test model.
Code:
hf download Qwen/Qwen3-235B-A22B-Instruct-2507 --local-dir /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/Step 4:
Start vLLM in dev mode and set –load-format dummy. Make sure to set –worker-extension-cls=checkpoint_engine.worker.VllmColocateWorkerExtension
Code:
VLLM_SERVER_DEV_MODE=1 python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 19730 --trust-remote-code \
--tensor-parallel-size=8 --max-model-len 4096 --load-format dummy \
--served-model-name checkpoint-engine-demo --model /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/ \
--worker-extension-cls checkpoint_engine.worker.VllmColocateWorkerExtensionTo update weights by checkpoint-engine. No need to wait for vLLM to get ready. Use the code below.
Code:
torchrun --nproc-per-node 8 examples/update.py --update-method all --checkpoint-path /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/To reuse weights from existing instances
New checkpoint-engine instances can join existing instances and reuse their weights.
Using the method below:
Step 1: Start the existing instance with –save-metas-file global_metas.pkl to save global metas to a file.
Step 2: Use –sleep-time 300 to make sure they stay alive.
Code:
torchrun --nproc-per-node 8 examples/update.py --checkpoint-path $MODEL_PATH \
--sleep-time 300 --save-metas-file global_metas.pklStep 3: After a checkpoint is registered, new instances can obtain a copy of the checkpoint by setting –load-metas-file global_metas.pkl
Code:
torchrun --nproc-per-node 8 examples/update.py --load-metas-file global_metas.pklFP8 quantization
Currently, FP8 quantization does not work in vLLM when updating weights. It uses a simple patch in patches/vllm_fp8.patch to handle the correct weight update. Also ,this patch is only tested in DeepSeek-V3.1 and Kimi-K2. So there are chances of having some compatibility issues with other models.
Test
Run a simple correctness test for checkpoint_engine
Code:
torchrun --nproc-per-node 8 tests/test_update.pyBenchmark
| Model | Device Setup | Metadata Gathering | Update (Broadcast) | Update (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8x H800 TP8 | 0.17 seconds | 3.94 seconds (1.42 GiB) | 8.83 seconds (4.77 GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8x H800 TP8 | 0.46 seconds | 6.75 seconds (2.69 GiB) | 16.47 seconds (4.05 GiB) |
| DeepSeek-V3.1 (FP8) | 16x H20 TP16 | 1.44 seconds | 12.22 seconds (2.38 GiB) | 25.77 seconds (3.61 GiB) |
| Kimi-K2-Instruct (FP8) | 16x H20 TP16 | 1.81 seconds | 15.45 seconds (2.93 GiB) | 36.24 seconds (4.46 GiB) |
| DeepSeek-V3.1 (FP8) | 256x H20 TP16 | 1.40 seconds | 13.88 seconds (2.54 GiB) | 33.30 seconds (3.86 GiB) |
| Kimi-K2-Instruct (FP8) | 256x H20 TP16 | 1.88 seconds | 21.50 seconds (2.99 GiB) | 34.49 seconds (4.57 GiB) |
Insights
Here are a few observations that I’ve made:
- The broadcast method generally offers the fastest update time, optimized for synchronous weight updates across many inference instances.
- The P2P method takes longer but enables dynamic updates when instances join or leave during runtime.
- These benchmark shows the scalability of Checkpoint Engine, handling a trillion parameter models efficiently on clusters ranging from 8 to 256 GPUs
Limitations of Checkpoint Engine
While Checkpoint Engine is a powerful solution for live weight updates in LLMs, it currently has some limitations.
- Works Best with vLLM for Now: The engine is mainly tested with the vLLM framework. If you’re hoping to use it with other AI frameworks or custom setups, you might need some extra work to get it running smoothly.
- Pipeline Still Improving: The ideal seamless pipeline that overlaps data moves perfectly isn’t fully finished yet. This means there’s still potential to make the updates even faster.
- P2P Update Could Be Smoother: The peer-to-peer method sends data through a bottleneck at one main node before sharing it with others, which can slow things down when you have lots of GPUs.
- Needs Extra GPU Memory: The clever broadcast system uses more GPU memory to speed things up. On machines with less memory, it switches to a slower, less efficient process.
- Limited Support for FP8 Models: If you’re working with the newer FP8 quantized models, you’ll need some experimental patches. And even then, not all models play nicely, yet beyond a couple of tested ones.
Conclusion
Moonshot AI’s Checkpoint Engine is a game-changer for updating huge AI models without stopping them. It keeps everything running smoothly, even while the model’s “brain” is getting smarter in real-time. While it still has a few areas to improve, the potential is huge. If you’re working with large AI systems, this tool is definitely worth watching. It’s helping make the future of AI faster and more efficient, without any downtime.
Frequently Asked Questions
Q1. What problem does Checkpoint Engine solve?
A. It lets large language models update weights in real-time during inference without downtime, so AI systems stay online while improving.
Q2. Which frameworks does Checkpoint Engine support?
A. Right now, it’s mainly integrated and tested with the vLLM inference framework.
Q3. What’s the difference between Broadcast and P2P methods?
A. Broadcast is faster for synchronized updates across many GPUs, while P2P allows flexible updates when instances join or leave.
I am a Data Science Trainee at Analytics Vidhya, passionately working on the development of advanced AI solutions such as Generative AI applications, Large Language Models, and cutting-edge AI tools that push the boundaries of technology. My role also involves creating engaging educational content for Analytics Vidhya’s YouTube channels, developing comprehensive courses that cover the full spectrum of machine learning to generative AI, and authoring technical blogs that connect foundational concepts with the latest innovations in AI. Through this, I aim to contribute to building intelligent systems and share knowledge that inspires and empowers the AI community.






