This article was published as a part of the Data Science Blogathon
Hello There, This blog has an example of an ensemble of convolutional neural networks.
In real life, to take any decision a person consults many people because different people have different ways to process the same thought. Why not use this in the case of deep learning to get a robust result. As a programmer, I have worked with a few deep learning models like CNN, VGG16, DenseNet201, ResNet50. In this blog, we will create an ensemble of convolutional neural networks.
What is Ensembling?
Ensembling is the process of combining multiple learning algorithms to obtain their collective performance i.e., to improve the performance of existing models by combining several models thus resulting in one reliable model. As shown in the figure, models are stacked together to improve their performance and get one final prediction.
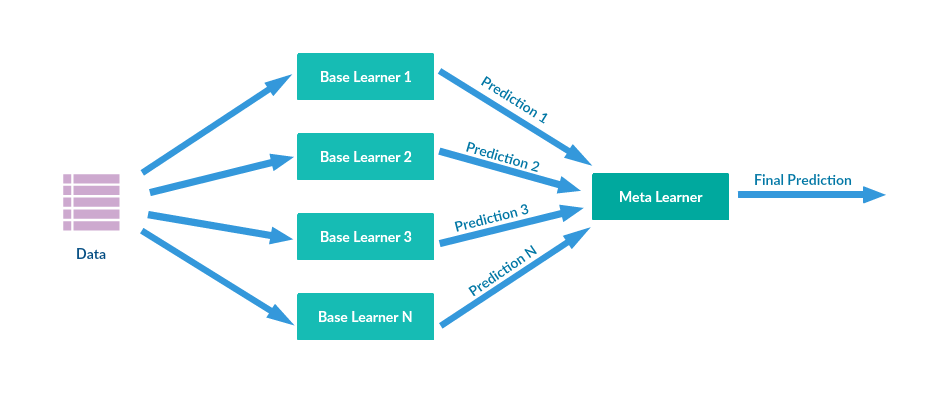
In the majority of applications, deep learning models individually proved to be competent but there is always scope to use a group of deep learning models for performing the same task as an ensembling approach.
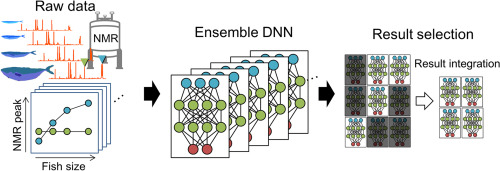
As shown in the figure the raw data is given as input to the ensemble model and then the training is done to get the result. Nowadays CNN is used almost everywhere like visual search, recommender engines, etc.., Some of the use cases of CNN are as follows:
1. Social networking: facial recognition is used to tag people on websites
2. In Entertainment: Filters in the social networking sites
3. In legal, banking, Insurance: Provide Optical character recognition
4. Document digitization: It provides a way to access any document anywhere at any time.
A CNN consists of four main layers they are convolution layer, rectified unit layer, pooling layer, connected layer. All these components work like a well-oiled machine to provide a prediction based on the input data. CNN obtains the input i.e., an image as a 3-dimensional object, then the CNN groups the pixels, which are then processed through filters.
The number of filters can be chosen depending on the complexity of the training data. Then the pooling layer performs regression i.e., reduce the parameters of the input. In an ensemble approach, we are just applying this process repeatedly over and over on the same data to obtain a more reliable result
Now, let us use the ensembling approach for CNN and see if it works better than the normal CNN.
Ensemble CNN
Let’s get started with the ensembling of CNN by importing the required libraries from python as shown below.
import pandas as pd import numpy as np import matplotlib.pyplot as plt
Pandas is used to read the CSV file provided with the dataset and NumPy is used to perform mathematical based operations on the data and matplotlib is used to represent graphs, images, etc..,
from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D, BatchNormalization from keras.optimizers import Adam, RMSprop
All the imports like sequential, Dense, Conv2D, etc.., are used to implement the CNN. In the next step, we import the data from a local directory or any other online website. The dataset used here is a fundus image dataset for diagnosing diabetic retinopathy consisting of 3662 images divided into the below-mentioned categories.
x_train=train_datagen.flow_from_directory(r"C:Users----colored_images",target_size=(64,64),batch_size=32,class_mode='categorical') x_test=train_datagen.flow_from_directory(r"C:Users----test",target_size=(64,64),batch_size=32,class_mode='categorical')
The ‘class_mode’ attribute is used to determine the number of classes or categories in the training data. In this case, the training data is divided into 5 categories like mild, moderate, severe, healthy, proliferative diabetic retinopathy. If in case there are only two categories then the class_mode must be ‘Binary’. The next steps include ensembling CNN. We use the number of individual nets as 10 and then a for loop is used to execute the model.
nets = 10
model = [0] *nets
for j in range(nets):
model[j] = Sequential()
model[j].add(Conv2D(32, kernel_size = 3, activation='relu', input_shape = (64, 64, 3)))
model[j].add(BatchNormalization())
model[j].add(Conv2D(32, kernel_size = 3, activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Conv2D(32, kernel_size = 5, strides=2, padding='same', activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Dropout(0.4))
#Second Layer of CNN
model[j].add(Conv2D(64, kernel_size = 3, activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Conv2D(64, kernel_size = 3, activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Conv2D(64, kernel_size = 5, strides=2, padding='same', activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Dropout(0.4))
#Third layer of CNN
model[j].add(Conv2D(128, kernel_size = 4, activation='relu'))
model[j].add(BatchNormalization())
model[j].add(Flatten())
model[j].add(Dropout(0.4))
#Output layer
model[j].add(Dense(5, activation='softmax'))
# Compile each model
model[j].compile(optimizer='adam', loss="categorical_crossentropy", metrics=["accuracy"])
Here, CNN is made of three layers which are implemented 10 times under a for a loop. The output layer has 5 dense units which represent the number of classes the training set is categorized into. Each model in the loop is compiled separately. Then the data is preprocessed using online data augmentation as shown in the code below.
train_datagen=ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
After preprocessing the training data, now it is time to train it and test the ensemble model against the basic CNN model.
for j in range(nets):
print(f'Individual Net : {j+1}')
model[j].fit_generator(x_train,steps_per_epoch=114,epochs=10,validation_data=x_test,validation_steps=1645)
The model is fit using a ‘for’ loop again and the steps_per_epoch, validation_steps are all calculated as follows:
1. Steps_per_epoch = total no images in training folder / batch size
2. Validation_steps = test sample count
3. Validation_data = test_data
Once the model is trained, it provides an accuracy of 74% whereas the basic CNN provides an accuracy of only 70% with my diabetic retinopathy data set. The model is then saved by using
for j in range(nets):
model[j].save('ensemble.h5')
After saving the model, I used Tkinter to build a simple user interface to test the model. An example of the outputs in Tkinter are shown in the screenshots below
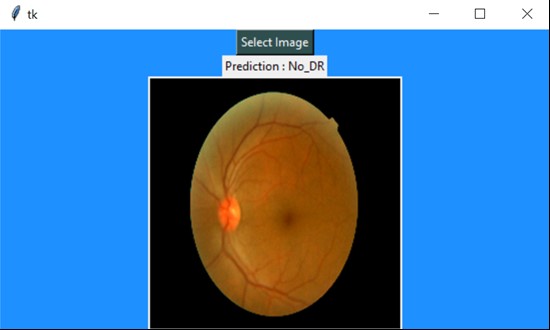
Classifies a healthy fundus image as healthy. source: Simi_Sanya
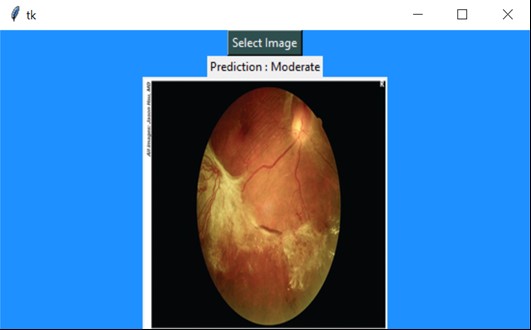
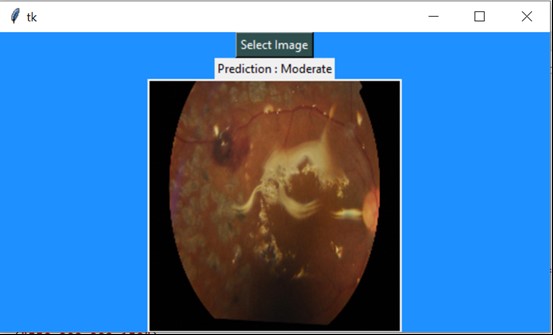
The ensemble model predicts correctly twice out of three times because of the accuracy. A larger and stronger dataset can be used to check the competency of the model. The ensemble model gives only 74% accuracy, but it is better than the basic CNN and we can say that it is stronger in terms of finding a pattern in the training data.
In this way, the ensembling approach can be applied to deep learning models, so that it can be applied to the tasks where basic deep learning models have given a low accuracy as per expectations. This method should be evaluated on much larger datasets of high-resolution images for the classification of diabetic retinopathy.
End Notes
To summarize, ensembling is the process of combining different models to obtain a robust and reliable model to make predictions. A convolutional neural network is an efficient deep learning model applied in various areas. On the other hand, an ensemble of the same deep learning model is more robust and provides more accuracy for the diabetic retinopathy dataset used. Ensemble models are more reliable and robust when compared with the basic deep learning models. Larger datasets can be applied to both models to make comparisons further. Other deep learning models can also be ensembled (same or different) to perform classifications.
Thank you for visiting the blog, for further queries write to [email protected]
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.




which part of the code is ensembling deep learning? what you have done so far is just creating 10 same models by looping, compiling and fitting each model separately.