Overview
- Real-time object detection is taking the computer vision industry by storm
- Here’s a step-by-step introduction to SlimYOLOv3, the latest real-time object detection framework
- We look at the various aspects of the SlimYOLOv3 architecture, including how it works underneath to detect objects
Introduction
Humans can pick out objects in our line of vision in a matter of milliseconds. In fact – just look around you right now. You’ll have taken in the surroundings, quickly detected the objects present, and are now looking at this article. How long did that take?
That is real-time object detection. How cool would be it if we could get machines to do that? Now we can! Thanks primarily to the recent surge of breakthroughs in deep learning and computer vision, we can lean on object detection algorithms to not only detect objects in an image – but to do that with the speed and accuracy of humans.
We will first look at the various nuances of object detection (including the potential challenges you might face). Then, I will introduce the SlimYOLOv3 framework and deep dive into how it works underneath to detect objects in real-time. Time to get excited!
If you’re new to the wonderful world of computer vision, we have designed the perfect course for you! Make sure you check it out here:
Table of Contents
- What is Object Detection?
- Applications of Object Detection
- Why Real-Time Object Detection?
- Challenges during Real-Time Object Detection
- Introduction to SlimYOLOv3
- Understanding the Architecture of SlimYOLOv3
What is Object Detection?
Before we dive into how to detect objects in real-time, let’s cover our basics first. This is especially important if you’re relatively new to the world of computer vision.
Object detection is a technique we use to identify the location of objects in an image. If there is a single object in the image and we want to detect that object, it is known as image localization. What if there are multiple objects in an image? Well, that’s what object detection is!
Let me explain this using an example:

The image on the left has a single object (a dog) and hence detecting this object will be an image localization problem. The image on the right has two objects (a cat and a dog). Detecting both these objects would come under object detection.
If you wish to get an in-depth introduction to object detection, feel free to refer to my comprehensive guide:
Now, you might be wondering – why is object detection required? ANd more to the point, why do we need to perform real-time object detection? We’ll answer these questions in the next section.
Applications of Object Detection
Object Detection is being widely used in the industry right now. Anyone harboring ambitions of working in computer vision should know these applications by heart.
The use cases of object detection range from personal security to automated vehicle systems. Let’s discuss some of these current and ubiquitous applications.
Self-Driving Cars
This is one of the most interesting and recent applications of Object detection. Honestly, it’s one I am truly fascinated by.
Self-driving cars (also known as autonomous cars) are vehicles that are capable of moving by themselves with little or no human guidance. Now, in order for a car to decide its next step, i.e. either to move forward or to apply breaks, or to turn, it must know the location of all the objects around it. Using Object Detection techniques, the car can detect objects like other cars, pedestrians, traffic signals, etc.

Face Detection and Face Recognition
Face detection and recognition are perhaps the most widely used applications of computer vision. Every time you upload a picture on Facebook, Instagram or Google Photos, it automatically detects the people in the images. This is the power of computer vision at work.

Action Recognition
You’ll love this one. The aim is to identify the activity or the actions of one or more series of images. Object Detection is the core concept behind this which detects the activity and then recognizes the action. Here’s a cool example:

Object Counting
We can use Object Detection algorithms for counting the number of objects in an image or even in real-time videos. Counting the number of objects is helpful in a variety of ways, including analyzing the performance of a store, or estimating the number of people in a crowd.

These are just a few popular object detection applications. There are a whole host of them springing up in the industry so if you know any that are worth mentioning, give me a shout in the comments section below!
Now, here’s the thing – most of the applications require real-time analysis. The dynamic nature of our industry leans heavily towards instant results and that’s where real-time object detection comes into the picture.
Why Real-Time Object Detection?
Let’s take the example of self-driving cars. Consider that we have trained an object detection model which takes a few seconds (say 2 seconds per image) to detect objects in an image and we finally deployed this model in a self-driving car.
Do you think this model will be good? Will the car be able to detect objects in front of it and take action accordingly?
Certainly not! The inference time here is too much. The car will take a lot of time to make decisions which might lead to serious situations like accidents as well. Hence, in such scenarios, we need a model that will give us real-time results. The model should be able to detect objects and make inferences within microseconds.
Some of the commonly used algorithms for object detection include RCNN, Fast RCNN, Faster RCNN, and YOLO.
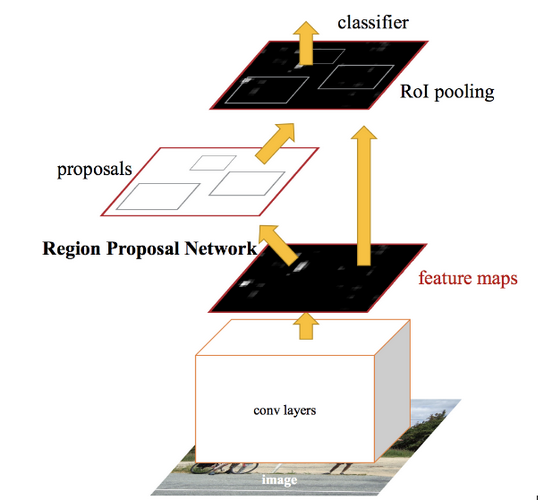
The aim of this article is not to deep dive into these techniques but to understand the SlimYOLOv3 architecture for real-time object detection. If you wish to learn more about these techniques, check out the below tutorials:
These techniques work really well when we do not need real-time detection. Unfortunately, they tend to stumble and fall when faced with the prospect of real-time analysis. Let’s look at some of the challenges you might encounter when trying to build your own real-time object detection model.
Challenges of Performing Real-Time Object Detection
Real-time object detection models should be able to sense the environment, parse the scene and finally react accordingly. The model should be able to identify what all types of objects are present in the scene. Once the type of objects have been identified, the model should locate the position of these objects by defining a bounding box around each object.
So, there are two functions here. First, classifying the objects in the image (image classification), and then locating the objects with a bounding box (object detection).
We can potentially face multiple challenges when we are working on a real-time problem:
- How do we deal with variations? The variations might be of difference in the shape of objects, brightness level, etc.
- Deploying object detection models. This generally takes A LOT of memory and computation power, especially on machines we use on a daily basis
- Finally, we must also keep a balance between detection performance and real-time requirements. Generally, if the real-time requirements are met, we see a drop in performance and vice versa. So, balancing both these aspects is also a challenge
So how can we overcome these challenges? Well – this is where the crux of the article begins- the SlimYOLOv3 framework! SlimYOLOv3 aims to deal with these limitations and perform real-time object detection with incredible precision.
Let’s first understand what SlimYOLOv3 is and then we will look at the architecture details to have a better understanding of the framework.
Introduction to SlimYOLOv3
Can you guess how a deep learning pipeline works? Here’s a quick summary of a typical process:
- First, we design the model structure
- Fine-tune the hyperparameters of that model
- Train the model and
- Finally, evaluate it
There are multiple components or connections in the model. Some of these connections, after a few iterations, become redundant and hence we can remove these connections from the model. Removing these connections is referred to as pruning.
Pruning will not significantly impact the performance of the model and the computation power will reduce significantly. Hence, in SlimYOLOv3, pruning is performed on convolutional layers. We will learn more about how this pruning is done in the next section of this article.
After pruning, we fine-tune the model to compensate for the degradation in the model’s performance.
A pruned model results in fewer trainable parameters and lower computation requirements in comparison to the original YOLOv3 and hence it is more convenient for real-time object detection.
Let’s now discuss the architecture of SlimYOLOv3 to get a better and clearer understanding of how this framework works underneath.
Understanding the Architecture of SlimYOLOv3
The below image illustrates how SlimYOLOv3 works:
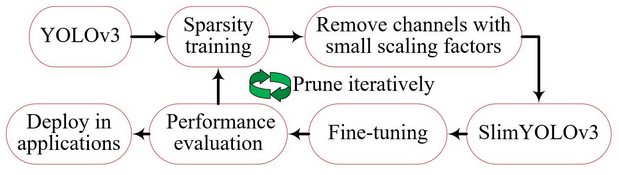
SlimYOLOv3 is the modified version of YOLOv3. The convolutional layers of YOLOv3 are pruned to achieve a slim and faster version. But wait – why are we using YOLOv3 in the first place? Why not other object detection algorithms like RCNN, Faster RCNN?
Why YOLOv3?

There are basically two types (or two categories) of deep object detection models:
- Two-stage detectors
Detectors belonging to the RCNN family fall under two-stage detectors. The process contains two stages. First, we extract region proposals and then classify each proposal and predict the bounding box. These detectors generally lead to good detection accuracy but the inference time of these detectors with region proposals requires huge computation and run-time memory
- Single-stage detectors
Detectors belonging to the YOLO series fall under single stage detectors. It is a single-stage process. These models utilize the predefined anchors that cover spatial position, scales, and aspect ratios across an image. Hence, we do not need an extra branch for extracting region proposals. Since all computations are in a single network, they are more likely to run faster than the two-stage detectors. YOLOv3 is also a single stage detector and currently the state-of-the-art for object detection
Sparsity training
The next step is the sparsity training of this YOLOv3 model:

Here, we prune the YOLOv3 model using the following steps:
- First, we evaluate the importance of each component of the YOLOv3 model. I will discuss the details of how to decide the importance of these components shortly
- Once the importance is evaluated, we remove the less important components
The removed components can either be an individual neural connection or the network structures. To define the importance of each component, we rank each neuron of the network based on their contribution. There are multiple ways to do it:
- We can take the L1/L2 regularized means of neuron weights
- The mean activation of each neuron
- Number of times the output of a neuron wasn’t zero
In SlimYOLOv3, the importance is calculated based on the L1 regularized means of neuron weights which are considered as the scaling factor. The absolute value of these scaling factors is the importance of a channel. To accelerate the convergence and improve the generalization of the YOLOv3 model, the batch normalization layer is used after every convolutional layer.
SlimYOLOv3
We then define a global threshold, let’s say ŷ, and discard any channel that has a scaling factor less than this threshold. In this way, we prune the YOLOv3 architecture and get the SlimYOLOv3 architecture:

While evaluating the scaling factor, the maxpool layers and the upsample layers of the YOLOv3 architecture have not been considered since they have nothing to do with the channel number of the layer number.
Fine-tuning
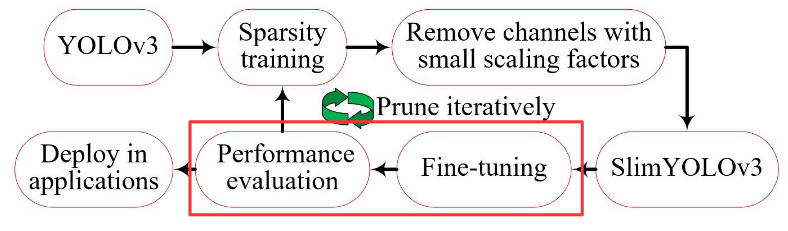
We now have the SlimYOLOv3 model, so what’s next?
We fine-tune it so as to compensate for the degradation in performance and finally evaluate the fine-tuned model to determine whether the pruned model is suitable for deployment.
Sparsity training is actually quite effective in reducing the scaling factor and hence making the feature channels of convolutional layers sparse. Training with a larger penalty factor of α = 0.01, leads to aggressive decay of the scaling factor and the model starts to overfit.
In SlimYOLOv3, a penalty factor of α = 0.0001 is used to perform channel pruning.
End Notes
We’ve covered a lot of ground in this article. We saw the different object detection algorithms like RCNN, Fast RCNN, Faster RCNN, as well as the current state-of-the-art for object detection YOLO. Then, we looked at the SlimYOLOv3 architecture which is the pruned version of YOLO and can be used for real-time object detection.
I’m excited to get my hands on the code for SlimYOLOv3! I will try to implement SlimYOLOv3 and will share my learning with you guys.
If you have any questions, doubts or feedback related to this article, feel free to discuss with me in the comments section below.
My research interests lies in the field of Machine Learning and Deep Learning. Possess an enthusiasm for learning new skills and technologies.




Truly, this article is really one of the very best in the history of articles. I am a antique Article collector and I sometimes read some new articles if I find them interesting. And I found this one pretty fascinating and it should go into my collection. Very good work!
Glad you liked it Anushya!
I was taking a gander at some of your posts on this site and I consider this site is truly informational! Keep setting up..
Thanks for your feedback Likhitha!
After reading your article I was amazed. I know that you explain it very well. And I hope that other readers will also experience how I feel after reading your article.
Glad you liked it Tejaswini!