This article was published as a part of the Data Science Blogathon
Introduction to ETL
ETL as the name suggests, Extract Transform and Load is the process of collecting data from one or more systems (not necessarily in the same format), transforming it to the desired form before pushing it to the data warehouse /database. ETL also makes it possible to migrate data between a variety of sources, destinations, and analysis tools. The ETL process plays a crucial role in producing business intelligence and accomplishing various data management strategies and achieving the organizations’ goals.
The organization data can be structured as well as unstructured, the ETL process makes it possible to put all the data under a single roof so as to produce business intelligence.ETL in the data warehouse offers deep historical context for the business. A well-defined ETL process helps to improve productivity in terms of code reusability and helps to make one consistent system.
Pandas Vs PETL
Pandas certainly do not need an introduction. Every data scientist be it novice or expert, has one or the other time worked with pandas. Pandas have become the prerequisite for all data scientists and machine learning experts, and mainly because pandas have a wide range of functions that make working with tables, data frames, or multi-dimensional arrays easier even for non-programmers. Pandas allow importing data from various file formats such as comma-separated-values, JSON, SQL, Microsoft Excel, etc and allows data manipulation on them.
Similar to pandas there is another python package called PETL which is used for extracting, transforming, and loading tables of data. In addition to allowing data import from CSV, JSON and SQL it has a wide range of functions for transforming tables with minimum lines of code. PETL is focused on ETL and hence it is more efficient than pandas when working with databases like MySQL or sqlite3 etc.
Why PETL?
PETL is more memory efficient than pandas as it does not load the database into memory each time it executes a line of code. When working with the mixed data types, unfamiliar, and heterogeneous data, petl is considered to be the go-to library. PETL is considered to be very lightweight and efficient and hence used for migrating between SQL databases.
PETL can be installed using pip, Syntax is mentioned below
pip install petl import petl as etl
PETL functionality
The functionality in the PETL module can be mainly divided into Extract, Transform, Load, along with some other Utility functions.
Extract
The data can be imported from all kinds of files including CSV, TSV, XML, dictionary, pickle, text, etc. Below are some of the examples of the same
Reading from sqllite3 student database
connection = sqlite3.connect(‘student_db’)
Table = etl.fromdb(connection,’’’
SELECT *
FROM student_table
WHERE student_id>100;’’’)
Reading from CSV file
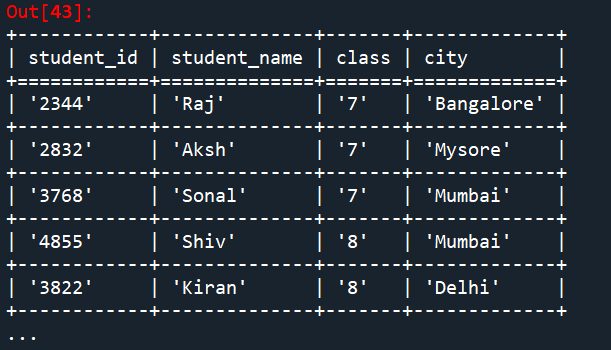
student_info = etl.fromcsv('student_info.csv') # reading students info from csv file
etl.look(student_info) #Display the table
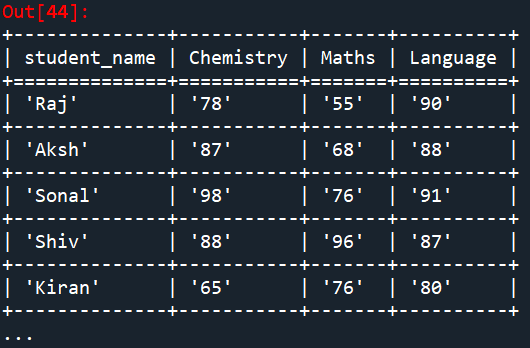
student_mark = etl.fromcsv('student_mark.csv') # Reading the student marks from csv file
etl.look(student_mark) # Display the table
Transformation
Below are some of the functions like cat , melt, transpose etc availbe in PETL library for data transformation
table = petl.cat(student_info, student_mark) #Concatenate the table together to make new table etl.look(table)
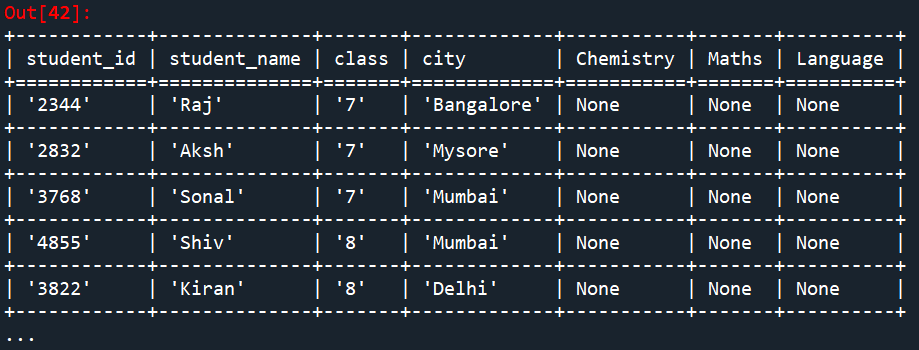
table2 = etl.melt(student_info, 'class') # used for melting the table based on a specific column etl.look(table2)
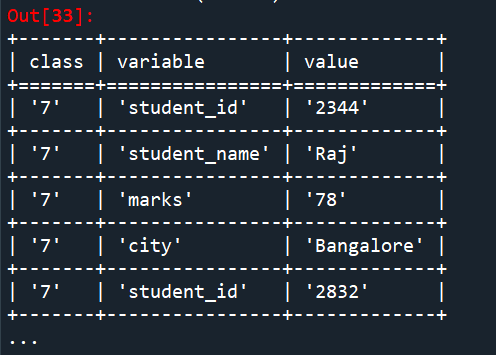
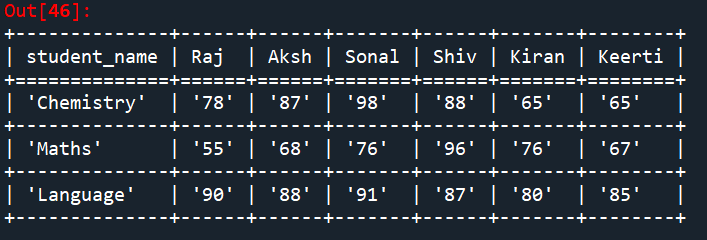
table = transpose(student_marks) #Transpose table and change rows to column and column to rows etl.look(table)
Load Tables
Once the transformation is done on the table, the results can be loaded into the database or save as CSV files. Below is the syntax for writing the resultant tables to CSV, TSV, XLSX, SQL database, etc.
etl.tocsv(table,’result.csv’) etl.totsv(table,’result.tsv’)
So if you check the directory from which you are running your code you’ll notice a result.csv file there. In case you wish to save the output to some other location, provide the path to the same in place of result.csv. The resulting file will be saved to your desired location.
Foot Notes
Although PETL is memory efficient and enables you to scale millions of rows with ease, it has certain drawbacks in terms of data analysis and visualization. PETL does not have any functions for performing any kind of data analysis as Pandas do, this is one of the reasons it is not as popular as pandas. Alongside PETL as a library is still under active development and also it lacks proper documentation and hence is not very popularly used by the data scientists’ community.
Other alternatives for PETL are dask, modin, bonbo, bubbles, etc
Below are the URLs for the official documentation and source code of PETL.
- Documentation: http://petl.readthedocs.org/
- Source Code: https://github.com/petl-developers/petl
- Download: http://pypi.python.org/pypi/petl
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







Very well done article. I am just learning about using Python as an ETL language and found this very insightful. Especially the last part about PETL not loading the data into memory for every time a line executes.